Journal of Mathematical Finance
Vol.06 No.04(2016), Article ID:71820,28 pages
10.4236/jmf.2016.64045
Conditioning the Information in Portfolio Optimization
Carlo Sala1, Giovanni Barone Adesi2
1Department of Financial Management and Control, ESADE Business School, Ramon Llull University, Barcelona, Spain
2Swiss Finance Institute at Università della Svizzera Italiana (USI), Institute of Finance, Lugano, Switzerland

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: September 4, 2016; Accepted: November 4, 2016; Published: November 7, 2016
ABSTRACT
This paper proposes a theoretical analysis of the impact of a suboptimal information set on the two main components used in asset pricing, namely the physical and neutral probability measures and the pricing kernel they define. The analysis is carried out by means of a portfolio optimization problem for a small and rational investor. Solving for the maximal expected utility of terminal wealth, it proves the existence of an information premium between what is required by the theory, that is a complete information set―thus a fully conditional measure―and what is instead achievable by an econometrician using real data. Searching for the best bounds, it then studies the impact of the premium on the pricing kernel. Finally, exploiting the strong interconnection between the pricing kernel and its densities, the impact of the premium on the risk-neutral measure is analyzed.
Keywords:
Information Premium, Portfolio Optimization Problem, Suboptimal Filtration Set, Optimal Bounds

1. Introduction
Decision making under uncertainty is an important problem in financial economics. The role of probability is to provide the tools to try to evaluate, as much accurately as possible, which are the possible future scenarios that an investor can face. Knowing that no purely stochastic events can be perfectly forecasted, the degree of accuracy of the outcomes strongly depends upon the quality and quantity of knowledge one has about the outcome of the actions. Unfortunately, despite what is too often assumed by many models in financial economics and more specifically by most of the asset pricing models, the investors’ knowledges about future events are far from being complete.
Starting from a very common finance stochastic problem, a portfolio optimization, this paper shows how this naive assumption may impact on the final performances of a small and rational investor that trades in risky and riskless assets. The distance between a theoretically optimal portfolio and the forecasted one is defined as the information premium. Section 2 shows how this premium proxies the amount of information lost in the so called real world measure. As it will be shown, most of this information is due to the forward looking beliefs of investors that play a crucial role in any investment decision. They are very difficult to estimate using backward looking data only. How this premium may flow from the suboptimally estimated real world measure to the risk- neutral one through the pricing kernel is also analyzed. Aside from the portfolio optimization problem, the contribution of this paper to the literature has a broader impact. It is in fact the scarcity and not the abundance of information the norm for an investors that deals with daily risky decisions using real data. It follows that the same information premium concept and how it may spread on different quantities can be applied to many other risky decisions under uncertainty.
The risk-neutral measure is a risk-adjusted real-world probability. Defined in an arbitrage-free, complete and efficient market, the equivalence of the risk-neutral measure, also known as the equivalent martingale measure (EMM), follows from the three fundamental theorems of asset pricing (FTAP) (Delbaen and Schachermayer, (1994), (1998) [1] [2] , Harrison and Pliska, (1981), (1983) [3] [4] , Jarrow, (2012) [5] , Jarrow and Larsson, (2012) [6] ).
Mathematically, the change of measure is made possible by a kernel, an operator. In finance, once properly discounted, this operator takes the name of pricing kernel (henceforth: PK). The tight interconnection existing between the two measures and the PK thus follows by construction and is at the base of most of the philosophy that underpins all of the actual asset pricing theory.
Exploiting this interrelationship, the knowledge of any of these two random variables implies uniquely the third. As a drawback, any possible misestimation may spread and affect more variables. Although too often not considered, this is particularly true in terms of the quality and quantity of the information used in pricing. While it is well known from a theoretical viewpoint, it is in fact still unclear econometrically which information should be transferred among the two measures (and how) to assure the required homogeneity.
A main goal of this paper is to build a bridge between what is required from a mathematical viewpoint and what is instead achievable on a daily basis by an econometrician or an investor that use real data. It follows that, although analyzed from a theoretical viewpoint, most of the main results of the paper have also strong empirical implications.
Dealing with the investors’ behavior and defined under the so called real-world probability, it is a well known fact that empirically both the PK as well as the real-world measure are non linear, unobservables and complex quantities to estimate.
Among the other advantages, the non trivial determination of these quantities allowed for the creation of the risk-neutral measure, one of the greatest innovations of all times in financial economics. In fact, the risk-adjustment applied to the artificially created risk-neutral measure, getting rid of the difficulties relative to the estimation of the subjective beliefs, makes its overall determination much less problematic and straightforward.
However, if from one side the creation of the risk-neutral measure solved most of the above problems, from the other side it left the theory silent on the best way to properly estimate both the real-world measure and the pricing kernel. A consequence of that is that there is still not a cut and clear agreement on the best way to properly estimate these random variables. Despite that it is by now conventional wisdom, both in academia and in the business community, to use option data and the relative un- derlying to estimate the risk-neutral and the real-world measures separately. The extraction of the relative PK thus follows from their discounted ratio.
Here is where most of the problems lie. The joint use of a properly estimated risk- neutral measure with a not so well estimated real-world one may have strong impact not only on the real-world measures and its connected pricing techniques, but also on the relative pricing kernel. At the heart of the problems there are the remarkably different features that characterize the two measures and that lead to very different final outputs. This is especially true from the viewpoint of the market information captured by the two measures, a characteristic too often assumed as negligible in most of the empirical works. In fact, if thanks to the information provided by the implied volatility and its higher moments, the risk-neutral measure extracted from option surfaces is, from an informative viewpoint, a naturally unbiased measure1, the real-world measure extracted from the underlying stream of past returns is a systematically biased sub- optimal measure. This is always true whenever the measure is estimated by means of a stream of past returns. Being a single value of the stock not enough to extract a density, this is always a necessary step. Options data, on the other side, provide for each day a complete set of strikes and time to maturities, thus making the inference process immediate and correct with no need of further past data.
This backward bias, often ignored, is the cause of possible mispricing and illusory arbitrages. This bias is the key element analyzed by the paper.
At the root of this backward bias there is the inability of capturing (by using historical stock data only) the investors’ subjective beliefs which play a crucial role in any investment decision and thus must be part of the information set of any investor.
We define it as a backward bias because, by construction, today investors’ beliefs of a future decision are naturally forward looking. An investor decides if and how to trade depending, among the others, on her personal beliefs. Therefore, the evaluation of any risky investment must take into account the forward nature of the investors’ subjective beliefs. But what is crystal clear theoretically under a mathematical viewpoint is not the same achievable in practice by an econometrician. For example:, counterintuitively with respect to its nature, the market subjective distribution of future returns is estimated by means of backward looking data (i.e.: Äit-Sahalia and Lo (2000) [7] , Jackwerth (2000) [8] , Brown and Jackwerth (2004) [9] , Engle and Rosenberg (2002) [10] , Barone Adesi, Engle and Mancini (2008) [11] , Yatchev and Härdle (2006) [12] ). Relying on these data, an important fraction of the investor’s risk and preferences is systematically lost. As a consequence, a discrepancy between what is empirically obtainable and what is theoretically required by the neoclassical asset pricing literature arises. While the above are just a fraction of the huge literature that deals with the estimation of the real-world measure and the relative pricing kernel, it is well known in literature that the estimation of a complete, hence conditional, real-world filtration set is econometrically a non trivial problem. In fact, it not only requires an econometrically advanced model in its estimation, but also (and probably more importantly) the availability of particular data. There is in fact no econometric model that can make backward looking data forward looking. The larger the forward looking information bias (usually due to higher market volatility), the larger is the subsequent mispricing.
