 Journal of Software Engineering and Applications, 2011, 4, 653-665 doi:10.4236/jsea.2011.412077 Published Online December 2011 (http://www.SciRP.org/journal/jsea) Cop yright © 2011 Sci Res. JSEA 653 Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario Mario Diván1,2 , Luis Olsina2, Silvia Gordillo3 1Law and Economy School, Universidad Nacional de La Pampa, Santa Rosa, Argentina; 2Engineering School, National University of La Pampa, General Pico, Argentina; 3LIFIA, Informatics School, National University of La Plata, La Plata, Argentina. Email: mjdivan@eco.unlpam.edu.ar, olsinal@ing.unlpam.edu.ar, gordillo@lifia.info.unlp.edu.ar Received Oct ober 25th, 2011; revised December 1st, 2011; accepted December 12th, 2011. ABSTRACT In this work we discuss SDSPbMM, an integrated Strategy for Data Stream Processing based on Measurement Meta- data, applied to an outpatient monitoring scenario. The measures associated to the attributes of the patient (entity) un- der monitoring, come from heterogeneous data sources as data streams, together with metadata associated with the formal definition of a measurement and evaluation project. Such metadata supports the patient analysis and monitoring in a more consistent way, facilitating for instance: 1) The early detection of problems typical of data such as missing values, outliers, among others; and 2) The risk anticipation by means of on-line classification models adapted to the patient. We also performed a simulation using a prototype developed for outpatient monitoring, in order to analyze empirically processing times and variable scalability, which shed light on the feasibility of applying the prototype to real situations. In addition, we analyze statistically the results of the simulation, in order to detect the components which incorporate more variability to the system. Keywords: Measurement, Data Stream Processing, C-INCAMI, Statistical Analysis 1. Introduction Nowadays, there are applications which make customized pro ce ssing of da ta set s, ge ne rated i n a co ntinuo us wa y, in response to queries and/or to adjust their behavior de- pend ing on t he ar ri val of ne w d at a [ 1 ]. Exa mple s of the se applications are namely for vital signs monitoring of pa- tients; for behavioral tracking of financial markets; for air traffic monitori ng, among others. In such applications, the arrival of a new data represents the arrival of a value (e.g. for a cardiac frequency, a foreign currency rate, etc.) associated to a syntactical behavior. Frequently, they only analyze the number (value) itself without formal and se- mantic support, disregarding not only the measurement metadata, but also the context in which the phenomenon happens. Therefore, in order to understand the meaning of arriving data and then act accordingly, such applications must necessarily incorporate a logic layer, i.e. procedures and metadata, which transform and/or interpret the data streams. Since a lack of clear separation of concerns be- tween the syntactic and semantic aspects of those current applications, very often an expert (e.g., for the outpatient monitoring system, the expert can be a doctor responsible for the monitoring) should intervene in order to interpret the situation. So we argue that given the state-of-the-art of IT in metadata and semantic pro cessing the intervene- tion of experts should be minimized as long as the appli- cations can perform the job. Taking into account the semantic and formal basis for measurement and evaluation (M&E), the C-INCAMI (Con- text-Information Need, Concept model, Attribute , Metric and Indicator) conceptual framework establishes an on- tology that includes the concepts and relationships nec- essary to specify data and metadata in any M&E project [2, 3]. O n the othe r ha nd, we have envisi oned t he ne ed of integrating heterogeneous data streams with metadata based on the C-INCAMI framework, in order to allow a more consistent and richer analysis of data sets (meas- ures). As result, the Strategy for Data Stream Processing based on Measurement Metadata (SDSPbMM) [4,5] was developed. The main SDSPbMM aim is filling the gap among the integration of heterogeneous data sources; the incorpora- tion and processing of metadata for attributes, contextual  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario 654 properties, metrics (for measurement) and indicators (for evaluation); and on-line classifiers that support in a more rob ust way dec i sion-making processes. Thus, by using the SDSPbMM approach for the above- mentioned applications, in this paper we present particu- larl y the fo undatio ns for d eveloping t he outpa tient moni - toring scenario. We also performed a simulation using a prototype developed for this scenario, in order to analyze empirically processing times and variable scalability, which shed light on the feasibility of applying the prototype to real situations. For this end, statistical techniques such as descriptive a nalysis, correla tion analysis a nd principal com- ponent analysis are used. The contributions of this work is manifold: 1) related to metrics: the detection of deviations of metrics’ values with respect to their formal definitions, identification of missing values and outliers; 2) related to the set of mea- sures: the instant detection of correlations; the identifica- tion of variability factors of the system; and the detection of trends on data streams, considering also the contextual situation; and 3) related to the empirical study: the vali- dation of the implemented prototype on a specific do- main scenario, i.e. the outpatient monitoring, which al- low us determining the feasibility to be applied in real si- tuations. The quoted contributions represent a step further with regard to our previous works [4,5], because now the en- hanced prototype incorporate the online classifiers which support proactive decision making, and their interaction with statistical techniques. Following this introduction, Section 2 points out the main motivation and provides an overview of the C-INCAMI framework and the SDSPbMM approach. Section 3 illus- trates the outpatient monitoring scenario, and Section 4 discusses the planning of the study and the analysis of results related to the simulation. Section 5 analyzes the contributions of this research regarding