Paper Menu >>
Journal Menu >>
 Wireless Sensor Network, 2009, 1, 334-339 doi:10.4236/wsn.2009.14041 Published Online November 2009 (http://www.scirp.org/journal/wsn). Copyright © 2009 SciRes. WSN Distributed Video Coding Using LDPC Codes for Wireless Video P. APARNA, Sivaprakash REDDY, Sumam DAVID* Department of Electronics and Communication Engineering, National Institute of Technology Karnataka, Surathkal, India Email: sumam@ieee.org Received May 19, 2009; revised June 16, 2009; accepted June 23, 2009 Abstract Popular video coding standards like H.264 and MPEG working on the principle of motion-compensated pre- dictive coding demand much of the computational resources at the encoder increasing its complexity. Such bulky encoders are not suitable for applications like wireless low power surveillance, multimedia sensor networks, wireless PC cameras, mobile camera phones etc. New video coding scheme based on the principle of distributed source coding is looked upon in this paper. This scheme supports a low complexity encoder, at the same time trying to achieve the rate distortion performance of conventional video codecs. Current im- plementation uses LDPC codes for syndrome coding. Keywords: Syndrome Coding, Cosets, Distributed Source Coding, Distributed Video Coding (DVC). 1. Introduction With the proliferation of various complex video applica- tions it is necessary to have advanced video and image compression techniques. Popular video standards like ISO MPEG and ITU-H.26x have been successful in accom- plishing the requirements in terms of compression effi- ciency and quality. However these standards are pertinent to downlink friendly applications like video telephony, video streaming, broadcasting etc. These conventional video codecs work on the principle of motion co mpensated prediction which increases the encoder complexity due to the coexistence of the decoder with the encoder. Also mo- tion-search algorithm makes the encoder computationally intensive. The downlink friendly architectures belong to the class of Broadcast model, where in high encoder com- plexity is not an issue. The encoder of a Broadcast model resides at the base-station where power consumption and computational resources are not an issue. However this Broadcast model of video is not suitable for uplink friendly applications like mobile video cameras, wireless video sensor networks, wireless surveillance etc which demands a low power, low complexity encoder. These uplink friendly applications which belong to wireless-video model demands a simple encoder since the power and the co mpu- tational resources are of primary concern in the wireless scenario. Based on the information theoretic b ounds estab- lished in 1970’s by Slepian-Wolf [1] for distributed lossless coding and by Wyner-Ziv [2] for lossy coding with de- coder side infor mat ion, it is s een that effi cien t co mpressio n can also be achieved by exploiting source statistics partially or wholly at the decoder. Video compression schemes that build upon these theorems are referred as distributed video coding which befits uplink friendly video applications. Distributed video coding shifts the encoder complexity to the decoder making it suitable for wireless video model. Unlike conventional video codecs distributed coding ex- ploits the source statistics at the decoder alone, thus inter- changing the traditional balance of complex encoder and simple decoder. Hence the encoder of such a video codec is very simple, at the expense of a more complex decoder. Such algorithms hold great promise for new generation mobile video cameras and wireless sensor networks. In the design of a new video coding paradigm, issues like com- pression efficiency, robustness to packet losses, encoder complexity are of prime importance in comparison with conventional coding system. In this paper we present the simulation results of distributed video coding with syn- drome coding as in PRISM [3], using LDPC codes for coset channel coding [4]. 2. Background 2.1. Slepian-Wolf Theorem for Lossless Distrib- uted Coding [1] Consider two correlated information sequences X and Y. *SMIEEE.  