The remaining of the paper analyzes this problem and is so organized: Section 2 recalls the above presented backward bias problem from a more rigorous mathematical viewpoint. The problem is then investigated through a portfolio optimization analysis for a small and rational investor under different utility functions. To show the existence and impact of a possible information premium the optimization problem is carried out from the point of view of an investor both with a complete and an incomplete infor- mation set. Section 6 analyzes the same problem showing how the existence of a backward bias may impact the area of existence of the pricing kernel. Finally, the connection with the risk-neutral measure and its impacts on the risk neutral pricing closes the paper.
2. Theoretical Motivation
From a probabilistic viewpoint the above presented backward bias, caused by the different assets used in estimation, can be represented by two filtration sets, with one of which is by construction smaller:
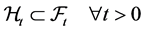 (1)
(1)
Both sets are increasing2 in time and contain all available and potentially usable information:
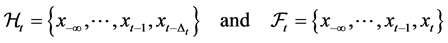 (2)
(2)
What makes 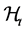 smaller is
smaller is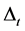 : the fraction of missing forward looking information that involves any risky decision to undertake from today with respect to a future time. From here on,
: the fraction of missing forward looking information that involves any risky decision to undertake from today with respect to a future time. From here on, 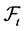 represents the theoretical information set and
represents the theoretical information set and 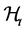 the suboptimal one. In connection with the motivation presented above
the suboptimal one. In connection with the motivation presented above 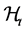 would be the filtration set obtainable from a stream of past stock returns while
would be the filtration set obtainable from a stream of past stock returns while 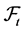 the one obtainable from a cross section of options data.
the one obtainable from a cross section of options data.
Being the information set the driver of any forecasting model, a suboptimal filtration set has a sure impact on the estimation of any random variable. It is in fact well known that future stochastic events are usually modelled by means of conditional expectations under the real-world measure3:
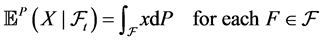 (5)
(5)
where the conditionality is with respect to what is known at time t: the information set. Let us apply the generic case to a finance related problem: the today prediction of the unknown price 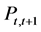 given
given , the information available at time t:
, the information available at time t:
 (6)
(6)
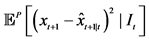 (3)
(3)
Given the problem, the best (minimum mean squared error: MMSE) predictor is the conditional expectation given the information set:
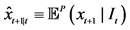 (4)
(4)
Given the time horizon of the prediction, here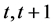 , the above integral4 re- presents the weighted sum of the averaged possible future values,
, the above integral4 re- presents the weighted sum of the averaged possible future values,  , under the physical probability. From (6) emerges clearly the importance of the right use of the information set. The average is in fact computed using the
, under the physical probability. From (6) emerges clearly the importance of the right use of the information set. The average is in fact computed using the  conditional probabilities,
conditional probabilities, . All information available thus enter into the
. All information available thus enter into the  forecast. The poorer the information set, the worse the final outcome.
forecast. The poorer the information set, the worse the final outcome.
Given the different informative content of the inputs it follows that while theo- retically, under some technical assumptions, the same expectation can be estimated indifferently using either the physical  or the risk-neutral
or the risk-neutral  measure, in reality this equivalence is often violated.
measure, in reality this equivalence is often violated.
For example, applying and extending under the two measures the above fundamental asset pricing Equation (6) to compute the today price,  , of a generic contingent claim that expires at time T:
, of a generic contingent claim that expires at time T:
 (7)
(7)
 (8)
(8)
 (9)
(9)
 (10)
(10)
 (11)
(11)
 (12)
(12)
 (13)
(13)
 (14)
(14)
 (15)
(15)
where, for each , we use:
, we use:
 (16)
(16)
to represent the conditional expectation under the optimal (left) and suboptimal (right) information set. For all equations,  represents the time-to-maturity and
represents the time-to-maturity and  the terminal payoff of the product given the value of the underlying
the terminal payoff of the product given the value of the underlying . The inequality in (11) is due to the missing but necessary information (relative to T) of the today (time t) risk-physical measure:
. The inequality in (11) is due to the missing but necessary information (relative to T) of the today (time t) risk-physical measure:
 (17)
(17)
Although the missing information is referred to the future, its impact is absorbed today and propagated onto tomorrow price forecast. As a consequence, while the left hand side is fully conditional on all values known today, the right hand side is not. Furthermore, if the PK is extracted from the discounted ratio of the pricing over the physical measure, it is immediate that an improper use of the information set pro- pagates a.s. from the real-world to the risk-neutral pricing equation through the PK, . The difference in (17) is then the focus of the paper.
. The difference in (17) is then the focus of the paper.
It follows naturally that a suboptimal information set has also an impact on the relative probability measures:
 (18)
(18)
 (19)
(19)
where  (resp.
(resp. ) represents the physical probability measure for a the optimal
) represents the physical probability measure for a the optimal  (resp. suboptimal
(resp. suboptimal ) information set. The same logic applies for the risk-neutral measures. The difference between
) information set. The same logic applies for the risk-neutral measures. The difference between  and
and  thus mirrors the distance between an empirically biased asset pricing with respect to the theoretical one. This distance represents the sub-optimality of the information set: what we will call as the infor- mation premium.
thus mirrors the distance between an empirically biased asset pricing with respect to the theoretical one. This distance represents the sub-optimality of the information set: what we will call as the infor- mation premium.
In a nutshell: conditional expectations reflect the change in unconditional proba- bilities given some auxiliary information; the definition and use of this information is then of fundamental importance to evaluate this change correctly. If the filtration used is missing of relevant information, hence is suboptimal, the projection onto the smaller set leads a.s. to an inequality:
 (20)
(20)
Although from an economic perspective consumption-based models would be the most comprehensive answer to all of the asset pricing questions, it is well known that they are not fully reliable. At the origin of their biases there are the high difficulties concerning a proper estimation of the investors’ consumption. To overcome the issue, a natural alternative approach to the classical Lucas asset pricing model is the following: given an economy where one can observe the prices of the available assets and try to model the subjective distribution of their final payoffs, what is the optimal portfolio for a small and rational investor5? Although the problem is very well-known in literature, not much emphasis has been put on the frequent biases that can arise whenever the investors’ subjective beliefs that compose her distribution are suboptimally estimated.
Extending Øksendal (2005) [13] this paper analyzes this problem starting from a simple economy described by a Levy-Itô mixed model and it analyzes how the obtained outputs may impact on the total profitability of the investors.