related work and, finally, Section 6 draws the main conclusions and out- lines future work. 2. Fundamentals of SDSPbMM 2.1. Motivation The SDSPbMM [4] approach proposes a flexible frame- work in which co-operative processes and components are specialized for data stream management with the ul- timate aim of having proactive decision making. In this sense, SDSPbMM allows the automation of data collec- tion and adaptation processes supporting also the incur- poration of heterogeneous data sources; the correction and analysis processes supporting the early detection of problems typical of data such as missing values, outliers, etc.; and online decision-making processes based on for- mal definitio ns of M &E projects, a nd current/updated cla - ssifiers (see Figure 2, which depicts a view of the SD SPbMM approach). For instance, to deal with detection, correction and ana- lysis processes, our proposal uses in online form, statis- tical techniques such as descriptive analysis, correlation analysis and principal co mponent analysis. In addition to these techniques other statistical techniques are used to initially validate the work. In a nutshell, we performed a simulation using a prototype developed for outpatient mo- nitoring scenario, in order to analyze empirically proc- essing times and variab le scalability, which shed lig ht on the feasibility of applying the pr o totype in real situations. Before going through the simulation and statistical ana- lysis issues, it is necessary to illustrate the main aspects of the C-INCAMI framework, which is a key part to the SDSPbMM approach. 2.2. C-INCAMI Overview C-INCAMI is a conceptual framework [2,3], which de- fines the concepts and their related components for the M&E area in software organizations. It provides a domain (ontological) model defining all the terms, properties, and relationships needed to design and implement M&E pro- cesses. It is an approach in which the requirements speci- fication, M&E design, and analysis of results are designed to satisfy a specific information need in a given context. In C-INCAMI, concepts and relationships are meant to be used along all the M&E activities. This way, a com- mon understanding of data and metadata is shared among the organization’s projects lending to more consistent analysis and results across projects. The SDSPbMM approach reuses totally the C-INCAMI conceptual base, in order to obtain a repeatable and con- sistent data stream processing where raw data usually is coming from data sources as sensors. While C-INCAMI was initially developed for software applications, the in- vol ved concept s such as metri c, measure ment method, scale, scale type, indicator, elementary function, decision crite- rion, etc., are semantically the same when applied to other domains, as it is the case when applied to the outpatient monitoring system for the healthcare domain. The C-INCAMI framework is structured in six com- ponents, namely: 1) M&E project definitio n, 2) Nonfunc- tional requirements specification, 3) Context specifica- tion, 4) Measurement design and implementation, 5) Eva- luation design and implementation, and 6) Analysis and recommendation specificatio n. The components are supported by ontological terms de- fined in [3]. The M &E project definition component (not shown in Figure 1), defines and relates a set of project concepts needed to deal with M&E activities, roles and artifacts. It allows defining the ter ms for a requirements project, and Cop yright © 2011 Sci Res. JSEA 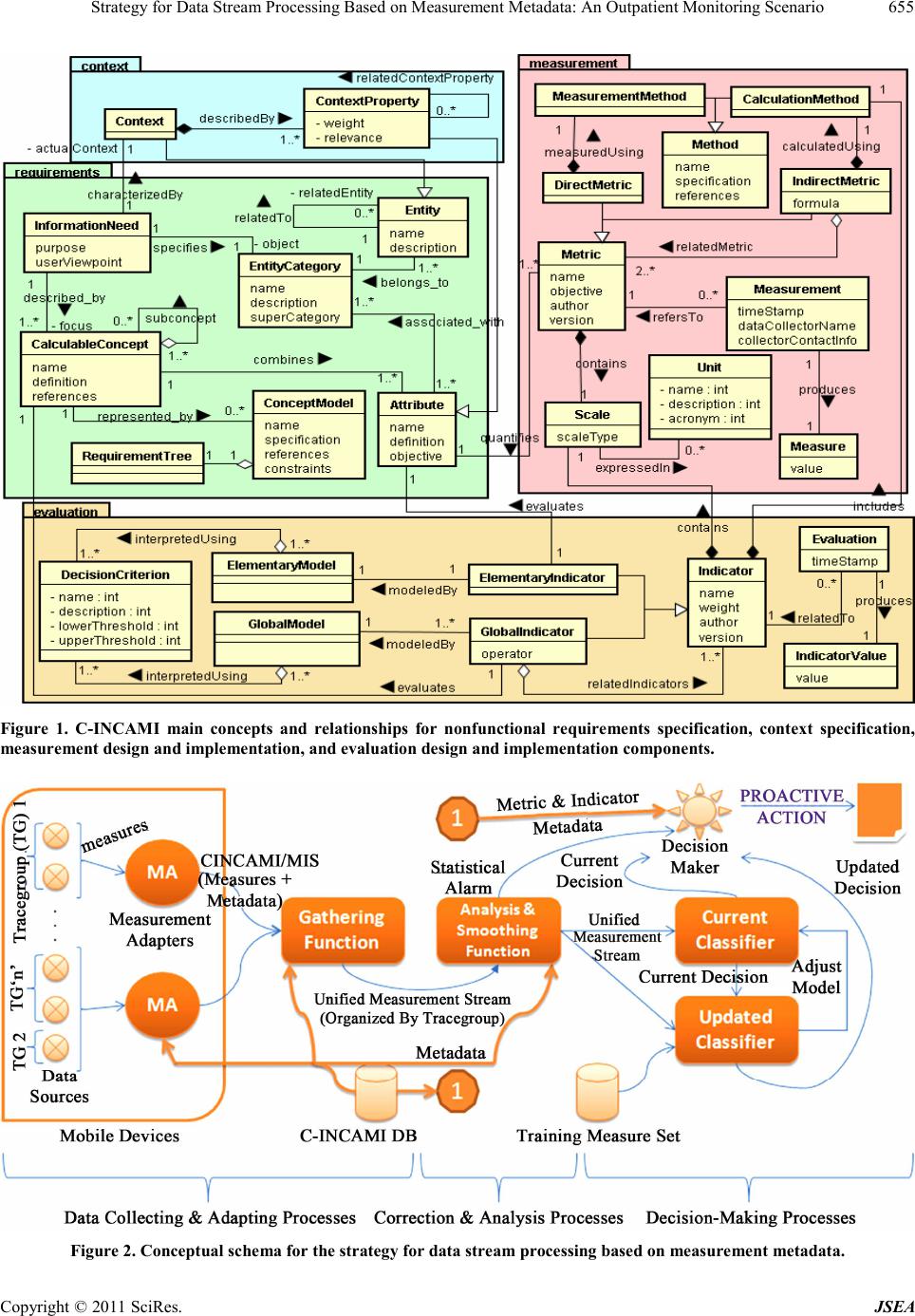 Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario Cop yright © 2011 Sci Res. JSEA 655 Figure 1. C-INCAMI main concepts and relationships for nonfunctional requirements specification, context specification, measurement design and implementation, and evaluation design and implementation components. Figure 2. Conceptual schema for the strategy for data stream processing based on measurement metadata.  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario 656 its associated measurement and evaluation sub-projects. The Nonfunctional requirements specification compo- nent (requirements package in Figure 1) allows specify- ing the Information Need of any M&E project. The in- formation need identifies the purpose (e.g. “understand”, “predict”, “monitor”, etc.) and the user viewpoint (e.g. “patient”, “final user”, etc); in turn, it focuses on a Cal- culable Concept—e.g. software quality, quality of vital signs, etc. and specifies the Entity Category to evaluate —e.g. a resource, a product, etc. A calculable concept can be defined as an abstract relationship between attrib- utes of an entity and a given information need. This can be represented by a Concept Model where the leaves of an instantiated model are Attributes. Attributes can be mea- sured by met rics . For the Context Specification component (context pack- age in Figure 1), o ne concep t i s Context, which represents the relevant state of the situation of the entity to be as- sessed with regard to the information need. We consider Context as a special kind of Entity in which related rele- vant entities are involved. To describe the context, attrib- utes of the relevant entities are used—which are also At- tributes called Context Properties (see [2] for details). The Measurement Design and Implementation com- ponent (measurement package in Figure 1), includes the concepts and relationships intended to specify the meas- urement design and implementation. Regarding measure- ment design, a Metric provides a Measurement speci- fication of how to quantify a particular attribute of an entity, u s ing a part i cular Method, and how to represent its values, using a particular Scale. The properties of the measured values in the scale with regard to the allowed mathematical and statistical operations and analysis are given by t he scale Type. Two types of metrics are distinguished. Direct Metric is that for which values are obtained directly from meas- uring the corre spondi ng entit y’s a ttrib ute, b y using a Mea- surement Method. On the other hand, the Indirect Metric value is calculated from other direct metrics’ values fol- lowing a function specification and a particular Calcula- tion Method. For measurement implementation, a Meas- urement specifies the activity by using