P. APARNA ET AL. 335 Encoder of each source is constrained to operate with- out the knowledge of the other sou rce while the de coder has access to both encoded binary message streams as shown in Figure 1. The problem that Slepian-Wolf theo rem a dd res ses is to de termi ne the mi ni mu m nu mber of bits per source character required for encoding the message stream in order to ensure accurate reconstruc- tion at the decoder. Considering separate encoder and the decoder for X and Y, the rate required is RX ≥ H(X) and RY ≥ H(Y) where H(X) and H(Y) represents the en- tropy of X and Y respectiv ely. Slepian -Wolf [1] show ed that good compression can be achieved with joint de- coding but separate encoding. For doing this an admissible rate region is defined [6] as shown in Fi gure 2 given b y: RX + RY ≥ H(X,Y) (1) RX ≥ H(X/Y), RY ≥ H(Y) (2) RX ≥ H(X), RY ≥ H(Y/X) (3) Thus Slepian-Wolf [1] sh owed that Equation (1) is th e necessary condition and Equation (2) or Equation (3) are the sufficient conditions required to encode the data in case of joint decoding. With the above result as the base, we can consider the distributed coding with side infor- mation at the decoder as shown in the Figure 3. Let X be the source data that is statistically dependent to the side information Y. Side information Y is separately encoded at a rate RY ≥ H(Y) and is available only at the decoder. Thus as seen from Figure 2 X can be encoded at a rate RX ≥ H(X/Y). Figure 1. Compression of correlated sources by separate encoder but decoded jointly. Figure 2. Admissible rate region [5]. Source X/YLoss l ess Encoder Lo ssless Deco der X Side I nformationY R x H(X/Y) R Y H(Y) Figure 3. Lossless decoder with side information. 2.1. Wyner-Ziv Rate Distortion Theory[2,6] Aaron Wyner and Jacob Ziv [2,6] extended Slepian- Wolf theorem and showed that conditional Rate-MSE distortion function for X is same whether the side in- formation is available only at the decoder or both at encoder and decoder; where X and Y are statistically dependent Gaussian random processes. Let X and Y be the samples of two random sequences representing the source data and side information respectively. Encoder encodes X without access to side information Yas shown in Figure 4. Decoder reconstructs X using Y as side information. Let D = E [d ( X , X)] is the acceptab le distortion. Let RX/Y(D) be the rate required for the case where side information is available at the encoder also and represent the Wyner-Ziv rate required when encoder doesn’t have access to side information. Wyner-Ziv proved that Wyner-Ziv rate distortion function is the achievable lower bound for the bitrate for a distortion D )( /DRWZ YX )DR ( / WZ YX Correlated Sources Joint De cod Encoder X Encoder Y X Y Rx Ry er X ˆ Y ˆ 0 )()( // DRDR YX WZ YX (4) They also showed that for Gaussian memoryless sources 0)()( // DRDR YX WZ YX (5) As a result source sequence X can be considered as the sum of arbitrarily distributed side information Y and in- dependent Gaussian No ise. R y R x bit s bits H(x) H(x/y) H(y/x) H(y) Distributed video coding is based on these two funda- mental theories, specifically works on the Wyner-Ziv coding considering a distortion measure. In such a coding system the encoder encodes each video frame separately Figure 4. Lossy decoder with side information. Vani s h i ng Errors for long sequences No Errors H(x,y)=R x + R y Source X/YLossy Enco derLossy D X Side Inf (D) wz x R ecoder ormation Y X' H(Y) Y R H(X/Y) Copyright © 2009 SciRes. WSN  336 P. APARNA ET AL. Copyright © 2009 SciRes. WSN The correlation between binary sources X = [X1, X2.....,Xn] and Y = [Y1, Y2, ..., Yn] is modeled using a bi- nary symmetric channel. We consider Xi and Yi to be correlated according to Pr [Xi Yi] = p < 0.5. The rate used for Y is its entropy RY = H(Y), therefore the theo- retical limit for lossless compression of X is given by with respect to th e correlation statistics betw een itself and the side information. The decoder decodes the frames jointly using the side information available only at the decoder. This video paradigm is as opposed