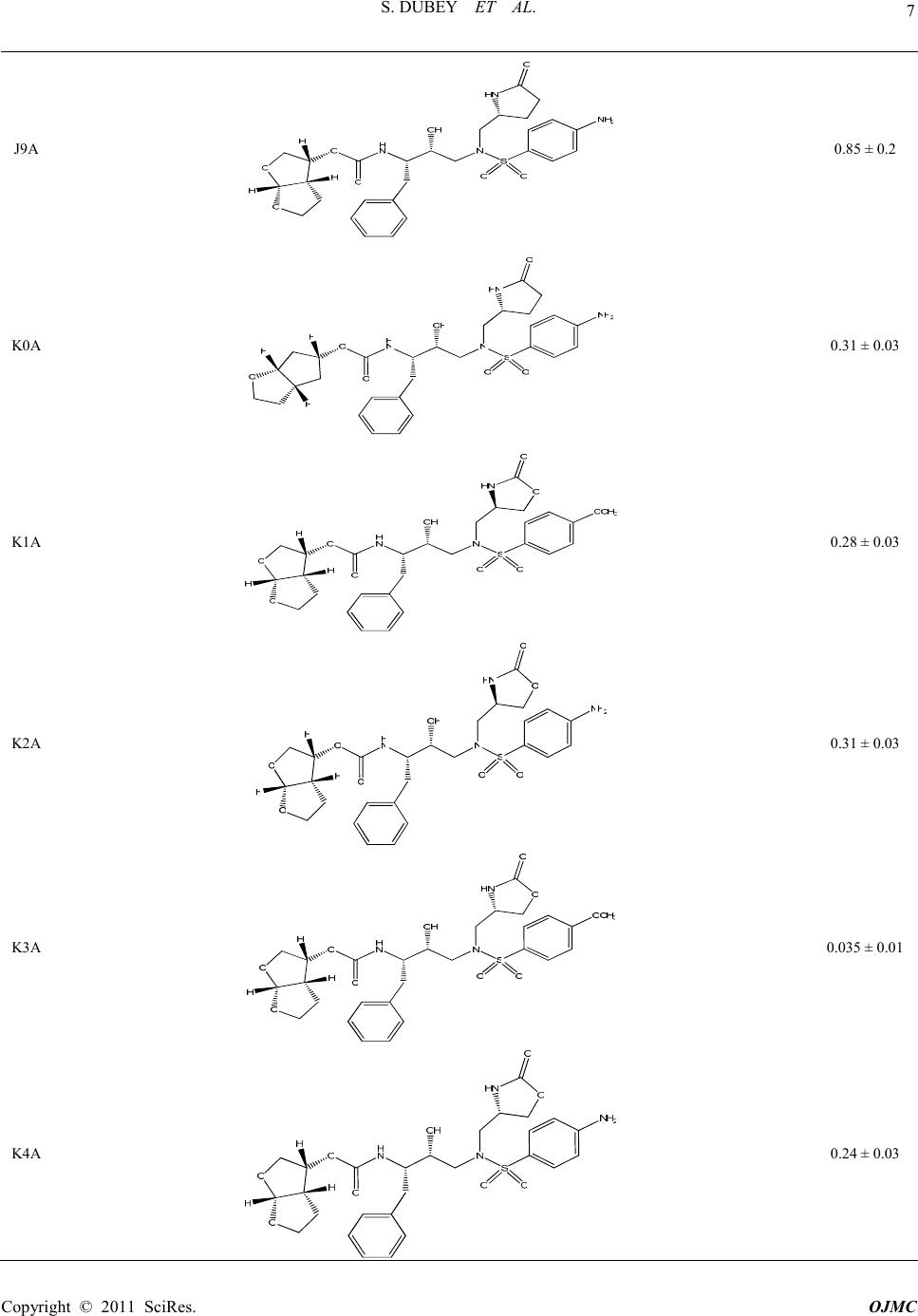
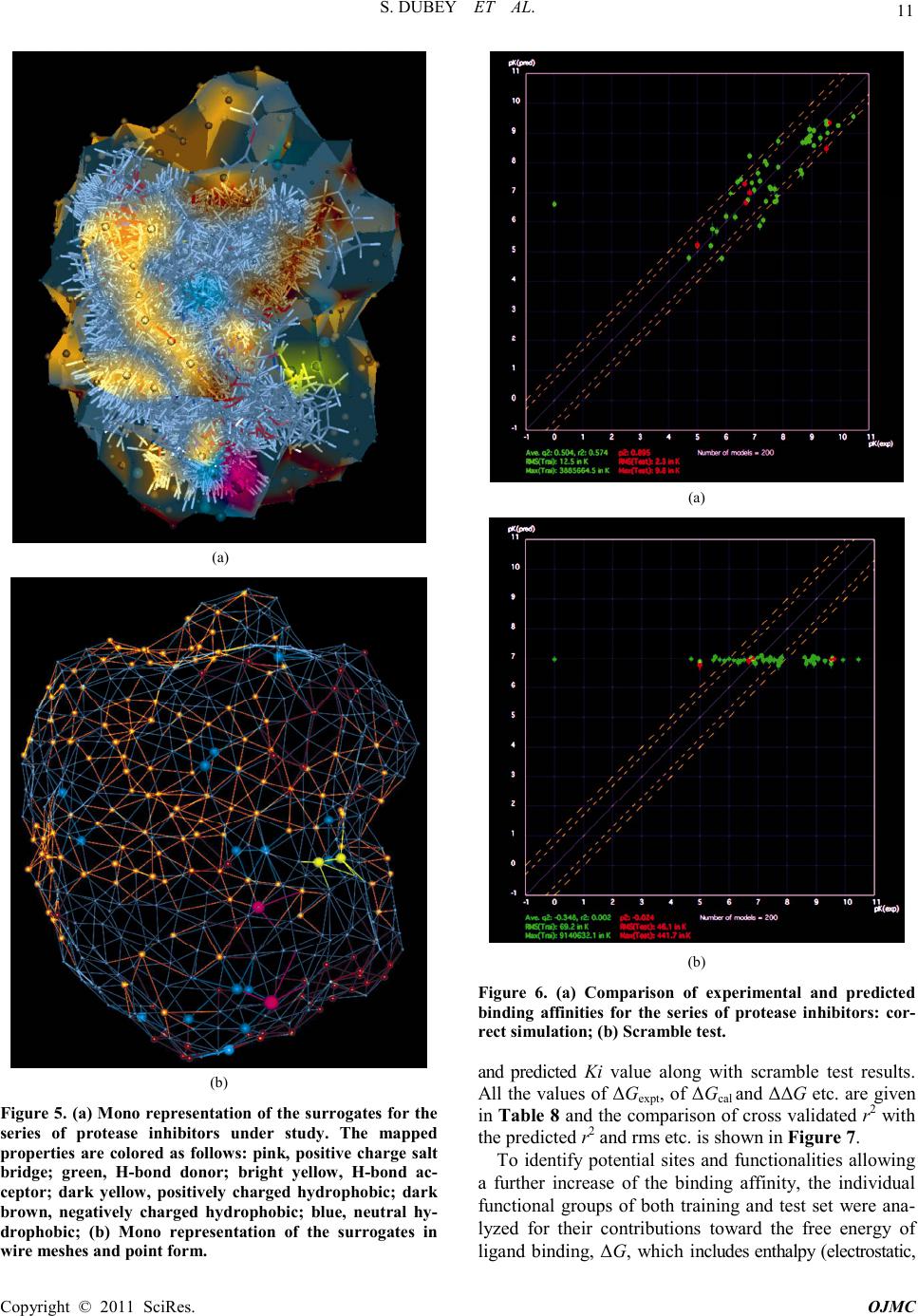
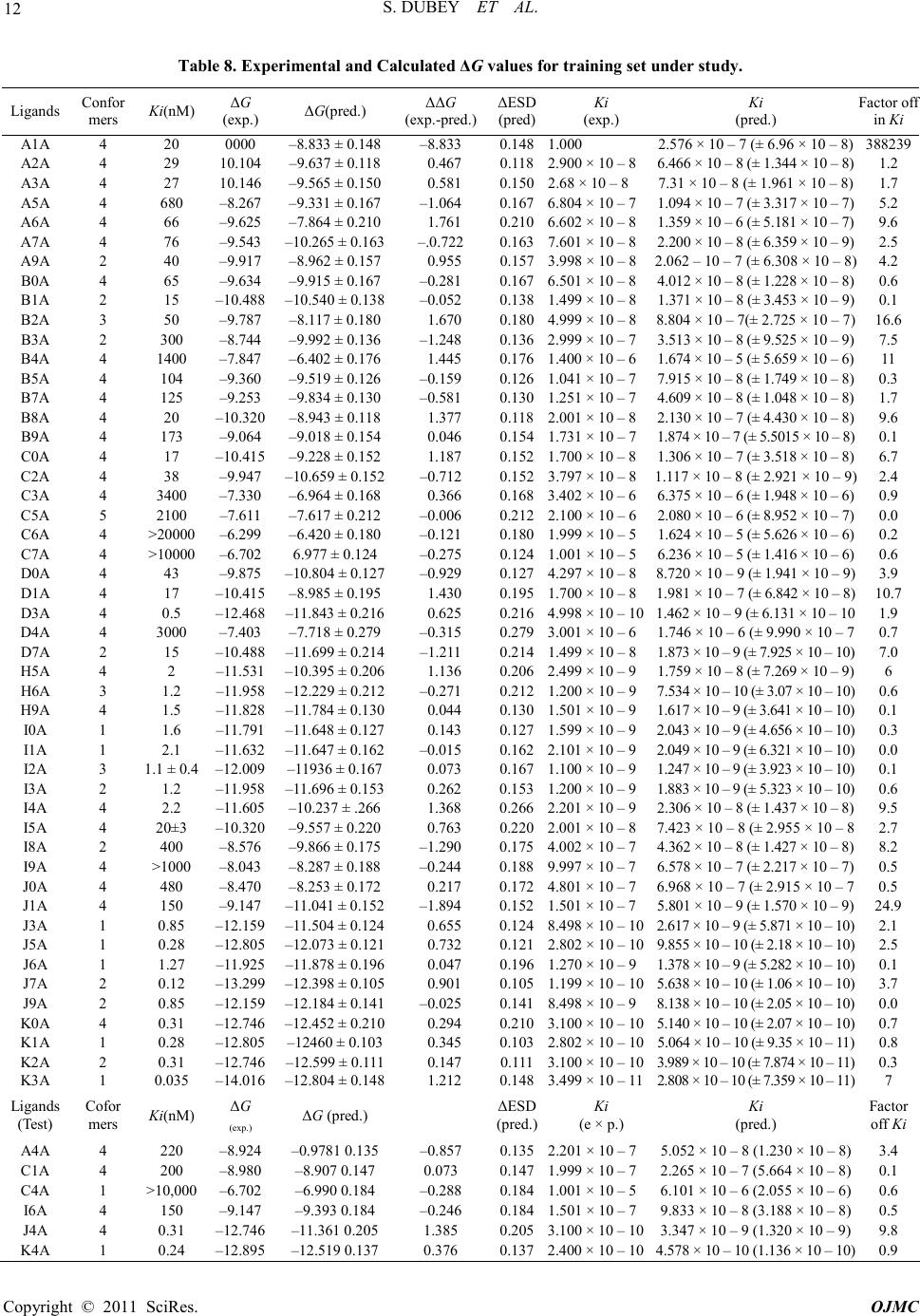
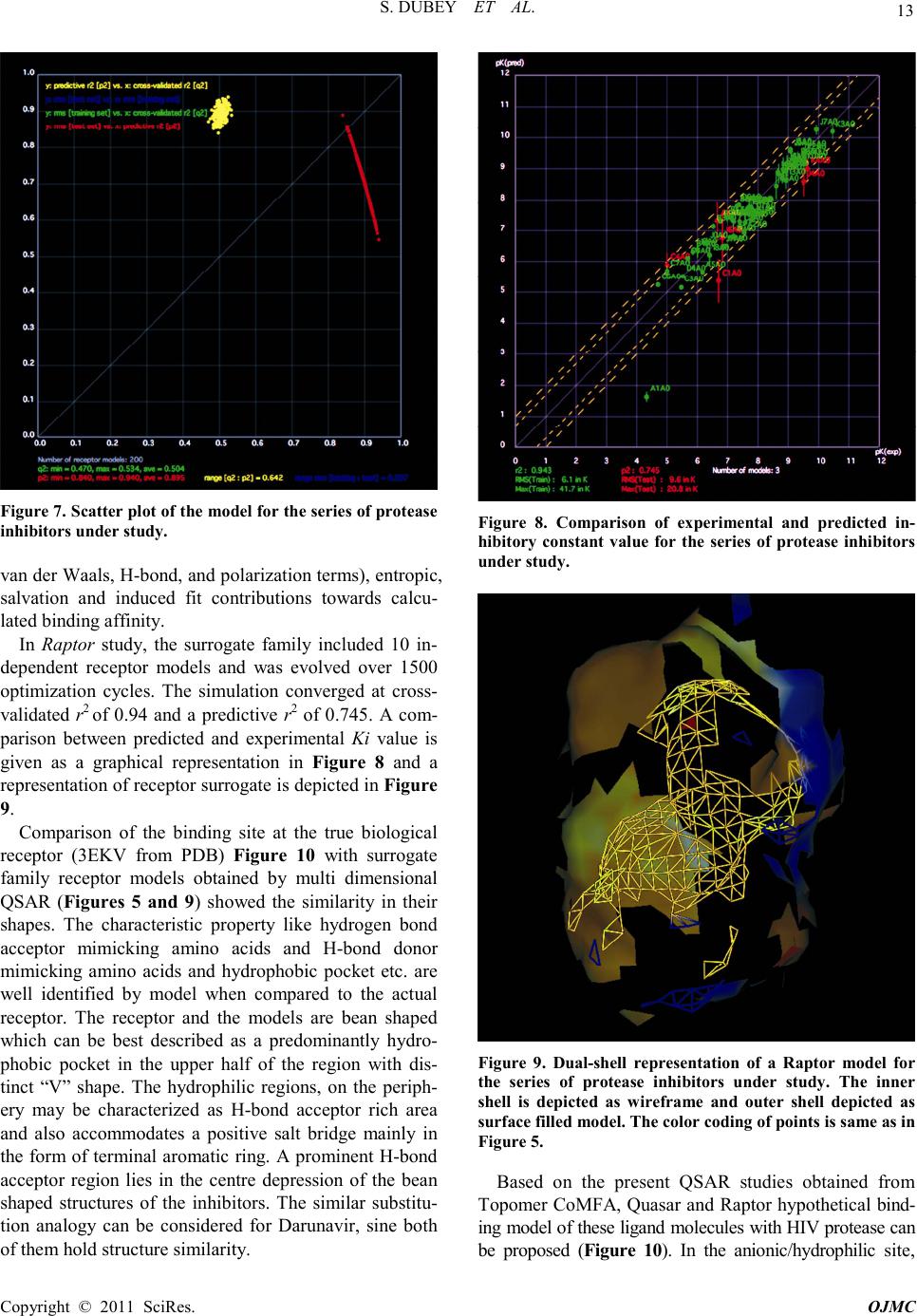
15
S. DUBEY ET AL.
[4] J. Vondrasek and A. Wlodawer, “A Database of the
Structures of Human Immunodeficiency Virus Protease,”
Proteins, Vol. 49, No. 4, 2002, pp. 429-431.
doi:10.1002/prot.10246
[5] M. L. West and D. P. Fairlie, “Targeting HIV-1 Protease:
A Test of Drug-Design Methodologies,” Trends in Phar-
macologi c al Sc i e nc e , Vol. 16, No. 2, 1995, pp. 67-75.
doi:10.1016/S0165-6147(00)88980-4
[6] T. D. Meek, “Inhibitors of HIV-1 Protease,” Enzyme
Inhibition, Vol. 6, No. 1, 1992, pp. 65-98.
doi:10.3109/14756369209041357
[7] C. Merry, M. G. Barry, F. Mulcahy, K. L. Halifax and D.
