Applied Mathematics
Vol.4 No.7(2013), Article ID:34302,10 pages DOI:10.4236/am.2013.47140
The Distribution of an Index of Dissimilarity for Two Samples from a Uniform Population
Faculty of Economics, University of Bari, Bari, Italy
Email: nannavecchia.a@dss.uniba.it
Copyright © 2013 Giovanni Girone, Antonella Nannavecchia. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Received October 11, 2012; revised January 6, 2013; accepted January 19, 2013
Keywords: Index of Dissimilarity; Uniform Distribution; Spacings
ABSTRACT
In this paper the authors study the sample behavior of the Gini’s index of dissimilarity in the case of two samples of equal size drawn from the same uniform population. The paper present the analytical results obtained for the exact distribution of the index of dissimilarity for sample sizes n ≤ 8. This result was obtained by expressing the index of dissimilarity as a linear combination of spacings of the pooled sample. The obtained results allow to achieve the exact expressions of the moments for any sample size and, therefore, to highlight the main features of the sampling distributions of the index of dissimilarity. The present study can enhance inferential statistical aspects about one of the main contributions of Gini.
1. Introduction
In 1915 Corrado Gini [1] introduced, as an index of dissimilarity between two groups of observations, the mean of the differences in absolute value between co-ranked observations. Fifty years later, in 1965, Gini [2] published a comprehensive and systematic overview of his own and of other authors results about dissimilarity.
We assume that two groups have equal number of observations n. Let  and
and ,
,  be the set of the observations in the first and in the second group respectively. Let
be the set of the observations in the first and in the second group respectively. Let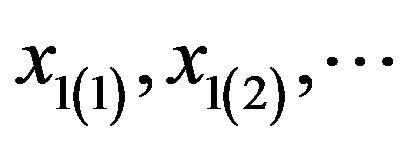 ,
,  and
and  be the observations arranged in non-descending order of magnitude, respectively in the first and in the second group. Gini’s simple index of dissimilarity is given by
be the observations arranged in non-descending order of magnitude, respectively in the first and in the second group. Gini’s simple index of dissimilarity is given by