to the conven- tional coding system where the side information is avail- able both at the encoder and decoder as shown in Figure 5. nRx ≥ nH(Xi/Yi) = nH(p) =n(−plog2p−(1−p)log2(1−p)) 2.2. Syndrome Coding [5] (6) The compressed version of X is the syndrome S which is the input to the chann el. The source Y is assumed to b e available at the decoder as side information. Using a lin- ear (n,k) binary block code, it is possible to have 2n−k distinct syndromes, each indexing a set of 2k binary words of length n. This compression results in mapp ing a sequence of n input symbols into (n−k) syndrome sym- bols. Let X be a source that is to be transmitted using least average number of bits. Statistically dependent side in- formation Y, such that X = Y + N is available only at th e decoder. The encoder must therefore encode X in the absence of Y, whereas the decoder jointly decodes X us- ing Y. Distributed source encoder compresses X in to syndromes S with respect to a Channel code C [7]. De- coder on receiving the syndrome can identify the coset to which X belongs and using side information Y can recon- struct back X. 3. Implementation 2.3. Correlation Channel and the Channel Codes [4] 3.1. Encoder The performance of the channel codes is the key factor of the distributed video coding system in both error cor- recting and data compression. Turbo and LDPC codes are two advanced channel codes which have astonishing performance near the Shannon Capacity limit. The use of LDPC codes for syndrome coding was first suggested by Liveris in [4], where the message passing algorithm was modified to take syndrome information in to account. The encoder block diagram is shown in the Figure 6. The video frames are divided into blocks of 8x8 and each block is processed one by one. Block DCT (Discrete Cosine Transform) is applied to each 8x8 block (or 16x16) and the DCT coefficients are zig-zag scann ed so that they are arranged as an array of coefficients in or- der of their importance. Then the transformed coeffi- cients are uniform quantized with reference to target distortion measure and desired reconstruction quality. After quantization a bitplane is formed for each block as shown in Figure 7 [3]. Main idea behind distributed video coding is to code source X assuming that the side information Y is available at the decoder such that X = Y + N, where N is Gaussian random noise. This is done in the classification step where bitplane for each coeffi- cient is divided into different levels of importance. Classification step strongly rely on the correlation noise Figure 5. Lossless decoder with side information. Figure 6. Video encoder. Encod er X ˆ De co de r X Side Information Y DCT & Zigzag ScanUniform Quantization Classification Syndrome Codi ng using LDPC co de s En t ropy Coding us in g Adapt ive Huff man Codin g Bit Plan e Formation Input Block Correlat ion Noise Estimation Encode Bit S t r e da m One Frame De lay MSB LS B Class Info  P. APARNA ET AL. 337 Copyright © 2009 SciRes. WSN Figure 7. Bit planes for each coefficient blocks. structure N between the source block X and the side information block Y. Less is the correlation noise be- tween X and Y, more is the similarity and hence less number of bits of X can be transmitted to the decoder. In order to classify the bitplanes offline training is done for different types of video files without any motion search. On the basis of offline process 16 types of classes are formed, where each class considers different number of bitplanes for entropy coding and syndrome coding for each coefficient in the block. In the classifi- cation process, MSE (mean square error) for each block is computed with respect to the zero motion blocks in the previous frame. Based on the MSE and the offline process appropriate class for that particular block is chosen. As a result some of the least significant bit planes are syndrome coded and some of the bitplanes that can be reconstructed from side information are to- tally ignored. The syndrome coding bitplanes shown in black and gray in Figure 7 and skip planes shown in white in Figure 7. Skip planes can be