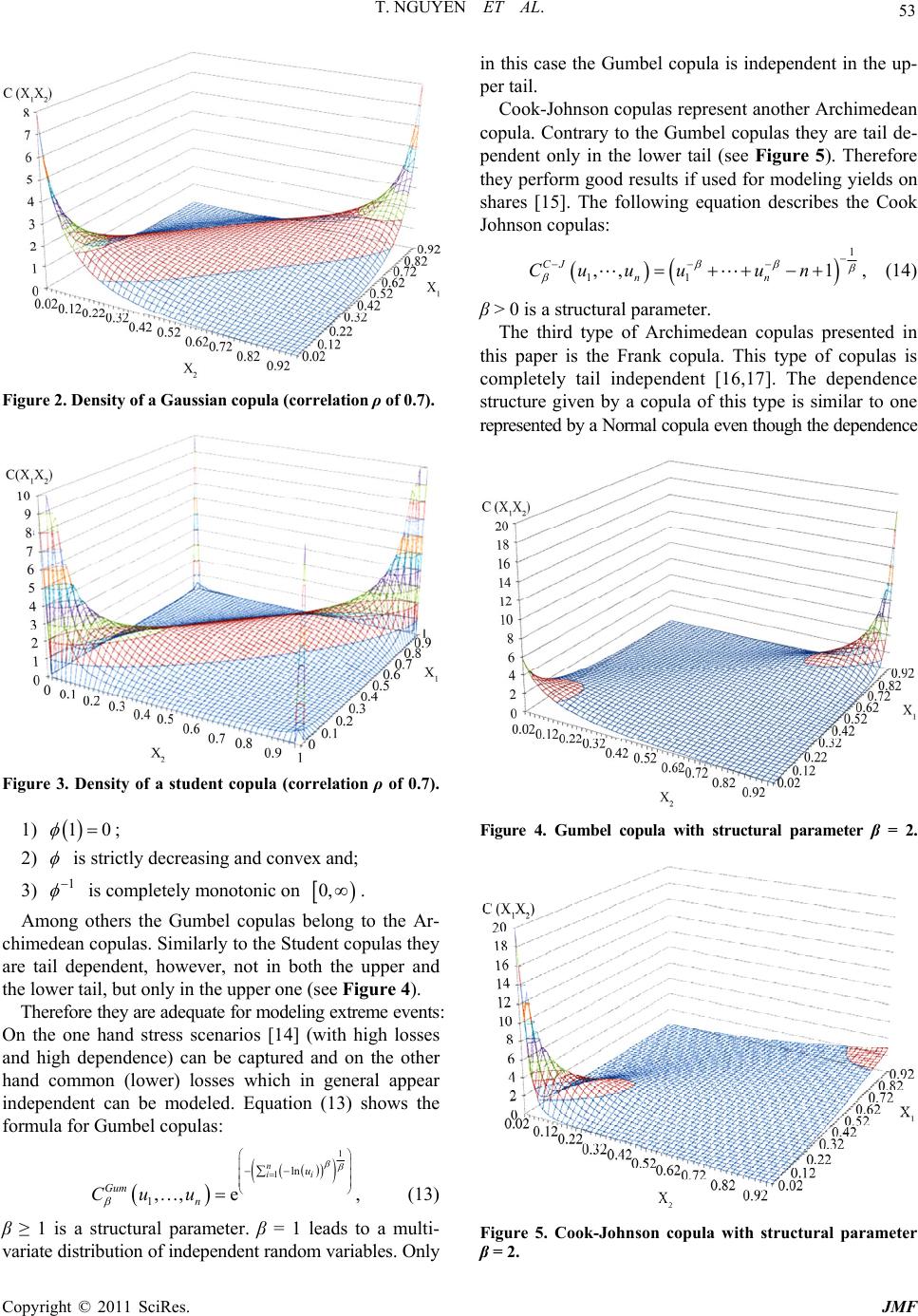
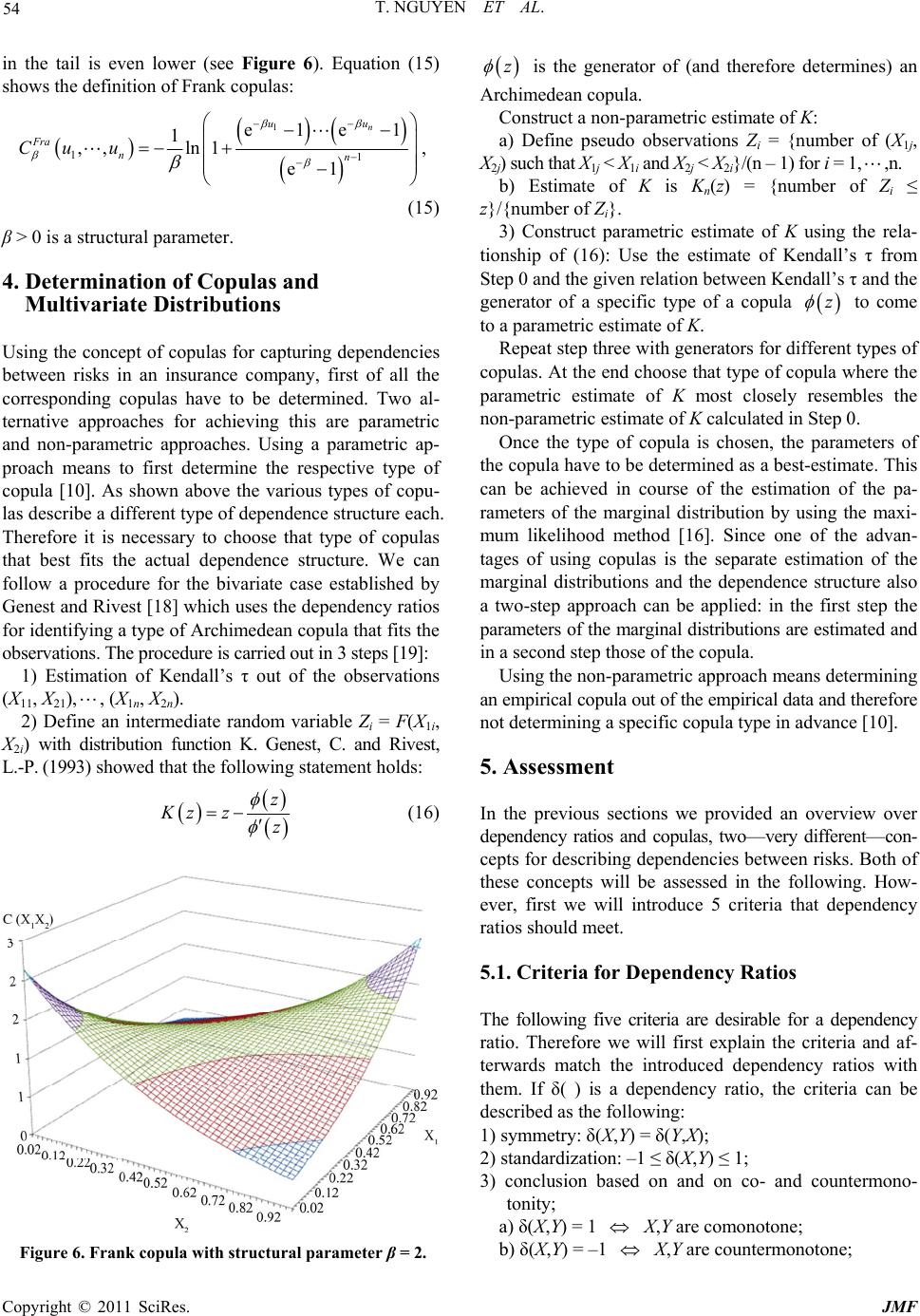
T. NGUYEN ET AL. 57
However, the Solvency IIves the possi-
bility to apply also the concto capture de-
odel. Tsupervisory aut
mp
a
ers which measure the dependencies
be
ve
us
pean Par-
liament and of the Council on the Taking-Up and Pursuit
ss of Insurance and Reinsurance,” 2009.
nsilium.europa.eu/pdf/en/09/st03/
Valdez, “Understanding Relation-
T of
78, No. 6, 2007, pp.
doi:10.1080/00949650701255834
framework gi
ept of copulas
pendencies in an internal m
ties may even require the co
he
anies to apply an inter-
ho-
ri
nl model for calculating the Solvency Capital Require-
ment, or a part thereof, if it is inappropriate to calculate
the Solvency Capital Requirement using the standard ap-
proach [1]. That means that if the approach for consider-
ing dependencies that is given in the standard model does
not lead to a realistic picture of the actual risk situation
of the company, the supervisory authorities may oblige
the company to use a more sophisticated way for captur-
ing dependencies.
Since the Solvency II framework does not use copulas
in the standard formula for reason of the proportionality
principle, we recommend that Solvency II should at least
reward those insur
tween their risks in a more sophisticated way. This could
be achieved either by reducing the SCR for those insur-
ers or the other way around by imposing higher require-
ments on companies which use the rudimental standard
approach. That would also be justifiable from an econo-
mical point of view: Companies that use linear correlations
may severely underestimate their overall risk and should
therefore be protected by higher capital requirements.
It would also make sense and give additional incen-
tives to explicitly mention the concept of copulas in the
directive and to rework the standard formula once the de-
velopment in multivariate modeling allows the effecti
e of copulas also for smaller insurance companies [20].