a particular metric description in order to produce a Measure value. Other associated metadata is the data collector name and the timestamp in which the measurement was performed. The Evaluation Design and Implementation compo- nent (evaluation package in Figure 1) includes the con- cepts and relationships intended to specify the evaluation desig n and imple mentatio n. It is worthy to mentio n that the selected metrics are useful for a measurement process as long as the selected indicators are useful for an evaluation process in order to interpret the stated information need. Indicator is the main term, and there are two types of in- dicators. First, Elementary Indicator that evaluates at- tributes combined in a concept model. Each elementary indicator has an Elementary Model that provides a map- ping function from the metric’s measures (the domain) to the indicator’s scale (the range). The new scale is inter- preted using agreed decision criteria, which help analyze the level of satisfaction reached by each elementary non- functional requirement, i.e. by each attribute. Second, Par- tial/Global Indicator, whic h eval ua tes mid - le vel and hi gher - level r eq ui re me nts , i.e. sub-characteristics and characteris- tics in a concept model. Different aggregation models (Global Model) can be used to perform evaluations. The global indicator’s value ultimately represents the global degree of satisfaction in meeting the stated information need for a given purpose and user viewpoint. As for the implementation, an Evaluation represents the activity in- volving a single calculation, following a particular indi- cator specification—either elementary or global-, produ- cing an Indicator Value. The Analysis and Recommendation Specification com- ponent (not shown in Figure 1), includes concepts and rela tions hip s dea ling with a na l ysis de sign a nd i mpl eme n- tation as well as conclusio n and recommendation. Analy- sis and recommendation use information coming from each M&E project, which includes requirements, context, mea- surement and evaluation data and metadata. By process- ing all this information and by using different kinds of statistical techniques and visualization tools, stakeholders can analyze the assessed entities’ strengths and weaknesses with regard to established information needs, and justify recommendations and ultimately decision making in a consis t ent wa y. Considering the SDSPbMM strategy and its developed prototype, streams coming from data sources (i.e. us uall y sensors) are structured incorporating to measures the me- tadata based on C-INCAMI such as the entity being mea- sured, the attribute and its corresponding metric, the trace group, among others. For a given data stream, not only measures associated to metrics of attributes are tagged but also measures associated accordingly to contextual properties as well. Thanks to each M&E project specification is based on C-INCAMI, the processing of tagged data streams are then in alignment with the project objective and informa- tion need, allowing thus traceability and consistency by supporting a clear separation of concerns. For instance, for a given project—more than one can be running at the same time—it is easy to identify whether a measure is coming from an attribute or from a contextual property, and also its associated scale type and unit. Therefore, the statistical analysis is benefited because the verification of each measure for consistency against its formal (metric) definition can be performed. Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario657 2.3. SDSPbMM Overview Data collecting and adapting processes deal with how to adapt different measurement devices to collect measures and then communicate them to correction and analysis processes. The main components (see Figure 2) are data sources, measurement adapters and the gathering function. The underlying idea of the SDSPbMM approach [4] is depicted in Figure 2. Briefly, the measurement stream is informed by each heterogeneous data source to the measurement adapter (MA). The MA incorporates the metadata (e.g. metric ID, context property ID, etc.) associated to each data source into the stream, in order to transmit measurements to the gathering function (GF). Such measurements are organ- ized in GF by their metadata and then sent to the Analysis & Smoothing Function (ASF). ASF perfor ms a set of sta - tis ti cal an alys is on th e st re am in o rd er t o de tect dev iat i ons or problems with data, considering its formal definition (as per C-INCAMI DB). In turn, the incremental classifiers (i.e. the current and updated classifiers) analyze the arri- vei ng mea sur eme nts and act a cco rdin gly tr igger in g alar ms in case a risk situation arises. SDSPbMM is made up of the following processes: 1) Data Collecting and Adapting Processes; 2) Correction and Analysis Processes; and 3) Decision-Making Proc- esses, which are summarized below. 2.3.1. Data Collecting and Adapting Processes The data collecting and adapting processes deal with how to adapt different measurement device s to collect measures and then communicate them to correction and analysis pro- cesses. T he mai n compon ents (see Figure 2) are data sour- ces, measurement adapters and the gathering function. In short, measures are generated in the heterogeneous data sources, and sent continuously to the MA. MA can usually be embedded in mobile devices, but also can be embedded i n any co mputin g device asso ciated to data sour - ces. It incorporates the measured values join to the M&E project metadata respectively, sending in turn both to the GF. GF introduces streams into a buffer (see Figure 3) or- ganized by trace groups—a flexible way to group data sources established dynamically by the M&E project di- rector. This organization allows consistent statistical ana- lysis at trace group level, without representing an addi- tional processing load. Within each trace group, as shown in Figure 3, the organization of measurements is tracked by metric. This fosters a consistent analysis among dif- ferent attributes (e.g. axillary temperature, cardiac fre- quency, etc.), which are monitored by a given trace group for a particular patient. Also, homogeneous comparisons of attributes can be made for different trace groups (or patients). Figure 2. A view of the multilevel buffer. Moreover, GF incorporates load shedding techniques [6], which allow managing the queue of services associ- ated to measurements, thus mitigating overflow risks re- gardless of how they are grouped. 