reconstructed back using side information at the decoder and hence need not be sent to the decoder. The important bits of each coefficient that cannot be determined by side in- formation has to be syndrome coded [3]. In our imple- mentation we code two bitplanes using coset channel coding and the remaining syndrome bitplanes using Adaptive Huffman coding. Among the syndrome cod- ing bitplanes we code the most significant bit planes using Adaptive Huffman coding. The number of bit- planes to be syndrome coded is directly used from class information that is hard coded. Hence we need not send four-tuple data (run, depth, path, last) as in PRISM [3]. Rest of the least significant bitplanes is coded using coset channel coding. This is done by using a parity check matrix H of a (n,k) linear channel code. Com- pression is achieved by generating syndrome bits of length (n-k) for each n bits of data. These syndrome bits are obtained by multiplying the source bits with the parity check matrix H such that x 0 x 1 x 2 x 3 x 63 b 0 b 2 b m b 1 Coe fficients Bitplanes S = HbX where S represents the syndrome bits. H represents the parity check matrix of linear channel code. bX represents the source bits. These syndromes identify the coset to which the source data belongs to. In this implementation we have considered two biplanes for coset coding marked gray in the Figure 7. We have implemented this using irregular 3/4 rate LDPC coder [4]. 3.2. Decoder The Decoder block diagram is shown in the Figure 8. The entropy coded bits are decoded by an entropy de- coder and the coset coded bits are passed to the LDPC decoder. In this implementation, previous frame is con- sidered as the side information required for syndrome decoding. Once the syndrome coded bits are recovered they identify the coset to which Xi belongs and hence using the side information Yi we can correctly decode the entire bits of Xi. The quantized codeword sequence is then dequantized and inverse transformed to get the original coefficients. 4. Simulation Results Video Codec is designed for a single camera scenario which is an application to wireless network of video camera equipped with cell phones. The video codec is simulated and tested with a object oriented approach Encoded Bit Stream Entropy D ec oding Syndro me D ecoding using LDPC dec o der Side I nf ormation Generation Bit Plane Formation LS B MSB Uniform DeQuantization IDCT & Zigzag Scan Reco nstructe d Block Figure 8. Video decoder. 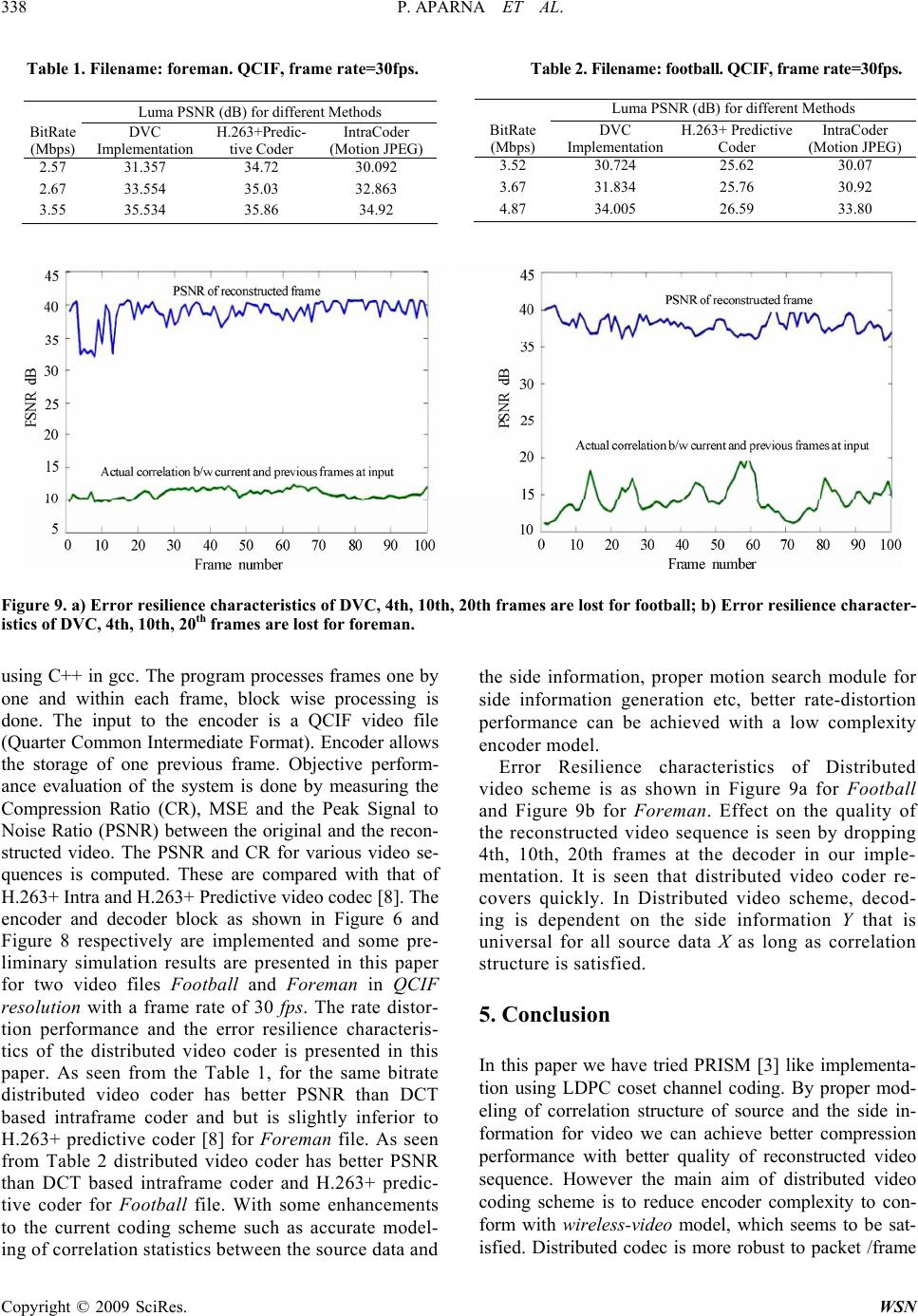 338 P. APARNA ET AL. Table 1. Filename: foreman. QCIF, frame rate=30fps. Table 2. Filename: football. QCIF, frame rate=30fps. Figure 9. a) Error resilience characteristics of DVC, 4th, 10th, 20th frames are lost for football; b) Error resilience character- istics of DVC, 4th, 10th, 20th frames are lost for foreman. using C++ in gcc. The program processes frames one by one and within each frame, block wise processing is done. The input to the encoder is a QCIF video file (Quarter Common Intermediate Format). Encoder allows the storage of one previous frame. Objective perform- ance evaluation of the system is done by measuring the Compression Ratio (CR), MSE and the Peak Signal to Noise Ratio (PSNR) between the original and the recon- structed video. The PSNR and CR for various video se- quences is computed. These are compared with that of H.263+ Intra and H.263+ Predictive video codec [8]. The encoder and decoder block as shown in Figure 6 and Figure 8 respectively are implemented and some pre- liminary simulation results are presented in this paper for two video files Football and Foreman in QCIF resolution with a frame rate of 30 fps. The rate distor- tion performance and the error resilience characteris- tics of the distributed video coder is presented in this paper. As seen from the Table 1, for the same bitrate distributed video coder has better PSNR than DCT based intraframe coder and but is slightly inferior to H.263+ predictive coder [8] for Foreman file. As seen from Table 2 distributed video coder has better PSNR than DCT based intraframe coder and H.263+ predic- tive coder for