3. The Optimization Problem
To analyze the above problem we model a simple economy made of two assets and we study the impact of a smaller information set onto a rational investor that, endowed with a positive initial capital, wants to maximize her final welfare choosing among the set of admissible portfolios:
 (21)
(21)
Under this framework, the conditionality of the expectation in (21) is represented by the set of feasible portfolios  where
where  represents the set of admissible portfolios and its subscript
represents the set of admissible portfolios and its subscript  restricts this set to the information available at time t. We will compute and compare the same optimization problem conditional on the complete and a suboptimal information set. Given a fixed time window,
restricts this set to the information available at time t. We will compute and compare the same optimization problem conditional on the complete and a suboptimal information set. Given a fixed time window,  , and for each
, and for each , the optimal portfolio weight of the investor conditional to the information set (if it exists), is represented by
, the optimal portfolio weight of the investor conditional to the information set (if it exists), is represented by . It follows that
. It follows that  is the optimal value of the problem and both random variables (the complete and the suboptimal) are then
is the optimal value of the problem and both random variables (the complete and the suboptimal) are then  - adapted stochastic processes.
- adapted stochastic processes.
Equation (21) is nothing but a classical consumer problem (CP) where the op- timization is with respect to some financial asset class. As a consequence  is a financial instrument that proxies consumption: i.e. wealth. The resolution of the optimization problem is linked to the arbitrary choice of a regular utility function
is a financial instrument that proxies consumption: i.e. wealth. The resolution of the optimization problem is linked to the arbitrary choice of a regular utility function  6. For simplicity the optimization is first analyzed assuming a generic logarithmic utility function7:
6. For simplicity the optimization is first analyzed assuming a generic logarithmic utility function7:
 (22)
(22)
The resolution of the asset pricing problem (21) leads to the optimal expected logarithmic utility of the investor terminal wealth .
.
The entire optimization is performed under the physical measure, P, and conditional to the filtration set of the investor, . This leads naturally to the use of the partial information approach presented in the previous section. It assumed a fixed time frame
. This leads naturally to the use of the partial information approach presented in the previous section. It assumed a fixed time frame  such that, for each time
such that, for each time :
:
 (23)
(23)
It follows that, depending on the filtration in use, the degree of adeptness (measurability) of the stochastic process may change, thus impacting in various form on the final outcomes of the optimization. As a technical remark: both filtrations lie in filtered probability spaces:
 (24)
(24)
and satisfy the usual hypotheses.
The goal of the presented framework is to model the economy of a single investor with a suboptimal information set, where the stochastic processes that affect the optimal portfolio choice are  and not
and not  -adapted, thus reflecting the poorer decisional power of the investor, due to the lack of forward looking information.
-adapted, thus reflecting the poorer decisional power of the investor, due to the lack of forward looking information.
4. The Lévy-Itô Model and the Portfolio Optimization Problem
Probably as a direct consequence of the much larger theoretical literature relative to the enlargement of filtration with respect to the one relative to the shrinkage of filtration, the same degree of richness is reflected on their different applications, i.e.: portfolio optimization. Equation (21) mirrors the well-known stochastic control problems related to the insider information (i.e. see Biagini and Øksendal (2005) [14] ). While the insider information cases are characterized by an informed trader that has a larger information set with respect to the one of the “honest” trader, here things go on the opposite directions. In both cases extra assumptions and computational tools are required. Differently than the insider case, the literature for these problems is far more scarce.
Following Øksendal (2005) [13] our starting point is a Lévy-Itô market model composed by two assets: one risky and one risk-free. Given this simple economy8, the investor implements her portfolio through a dynamic trading of the two assets. The choice of modelling the stochastic part of the risky investment by means of a Brownian motion (Itô process) and a pure jump process (Lévy process) instead of just using the classical diffusion-Itô model is justified by the higher descriptive power of the former9.
More in detail, the two assets that compose the economy are:
・ A riskless asset, whose rate of return is allowed to fluctuate but that is otherwise risk-free, which is represented by a risk-free bond , with unit price
, with unit price  at time t is:
at time t is:
 (25)
(25)
 (26)
(26)
where  is
is  -adapted and represents the time invariant risk-free rate in the market10.
-adapted and represents the time invariant risk-free rate in the market10.
・ A risky asset, represented by a stock P driven by a one dimensional Brownian motion and a pure jump process (Lévy-Itô process), with unit price  at time t is:
at time t is:
 (27)
(27)
 (28)
(28)
Technical assumptions (T.A.):
For each ,
,  and
and  it is assumed that the parameters of the continuous part of the process
it is assumed that the parameters of the continuous part of the process  and
and  satisfy the following technical assumptions (T.A.):
satisfy the following technical assumptions (T.A.):
T.A.1  -progressively measurable, hence time dependent and non-anticipating.
-progressively measurable, hence time dependent and non-anticipating.
T.A.2 bounded on .
.
T.A.3 parameters  and
and  represent respectively the investors’ expected returns form
represent respectively the investors’ expected returns form  and the volatility of
and the volatility of .
.
T.A.4  is an
is an  -adapted one dimension Brownian Motion.
-adapted one dimension Brownian Motion.
While the parameters governing the jump part of the process are such that:
T.A.5  is
is  -adapted hence time dependent, and non-anticipating.
-adapted hence time dependent, and non-anticipating.
T.A.6  is the
is the  -compensated Poisson random measure of
-compensated Poisson random measure of  where:
where:
 (29)
(29)
T.A.7 to prevent the process to be , we set:
, we set:  for a.a.
for a.a.  with respect to
with respect to .
.
T.A.8 .
.
Further details on the main characteristics that govern the jump part of (27) are in Appendix (9.1) and we refer the reader to Tankov and Cont (2000) [16] for more details about Lévy processes in finance.
The application of the Itô formula for semimartingales plays a key role for the resolution of the problem. It turns out that also its application is fully dependent to a proper assessment of the filtration set. Let us quickly recall it:
Theorem 1. If  is an Itô-Lévy process:
is an Itô-Lévy process:
 (30)
(30)
such that:
 (31)
(31)
and , where
, where  and
and , then, by the Itô formula for semimartingales:
, then, by the Itô formula for semimartingales:
 (32)
(32)
the process  is an Itô-Lévy process as well.
is an Itô-Lévy process as well.
Let us apply theorem (1) to the portfolio problem. If the presented T.A. are satisfied and if the t and z dependent parameters of Equations (25) and (27) are  -adapted such that:
-adapted such that:
 (33)
(33)
then, by the Itô formula for semimartingales, the solution of (27) is:
 (34)
(34)
Now, suppose that  is an
is an  -measurable stochastic process representing the fraction of wealth
-measurable stochastic process representing the fraction of wealth  invested the investor in the risky asset and
invested the investor in the risky asset and  is invested in the risk-free asset. The evolution of the total wealth process,
is invested in the risk-free asset. The evolution of the total wealth process,  11, of the investor is then:
11, of the investor is then:
 (35)
(35)
 (36)
(36)
or, collecting terms:
 (37)
(37)
 (38)
(38)
A key element for the analysis of the paper is how to define an admissible portfolio under the different filtrations in use.