2.3.2. Correction and Analysis Processes The correction process is based on statistical techniques where data and their a ssociated metadata allo w richer (se- mantic) analysis. The semantic lies in the formal definition of each M&E project regarding the C-INCAMI concep- tual framework (introduced in sub Section 2.2). It is important to remark that the formal definition of each project is made by experts. In this way, such a defi- nition becomes a reference pattern in order to determine if a particular measure (value) is coherent and consistent with regard to its associated metric specification. Once the measures are organized in the buffer, the SDSPbMM prototype applies descriptive, correlation and principal components analysis. These t e ch ni ques allow de- tecting inconsistent situations, trends, correlations, and/or identifying system components that incorporate more va- riability. If some situation is detected in ASF (see Figure 2), a statistical alarm is triggered to the decision maker (DM) component in order to evaluate whether it is nec- essary to send an external alarm (via e-mail, SMS, etc.) for reporting on this situation to medical staff or not. 2.3.3. Decision-Making Processes Once the statistical analysis was performed, the unified streams are communicated to the current classifier (CC) component, which classifies measurements to decide whe- ther they correspond to a risk situation or not and report accordingly such decision to DM. Simultaneously, CC is regenerated by incorporating the unified streams to the training measure set, and then producing a new model named Updated Classifier (UC) in Figure 2. Later, the UC classifies the unified streams and pro- duces an updated decision notifying to DM. Ultimately, DM evaluates if both decisions (from CC and UC) cor- respond to a risk situation and its probability of occurrence. Finally, regardless the selected decision made by DM, the UC becomes the CC replacing the previous one (see the adjust model arrow in Figure 2), only if an impro- Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario Cop yright © 2011 Sci Res. JSEA 658 vement in the classification capacity according to the ad- justment model based on ROC (Receiver Operating Cha- racteristic) [7] curves exists. Hence, CINCAMI/MIS is a schema—based on the C- INCAMI conceptual base as discussed in subsection 2.2-, which cope with interoperability issues in the provision of data from hetero geneo us devic es, and their furthe r orga ni- zation. 2.3.4. Contribution of Metadata to the Measurement Process In Figure 4 an annotated schema of a C-INCAMI/MIS stream is presented. For each sent stream, MA incorpo- rates to the raw data—e.g. the value 80—the structure of C-INCAMI/MIS schema, indicating the correspondence of each measure with each attribute and contextual prop- erty. For instance, in the message of Figure 4, IDEntity = 1 represents the outpatient entity, IDMetric = 2 the metric value of cardiac frequency, and IDProperty = 5 the met- ric value of environmental humidity percentage, in the pa- tient location—representing a contextual property. Thus, the metadata in the message clearly includes a set of in- formation which allows keeping a link between a meas- ure value a nd th e ori gin o f d at a to id en ti fy the data so urce, the metric and entity ID, among others. This information allows increasing the consistency in the processing model for each M&E project definition. In this subsection the added value of metadata for data interoperability, consistency and processability is addressed. Recall that measures are sent from heterogeneous data sources to the GF component through MA. When MA receives data streams from each data source, incorporates metadata accordingly to a common stream-independent- tly that measures come from several data sources- and transmit it by means of the C-INCAMI/MIS (Measure- ment Interchange Schema) [4] schema t o the GF co mpo- nen t. Th us, pr evio us to se ndin g measure s, ea ch d ata so urce must configure just once each metric that quantifies each attribute (e.g. the cardiac frequency attribute) of the en- tity under assessment (e.g. an outpatient), and the in- cluding contextual properties (e.g. environmental tempe- rature) of the situation. This al lows MA be aware of how such metadata should be embedde d into the stream. Figure 3. Annotated XML (Extended Markup Language) schema of a C-INCAMI/MIS stream.  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario659 Let’s suppose, for example, a value of 80 associated to a cardiac frequency of an outpatient arrived; then, the fo- llowing basic questions can be raised: What does it re- present? W hich unit of measu re do es it have? W hich ma- thematical and statistical properties have the value regar- ng the scale type? Is it good or bad? What is good and what is bad, i.e. what are the decision criteria? Could any software process t he mea sure? Therefore, if the stream metadata were not available, many questions as those could not be answered in a con- sistent way. Even more, the processability of measures can be hampered and the analysis be skewed. 3. Outpatient Monitoring Scenario In this section, we illustrate the formal definition of a M&E project for outpatient monitoring, and some as- pects of its implementation as well. In the M&E project defi nitio n, t he kno wledge of e xper ts (e .g. d oct ors) is a va- luable asset. 