Open Access Library Journal
Vol.04 No.11(2017), Article ID:80692,18 pages
10.4236/oalib.1104053
Statistical, Data-Driven Approach to Forecasting Production from Liquid-Rich Shale Reservoirs
Ibukun Makinde
KBC Advanced Technologies, Houston, TX, USA
Copyright © 2017 by author and Open Access Library Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: October 22, 2017; Accepted: November 26, 2017; Published: November 29, 2017
ABSTRACT
The oil and gas industry needs fast and simple techniques of forecasting oil and gas production. Forecasting production from unconventional, low permeability reservoirs is particularly challenging. As a contribution to the continuing efforts of finding solutions to this problem, this paper studies the use of a statistical, data-driven method of forecasting production from liquid-rich shale (LRS) reservoirs called the Principal Components Methodology (PCM). In this study, production of five different highly volatile and near-critical oil wells was simulated for 30 years with the aid of a commercial compositional simulator. Principal Components Methodology (PCM) was applied to production data from the representative wells by using Singular Value Decomposition (SVD) to calculate the principal components (PCs). These principal components were then used to forecast oil and solution gas production from the near-critical oil wells with production histories ranging from 0.5 to 2 years, and the results were compared to simulated data and the Modified Arps’ decline model forecasts. Application of the PCM to field data is also included in this work. Various factors ranging from ultra-low permeability to multi-phase flow effects have plagued the mission of forecasting production from liquid rich shale reservoirs. Traditional decline curve analysis (DCA) methods have not been completely adequate for estimating production from shale reservoirs. The PCM method enables us to obtain the production decline structure that best captures the variance in the data from the representative wells considered. This technique eliminates the need for parameters like the hyperbolic decline exponents (b values) and the task of switching from one DCA model to another. Also, production forecasting can be done without necessarily using diagnostic plots. With PCM, production could be forecasted from liquid-rich shale reservoirs with reasonable certainty. This study presents an innovative and simple method of forecasting production from liquid-rich shale (LRS) reservoirs. It provides fresh insights into how estimating production can be done in a different way.
Subject Areas:
Chemical Engineering & Technology, Mineral Engineering
Keywords:
Principal Components, Liquid-Rich Shale, Unconventional Resources, Production Forecasting, Pattern Recognition, Decline Curve Analysis