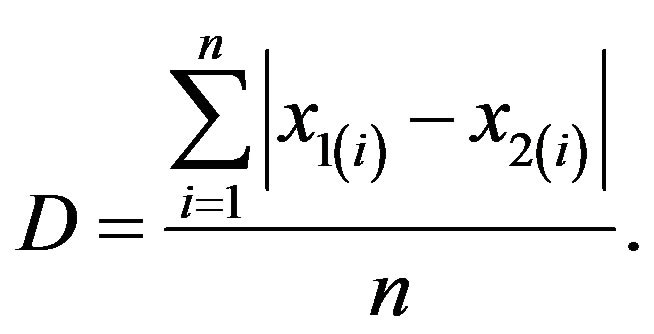
If the two groups of observations are random samples, the distribution of the Gini index with samples drawn from the same population is of great interest for inferential purposes (e.g. to verify the homogeneity of two populations).
As far as we know, the distribution of the index of dissimilarity between two samples has not been studied in depth yet, maybe for the complex structure of the index which considers observations arranged in order of magnitude, co-ranked pairs and differences in absolute value. Instead the distribution of the index of dissimilarity between a sample and its population was obtained by Forcina and Galmacci [3] for the particular case of a discrete, equispaced and equidistributed population. The mean and variance of the distribution of the index of dissimilarity, both between two samples and between a sample and its population, have been obtained by Herzel [4] and Bertino [5] for some particular cases.
The purpose of this note is to study the sample behavior of the index of dissimilarity in the case of two samples from the same uniform population. In this paper we present the analytical results obtained for the exact distribution of the index of dissimilarity for sample sizes n ≤ 8 as well as for the exact general expressions of the main characteristic values (mean, variance, moments) of such a distribution for any sample size and their limiting values.
2. The Distribution of a Linear Combination of Spacings
Let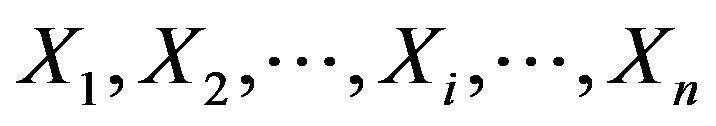 , be a random sample from a uniform population expressed by the probability density function (p.d.f.)
, be a random sample from a uniform population expressed by the probability density function (p.d.f.)
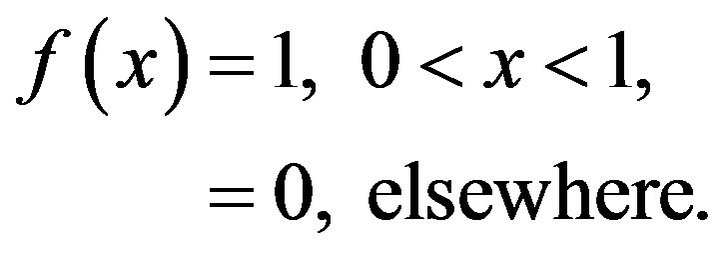 (1)
(1)
The variables of the sample in nondescending order 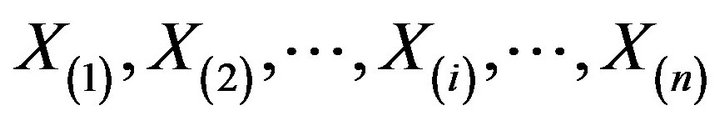 determine
determine 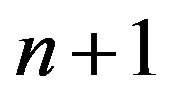 spacings
spacings
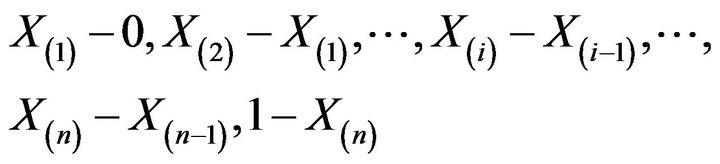
denoted by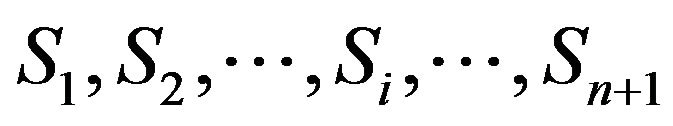 . These spacings are exchangeable random variables.
. These spacings are exchangeable random variables.
Let