3.1. Definition The present scenario aims at illustrating the SDSPbMM approach. The underl ying hypothesis is doctors of a health - care centre could avoid adverse reactions and major da- mage in the health of patients (particularly, outpatients) if the y ha d a c ontin uo us mo ni t or ing ove r t hem. That is to say, doctors should have a mechanism by which can be informed about unexpected variations and/or inconsis- tencies in health indicators defined by them (as experts). So, the core idea is that there exists some proactive me- chanism based on health metrics and indicators that pro- duces an on-line report (alarm) for each risk situation as- sociated to the outpatient under monitoring. Considering C-INCAMI, the information need is “to monitor the principal vital signs of an outpatient when he/she is given the medical discharge from the health- care centre”. The entity under analysis is the outpatient. According to medical experts, the corporal temperature, the systolic arterial pressure (maximum), the diastolic arterial pressure (minimum) and the cardiac frequency represent the relevant attributes of the outpatient vital signs to monitor. They also consider as necessary moni- toring the environmental temperature, environmental pres- sure, hu midity, and patien t position (i.e. latitude and lon- gitude) contextual properties. The definition of the infor - mation need, the entity, its associated attributes and the context are part of the “Nonfunctional requirements speci- fication” and “Context specification” components as dis- cussed in sub-Section 2.2. The quantification of attributes and contextual proper- ties is performed by metrics as shown in the Measure- ment Design and Implementation component in Figure 1. For monitoring purposes, the metrics that quantify the cited attributes, were selected from the C-INCAMI DB repository; likewise the metrics that quantify the cited con- textual properties. Figure 5 shows the specification of the metric for environmental temperature contextual pro- perty. After the set of metrics and contextual properties for outpatient monitoring has been selected, the correspond- ing elementary indicators for interpretation purposes (as discussed in sub-Section 2.2) have also to be selected by experts. In this way, they have included the following elementar y indicators: level of corporal temperature, level of pressure, level of cardiac frequency and level of dif- ference between the corporal and the environmental tem- perature. The concepts related to indicators are part of the Evaluation Design and Implementation component (see Figure 1). Figure 6 shows the specification of the level of corpo- ral temperature elementary indicator. For example, the different acceptability levels with their interpretations are shown, among other metadata. Besides, considering that ranges of the acceptability levels (shown in Figure 6) are in a categorical scale (i.e. an ordinal scale type), then the target variable for the mining function (classification) is also categorical. So, the classifiers both CC and UC, act relying on the values of the given indicators and their ac- ceptability levels. 3.2. Implementation Issues Once all the above project information was established, it is necessary for implementation issues to choose a con- crete architecture to deploy the system. Figure 7 depicts an abridged deployment view for the outpatient moni- toring system considering the SDSPbMM approach. Let’s suppose we install and set up the MA in a mobile device—the outpatient device-, which will work in con- junction with sensors as shown in Figure 7. Therefore, Figure 5. Metric definition for the environmental tempera- ture contextual property . Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario 660 Figure 6. Details of the level of corporal temperature ele- mentary indicator specification. while the data collecting and adapting processes are im- plemented in a mobile device by the MA, the gathering function and other processes can reside in the healthcare center computer. The M A co mponent, using web services , informs the measures (streams) to the gathering function (GF) in an asynchronous and continuous way. MA takes the measures from sensors—the data sources- and incur- porates the associated metric metadata for attributes and contextual properties accordingly. For instance, it incur- porates the contextual property ID for the environmental temperature (VTAPT, in Figure 5) joint to the value to transmit; and so for every attribute and contextual prop- erty. Note that data (values) and metadata are transmitted through the C-INCAMI/MIS schema to the gathering function (GF), as discussed in sub-Section 2.3.4. When the gathering function receives measures from several outpatients under monitoring it arranges them, for insta nce, by patient (i. e. the trace group) and transmits them to the analysis and correction processes. As discussed in subSection 2.3.2, ASF mainly solves typical problems of data such as missing values, noises, among others. For example, and thanks to metadata, if ASF receives for the Value of axillary temperature metric a zero value, by the metric definition the processing model identifies an er- ror because the scale is numeric (in interval scale type), Figure 7 . A depl oyme nt view f or the O utpatient Monitoring System. Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario661 continuous, and defined in the interval of positive real numbers. Although all the values of metrics and contextual pro- perties from monitored o utpatients are si multa neousl y re- ceived and analyzed, let’s consider for a while, for illu- stration purpose, that the system only receives data for the axillary temperature attribute and the environmental temperature contextual property from one outpatient, and that also the system visualizes them. As depicted in Fig- ure 8, the lower and upper limit defined for the level of (axillary temperature) corporal temperature indicator to- gether with the evolution of the environmental tempera- ture and the axillary temperature can be tracked. The measures and, ultimately, the acceptability level achieved by the level of corporal temperature elementary indicator ( see Figure 8) indica te a normal situatio n for the patient. Nevertheless, the on-line decision-making process, apart from analyzing for attributes the level of accept- ability met also analyzes the interaction with contextual properties and their values. This analysis allows detect- ing a situation like that exposed in Figures 9(a) and (b). At first glance, what seemed to be normal and evident, it was probably not because in a proactive form the pro- cessing model has detected a correlation between axillary temperature and environmental temperature as shown in Figure 9(b). This could cause the triggering of a preven- tive alarm from the healthcare centre to doctors, because the increment on the environmental temperature can drag in turn the increment in the corporal temperature, and therefore this situation can be associated to a gradual rais e in the risk probability for the outpatient. 