J. Back, “Saquinavir Pharmacokinetics Alone and In
Combination with Nelfinavir in HIV-Infected Patients,”
AIDS, Vol. 11, No. 15, 1997, pp. F117-F120.
do i:1 0. 10 97 /00 00 20 30 - 19 97 15 000 -00 00 1
[8] E. L. Ellsworth, J. Domagala, J. V. Prasad, S. Hagen, D.
Ferguson, T. Holler, D. Hupe, N. Graham, C. Nouhan, P.
J. Tummino, G. Zeikus and E. A. Lunney, “4-Hydroxy-
5,6-dihydro-2H-pyran-2-ones.3. Bicyclic and Hetero-Ar-
omatic Ring Systems as 3-Position Scaffolds to Bind to
S1' and S2' of the HIV-1 Protease Enzyme,” Bioorganic
& Medicinal Chemistry Letters, Vol. 9, No. 14, 1999, pp.
2019-2024. doi:10.1016/S0960-894X(99)00332-7
[9] A. K. Patick, K. E. Potts, “Protease Inhibitors as Antiviral
Agents,” Clinical Microbiology Reviews, Vol. 11, No. 4,
1998, pp. 614-627.
[10] J. R. Huff, “HIV Protease: A Novel Chemotherapeutic
Target for AIDS,” Journal of Medicinal Chemistry, Vol.
34, No. 8, 1991, pp. 2305-2312.
doi:10.1021/jm00112a001
[11] N. E. Kohl, E. A. Emini, W. A. Schleif, L. J. Davis, J. C.
Heimbach, R. A. Dixon, E. M. Scolnick and I. Sigal,
“Active Human Immunodeficiency Virus Protease is Re-
quired for Viral,” Proceedings of the National Academy
of Science USA, Vol. 85, No. 3, 1988, pp. 4686-4690.
doi :1 0. 1073 / pn as. 8 5.13 . 46 86
[12] E. T. Brower, U. M. Bacha, Y. Kawasaki and E. Freire,
“Inhibition of HIV-2 Protease by HIV-1 Protease Inhibi-
tors in Clinical Use,” Chemical Biology and Drug Design,
Vol. 71, No. 4, 2008, pp. 298-305.
doi:10.1111/j.1747-0285.2008.00647.x
[13] G. Bold, H. G. Capraro, R. Cozens, T. Klimkait, J. Laz-
dins, J. Mestan, B. Poncioni, J. Rosel, V. Stover, M. Tin-
telnot-Blomley, F. Acemoglu, W. Beck, B. Boss, M.
Eschbachm, T. Hurlimann, E. Masso, S. Roussel, K. Uc-
ciStoll, D. Wyss and M. Lang, “New Aza-Dipeptide
Analogues as Potent and Orally Absorbed HIV-1 Protease
Inhibitors: Candidates for Clinical Development,” Journal of
Medicinal Che mistry, Vol. 41, No. 18, 1998, pp. 3387-3401.
doi:10.1021/jm970873c
[14] D. C. Richard, “Topomer CoMFA: A Design Methodol-
ogy for Rapid Lead Optimization,” Journal of Medicinal
Chemistry, Vol. 46, No. 3, 2003, pp. 374-388.
doi:10.1021/jm020194o
[15] F. G. Salituro, C. T. Baker, J. J. Court, D. D. Deininger, E.
E. Kim and B. Li, “Design and Synthesis of Novel Con-
formationally Restricted HIV Protease Inhibitors,” Bio-
organic Medicinal Chemistry Letters, Vol. 8, No. 24,
1998, pp. 3637-3642.
doi:10.1016/S0960-894X(98)00670-2
[16] C. T. Baker, F. G. Salituro, J. J. Court, D. D. Deininger, E.