Football file. With some enhancements to the current coding scheme such as accurate model- ing of correlation statistics between the source data and the side information, proper motion search module for side information generation etc, better rate-distortion performance can be achieved with a low complexity encoder model. Error Resilience characteristics of Distributed video scheme is as shown in Figure 9a for Football and Figure 9b for Foreman. Effect on the quality of the reconstructed video sequence is seen by dropping 4th, 10th, 20th frames at the decoder in our imple- mentation. It is seen that distributed video coder re- covers quickly. In Distributed video scheme, decod- ing is dependent on the side information Y that is universal for all source data X as long as correlation structure is satisfied. 5. Conclusion In this paper we have tried PRISM [3] like implementa- tion using LDPC coset channel coding. By proper mod- eling of correlation structure of source and the side in- formation for video we can achieve better compression performance with better quality of reconstructed video sequence. However the main aim of distributed video coding scheme is to reduce encoder complexity to con- form with wireless-video model, which seems to be sat- isfied. Distributed codec is more robust to packet /frame Luma PSNR (dB) for different Methods BitRate (Mbps) DVC Implementation H.263+ Predictive Coder IntraCoder (Motion JPEG) 3.52 30.724 25.62 30.07 3.67 31.834 25.76 30.92 4.87 34.005 26.59 33.80 Luma PSNR (dB) for different Methods BitRate (Mbps) DVC Implementation H.263+Predic- tive Coder IntraCoder (Motion JPEG) 2.57 31.357 34.72 30.092 2.67 33.554 35.03 32.863 3.55 35.534 35.86 34.92 Copyright © 2009 SciRes. WSN  P. APARNA ET AL. 339 loss due to the absence of pred iction loop in the encod er. In a Predictive coder accuracy of decoding is strongly dependent on a sing le predictor from the encoder, lo ss of which results in erroneous decoding and error propaga- tion. Hence Predictive coder can recover from packet or frame loss by only some extent. The quality of the re- constructed signal for the same CR can be improved by performing more complex motion search. However it is seen that the current implementation operates well in high quality (PSNR of order of 30dB) regime. The ex- tension to lower bit rates withou t any compromise in the quality so that it is comparable with the conventional codecs will be the next part of the work. 6. References [1] J. D. Slepian an d J. K. Wolf, “Noiseless coding of corre- lated information sources,” IEEE Transactions on Infor- mation Theory, Vol. IT-19, pp. 471–480, July 1973. [2] A. D. Wyner and J. Ziv, “The rate-distortion function for source coding with side information at the decoder,” IEEE Transactions on Information Theory, Vol. IT-22, No. 1, pp. 1–10, January 1976. [3] R. Puri, A. Majumdar, and K. Ramachandran, “PRISM: A video coding paradigm with motion estimation at the decoder,” IEEE Transactions on Image Processing, Vol. 16, No. 10, October 2007. [4] A. D. Liveris, “Compression of binary sources with side information at the decoder using LDPC codes,” IEEE Communication Letters, Vol. 6, No. 10, October 2002. [5] S. S. Pradhan and K. Ramchandran, “Distributed source coding using syndromes (DISCUS): Design and con- struction,” Proc. IEEE Data Compression Conference, Snowbird, UT, pp. 158–167, March 1999. [6] A. D. Wyner, “Recent results in the Shannon theory,” IEEE Transactions on Information Theory, Vol. 20, No. 1, pp. 2–10, January 1974. [7] R. Puri and K. Ramchandran, “PRISM: A new robust video coding architecture based on distributed compres- sion principles,” Proc. Allerton Conference on Commu- nication, Control and Computing, Allerton, IL, October 2002. [8] G. Cote, B. Erol, M. Gallant, and F. Kosssentini, “H.263+: Video coding at low bitrates,” IEEE Transactions. Cir- cuits Sys. Video Technology, Vol. 8, No. 7, pp. 849–866, November 1998. [9] B. Girod, A. M. Aaron, S. R. and D. Rebollo-Monedero, “Distributed video coding,” Proceedings of the IEEE , Vol. 93 , No. 1, pp. 71–83, January 2005. Copyright © 2009 SciRes. WSN |