be their linear combination. Huffer and Lin [6] showed that the p.d.f. of Z is
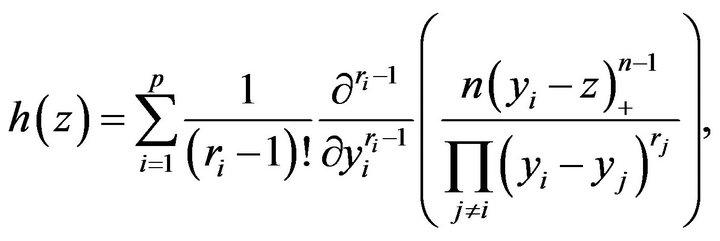 (2)
(2)
in which 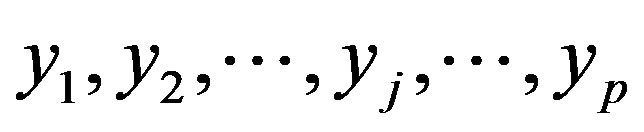 are the distinct values of the weights ai with frequencies
are the distinct values of the weights ai with frequencies  while the sign +, appearing at the numerator of the ratio in the brackets, indicates that the function is nonzero only if it is positive. This result will be used for determining the p.d.f. of the index of dissimilarity.
while the sign +, appearing at the numerator of the ratio in the brackets, indicates that the function is nonzero only if it is positive. This result will be used for determining the p.d.f. of the index of dissimilarity.
3. The Index of Dissimilarity as a Linear Combination of Spacings
The case of two independent random samples from uniform population with p.d.f. given by expression (1), both of size n, can be brought to the case of one random sample of size 2n from the same uniform population. Let  be the 2n variables of the pooled sample arranged in nondescending order of magnitude. They determine
be the 2n variables of the pooled sample arranged in nondescending order of magnitude. They determine 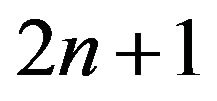 spacings
spacings
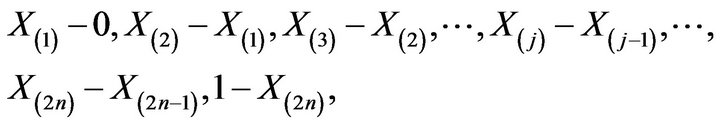
which we denote by . Given all the
. Given all the  subdivisions of the pooled sample into two samples of equal size n, let
subdivisions of the pooled sample into two samples of equal size n, let 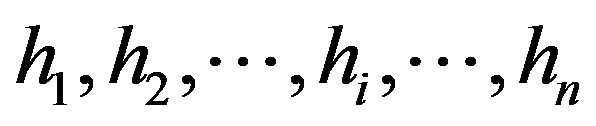 and
and  be the ranks in the pooled sample of the variables in the first and in the second sample respectively. Moreover
be the ranks in the pooled sample of the variables in the first and in the second sample respectively. Moreover 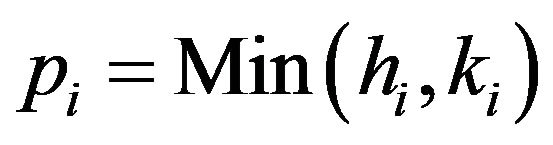 and
and 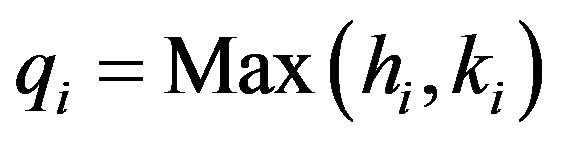 , for
, for . It is easy to verify that the index of dissimilarity is given by
. It is easy to verify that the index of dissimilarity is given by