E. Kim, B. Li, P. M. Novak, B. G. Rao, S. Pazhanisamy,
W. C. Schairer and R. D. Tung, “Design, Synthesis and
Conformational Analysis of a Novel Series of HIV Pro-
tease Inhibitor,” Bioorganic Medicinal Chemistry Letters,
Vol. 8, No. 24, 1998, pp. 3631-3636.
[17] A. K. Ghosh, J. F. Kincaid, W. Cho, D. E. Walters, K.
Krishnan, K. A. Hussain, Y. Koo, H. Cho, C. Rudall, L.
Holland and J. Buthod, “Potent HIV Protease Inhibitors
Incorporating High-Affinity P2-Ligands and (R)-(Hyd-
roxyethylamino)Sulfonamide Isoesters,” Bioorganic Me-
dicinal Chemistry Letters, Vol. 8, No. 6, 1998, pp. 687-
690.
[18] A. K. Ghosh, J. F. Kincaid, W. Cho, D. E. Walters, H.
Cho, Y. Koo, J. Trevino, L. Holland and J. Buthod,
“Structure Based Design: Novel Spirocyclic Ethers as
Nonpeptidal P2-Ligands for HIV Protease Inhibitors,”
Bioorganic Medicinal Chemistry Letters, Vol. 8, No. 8,
1998, pp. 979-982. doi:10.1016/S0960-894X(98)00139-5
[19] A. K. Ghosh, S. Leshchenko-Yashchuk, D. D. Anderson,
A. Baldridge, M. Noetzel, H. B. Miller, Y. Tie, Y. F.
Wang, Y. Koh, I. T. Weber and H. Mitsuya, “Design of
HIV-1 Protease Inhibitors with Pyrrolidinones and Oxa-
zolidinones as Novel P1'-Ligands to Enhance Backbone-
Binding Interactions with Protease: Synthesis, Biological
Evaluation and Protien-Ligand X-Ray Studies,” Journal
of Medicinal Chemistry, Vol. 52, No. 13, 2009, pp. 3902-
3914. doi:10.1021/jm900303m
[20] R. D. Cramer, “Topomer CoMFA: A Design Methodol-
ogy for Rapid Lead Optimization,” Journal of Medicinal
Chemistry, Vol. 46, No. 3, 2003, pp. 374-388.
doi:10.1021/jm020194o
[21] R. D. Cramer, R. J. Jilek and K. M. Andrews, “Topomer
Similarity Searching of Conventional Databases,” Jour-
nal of Molecular Graphics and Modeling, Vol. 20, No. 6,
2002, pp. 447-462. doi:10.1016/S1093-3263(01)00146-2
[22] A. Vedani and M. Dobler, “5D-QSAR: the Key for
Simulating Induced Fit?” Journal of Medicinal Chemistry,
Vol. 45, No. 11, 2002, pp. 2139-2149.
doi:10.1021/jm011005p
[23] A. Vedani, M. Dobler and M. A. Lill, “Combining Pro-
tein Modeling and 6D-QSAR. Simulating the Binding of
Structurally Diverse Ligands to the Estrogen Receptor,” Jou r-
nal of Medicinal Chemistry, Vol. 48, No. 11, 2005, pp. 3700-
3703. doi:10.1021/jm050185q
[24] A. Vedani, M. Dobler, H. Dollinger, M. Hasselbach Kai,
F. Birke and M. A. Lill, “Novel Ligands for the
Chemokine Receptor-3 (CCR3): A Receptor-Modelling
Study Based on 5D-QSAR,” Journal of Medicinal Chem-
istry, Vol. 48, No. 5, 2005, pp. 1515-1527.
doi:10.1021/jm040827u
[25] A. Vedani, “QSAR: Prediction Beyond the Fourth Di-
mension,” Drug Discovery and Development, 2005.
http://www.dddmag.com/qsar-prediction-beyond-the-four
th.aspx.
Copyright © 2011 SciRes. OJMC