Definition 4.1. Given a small and rational investor, a portfolio process  is assumed to be
is assumed to be  -admissible for each
-admissible for each  if:
if:
・ is  -adapted for each t, where
-adapted for each t, where .
.
・  .
.
・  a.s. for
a.s. for  for a.a. t and z.
for a.a. t and z.
Given this framework, we analyze the stochastic control problem of a small investor whose goal is to maximize  over a finite time window
over a finite time window  and over the class of all possible time (t) admissible portfolios
and over the class of all possible time (t) admissible portfolios . Formally:
. Formally:
Proposition 2. We solve a finite horizon  stochastic control problem of a rational and small investor endowed with a positive initial capital
stochastic control problem of a rational and small investor endowed with a positive initial capital  and described by a generic utility function
and described by a generic utility function , here a logarithmic utility function, whose goal is to maximize her expected utility from terminal wealth, i.e.:
, here a logarithmic utility function, whose goal is to maximize her expected utility from terminal wealth, i.e.:  by investing continuously in a risky, P, and in a risk-free asset,
by investing continuously in a risky, P, and in a risk-free asset, .
.
The optimal value of the problem, denoted by,  , is valid only if, for each
, is valid only if, for each  and
and , there exists an optimal portfolio process,
, there exists an optimal portfolio process,  , which belongs to the set of admissible portfolios,
, which belongs to the set of admissible portfolios,  , s.t.:
, s.t.:
 (39)
(39)
where the value function of the problem is assumed to be:
 (40)
(40)
Given proposition (2) it emerges clearly that the solution of the problem is strongly related to the admissibility of the portfolio with respect to the information set, . To better underline its importance, the same portfolio problem will be analyzed under two different information sets:
. To better underline its importance, the same portfolio problem will be analyzed under two different information sets:
1) Theoretical case: : the information set is complete.
: the information set is complete.
2) Real-world case: : some relevant information is missing, hence cannot be reflected in the final asset price.
: some relevant information is missing, hence cannot be reflected in the final asset price.
The former case pertains to an investor which is able to set up an asset pricing model that fully capture all past, present and future relevant pricing information, hence also and above all her forward looking beliefs with respect to the future outcome. The latter pertains instead to a more realistic suboptimal case. Illusory arbitrages may be the naive consequence of an investor not being fully aware of pertaining to the former or the latter group.
While is at least since Merton (1969) [18] and Samuelson (1969) [19] that the stochastic control problem for  -adapted portfolios is well-known in literature (a good review of the subject is, among the others, Cvitanic and Karatzas (1992) [20] ), the one for an Itô-Lévy market model with a suboptimal information set is not. We extend the literature answering this problem and analyzing its effect in asset pricing under different viewpoints.
-adapted portfolios is well-known in literature (a good review of the subject is, among the others, Cvitanic and Karatzas (1992) [20] ), the one for an Itô-Lévy market model with a suboptimal information set is not. We extend the literature answering this problem and analyzing its effect in asset pricing under different viewpoints.
4.1. The Theoretical Optimal Choice
This subsection solves the portfolio optimization problem for an investor with logarithmic utility function under the theoretical case: when the filtration set is the complete one:
 (41)
(41)
Assuming for all , that
, that  and applying the Itô theorem for semi- martingales to (37) the admissible investor’s terminal wealth is:
and applying the Itô theorem for semi- martingales to (37) the admissible investor’s terminal wealth is:
 (42)
(42)
Given the evolution of the total wealth of the investor, and assuming that:
 (43)
(43)
the expected value of the problem is:
 (44)
(44)
Fixing  and
and , the objective function to maximize is:
, the objective function to maximize is:
 (45)
(45)
where h is a positive and concave function. Taking the first order condition with respect to  and equating the result to zero we obtain the solution
and equating the result to zero we obtain the solution  :
:
 (46)
(46)
Collecting terms, the extra return from the portfolio is:
 (47)
(47)
which, for the continuous case :
:
 (48)
(48)
whose validity depends on  a.s. for a.a.
a.s. for a.a. ,
,  and
and .
.  is the optimal portfolio process
is the optimal portfolio process  only if is in the set of admissible portfolios given the information set:
only if is in the set of admissible portfolios given the information set:
 (49)
(49)
It follows that the optimal portfolio value for the case of a theoretical (or full) information set  is:
is:
 (50)
(50)
With no loss of generality the investor initial capital can be set as  s.t.:
s.t.:
 (51)
(51)
In conclusion: for a finite-time complete market model with one riskless and one risky asset, the maximal expected logarithmic utility of the terminal wealth for a small and rational investor with a complete set of information is the integrated sum of the risk-free rate and a fraction of the Sharpe ratio squared.
4.2. The Real-World Optimal Choice
This subsection analyzes again the same problem but for the viewpoint of an econome- trician that uses real data:
 (52)
(52)
It thus focus the attention, both theoretically and conceptually, on how the missing information of the filtration set propagates and affect onto the final profit of the investor.
Except for  and
and , which are affected by the scarcer informative content given by the suboptimal filtration set, the starting point for the restricted case is the same as the complete one:
, which are affected by the scarcer informative content given by the suboptimal filtration set, the starting point for the restricted case is the same as the complete one:
 (53)
(53)
Given the evolution of the total wealth of the investor and assuming that:
 (54)
(54)
the expected value of the problem is:
 (55)
(55)
To account for the smaller amount of information for the optimization of the re- stricted optimal portfolio , we need to insert, for all
, we need to insert, for all , an extra con- ditioning of the expectation with respect to
, an extra con- ditioning of the expectation with respect to :
:
 (56)
(56)
or, applying the same convention as before:
 (57)
(57)
then:
 (58)
(58)
where  identifies the value of the parameters under the
identifies the value of the parameters under the  restriction.
restriction.
Dealing with the subjective beliefs that affect the investor’s investment decisions, the consequences of a suboptimal filtration set have an impact only on the risky assets of the investor’s portfolio. Although allowed to fluctuate, the risk-free asset is in fact assumed to be free of any subjective and objective risks thus not affecting the overall investor’s subjective behaviour with respect to risky decision to undertake.