4. Scenario Simulation 4.1. Goal The developed prototype for the SDSPbMM approach im- plements functionalities (see Figure 2) ranging from the Figure 8. Visualization of the evolution of axillary tempera- ture versus e nvironmental temperature measu res. (a) (b) Figure 9. (a) Correlation Analysis for the axillary tempera- ture versus the enviro nmental temperature; (b) Correlati on Matrix. formal definition of the M&E project including the C- INCAMI repository with metadata, the integration of he- terogeneous data sources, trace groups and MA, to clas- sifiers for on-line decision-making process. In addition, it implemen ts the C- INCAMI/M IS schema for the inte rch an ge of measures in an interoperable way, and the multilevel buffer based on metadata (see Figure 3). The prototype has been implemented in JAVA, using R [8] as statistical calculus engine, and the CRAN (Com- prehensive R Archive Network) Rserve mechanism to access TCP/IP from the streaming application to the R engine, without requiring persistence and prioritizing the direct communication. The simulation goal is to determine the processing times involved in the outpatient scenario and the variable scal- ability. This simulation can allow us analyzing the feasi- bility of applying the prototype to real situations. Fur- thermore, we discuss statistically the results of the simu- lation, in order to detect the components which incorpo- rate more variability to the system. 4.2. Si m ul atio n Plan ning an d Ex e c ut i on The simulation has been performed from the illustrated scenario in Section 3. The measurement data have been generated in a pseudo-random way considering two pa- rameters: quantity of metrics (in a simulation each metric corresponds to a variable), and quantity of measurements by variable. Each patient has 8 associated metrics pertain- ing to attributes and contextual properties as commented in sub-Section 3.1. The simulation discretely varied the quantity of vari- ables (metrics) into the data stream from 3 to 99, and the quantity of measurements by variable from 100 to 1000. Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario 662 The idea of discretely vary the quantity of metrics instead of doing it as a multiple of 8—i.e. based on the 8 ones associated per each patient-, lies in analyzing the proto- type behavior in presence of missing values and the pro- gressive reincorporation of measures to the stream. The prototype, R and Rserve were running in a PC equipped with AMD Athlon × 2 64 bits processor, 3 GB of RAM, and Windows Vista Home Premium as operat- ing syste m. For the simulation, the following variables which are the target of measurement considering the stream as the entity under a nalysis have been define d, namely: Startup: the necessary time (in ms) to start up the functio ns of the ana lysis AnDesc: the necessary time (ms) to make the de- scriptive analysis on the complete data stream Cor: the necessary time (ms) to make the correla- tion analysis by trace group inside the complete data stream Pca: the necessary time (ms) to make the principal component analysis by trace group inside the complete data stream Tota l: the necessary time (ms) to make all the ana- lysis on the complete data stream The simulation parameters used for the statistical ana- lysis of results are represented by qVar, to indicate the quantity of variables of the data stream; and by meds, to indicate the quantity of measures by variable of the data stream. From now onwards, in order to simplify the reading of the statistical analysis, the parameters qVar and meds will be directly referred to as variables, and Startup, An- desc, Cor, Pca and Total will be called variables as well. From the simulation process standpoint, we have ob- tained 1390 measurements over the overall processing time in relation to the evolution of the quantity of vari- ables and measurements. This allows us to statistically arr ive at verif iable results that he lp us conseque ntly vali - dating the prototype in a controlled environment. 4.3. Analysis of Results The chart in Fig ure 10(b) clea rly shows us how the evolu- tion of quantity of var iables affects significantly the over- all processing time o f data streams, incrementin g according to the values shown in chart (a). Here, we can observe that the increment in the processing time produced by the in- crease of measurements is extremely low in compareson with the one produced by the increase of variables. This latter aspect indicates that the load shedding mechanism really achieved the goal of avoiding overflows without affecting the time of stream processing against the varia- tion of the s tream vol ume. Wh ile the i ncorporatio n of ne w variables does influence because besides the stream vo- lume by adding a new variable, there exists also the in- teraction with the preexistent variables, being this the cause Figure 10. Two views of the evolution of overall processing time (ms) against the evolution of the quantity of variables and meas urements . and main difference in terms of the processing time with respect to the increase produced by measurements. In both disper sion char ts, (a) and (b), eac h point is rep - resented with a color that is associated with the quantity of variables. This allows us to identify regions in the graph in a graceful way and to compare them from both per- spectives. In chart (b), we can observe that the overall pro- cessing time keeps a linear rel ation according to the quan- tity of variables. Considering suc h a situation, and on the basis that the statistical analyzer (ASF in Figure 2) per- forms a series of analysis on the data stream, we have studied the incidence of each analysis in the overall pro- cessing time, in order to detect which of them are more critical in temporary terms. The Pearson’s correlation matrix shown in Figure 11(a) would confirm, firstly, the linear relationship indicated between the quantity of variables (qVar) and the overall processing time of the data stream (Total) given the co e f - ficient value of 0.95. Secondly, it can be concluded that the overall processing time would keep a strong linear relationship with respect to the time of the descriptive analysis with a coefficient of 