1. Introduction
Liquid-rich shale (LRS) reservoirs have complex characteristics that are yet to be fully understood. Lengthy transition flow regimes, complicated reservoir fluid dynamics among other features contribute to the difficulties of forecasting production from LRS reservoirs.
Over the years, several empirical decline curve analysis (DCA) models have been used to forecast reservoir production such as the Arps’ hyperbolic decline model [1] , Duong’s model [2] , the Stretched Exponential Production Decline (SEPD) model [3] , the power-law model [4] and more recently the YM-SEPD model [5] . All these models have limitations, which have made them not entirely satisfactory for forecasting production from unconventional reservoirs, especially when production history is short. The use of hybrid (combination) DCA models can improve results significantly [6] . However, these models require careful analysis of diagnostic plots and more importantly, accurate determination of the time of switch from one model to another.
Analytical models are quite rigorous. The tri-linear flow model [7] , its extended version by Stalgorova and Mattar [8] , the semi-analytical model by Clarkson and Qanbari [9] are among several analytical models that have been proposed for forecasting production from LRS reservoirs. These models, however, assume single-phase flow. When pressure drops below the bubble point, multi- phase flow effects come into play. Therefore, negligence of this major factor when creating analytical forecasting models may lead to erroneous production estimates.
Further research efforts have led to the consideration of other possible ways of forecasting production from unconventional plays. The Principal Components Methodology (PCM) was proposed by Makinde and Lee [10] as a novel approach to forecasting oil production from tight oil reservoirs. This method was also further used in a simulation study by Makinde and Lee [11] to forecast the secondary phase―gas, from shale oil reservoirs. PCM is a data-driven method of forecasting based on the statistical technique of principal components analysis (PCA). Principal components analysis (PCA) has numerous applications in various fields such as biology, finance, architecture, etc. The ability to use PCA to extract common trends and patterns from sets of data has made it applicable to production forecasting as well. Bhattacharya and Nikolaou [12] used PCA to analyze production history from unconventional gas reservoirs but did not forecast future production. Makinde and Lee [13] used the Principal Components Methodology (PCM) to forecast production from shale volatile oil reservoirs and compared the results to compositionally simulated data and production estimates from different decline curve analysis (DCA) models.
In this paper, a clearer and more explicit explanation of the procedure for Principal Components Methodology (PCM) is presented. The results of PCM oil production forecasts were compared with results from the Modified Arps (commonly used in the industry) DCA model. This was not done in my previous publications [10] [13] . The other publications either focused on solely on assessing the performance of PCM with varying ranges of historical data or compared PCM with YM-SEPD, Duong, Modified Duong as well as their hybrid variants. In addition, PCM was used to forecast solution gas production from near-critical oil wells. More importantly too, this paper highlights some of the challenges that may be encountered when applying PCM to field data. Possible solutions to these issues were proffered in this article. For the field data analyses, hindcasting was included. That is, using PCM to match actual field data with the aid of some portion of the available historical field data.
2. Reservoir Model
A multi-fractured horizontal well (MFHW) with 20 uniform hydraulic fractures and length of 5000 ft was modeled. The fractures are all infinitely conductive with half lengths of 150 ft. A commercial compositional simulator was used to simulate production from wells with five different reservoir fluids (highly volatile and near-critical oils). 30 years of production was simulated from wells with different minimum bottomhole pressure (BHP) constraints of 500 psi and 1000 psi, reservoirs with different degrees of undersaturation―initial reservoir pressures of 4000 psi and 5000 psi, as well as reservoir fluids with different critical gas saturations―5% and 10% respectively (shown in Table 1). The original base cases are wells (with the ten different fluid samples) having a minimum BHP of 1000 psi, initial reservoir pressure of 5000 psi and critical gas saturation of 5%. Altogether, production data were simulated from 20 different wells. Pressure drop and fluid flow were modeled using logarithmically-spaced local grid refinement (LS-LGR) and the Peng-Robinson equation of state was used for the PVT. Figure 1 shows the MFHW model and Table 2 shows the five different reservoir fluid compositions. Fluids 3 and 4 are near-critical volatile oils. Reservoir data in Table 1 are those of a typical liquid-rich shale reservoir.

Figure 1. Multi-Fractured Horizontal Well (MFHW) model.

Table 1. Reservoir data.
Table 2. Fluid compositions.
3. Arps’ Decline Model
Production decline characteristics depend on the rate of decline, D and the decline exponent (b value):
where q is the production rate in barrels per day, month or year and t is time in days, months or years. This equation defines the instantaneous changes in the slope of the curvature, dq/dt, with change in the production rate, q over time.
For the hyperbolic decline model, the decline rate, D varies and the b value (decline exponent) is more than 0 and less than 1 (0 < b < 1). Production rate in this case is expressed with the following equation:
where qi is the initial production rate and Di is the initial decline rate.
The exponential and harmonic decline models are special cases. For exponential decline, the rate of decline, D is constant and the b value is 0. Here, the production rate is expressed as:
In the case of harmonic decline, the rate of decline, D also varies but is directly proportional to the production rate, and the b value is 1. Production rate in this instance is:
Modified Arps’ decline model simply refers to the application of Arps’ decline model by changing the b values accordingly throughout the production history of a well regardless of the flow regime present. In unconventional reservoirs, the use of b values (decline exponents) greater than 1 may be encountered. Decline exponents greater than 1 causes forecasted cumulative production to increase toward infinity, (i.e. they are unbounded), which is not possible. However, since unconventional reservoirs like shale have very low permeabilities and exhibit lengthy transient flow, b values greater than 1 provide “best-fits” to production data in certain situations.
Before using DCA techniques for production forecasting, diagnostic plots are necessary for proper flow regime identification. Log-log rate-time and log-log rate-MBT (Material Balance Time) plots are the most commonly used diagnostic plots for flow regime identification. Transient linear flow can be identified with a slope of −1/2, bilinear flow―slope of −1/4 on both diagnostic plots and boundary dominated flow (BDF) with a slope of −1 on the log-log rate-MBT plot. Lengthy transition periods between transient linear flow and BDF, as indicated in these figures, are common for LRS reservoirs. The impact of multi-phase flow as reservoir pressure drops below the bubble point is presumed to be one of the major reasons. The ultra-low permeability of shale reservoirs may also be a contributing factor. Figure 2 and Figure 3 show the diagnostic plots (log-log rate- time and log-log rate-MBT) for one of the near-critical fluids.
On the log-log rate-time diagnostic plot, it can be observed that the slopes after the perceived “start of boundary dominated flow” (STBDF) steadily decrease to values more negative than −1. Despite this, it is presumed that boundary dominated flow regime covers the range from the STBDF till the end of the production period. The STBDF on the log-log rate-time diagnostic plot corres-