or, when the differences are expressed in terms of spacings

by
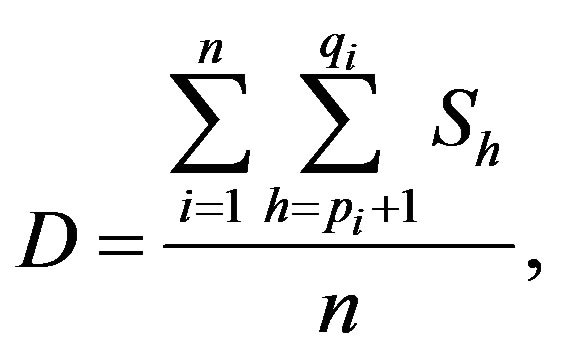
clearly D is equal to the linear combination of spacings given by

in which ah is the relative frequency of the n intervals 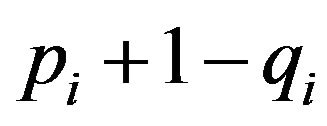 that contain the hth spacing. The above procedure for each of the
that contain the hth spacing. The above procedure for each of the 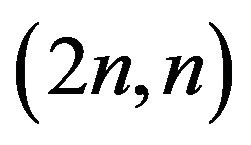 subdivisions of the pooled sample should be used to determine the p.d.f. of the index of dissimilarity. To reduce the amount of computation it is appropriate to aggregate the subdivisions which bring to the same coefficients ah. Due to the exchangeability of thespacings it is also appropriate to aggregate all subdivisions which bring to the same set offrequencies. In practice the
subdivisions of the pooled sample should be used to determine the p.d.f. of the index of dissimilarity. To reduce the amount of computation it is appropriate to aggregate the subdivisions which bring to the same coefficients ah. Due to the exchangeability of thespacings it is also appropriate to aggregate all subdivisions which bring to the same set offrequencies. In practice the  subdivisions are aggregated into groups characterized by the same set of frequencies. Denoting by
subdivisions are aggregated into groups characterized by the same set of frequencies. Denoting by  the distinct values of coefficients ah and by
the distinct values of coefficients ah and by 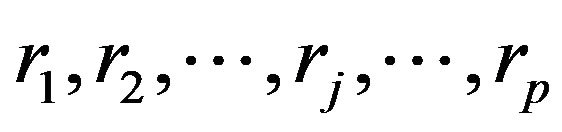 their frequencies (see Paragraph 2) we can apply formula (2) with the only variant of replacing n with 2n. Taken together the subdivisions which have the same values
their frequencies (see Paragraph 2) we can apply formula (2) with the only variant of replacing n with 2n. Taken together the subdivisions which have the same values  it is possible to proceed in an aggregate way by applying formula (2) only to homogeneous groups of subdivisions. These are in number of
it is possible to proceed in an aggregate way by applying formula (2) only to homogeneous groups of subdivisions. These are in number of 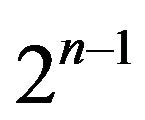 which allows to reduce considerably the amount of computation. Obviously, regard should be given to frequencies of the homogeneous subdivisions.
which allows to reduce considerably the amount of computation. Obviously, regard should be given to frequencies of the homogeneous subdivisions.
4. The Distributions of the Index of Dissimilarity for Sample Size Up to 8
To generate the sampling distribution of the index of dissimilarity two programs have been developed for Mathematica software. The first one generates, for each value of n, the subdivisions of the first 2n natural numbers into two subsets of size n and proceeds to identify homogeneous typologies and to define their frequencies. The second one starts, for each value of n, with such typologies and frequencies and gives, by applying formula (2), the p.d.f. of the index of dissimilarity. It should be said that heaviness of both calculation and resulting expressions led us to stop at . The sampling densities of the index of dissimilarity (see Paragraph 2) are splines of order 2n − 1 with knots at points i/n for
. The sampling densities of the index of dissimilarity (see Paragraph 2) are splines of order 2n − 1 with knots at points i/n for  They are also unimodal between 0 and 1, extreme values in which they assume value 0. The only exception is the degenerate case
They are also unimodal between 0 and 1, extreme values in which they assume value 0. The only exception is the degenerate case 
For 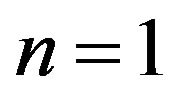
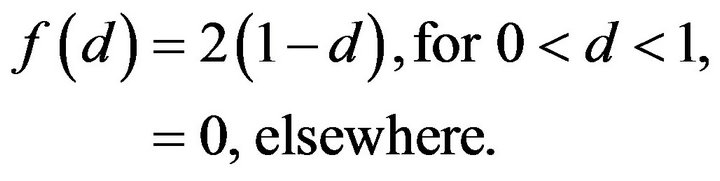
For 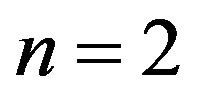
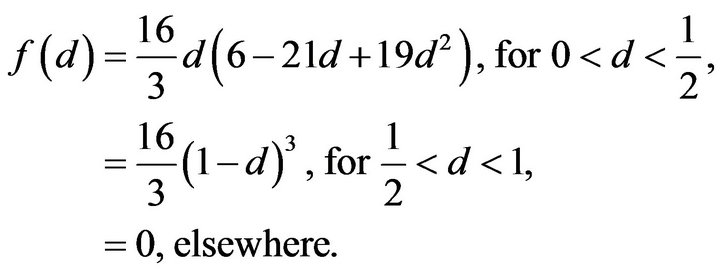
For 