This can be easily “demonstrated” starting from the definition of the classical physical pricing equation:
 (59)
(59)
where  represents the time t pricing functional of a risk-free bond, B, which matures at time T and
represents the time t pricing functional of a risk-free bond, B, which matures at time T and  its relative PK. By construction, the role of the PK in asset pricing is to adjust the future payoff accounting for all possible risky future outcomes that can affect the underlying. A risk-free product is, by definition, without risk12. Not having to consider any risk or time preference of the investor, its expected final payoff is at any point in time equal to one, no matter what happens in the market. Given a finite time window,
its relative PK. By construction, the role of the PK in asset pricing is to adjust the future payoff accounting for all possible risky future outcomes that can affect the underlying. A risk-free product is, by definition, without risk12. Not having to consider any risk or time preference of the investor, its expected final payoff is at any point in time equal to one, no matter what happens in the market. Given a finite time window,  , this is translated in a PK:
, this is translated in a PK:
 (60)
(60)
As a consequence, at any , the risk-free bond is immune to any risk and Equation (59) can be iterated-back in time such that its time 0 price is:
, the risk-free bond is immune to any risk and Equation (59) can be iterated-back in time such that its time 0 price is:
 (61)
(61)
Given the role of the PK, the absence of risk for the underlying in question, and differently than (57), Equation (61) is not affected by any possible missing forward looking information:
 (62)
(62)
It follows that the riskless bond has the same value, no matter under which filtration:
 (63)
(63)
 (64)
(64)
It follows naturally that no hat is needed on any of the riskless parameters present in the portfolio problems i.e.: .
.
As for the complete case, let’s fix  such that the suboptimal objective function is:
such that the suboptimal objective function is:
 (65)
(65)
which is again positive and concave hence solvable:
 (66)
(66)
It follows that the excess return under the suboptimal filtration set is:
 (67)
(67)
Remark 4.1. Equation (67) is valid only if  and if the a.s. uniform integrability with respect to
and if the a.s. uniform integrability with respect to  of:
of:
 (68)
(68)
applies for almost all .
.
Once more, for each , Equation (68) is a consequence of:
, Equation (68) is a consequence of:
 (69)
(69)
In case of no jumps :
:
 (70)
(70)
where the above equation is valid only if  a.s. for a.a.
a.s. for a.a. ,
,  and
and .
.
Once more,  is the optimal portfolio process
is the optimal portfolio process  only if is in the set of admissible portfolios given the information set:
only if is in the set of admissible portfolios given the information set:
 (71)
(71)
It follows that the optimal restricted portfolio value is:
 (72)
(72)
With no loss of generality the initial capital of the investor is set to  s.t.:
s.t.:
 (73)
(73)
Now, combining (51) and (73) it follows that the use of a suboptimal information set leads to:
 (74)
(74)
 (75)
(75)
where  represents the time t information premium.
represents the time t information premium.
Following the neoclassical literature, the optimal (or theoretical) case assumes the investor to be a natural and fully rational optimizer capable to obtain the highest possible reward given the market scenario. On the contrary, the more realistic real- world case assumes and implies some deficiencies in optimization. It follows naturally for the above obtained information premium:
 (76)
(76)
At the same time, the amount of premium cannot be determined ex ante and is highly dependent to the market scenario (i.e.: level of volatility in the market).
Empirically, to have at each point in time a full information set as required by the neoclassical theory is usually a mere illusion. Therefore, the goal of a good financial modeller should be, for each , to minimize
, to minimize  as much as possible
as much as possible
 (77)
(77)
It follows immediately that to minimize  means to collect and model in the best way possible all the information that is relevant for pricing the assets. A proper estimation of the real-world probabilities is then of key importance for many day-by- day operations (i.e.: trading, risk management, asset management).
means to collect and model in the best way possible all the information that is relevant for pricing the assets. A proper estimation of the real-world probabilities is then of key importance for many day-by- day operations (i.e.: trading, risk management, asset management).
5. The Power Utility Case
A common drawback that pertains to the literature of the stochastic optimization problems (and not only) is its high reliance on the standardization of the parameters that govern most of models. In this paper the proposed model is highly dependent on the choice of the utility function used to describe the investor decisions. Given their widespread use in literature and as an alternative to broaden the analysis, the power utility function is proposed as a possible extension of the logarithmic utility one. Being aware that no investor can be properly and fully described by a parametric utility function, the proposed alternative is not a solution of the utility-problem but just a possible alternative. It follows that all results must then be considered as appro- ximations.
The problem remains the same:
Proposition 3. We like to solve a finite horizon  stochastic control problem of a rational and small investor endowed with a positive initial capital
stochastic control problem of a rational and small investor endowed with a positive initial capital  and described by a generic utility function
and described by a generic utility function , here a power utility function, whose goal is to maximize her expected subjective utility from terminal wealth, i.e.:
, here a power utility function, whose goal is to maximize her expected subjective utility from terminal wealth, i.e.:  by investing continuously in a risky, P, and in a risk-free asset,
by investing continuously in a risky, P, and in a risk-free asset, .
.
The optimal value of the problem, denoted by,  , is valid only if, for each
, is valid only if, for each  and
and , there exists an optimal portfolio process,
, there exists an optimal portfolio process,  , which belongs to the set of admissible portfolios,
, which belongs to the set of admissible portfolios,  , s.t.:
, s.t.:
 (78)
(78)
where the the value function of the problem is assumed to be:
 (79)
(79)
As stated in proposition (3) and differently than (2) the investor is modelled through a Constant Relative Risk Aversion (CRRA) utility function:
 (80)
(80)
where  is a constant and measures the degree of relative risk aversion implicit in the utility function. Going into the limit (see Appendix (9)):
is a constant and measures the degree of relative risk aversion implicit in the utility function. Going into the limit (see Appendix (9)):
 (81)
(81)
Given the new setup we follow the same procedure as before to solve the stochastic optimization problem under the two scenarios.
For a full information set:  and with
and with :
:
 (82)
(82)
where  is the optimal portfolio process
is the optimal portfolio process  only if is in the set of admissible portfolios given the information set:
only if is in the set of admissible portfolios given the information set:
 (83)
(83)
For (82), to be valid, we need  and
and  a.s. for a.a.
a.s. for a.a. ,
,  and
and  to hold.
to hold.
Setting the investor initial capital to :
:
 (84)
(84)
In conclusion, for a finite-time complete market with one riskless and and one risky asset, the maximal expected power utility of the terminal wealth for a small and rational investor with a complete set of information, is the integrated sum of the risk-free rate and a fraction of the Sharpe ratio squared normalized by .
.
The same logic applies for the partial information set . In case of no jumps
. In case of no jumps :
:
 (85)
(85)
where , the indicator of the subjective degree of risk aversion of an investor, is fully impacted by the coarser filtration set so that:
, the indicator of the subjective degree of risk aversion of an investor, is fully impacted by the coarser filtration set so that:
 (86)
(86)
is a valid equivalence.
 is the optimal portfolio process
is the optimal portfolio process  only if is in the set of admissible portfolios given the information set:
only if is in the set of admissible portfolios given the information set:
 (87)
(87)
Also for the restricted Sharpe ratio, to be valid, we need  and
and  a.s. for a.a.
a.s. for a.a. ,
,  and
and  to hold.
to hold.