Figure 2. Oil rate vs. time―near-critical fluid.

Figure 3. Oil rate vs. MBT―near-critical fluid.
ponds with the “start of boundary effects” (STBE) on the log-log rate-MBT diagnostic plot. On the log-log rate-MBT diagnostic plot, the “end of linear flow” (ELF), the “start of boundary effect” (STBE) and the “start of boundary dominated flow” (STBDF) are visibly shown. The regions between the ELF and STBDF are the “transition flow regime periods”. According to Makinde and Lee [6] , the “start of boundary effects” (STBE) is a point on the log-log rate-MBT diagnostic plot where there is a slightly observable change of slope which matches with the STBDF on the log-log rate-time plot. At this point, it is assumed that the reservoir boundaries have started to affect flow rate.
4. Principal Components Methodology (PCM)
The principal components methodology (PCM) is a statistical, data-driven method of forecasting based on the principal components analysis (PCA). It basically involves representing the well production data in matrix form and using singular value decomposition (SVD) to calculate the principal components. These principal components are then used to estimate future production. The basic workflow for PCM is as follows:
1) Obtain representative collection of well production/GOR data for time 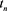 (e.g., 30 years in this study) and construct a m × n matrix Z from the representative data as shown below:
(e.g., 30 years in this study) and construct a m × n matrix Z from the representative data as shown below:
where are production/GOR data of well 𝑖 over time;
m―number of wells (always equal to the number of sets of principal components (PCs) generated);
n―length of production history (time).
2) Apply principal components analysis (PCA) to the representative well data using singular value decomposition (SVD) to obtain the principal components as follows:
where S―diagonal matrix of singular values and U and VT―left and right normalized eigenvectors respectively. Singular Value Decomposition breaks down this matrix into 3 major components―left and right normalized eigenvectors (matrices U and VT) and diagonal matrix S. The m rows of the matrix VT are the sets of principal components (PCs).
; . The diagonal elements of matrix S are the
singular values, which are the positive square roots of the eigenvalues of ZTZ. The singular values are in decreasing order from top to bottom of diagonal matrix S. Each singular value is associated with a set of principal components (PCs). How large the singular values are, determine how well the set of PCs associated with it capture variance in the representative well data under consideration. The larger the singular value, the more variance in the representative well data is captured by the set of PCs associated with it. The largest singular value is associated with the first set of PCs (which captures the most variance in the representative well data under consideration).
3) After SVD, the matrix Z can be represented with the following expressions:
where R―number of sets of PCs to be used in forecasting and 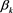 ―PC multiplier. Since the matrix Z has been decomposed into 3 components, 2 of the components (the singular values and the left normalized eigenvectors) are lumped together to form the PC multiplier,
―PC multiplier. Since the matrix Z has been decomposed into 3 components, 2 of the components (the singular values and the left normalized eigenvectors) are lumped together to form the PC multiplier, 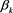 .
because it is advisable to use the sets of PCs (R in number that are associated with the largest singular values) which capture more of the variance in the well data considered. The other sets of PCs (the rest of the m number of sets of PCs after R has been chosen) capture very little of the variance in the well data, therefore they can be discarded.
.
because it is advisable to use the sets of PCs (R in number that are associated with the largest singular values) which capture more of the variance in the well data considered. The other sets of PCs (the rest of the m number of sets of PCs after R has been chosen) capture very little of the variance in the well data, therefore they can be discarded.
4) Given wells with limited production history (in cases here, ranging from 0.5 to 2 years), use the least square regression method to identify best estimates for 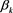 (PC multiplier), which would be
(PC multiplier), which would be 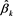 , with the following formula:
, with the following formula:
where d are oil/gas rates or GOR data and are the principal components.
5) Production/GOR can then be forecasted using the formula below:
6) To estimate solution gas production, the trapezoidal rule can be used to approximate the area under the forecasted producing GOR vs. cumulative oil production (Np) curve with the equation below:
The more data points that are available, the more accurate trapezoidal rule approximations are.
A pictorial representation of the PCM workflow is shown in Figure 4.
In this study, a representative collection of production data from 20 different wells with 5 different reservoir fluid compositions was generated by compositional simulation with a commercial compositional simulator. Then SVD was used to obtain 20 sets of principal components (PCs). The first set of principal components are the primary principal components which reveal the structure or pattern that best captures most of the variance in the representative data from all the 20 wells considered. The other sets of PCs portray certain characteristic features for each well. The first set of PCs capture the most data that maximize the variance from all representative wells, followed by the second set of PCs, the third set and so on. In this work, only the first set of principal components out of the total 20 obtained were used for analyses. The rest were discarded since they capture little of the variance in the well data under consideration. Figure 5 shows the graphical representation of the first set of PCs used for analyses in this paper.