For 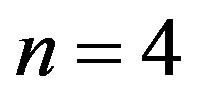

For 

For 

For 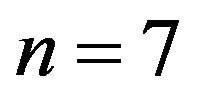


For 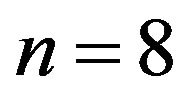



The sampling distribution of the index of dissimilarity for 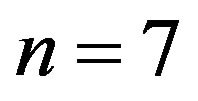 is shown in Figure 1.
is shown in Figure 1.
5. The Moments of the Sampling Distribution of the Index of Dissimilarity
On thee basis of the sampling distributions of the index of dissimilarity (see Paragraph 4), we obtained the values ofthe mean and of the second, third and fourth moment about the origin reported in Table 1.
Using the moments of the Dirichelet distribution, which is the model of the joint distribution of uniform spacings, as well as the expressions of the moments of a linear combination of equally distributed random variables, we obtained the mean and the second, third and fourth moment of the sampling distribution of the index of dissimilarity:
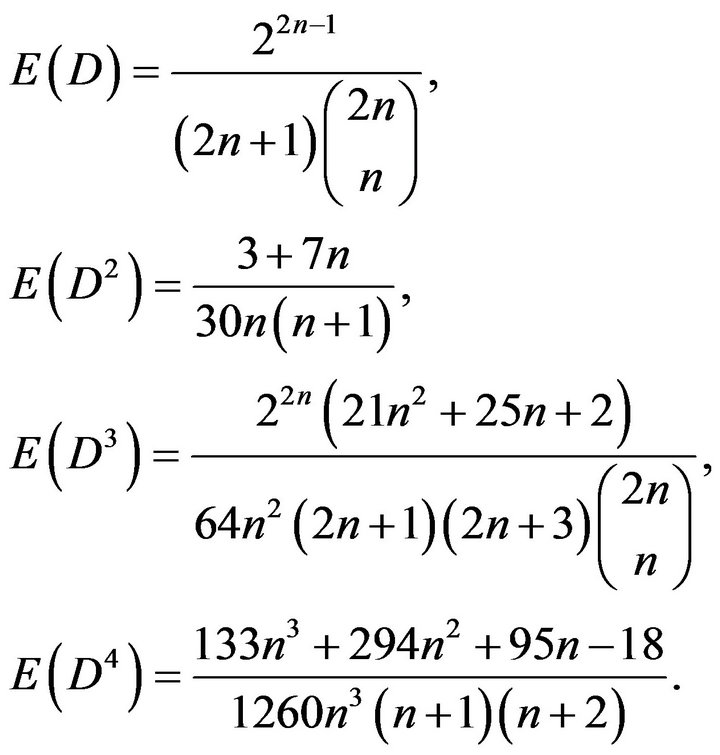
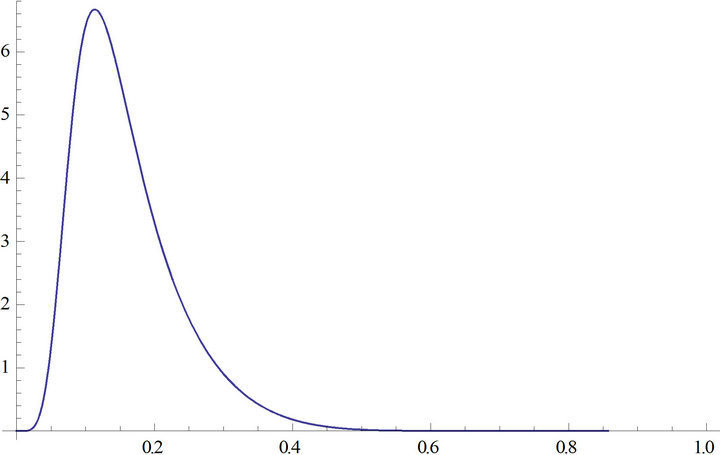
Figure 1. Sampling distribution of the index of dissimilarity for n = 7.
Based on these moments, we could study the main features of the sampling distribution of the index of dissimilarity starting from the mean. The trend of the mean with increasing sample size is shown in Figure 2.
It can be seen, the mean decreases for increasing n and it goes to zero for . The trend of the mean multiplied by
. The trend of the mean multiplied by  is increasing and converges to
is increasing and converges to 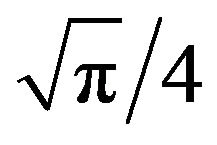 (Figure 3).
(Figure 3).
The variance of the sampling distribution of the index of dissimilarity can be expressed as follows