Setting the initial capital of the investor to  the optimal restricted portfolio value is
the optimal restricted portfolio value is
 (88)
(88)
Now, combining (84) and (88) it follows that the difference in filtration is equal to:
 (89)
(89)
 (90)
(90)
which, as  13:
13:
 (91)
(91)
 (92)
(92)
6. Connection with the PK
There is a well known and strong interconnection between optimal portfolios and the PK. The latter is in fact bounded by the highest feasible Sharpe ratio and vice-versa. The simplicity and generality of the rules that govern these bounds justify their widespread use in many aspects of financial economics (see Bekaert and Liu (2001) [21] for a review.). These bounds, also known as the Hansen-Jagganathan bounds (1991) [22] , pose upper and lower limits on both random variables. Henrotte (2002) [23] inves- tigates the tight but non-trivial relationship between the PK, its variance and the optimal portfolio choice. He defines that:
Definition 6.1. The square of the Sharpe ratio of every portfolio is smaller than the variance of every normalized PK.
From the definition, two are the main consequences in asset pricing:
・ The square of the Sharpe ratio of any portfolio bounds the variance of any normalized PK:

・ No Sharpe ratios squared can be greater than the variance of the normalized PK:

where the variance is normalized through the mean of the PK itself and  states for Sharpe Ratio squared.
states for Sharpe Ratio squared.
In this section, I extend and generalize the above definition for the case of a suboptimal PK. Due to qualitative and quantitative importance of the missing infor- mation from the suboptimal filtration set it follows from Equation (74) that, for each , if
, if  and
and  differs significantly, then:
differs significantly, then:
 (93)
(93)
which implies an a.s. inequality for the Sharpe ratios squared of the two portfolios:
 (94)
(94)
All else equal, a better informed investor can aim to higher returns and lower volatility, which justify also conceptually the above inequality. These results show clearly that a suboptimal information set impacts directly on the total profitability of the investor’s portfolio and also indirectly on the quality of their bounds.
Different papers refine and extend the Hansen-Jagganathan bounds in several directions14. One of the main difficulties, common to many papers, is the time-varying estimation of the elements that compose the PK. Some authors propose unconditional PKs thus lowering the effectiveness of the findings. A time independent PK would be in fact of little usefulness for many day-by-day operations (i.e.: asset and risk man- agement). Working on the insights of Gallant, Hansen and Tauchen (1990) [25] a more recent paper of Bekaert and Liu (2004) [21] extends the theory on the optimal bounds putting emphasis on the optimal use of the conditioning of the information. As a main result they show how, given some technical conditions15 the best bounds are the ones that maximizes the squared Sharpe Ratio:
 (95)
(95)
Applying the theorem to our findings emerges how a more informed investors can not only benefit from superior returns, but also from sharper, thus better, PK bounds. Given this result and from definition (6.1) it follows that:
 (96)
(96)
7. Expressing the Information Premium as the Kullback-Leibler Divergence
This section shows how, through the PK, a suboptimal filtration set may propagates onto the risk-neutral pricing. Results can be so summarized:
・ The information premium is nothing but the difference between the optimal and the suboptimal Kullback-Leibler divergences
・ A suboptimal information set may affect the risk-neutral pricing by means of the restricted market price of risk that enters into the Girsanov theorem
Let us start defining the time-dependent theoretical and suboptimal market prices of risk16 as:
 (97)
(97)
 (98)
(98)
Then, if  and
and  are locally square integrable and if:
are locally square integrable and if:
 (99)
(99)
 (100)
(100)
then, for all  and
and ,
, :
:
 (101)
(101)
 (102)
(102)
are the optimal and suboptimal probability measures defined respectively on  and
and  where:
where:
 (103)
(103)
 (104)
(104)
are the respective optimal and suboptimal pricing kernels. For both pricing kernels,  and
and  are the respective optimal and suboptimal Brownian Motion defined on
are the respective optimal and suboptimal Brownian Motion defined on  and
and  so that
so that  and
and  are
are  - and
- and  -adapted.
-adapted.
It follows that:
 (105)
(105)
such that  is a positive true martingale17. Given that some families of semi- martingales-namely: local and strict local martingales-may change the nature of their process (from absolutely continuous to mixed) once projected onto smaller filtration sets (Protter (2015) [26] , Sala and Barone Adesi (2015) [27] ), the same may not be true under the suboptimal scenario. From the previous sections and justified by the rational behaviours of the investors under the neoclassical theory, it follows that the optimal quantities are always larger with respect to the suboptimal ones.
is a positive true martingale17. Given that some families of semi- martingales-namely: local and strict local martingales-may change the nature of their process (from absolutely continuous to mixed) once projected onto smaller filtration sets (Protter (2015) [26] , Sala and Barone Adesi (2015) [27] ), the same may not be true under the suboptimal scenario. From the previous sections and justified by the rational behaviours of the investors under the neoclassical theory, it follows that the optimal quantities are always larger with respect to the suboptimal ones.
 (106)
(106)
Now, let’s recall the information premium:
 (107)
(107)
Since the theory in object applies independently of the utility function used, we omit to specify it.
Assuming that the usual technical assumption holds (square local integrability and Novikov condition) the Kullback-Leibler divergence among the optimal densities is:
 (108)
(108)
 (109)
(109)
 (110)
(110)
 (111)
(111)
 (112)
(112)
The same hold for the suboptimal case:
 (113)
(113)
 (114)
(114)
 (115)
(115)
 (116)
(116)
 (117)
(117)
where:
 (118)
(118)
Condition (118) determines the highly remote, but theoretically possible, extreme case of an unbounded value due to the lack of absolutely continuity of the measures18.
Now, taking the difference among the two distances:
 (119)
(119)
 (120)
(120)
 (121)
(121)
In finance, the EMM has the advantage of being fully neutral and unaffected by subjective beliefs. Among the others, one of the main feature is that it prevents the problem of picking a parametric utility function to describe the fully non-parametric investors behavior. This paper shows how, in presence of information premiums, both the risk-neutral and the real-world measure and the relative pricing kernel can be strongly affected. Overall, the asset pricing bias can be so summarized:
Suboptimal information: 
ß
Suboptimal filtration set: 
ß
Impact on the risk physical measure: 
ß
Impact on the market price of risk: 
ß
Impact on the pricing kernel: 
ß
Impact on the risk-neutral measure: 
ß
Mispricing: 
8. Conclusions
This paper investigates how possible misestimations of the investor’s future beliefs may lead to mispricing.
Econometrically, it is conventional wisdom for most of the (in not the entire) literature to use backward-looking data to estimate forward-looking beliefs. This approach leads almost surely to biased estimations due to the use of a coarser filtration set. Starting from this well-known bias, this paper documents how the use of a suboptimal information set may affect the asset pricing in different ways. Due to the strong interconnection between the measures and the pricing kernel, possible misestimations of the physical measure load naturally onto the other two quantities.
Starting from a portfolio optimization problem for a small and rational investor, it shows how a partially-informed trader that wants to maximize her final wealth through dynamic trading may end up with a smaller profit with respect to a fully informed one. Performing the same optimization technique for a theoretical (full information set) and a real-world (partial information set) case, emerges the existence of an information premium. To minimize this premium, hence the bias, means to maximize the infor- mation estimation.