Figure 4. Basic workflow for PCM.

Figure 5. First set of principal components (PCs).
5. Results―Oil Production Forecasts
PCM was used to forecast 30 years of production for each of the five highly volatile oil wells with availability of 0.5 to 2 yrs of simulated production history. The results were then compared to compositional simulation study results and Modified Arps’ forecasts (with the availability of all 30 years of production history). Analyses were done with PCM, using only the 1st primary set of principal components to estimate future production. Results for the near-critical fluids are displayed in the graphs below (Figures 6-9).
Results indicate that the Principal Components Methodology (PCM) forecasts with reasonable level of accuracy (percentage forecast error as low as 0.4%) irrespective of the length of the available production history. In Figure 9, despite using all 30 years of the production history to forecast using the Modified Arps’ model, the result was still not as accurate as that obtained through PCM with only 6 months of available historical production data.
6. Results―Solution Gas Production Forecasts
Over the years, the chief focus has been on predicting oil production performance shale oil reservoirs, neglecting the equally important solution gas and the variables that govern its production. Due to the potential value of natural gas, it is vital to be able to forecast solution gas production from shale oil reservoirs. PCM was used to forecast 30 years of producing gas-oil ratio (GOR) data for each of the five highly volatile oil wells with availability of 0.5 to 2 yrs of simulated production history. The results were then compared to compositional simulation study results. Analyses were done with PCM, using only the 1st primary set of principal components to estimate future GOR. Graphical displays of GOR forecasts and the plots of the estimated GOR forecasts versus cumulative oil production for the near-critical fluids are shown in Figures 10-15.
From the results, observations show that forecasts were reasonable and errors in the calculated solution gas produced (after 30 yrs) were relatively low. Percentage

Figure 6. Oil rate vs. time forecast―0.5 yr. historical data.

Figure 7. Oil rate vs. time forecast―1 yr. historical data.

Figure 8. Oil rate vs. time forecast―2 yrs. historical data.

Figure 9. Oil rate vs. time forecast―0.5 yr. historical data for PCM & 30 yrs. of historical data for modified Arps.

Figure 10. GOR vs. time forecast―0.5 yr. historical data.

Figure 11. Forecasted GOR vs. cumulative oil―0.5 yr. historical data.

Figure 12. GOR vs. time forecast―1 yr. historical data.

Figure 13. Forecasted GOR vs. cumulative oil―1 yr. historical data.

Figure 14. GOR vs. time forecast―2 yrs. historical data.