The trend of the standard deviation with increasing sample size is shown in Figure 4.
It can be seen that the standard deviation decreases with increasing n and it goes to zero for . The trend of the standard deviation multiplied by
. The trend of the standard deviation multiplied by 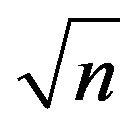 is also
is also
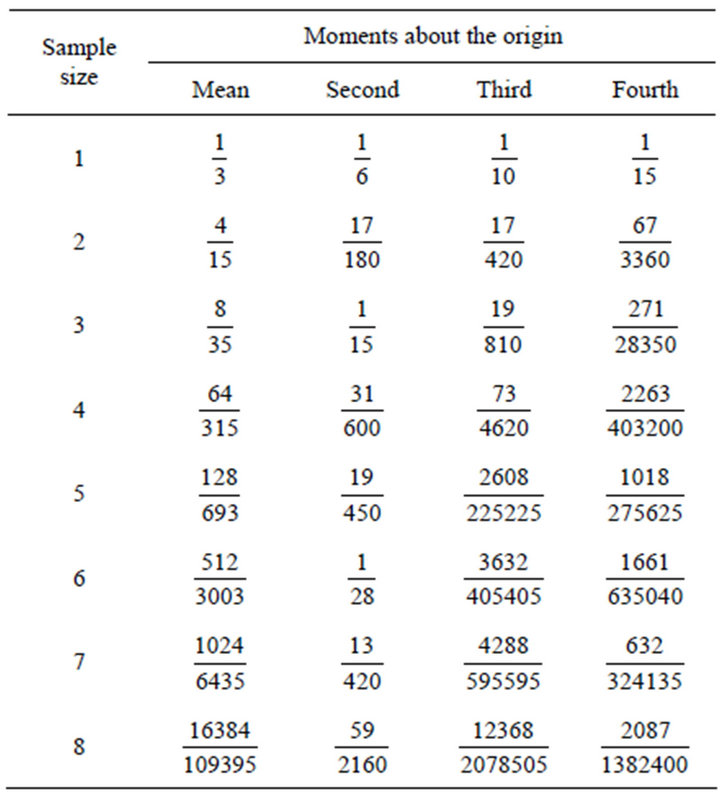
Table 1. Mean and moments of the sampling distribution of the index of dissimilarity for sample size up to 8.