Moreover, we have discovered that the given correlations
do not seem to reflect an actual average of the insurance
industry. So, if correlations are used, they should at least
be actually measured in the insurance industry.
7. References
[1] European Commission, “Directive of the Euro
of the Busine
http://register.co
st03643-re06.en09.pdf
[2] S. Wang, “Aggregation of Correlated Risk Portfolios:
Models and Algorithms,” Proceedings of the Casualty
Actuarial Society, Vol. 85, 1998, pp. 848-939.
[3] E. W. Frees and E. A.
ships Using Copulas,” North American Actuarial Journal,
Vol. 2, No. 1, 1998, pp. 1-25.
[4] P. Blum, A. Dias and P. Embrechts, “The AR De-
pendence Modeling: The Latest Advances in Correlation
Analysis,” In: M. Lane, Ed., Alternative Risk Strategies,
Risk Books, London, 2002.
[5] A. J. McNeil, “Sampling Nested Archimedean Copulas,”
Journal of Statistical Computation and Simulation, Vol.
567-581.
[6] M. Elng and D. Toplek, “Modeling and Man
Nonlinear Dependencies-Copulas in Dynamic Financial
iagement of
Analysis,” Journal of Risk and Insurance, Vol. 76, No. 3,
2009, pp. 651-681.
doi:10.1111/j.1539-6975.2009.01318.x
[7] A. Tang and E. A. Valdez, “Economic Capital and the
Aggregation of Risks using Copulas,” 2006.
http://www.ica2006.com/Papiers/282/282.pdf
[8] A. Patton, “Copula-Based Models for Financial Time
Series,” In: T. G. Andersen, R. A. Davies, J.-P. Kreiss
and T. Mikosch, Ed., Handbook of Financial Time Series,
Springer, Berlin, 2009, pp. 767-785.
doi:10.1007/978-3-540-71297-8_34
[9] C. Genest, M. Gendron and M. Bourdeau-Brien, “The
Advent of Copulas,” European Journal of Finance, Vol.
15, No. 7-8, 2009, pp. 609-618.
doi:10.1080/13518470802604457
[10] G. Szegö, “Measures of Risk,” Journal of Banking and
Finance, Vol. 26, No. 7, 2002, pp. 1253-1272.
doi:10.1016/S0378-4266(02)00262-5
[11] D. Pfeifer, “Möglichkeiten und Gren
tischen Schadenmodellierung,” Zeitsc
zen der mathema-
hrift für die gesam-
à n Dimensions et Leurs
de Statistique de l’Un-
rrelation
nt: Properties and
zum
te Versicherungswissenschaft—German Journal of Risk
and Insurance, Vol. 92, No. 4, 2003, pp. 665-696.
[12] M. Sklar, “Fonctions de Répartition
Marges,” Publications de l’Institut
iversité de Paris, No. 8, 1959, pp. 229-231.
[13] P. Embrechts, A. McNeil and D. Straumann, “Co
and Dependence in Risk Manageme
Pitfalls,” 2002.
http://www.math.ethz.ch/~strauman/ preprints/pitfalls.pdf
[14] H.-J. Zwiesler, “Asset-Liability-Management—Die Ver-
sizcherung auf dem Weg von der Planungsrechnung
Risikomanagement,” In: K. Spremann, Ed., Versicherun-
gen im Umbruch—Werte Schaffen, Risiken managen, Kun-
den gewinnen, Springer, Berlin, 2005, pp. 117-131.
[15] T. Ané, T. and C. Kharoubi, “Dependence Structure and
Risk Measure,” Journal of Business, Vol. 76, No. 3, 2003,
pp. 411-438. doi:10.1086/375253
[16] M. Junker and A. May, “Measurement of aggregate risk
with copulas,” Econometrics Journal, Vol. 8, No. 3, 2005,
pp. 428-454. doi:10.1111/j.1368-423X.2005.00173.x
[17] G. G. Venter, “Tails of Copulas,” Proceedings of the Ca-
sualty Actuarial Society, Vol. 89, No. 171, 2002, pp. 68-113.
[18] C. Genest and L.-P. Rivest, “Statistical Inference Proce-
dures for Bivariate Archimedean Copulas,” Journal of the
American Statistical Association, Vol. 88, No. 423, 1993,
pp. 1034-1043. doi:10.2307/2290796
doi:10.1111/j.1539-6975.2009.01310.x
[19] E. W. Frees and E. A. Valdez, “Understanding Relation-
ships Using Copulas,” North American Actuarial Journal,
Vol. 2, No. 1, 1998, pp. 1-25.
[20] P. Embrechts, “Copulas: A Personal View,” Journal of
Risk and Insurance, Vol. 76, No. 3, 2009, pp. 639-650.
Copyright © 2011 SciRes. JMF