Figure 15. Forecasted GOR vs. cumulative oil―2 yrs. historical data.
Table 3. Solution gas production forecast results.
error in the estimated solution gas production after 30 years was as low as 3.8%. The calculated results can be seen in Table 3.
7. Field Data Analyses
When actual field data are available, the application of PCM involves some steps prior to following the already outlined basic workflow. Firstly, the historical field data can be history-matched. The parameters obtained from the history- matching exercise can then be used to simulate production data for as long as we would like to forecast (in this case, 30 years). After this, the basic PCM workflow outlined earlier can be followed. Hindcasting can also be done to verify the validity of PCM by applying the methodology to a portion of the available historical data from a representative group of wells. The principal components (PCs) generated are then used to forecast the remaining part of the available historical data. In other words, through the hindcasting exercise, PCM can be used to match the actual field data available. Examples of these two approaches are shown later in this work. Note though, that prior to applying the PCM workflow to field data, it is advisable to eliminate the outliers and clean up the production data.
When applying PCM to field data, certain challenges may be encountered. For example, different wells may have different production start and end times. Also, in some cases, wells might be shut in i.e., no production data available for that period. This study proposes certain solutions to handling these challenges that may arise. They are outlined below:
1) Always treat the data as purely raw data. Meaning, ignore the exact times associated with the oil and gas rates. Treat the oil and gas rates as purely raw data. This helps to avoid the complications associated with the irregularity of production data points;
2) To tackle the issue of different start and end production times for different wells, always remember that the matrix Z formed from your available data is m x n. The length of production history (time), n must be the same for all the well data being considered in order to apply PCA appropriately using singular value decomposition (SVD). That is, endeavor to choose a specific length of production history (time) for your analyses and use the same length of time for all the well data under consideration regardless of their actual lengths of production history. For example, for wells with lengthier production histories (e.g. 3 years) than your choice for analyses (e.g. 2 years), use data from the beginning up to the time of your choice (2 years) and ignore the rest of the data at later times. And, for wells with shorter production histories (e.g. 6 months) than your choice for analyses (e.g. 2 years) you can only use data up to the amount available and other well data must be equal to 6 months as well for PCA (using SVD) to be applicable in this instance. In this case, if your choice of production history for analyses is lengthier than 6 months, the wells with only 6 months of production history can not be included or considered for PCA application using SVD;
3) If there are shut-ins, ignore the shut-in periods and focus on the available data. For example, the last datum (oil or gas rate) before the shut-in period should be followed directly by the first datum (oil or gas rate) after the shut-in period.
In this study, PCM was applied to data (after clean up) from 10 different representative wells in the same liquid-rich shale play. Therefore, 10 sets of principal components (PCs) were calculated using singular value decomposition (SVD). The first set of PCs were then used to forecast future production of the wells and other wells in the same region. An example for a well with about 3,561 days of historical production data is presented here. Figure 16 and Figure 17 display the history-matched production data and simulated forecast. Figure 18 shows comparison with the PCM forecast. Here, the PCM forecast is highly accurate, with a forecast error of only 0.02%.
Examples of hindcasting exercise for the same well but with approximately 3000 days of the historical production data are shown in Figure 19 and Figure 20. PCM was applied to 1400 days out of the available historical production data for all the 10 representative wells. The principal components obtained were used

Figure 16. History-matched field data.

Figure 17. Field data―simulated forecast.

Figure 18. Forecast comparisons―field data.

Figure 19. Hindcasting: oil rate vs. time―field data.