Figure 2. Trend of the mean with increasing sample size.
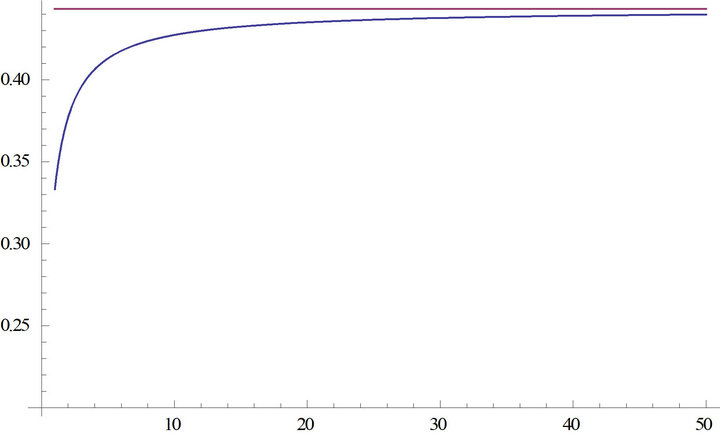
Figure 3. Trend of the mean multiplied by  with increasing sample size.
with increasing sample size.
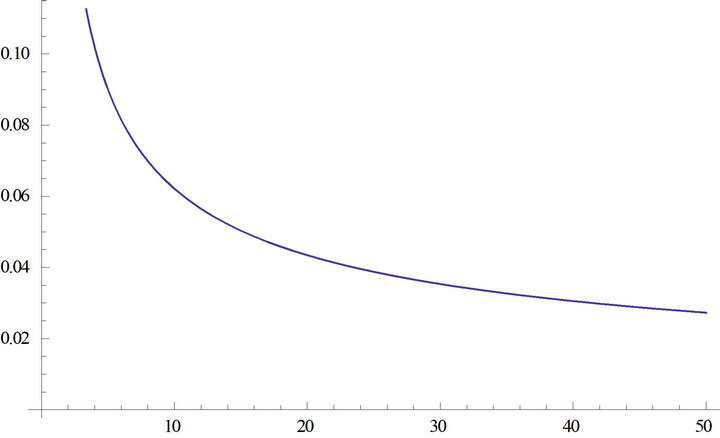
Figure 4. Trend of the standard deviation with increasing sample size.
decreasing and converges to 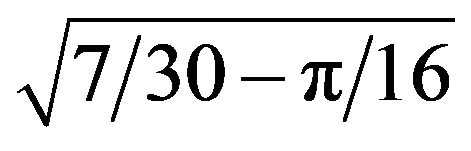 (Figure 5).
(Figure 5).
By converting moments about the origin into central moments it is possible to obtain indices of skewness and excess of kurtosis of the sampling distribution of the index of dissimilarity for a uniform population. Their trends with increasing sample size are shown in Figures 6 and 7.
It can be seen that distributions of the dissimilarity index are positively skewed and the skewness increases for increasing sample sizes up to the limit given by
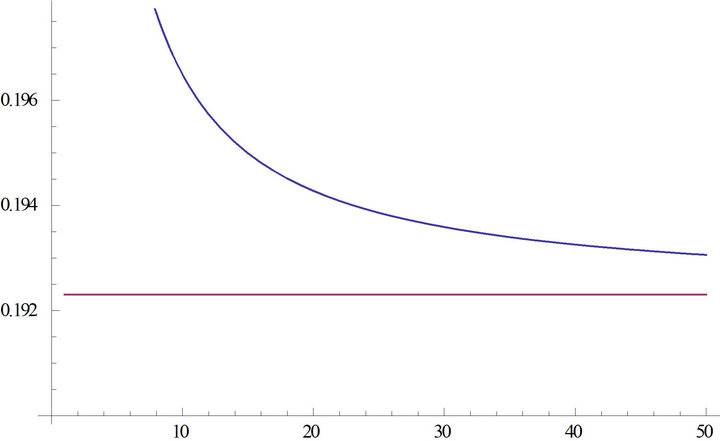
Figure 5. Trend of the standard deviation multiplied by  with increasing sample size.
with increasing sample size.

Figure 6. Trend of the skewness index with increasing sample size.

Figure 7. Trend of the excess of kurtosis index with increasing sample size.
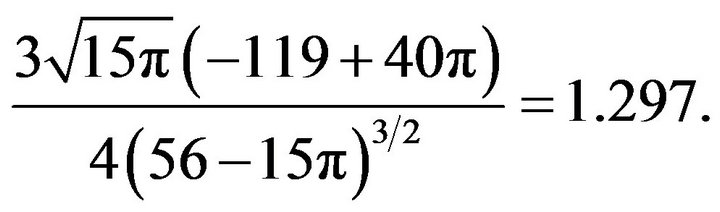
It is also clear that such distributions are leptokurtic and this leptokurtosis increases for increasing sample sizes up to the limit given by