The existence of an information premium, impacting on the optimality of the pricing kernel bounds, has a direct effect on its usability. As a consequence, a less informed investor, having access to a smaller range of supports of the pricing kernel, has a reduced spectrum of possible scenario analysis. This has a direct consequence on the quality and the effectiveness of many day-by-day operations i.e.: hedging or trading strategies.
Focusing on the premium, it shows that the information premium arising from two investors is nothing but the Kullback-Leibler distance among the two set of densities.
To conclude, through the Girsanov’s theorem, it shows how starting from a suboptimal information set, the bias propagates naturally from the physical to the risk- neutral pricing.
Acknowledgements
We thank the editor and the referees for their comments. We are grateful for the financial support of the Swiss Finance Institute (SFI) and the Swiss National Science Foundation (SNF).
Cite this paper
Sala, C. and Barone Adesi, G. (2016) Conditioning the Information in Portfolio Optimization. Journal of Mathematical Finance, 6, 598-625. http://dx.doi.org/10.4236/jmf.2016.64045
References
- 1. Delbaen, F. and Schachermayer, W. (1994) A General Version of the Fundamental Theorem of Asset Pricing. Mathemathische Annalen, 300, 463-520.
http://dx.doi.org/10.1007/BF01450498 - 2. Delbaen, F. and Schachermayer, W. (1998) Fundamental Theorem of Asset Pricing for Unbounded Stochastic Processes. Mathemathische Annalen, 334, 215-250.
http://dx.doi.org/10.1007/s002080050220 - 3. Harrison, J.M. and Kreps, D.M. (1979) Martingales and Arbitrage in Multiperiod Securities Markets. Journal of Economic Theory, 20, 381-408.
http://dx.doi.org/10.1016/0022-0531(79)90043-7 - 4. Harrison, J.M. and Pliska, S.R. (1983) A Stochastic Calculus Model of Continuous Trading: Complete Markets. Stochastic Processes and Their Applications, 15, 313-316.
http://dx.doi.org/10.1016/0304-4149(83)90038-8 - 5. Jarrow, R. (2012) The Third Fundamental Theorem of Asset Pricing. Annals of Financial Economics, 7, Article ID: 1250007.
- 6. Jarrow, R. and Larsson, M. (2012) The Meaning of Market Efficiency. Mathematical Finance, 22, 1-30.
http://dx.doi.org/10.1111/j.1467-9965.2011.00497.x - 7. Ait-Sahalia, Y. and Lo, A.W. (1998) Non-Parametric Estimation of State-Price Densities Implicit in Financial Asset Prices. The Journal of Finance, 53, 499-457.
http://dx.doi.org/10.1111/0022-1082.215228 - 8. Jackwerth, J. (2000) Recovering Risk Aversion from Option Prices and Realized Returns. Review of Financial Studies, 13, 433-451.
http://dx.doi.org/10.1093/rfs/13.2.433 - 9. Brown, D.P. and Jackwerth, J. (2004) The Pricing Kernel Puzzle: Reconciling Index Option Data and Economic Theory. Working Paper.
- 10. Engle, R. and Rosenberg, V. (2002) Empirical Pricing Kernels. Journal of Financial Economics, 64, 341-372.
http://dx.doi.org/10.1016/S0304-405X(02)00128-9 - 11. Barone-Adesi, G., Engle, R. and Mancini, L. (2008) A Garch Option Pricing Model in Incomplete Markets. Review of Financial Studies, 21, 1223-1258.
http://dx.doi.org/10.1093/rfs/hhn031 - 12. Yatchev, A. and Hardle, W. (2006) Non-Parametric State Price Density Estimation Using Costrained Least Squares and the Bootstrap. Journal of Econometrics, 133, 579-599.
http://dx.doi.org/10.1016/j.jeconom.2005.06.031 - 13. Oksendal, B. (2005) The Value of Information in Stochastic Control and Finance. Australian Economic Papers, 44, 352-364.
http://dx.doi.org/10.1111/j.1467-8454.2005.00267.x - 14. Biagini, F. and Oksendal, B. (2005) A General Stochastic Calculus Approach to Insider Trading. Applied Mathematics and Optimization, 52, 167-181.
http://dx.doi.org/10.1007/s00245-005-0825-2 - 15. Barndorff-Nielsen, O. (1998) A Process of Normal Inverse Gaussian Type. Finance and Stochastics, 2, 41-68.
http://dx.doi.org/10.1007/s007800050032 - 16. Tankov, P. and Cont, R. (2004) Financial Modelling with Jump Processes. CRC Press, Boca Raton.
- 17. Korn, R. and Kraft, H. (2001) A Stochastic Control Approach to Portfolio Problems with Stochastic Interest Rates. SIAM Journal on Control and Optimization, 40, 1250-1269.
http://dx.doi.org/10.1137/S0363012900377791 - 18. Merton, R.C. (1969) Lifetime Portfolio Selection under Uncertainty: The Continuous Time Case. Review of Economics and Statistics, 51, 247-257.
http://dx.doi.org/10.2307/1926560 - 19. Samuelson, P.A. (1969) Lifetime Portfolio Selection by Dynamic Stochastic Programming. Review of Economics and Statistics, 51, 239-246.
http://dx.doi.org/10.2307/1926559 - 20. Cvitanic, J. and Karatzas, I. (1992) Convex Duality in Constrained Portfolio Optimization. Annals of Applied Probability, 2, 767-818.
http://dx.doi.org/10.1214/aoap/1177005576 - 21. Bekaert, G. and Liu, J. (2004) Conditioning Information and Variance Bounds on Pricing Kernels. The Review of Financial Studies, 17, 339-378.
http://dx.doi.org/10.1093/rfs/hhg052 - 22. Hansen, L. and Jagannathan, R. (1991) Implications of Security Market Data for Models of Dynamic Economies. Journal of Political Economy, 99, 225-262.
http://dx.doi.org/10.1086/261749 - 23. Henrotte, P. (2002) Pricing Kernels and Dynamic Portfolios. Pricing Kernels and Dynamic Portfolios.
http://ssrn.com/abstract=302047
http://dx.doi.org/10.2139/ssrn.302047 - 24. Ferson, W.E. and Siegel, F. (2003) Stochastic Discount Factor Bounds with Conditioning Information. Review of Financial Studies, 15, 567-595.
http://dx.doi.org/10.1093/rfs/hhg004 - 25. Gallant, R., Hansen, L. and Tauchen, G. (1990) Using Conditional Moments of Asset Payoffs to Infer the Volatility of the Intertemporal Marginal Rates of Substitution. Journal of Econometrics, 45, 141-179.
http://dx.doi.org/10.1016/0304-4076(90)90097-D - 26. Protter, P. (2015) Strict Local Martingales with Jumps. Stochastic Processes and Their Applications, 125, 1352-1367.
http://dx.doi.org/10.1016/j.spa.2014.10.018 - 27. Sala, C. and Barone-Adesi, G. (2015) Sentiment Lost: The Effect of Projecting the Empirical Pricing Kernel onto a Smaller Filtration Set. Working Paper.