Figure 20. Hindcasting: oil rate vs. time forecast comparison with modified Arps―field data.
to forecast the remaining production. The PCM results were compared to the actual field data and Modified Arps’ decline model forecast. Result showed that PCM matched actualfield data better than the Modified Arps’ decline model.
8. Conclusions
Principal components analysis (PCA) is a statistical tool that helps to account for the variability in a group of representative data sets. Principal components (PCs) are obtained by Singular Value Decomposition (SVD), which is one of the ways of executing PCA. The first set of PCs has the largest possible variance and the successive sets of PCs have the maximum possible variance under a constraint that is orthogonal to preceding sets of PCs.
The application of these principal components (PCs) to forecasting oil and solution gas production gave rise to the Principal Components Methodology (PCM). This simple, easy-to-use technique of forecasting production is based on pattern recognition and feature extraction. The principal components methodology (PCM) has the following noteworthy advantages over other empirical and analytical methods of production forecasting:
1) It eliminates the need to determine vital decline curve analysis (DCA) model parameters like the hyperbolic decline exponents (b values);
2) Diagnostic plots are not necessary prior to forecasting with PCM;
3) It avoids the complication of switching from one DCA model to another, as is the case with hybrid (combination) DCA models;
4) It does not involve complex and rigorous calculations.
Despite some of the challenges that may be encountered while applying PCM to field data, this method can forecast with reasonable certainty irrespective of the length of historical production data available.
Acknowledgements
Many thanks to Computer Modelling Group Ltd. (CMG) for providing software for the simulation studies.
Cite this paper
Makinde, I. (2017) Statistical, Data-Driven Approach to Fore- casting Production from Liquid-Rich Shale Reservoirs. Open Access Library Journal, 4: e4053. https://doi.org/10.4236/oalib.1104053
References
- 1. Arps, J.J. (1945) Analysis of Decline Curves. AIME, 160, 228-247.
https://doi.org/10.2118/945228-G - 2. Duong, A.N. (2011) Rate-Decline Analysis for Fracture-Dominated Shale Reservoirs. SPE Reservoir Evaluation & Engineering, 14, SPE 137748-PA.
- 3. Valko, P.P. and Lee, W.J. (2010) A Better Way to Forecast Production from Unconventional Gas Wells. The SPE Annual Technical Conference and Exhibition, Florence, 19-22 September 2010, SPE Paper 134231
- 4. Ilk, D., Rushing, J.A., Per-ego, A.D. and Blasingame, T.A. (2008) Exponential vs. Hyperbolic Decline in Tight Gas Sands: Understanding the Origin and Implications for Reserve Estimates Using Arps’ Decline Curves. The SPE Annual Technical Conference and Exhibition, Denver, 21-24 September 2008, SPE Paper 116731.
- 5. Yu, S. and Miocevic, D.J. (2013) An Improved Method to Obtain Reliable Production and EUR Prediction for Wells with Short Production History in Tight/Shale Reservoirs. The Unconventional Resource Technology Conference, Denver, 12-14 August 2013, SPE Paper 168684.
- 6. Makinde, I. and Lee, W.J. (2017) Forecasting Production of Liquid Rich Shale (LRS) Reservoirs Using Simple Models. Journal of Petroleum Science and Engineering, 157, 461-481.
https://doi.org/10.1016/j.petrol.2017.07.049 - 7. Ozkan, E., Brown, M., Raghavan, R. and Kazemi, H. (2011) Comparison of Fractured-Horizontal-Well Performance in Tight Sand and Shale Reservoirs. SPE Reservoir Evaluation & Engineering, 14, SPE 121290-PA.
- 8. Stalgorova, E. and Mattar, L. (2013) Analytical Model for Unconventional Multifractured Composite Systems. SPE Reservoir Evaluation & Engineering, 16, SPE 162516-PA.
- 9. Clarkson, C.R. and Qanbari, F. (2015) A Semianalytical Forecasting Method for Unconventional Gas and Light Oil Wells: A Hybrid Approach for Addressing the Limitations of Existing Empirical and Analytical Methods. SPE Reservoir Evaluation & Engineering, 18, SPE 170767-PA.
- 10. Makinde, I. and Lee, W.J. (2016) A New Approach to Forecasting Production from Liquid Rich Shale Reservoirs. The Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, 7-10 November 2016, SPE Paper 183021.
https://doi.org/10.2118/183021-MS - 11. Makinde, I. and Lee, W.J. (2016) Statistical Approach to Forecasting Gas-Oil Ratios and Solution Gas Production from Shale Volatile Oil Reservoirs. The Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, 7-10 November 2016, SPE Paper 182933.
https://doi.org/10.2118/182933-MS - 12. Bhattacharya, S. and Nikolaou, M. (2013) Analysis of Production History for Unconventional Gas Reservoirs with Statistical Methods. SPE Journal, SPE 147658.
- 13. Makinde, I. and Lee, W.J. (2016) Production Forecasting in Shale Volatile Oil Reservoirs Using Reservoir Simulation, Empirical and Analytical Methods. The Unconventional Resources Technology Conference, San Antonio, 1-3 August 2016, URTeC 2429922.