Table 2. Thresholds of the sampling distribution of the index of dissimilarity for sample size up to 8.
6. Thresholds of the Sampling Distributions of the Index of Dissimilarity
Thresholds at usual levels 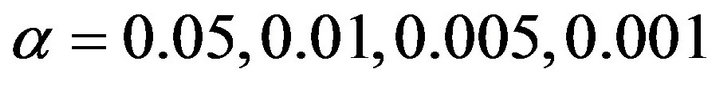 are required to test statistical hypothesis that two samples come from the same uniform population. Thresholds have been calculated on the exact sampling distributions of the index of dissimilarity (see Paragraph 4) and their values are reported in Table 2. For larger sample sizes can be used the approximate conservative thresholds
are required to test statistical hypothesis that two samples come from the same uniform population. Thresholds have been calculated on the exact sampling distributions of the index of dissimilarity (see Paragraph 4) and their values are reported in Table 2. For larger sample sizes can be used the approximate conservative thresholds
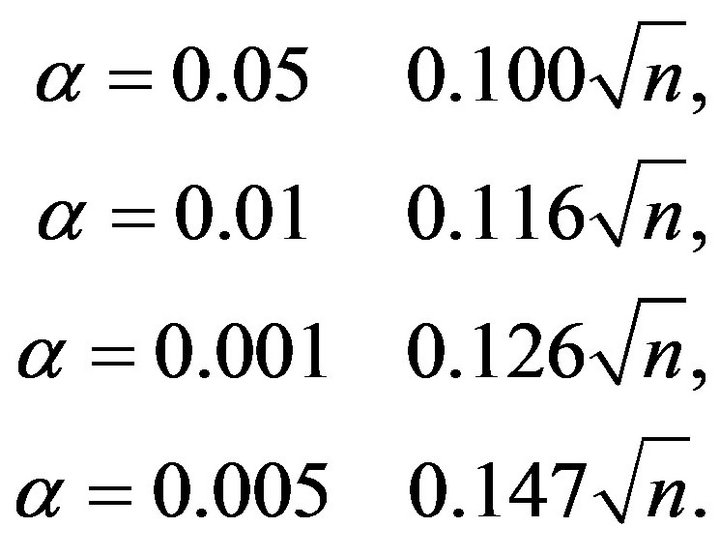
7. Conclusions
In this note we obtained the distributions of the index of dissimilarity in the case of two random samples of small size from a uniform population. This result was obtained by expressing the index of dissimilarity as a linear combination of spacings of the pooled sample. The exact expressions, in the form of splines of order 2n − 1, were obtained for samples of size ≤ 8. Although it would be possible to go further we stopped at this size because of the heaviness in processing and in the resulting expressions. This limit could be overcome by using some already set calculus programs. The obtained results allow to achieve the exact expressions of the moments and, therefore, to highlight the main features of the sampling distributions of the index of dissimilarity.
Beyond the problem of dealing with larger sample sizes, open problems are also those considering the case of two samples with different sizes as well as the case of other distribution models for population.
We believe that the present work has re-opened a research strand able to enhance also the inferential statistical aspects about one of the fundamental contributions of Gini.
REFERENCES
- C. Gini, “Di Una Misura Della Dissomiglianza tra Due Gruppi di Quantità e Delle Sue Applicazioni Allo Studio Delle Relazioni Statistiche,” Proceedings of the R. Venetian Institute of Sciences, Literatures and Arts, Vol. 74, 1914, pp. 185-213.
- C. Gini, “La Dissomiglianza,” Metron, Vol. 24, No. 1-4, 1965, pp. 85-215.
- A. Forcina and G. Galmacci, “Sulla Distribuzione Dell’ Indice Semplice di Dissomiglianza,” Metron, Vol. 32, No. 1-4, 1974, pp. 361-378.
- A. Herzel, “Il Valor Medio e la Varianza Dell’Indice Semplice di Dissomiglianza Negli Universi dei Campioni Bernoulliano ed Esaustivo,” Library of Metron, Series C, Notes and Reports, Vol. 2, 1963, pp. 199-224.
- S. Bertino, “Sulla Media e la Varianza Dell’Indice Semplice di Dissomiglianza Nel Caso di Campioni Provenienti da una Stessa Variabile Casuale Assolutamente Continua,” Metron, Vol. 30, No. 1-4, 1972, pp. 256-281.
- W. F. Huffer and C. T. Lin, “Spacings, Linear Combinations of,” In: Encyclopedia of Statistical Sciences, John Wiley & Sons Inc., New York, 2006, pp. 7866-7875. doi:10.1002/0471667196.ess5049.pub2