0.99, followed up by the time of Pca with 0.9, and Cor with 0.89 respectively. The resulting matrixes of the principal component ana- lysis—shown in Figures 11(b) and (c) reveal which of the variables provide more variability to the system. Thus, the first autovalue (row 1, Figure 11(b)) explains the 66% of Cop yright © 2011 Sci Res. JSEA 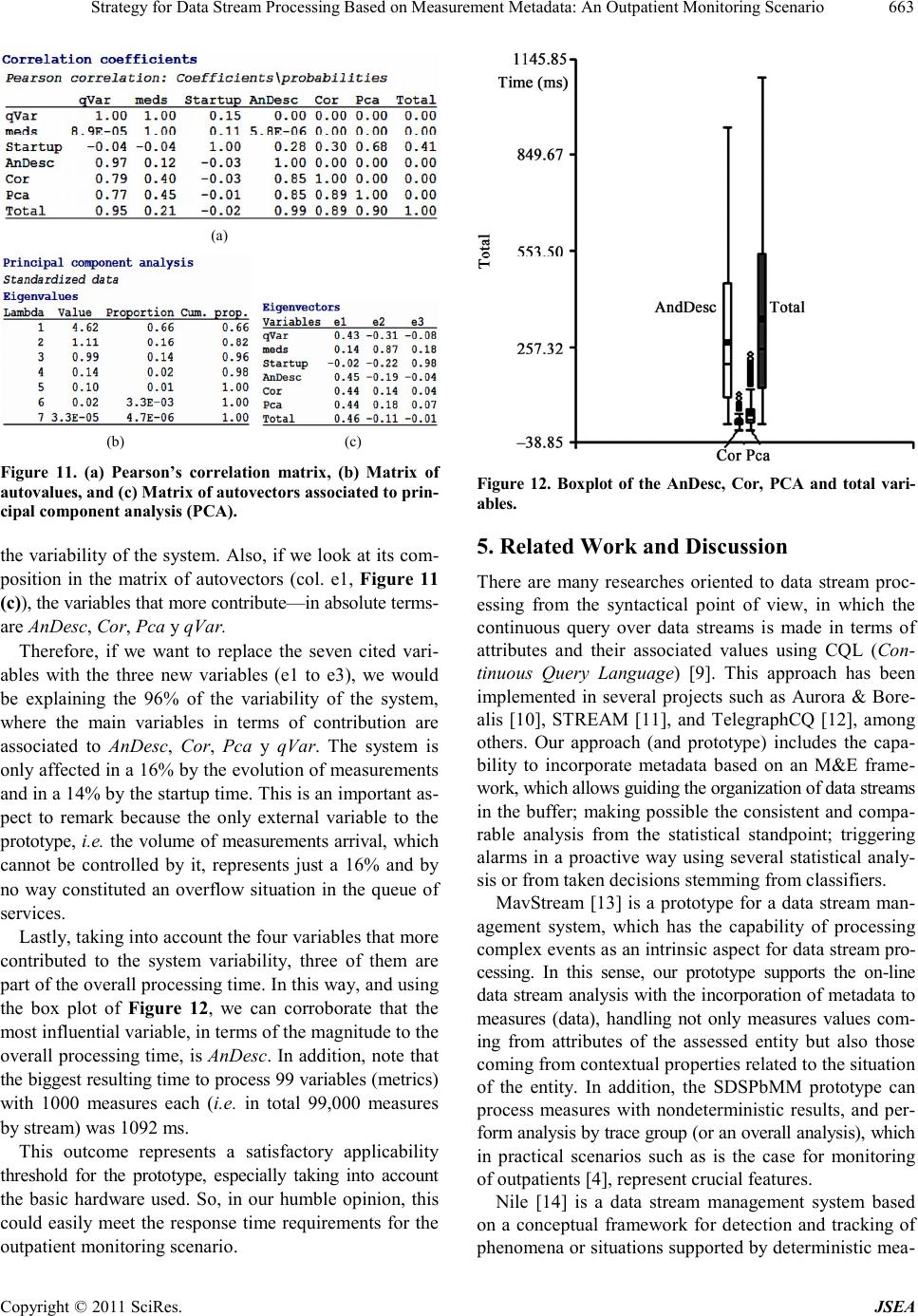 Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario663 (a) (b) (c) Figure 11. (a) Pearson’s correlation matrix, (b) Matrix of autov alues, and (c) Matri x of autovectors ass ociated to prin- cipal component analysis (PCA). the variability of the system. Also, if we look at its com- position in the matrix of autovectors (col. e1, Figure 11 (c)), the variables that more contribute—in absolute terms- are AnDesc, Cor, Pca y qVar. Therefore, if we want to replace the seven cited vari- ables with the three new variables (e1 to e3), we would be explaining the 96% of the variability of the system, where the main variables in terms of contribution are associated to AnDesc, Cor, Pca y qVar. The system is only affected in a 16% by the evolution of measurements and in a 14% by the startup time. This is an important as- pect to remark because the only external variable to the prototype, i.e. the volume of measurements arrival, which cannot be controlled by it, represents just a 16% and by no way constituted an overflow situation in the queue of services. Lastly, taking into account the four variables that more contributed to the system variability, three of them are part of the overall processing time. In this way, and using the box plot of Figure 12, we can corroborate that the most influential variable, in terms of the magnitude to the overall processing time, is AnDesc. In addition, note that the biggest resulti ng time to process 99 variables ( metrics) with 1000 measures each (i.e. in total 99,000 measures by stream) was 1092 ms. This outcome represents a satisfactory applicability threshold for the prototype, especially taking into account the basic hardware used. So, in our humble opinion, this could easily meet the response time requirements for the outpatient monitoring scenario. Figure 12. Boxplot of the AnDesc, Cor, PCA and total vari- ables . 5. Related Work and Discussion There are many researches oriented to data stream proc- essing from the syntactical point of view, in which the continuous query over data streams is made in terms of attributes and their associated values using CQL (Con- tinuous Query Language) [9]. This approach has been implemented in several projects such as Aurora & Bore- alis [10], STREAM [11], and TelegraphCQ [12], among others. Our approach (and prototype) includes the capa- bility to incorporate metadata based on an M&E frame- work, w h ich allows gu iding th e or gani zation of d at a stre ams in the buffer; making possible the consistent and compa- rable analysis from the statistical standpoint; triggering alarms in a proactive way using several statistical analy- sis or fr om take n decisions stemming from clas sifiers. MavStream [13] is a prototype for a data stream man- agement system, which has the capability of processing complex events as an intrinsic aspect for data stream pro- cessing. In this sense, our prototype supports the on-line data stream analysis with the incorporation of metadata to measures (data), handling not only measures values com- ing from attributes of the assessed entity but also those coming from contextual properties related to the situation of the entity. In addition, the SDSPbMM prototype can process measures with nondeterministic results, and per- form analysis by trace group (or an overall analysis), which in practical scenarios such as is the case for monitoring of outpatients [4], represent crucial features. Nile [14] is a data stream management system based on a conceptual framework for detection and tracking of phenomena or situations supported by deterministic mea- Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario 664 sures. Our prototype unlike Nile, allows the incorpora- tion of heterogeneous data sources embracing not only deterministic but also nondeterministic measures. On the other hand , Sin gh et al. [15] introduce a system architect- ture for a formal framework of data mining oriented to the situation presented in [16]. This system is used in medical wireless applications and shows how the archi- tecture can be applied to several medical areas such as diabetes treatment and risk monitoring of heart disease. In our humble opinion, this system neglects central issues for assuring repeatability and interoperability because it lacks a clear specification of metrics both for entity at- tributes and contextual properties, indicators, scales and scale types, among other metadata. Lastly, Huang et al. [17] present an approach based on self-managed reports for tracking of patients. Such re- ports are made up of a set of questionnaire items with numeric (scale) responses, which are filled in by patients at home. The patient’s responses feed a classification mo- del based on neural networks in order to progressively improve the selection of questionnaire items incorporated in the reports. Hence, they argue this decrease the pa- tients’ response time and allow identifying those aspects that will foster an improvement in their quality of life. Likewise happens in Singh et al. [15,16] proposal; this approach says nothing about how to define metrics, indi- cators, scales, and so on. Our strategy and its prototype support data stream pro- cessing in alignment with a conceptual base, i.e. the met- ric and indicator ontology [3], which guarantees not only syntactic but also semantic processing, in addition to interoperability and consiste ncy. 6. Conclusions and Future Work In this work, we have discussed how the presence of me- tadata based on the C-INCAMI M&E framework linked to measures in data streams, allows the organization of measurements which foster the consistency for statistical analysis, since they specify not only the formal compo- nents of data but also the associated context. Hence, it is possible to perform particular analysis at trace group or at a m ore ge n eral level , compari n g v al u es of m et rics among different trace groups in order to identify, for example, deviations