Appendix
A1. Properties of Lévy Processes
Given a filtered probability space which satisfies the usual hypothesis  and a fixed time period
and a fixed time period , a generic stochastic process
, a generic stochastic process  whose values are in
whose values are in  and
and  is a Lévy process:
is a Lévy process:
 (122)
(122)
if satisfies the following properties:
・ Independent increments: for an increasing sequence of times  with
with , the random variables are time independent:
, the random variables are time independent:  .
.
・ Stationary increments: the law of  is independent to t.
is independent to t.
・  is a right continuous with left limits-cadlag-process s.t. the paths
is a right continuous with left limits-cadlag-process s.t. the paths  are non-anticipating.
are non-anticipating.
・ Stochastic continuity: ,
, .
.
where the last property assures that jumps occur at random times. If the probability of having a jump is not a.s. equal to 0, we would have the so called “calendar effect”.
Given a Lévy process and a measurable subset A, its measure  on
on  is called the Lévy measure
is called the Lévy measure  and is defined as:
and is defined as:
 (123)
(123)
The Lévy measure represents the expected number, per unit of time, of jumps whose size belongs to the measurable set .
.
Now, given a Lévy process  on
on  and a Lévy measure
and a Lévy measure , by the Lévy-Ito decomposition theorem any such a process can be decomposed as:
, by the Lévy-Ito decomposition theorem any such a process can be decomposed as:
 (124)
(124)
where  are constants,
are constants,  is an
is an  -adapted Brownian Motion. The first two terms on the right hand side compose the continuous Gaussian Lévy process.
-adapted Brownian Motion. The first two terms on the right hand side compose the continuous Gaussian Lévy process.
The discontinuous part is composed by:
 (125)
(125)
and (126)
 (127)
(127)
 (128)
(128)
where the last term converges a.s. and uniformly in . The former process is a compound Poisson process while the latter indicates the compensated version of the process19. All terms in (124) are independent.
. The former process is a compound Poisson process while the latter indicates the compensated version of the process19. All terms in (124) are independent.
The process  is identified by means of the characteristic triplet
is identified by means of the characteristic triplet  where A is the covariance matrix of the Brownian motion,
where A is the covariance matrix of the Brownian motion,  is the Lévy measure and
is the Lévy measure and  is the drift of the continuous Gaussian Lévy process.
is the drift of the continuous Gaussian Lévy process.
A2. From Power to Logarithmic Utility Function
In this appendix, I prove Equation (80):
 (129)
(129)
where, with no loss of generality, the utility function  can be rewritten as:
can be rewritten as:
 (130)
(130)
which, given the iso-elastic properties of the utility functions, is a valid statement since the investors’ optimal decisions are not affected by additive constant terms in the objective function so that:
 (131)
(131)
With no loss of generality and to improve the readability of the proof, I omit visually the time dependence.
To prove the convergence in (131), I make use of the l’Hôpital’s rule which I report here:
Theorem 4 (l’Hopital’s rule). Let f and g be differentiable functions with  on an open interval O around a, except possibly at a.
on an open interval O around a, except possibly at a.
If:
 (132)
(132)
and if: (133)
 (134)
(134)
then: (135)
 (136)
(136)
Which, applied to (130):
 (137)
(137)
 (138)
(138)
 (139)
(139)
 (140)
(140)
 (141)
(141)
By the same token:
 (142)
(142)
 (143)
(143)
 (144)
(144)

Submit or recommend next manuscript to SCIRP and we will provide best service for you:
Accepting pre-submission inquiries through Email, Facebook, LinkedIn, Twitter, etc.
A wide selection of journals (inclusive of 9 subjects, more than 200 journals)
Providing 24-hour high-quality service
User-friendly online submission system
Fair and swift peer-review system
Efficient typesetting and proofreading procedure
Display of the result of downloads and visits, as well as the number of cited articles
Maximum dissemination of your research work
Submit your manuscript at: http://papersubmission.scirp.org/
Or contact jmf@scirp.org
NOTES

1This is always true, by construction, as long as there is no option mispricing.

2Two assumptions underpin this statement: the first is that information is time-varying and the second is that decision makers keep memory of all the past data.
3Let us assume that at time t we want to forecast the tomorrow’s value of a random variable 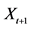 given the set of available information
given the set of available information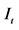 . This is an optimization problem; more precisely we pick the best predictor among all possible predictors by choosing the one that minimizes the expected quadratic prediction error:
. This is an optimization problem; more precisely we pick the best predictor among all possible predictors by choosing the one that minimizes the expected quadratic prediction error:
4The extremes of the integral may also be defined i.e.: put and call options are bounded by their strike prices either above or below.

5For small investor we define an unsophisticated investor that cannot affect the market prices with her trading. Rationality is defined under the neo-classical theory as a risk averse investor that always prefers more to less.
6A utility function is assumed to be regular if it is differentiable, concave a non-negative.
7With no loss of generality results applying to different types of utility functions. The main goal of the paper is to provide an intuitive explanation of the problem more than just a set of mathematical solutions of the optimization. Therefore the model is one-dimensional and only the cases of log and power utility functions are studied. Although much less explicit, similar results can be achieved with other utility functions and in a multidimensional framework.
8Extending the problem to a model with 1 risk-free asset and n,  risky assets is surely more realistic but the obtained results would be much less immediate to interpret. As a main difficulty there is the delicate calibration of the possible correlation among the assets.
risky assets is surely more realistic but the obtained results would be much less immediate to interpret. As a main difficulty there is the delicate calibration of the possible correlation among the assets.
9For modelling details we refer to Barndorff-Nielsen (1998) [15] and Cont and Tankov (2004) [16] .

10Equation (25) could be further refined by using a time varying risk-free rate as proposed by i.e.: Korn and Kraft (2001) [17] . The usual precision/tractability trade-off arises. To guarantee a higher tractability in the model we leave it deterministic.

11The parameter  is time-varying and its time dependency is equivalently represented with
is time-varying and its time dependency is equivalently represented with  or
or .
.
12This is not entirely true in reality since all assets may be affected by some risk. Nevertheless, although no products may have an a.s. probability of being totally risk-free, some of them have negligible risk potential so that they can be assumed as risk-free assets.
13Which implies that also .
.

14See Ferson and Siegel (2002) [24] and references therein.
15See [21] , Section 1.4 pag 345 and 346 for the main theorem and its proof.

16With no loss of generality, the market price of risk of the previous sections, being scaled by its variance, is a proportional version of the theoretical one.
17The Brownian motion under the new measure is:
18Under some conditions, i.e.: the existence of a measure under which both  and
and  are absolutely continuous, it is possible to have a finite value even if
are absolutely continuous, it is possible to have a finite value even if  is not absolutely continuous with respect to
is not absolutely continuous with respect to . As well as we can have non finite values if the two measures are mutually absolutely continuous.
. As well as we can have non finite values if the two measures are mutually absolutely continuous.
19The jump integral is  replaced by its compensated version to avoid singularities and assure convergence.
replaced by its compensated version to avoid singularities and assure convergence.