of measures against their formal definition; the main system variability factor s, as well as relations a mong variables. In the outpatient monitoring scenario introduced in Section 3, we have shown in Figures 8 and 9 the relation- ships between the data/metadata of metrics—i.e. metrics that quantify contextual properties and attributes- and the statistical analysis, considering our data stream process- ing strategy. In this sense, even when the measures seemed to have normal values, the data and metadata of metrics in conjunction with the correlation analysis allowed iden- tifying a drag situation and then triggering alarms to pre- vent it. Moreover, such metadata allowed identifying va- riability factors and detecting trends in a consistent way considering the contextual situation as well. Using the developed prototype which implements the SDSPb MM strat egy, we have demonstr ated fr om the sta- tistical analysis viewpoint of the simulation outcomes that the prototype is more susceptible, in terms of processing time, to the increase of the quantity of variables than to the increase of the quantity of measurements by variable. Using the principal components analysis technique, we have proved that the aspects that more contribute to the system variability are those associated to the Andesc, Cor, Pca and qVar variables, being Andesc the one that de- fines the biggest proportion of the final processing time of data streams. Taking into account that the implemented prototype ran in a system which is totally accessible in the market, we could establish as a benchmark that to process 99,000 measurements (99 variables and 1000 measures/variable), the biggest time spent was 1092 ms. This is an important starting point since now we can consistently evaluate se- veral application scenarios against this benchmark. On the other hand, the effectiveness of the load shedding me- chanism in the multilevel buffer was also proved statisti- cally, coming up that the evolution of the quantity of mea- surements does not compromise the prototype operation and the final processing time of the data stream has not been affected. Although the present work is just a simulation of the outpatient monitoring scenario by means of a prototypi- cal software application, we have initially proved that it can scale up to a real scenario. As a future work, we also plan to experimentally test our data stream processing strategy enriched with context, measurement and evalua- tion metadata on several scenarios in or der to statistically validate the initial benchmark obtained for the outpatient monitoring scenario. 7. Acknowledgements This research is supported by the PICT 2188 project from the Science and Technology Agency and by the 09/F052 project from the UNLPam, Argentina. REFERENCES [1] J. Namit, J. Gehrke and H. Balakrishan, “Towards a Streaming SQL Standard,” Proceedings of the VLDB En- dowment, Vol. 1, No. 2, 2008, pp. 1379-1390. [2] H. Molina and L. Olsina, “Towards the Support of Con- textual Information to a Measurement and Evaluation Fram ework , ” International Conference on Quality of Infor- mation and Communications Technology, Lisbon, 12-14 Cop yright © 2011 Sci Res. JSEA  Strategy for Data Stream Processing Based on Measurement Metadata: An Outpatient Monitoring Scenario Cop yright © 2011 Sci Res. JSEA 665 Septem be r 2007, pp. 1 54-166. [3] L. Olsina, F. Papa and H. Molina, “How to Measure and Evaluate Web Applications in a Consistent Way,” In: G. Ros si, O. Pastor, D. Schwabe and L. Olsina, Eds., Web En- gineering: Modelling and Implementing Web Applica- tions, Sprin ger Book, London , 2008, pp. 385-420. [4] M. Diván and L. Olsina, “Integrated Strategy for the Data Stream Processing: A Scenario of Use,” Proceeding of Iberoamerican Conference in “Software Engineering”, Me- dellín, 2009, pp. 374-387. [5] M. Diván, L. Olsina and S. Gordillo, “Data Stream Proc- essing Enriched with Measurement Metadata: A Statisti- cal Analysis,” Proceeding of Iberoamerican Conference in “Software Engineering” (CIbSE), Rio de Janeiro, 2011, p. 29. [6] M. Wei, W. Rundensteiner and M. Mani, “Utility-Driven Load Shedding for XML Stream Processing,” Interna- tional Conference on World Wide Web, Beijing, 21-25 April 2008, pp. 855-864. [7] C. Marrocco, R. Duin and F. Tortorella, “Maximizing the Area under the ROC Curve by Pairwise Feature Combi- nation,” ACM Pattern Recognition, Vol. 41, No. 6, 2008, pp. 1961 -1974. doi:10.1016/j.patcog.2007.11.017 [8] R. Software Foundation, “The R Foundation for Statisti- cal Computing,” 2010. http://www.r-project.org/foundation/ [9] S. Babu and J. Widom, “Continuous Queries over Data Streams,” ACM SIGMOD Record, Vol. 30, No. 3, 2001, pp. 109- 120. doi:10.1145/603867.603884 [10] D. Abadi, Y. Ahmad, M. Balazinska, U. Cetintemel, M. Cherniack, J. Hwang, W. Lindner, A. Maskey, A. Rasin, E. Ryvkina, N. Tatbul, Y. Xing and S. Zdonik, “The De- sign of the Borealis Stream Processing Engine,” Confer- ence on Innovative Data Systems Research (CIDR), Asi- lomar, 2005, pp. 277-289. [11] The Stream Group, “STREAM: The Stanford Stream Data Manager ,” Sta nfor d, 2003. [12] S. Krishnamurthy, S. Chandrasekaran, O. Cooper, A. Desh- pande, M. Franklin, J. Hellerstein, W. Hong, S. Madden, F. Reiss and M. Shah, “Telegraph CQ: An Architectural Status Report,” IEEE Data Engineering Bulletin, Vol . 26, No. 2, 2003, pp. 11-18. [13] S. Chakravarthy and Q. Jiang, “Stream Data Processing: A Quality of Service Perspective,” Springer Book, New York, 2009. [14] M. Ali, W. Aref, R. Bose, A. Elmagarmid, A. Helal, I. Kamel and M. Mokbel, “NILE-PDT: A Phenomenon De- tection and Tracking Framework for Data Stream Man- agemen t S yste ms, ” Very Large Database, Trondheim, 2005, pp. 1295-1298. [15] S. Singh, P. Vajirkar and Y. Lee, “Context-Aware Data Mining Framework for Wireless Medical Application,” LNCS of Springer, Vol. 2736, 2 0 03, pp . 381-391. [16] S. Singh, P. Vajirkar and Y. Lee, “Context-Based Data Mining Using Ontologies,” LNCS of Springer, Vol. 2813. 2003, pp. 405-418. [17] Y. Huang, H. Zheng, C. Nugent , P. McCullagh, N. Black, K. Vowles and L. McCracken, “Feature Selection and Cla- ssification in Supporting Report Based Self Management for People with Chronic Pain,” IEEE Transactions on In- formation Technology in Biomedicine, Vol. 15, No. 1, 2011, pp. 54-61.
|