Journal of Software Engineering and Applications
Vol.6 No.4A(2013), Article ID:30429,8 pages DOI:10.4236/jsea.2013.64A007
Intelligent System for Parallel Fault-Tolerant Diagnostic Tests Construction
![]()
1Department of Informatics, National Research Tomsk State University, Tomsk, Russia; 2Laboratory of Intelligent Systems, Tomsk State University of Architecture and Building, Tomsk, Russia; 3Department of Computer Systems, Tomsk State University of Control Systems and Radioelectronics, Tomsk, Russia.
Email: ayyankov@gmail.com, svkitler@gmail.com
Copyright © 2013 Anna Yankovskaya, Sergei Kitler. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Received February 13th, 2013; revised March 15th, 2013; accepted March 23rd, 2013
Keywords: Intelligent System; Test Methods of Pattern Recognition; Matrix Model of Knowledge and Data Representation; Revealing of Various Kinds Regularities; Fault-Tolerant Diagnostic Tests; Parallel Algorithm; Irredundant H-Fold Column Coverings of Boolean Matrix
ABSTRACT
This investigation deals with the intelligent system for parallel fault-tolerant diagnostic tests construction. A modified parallel algorithm for fault-tolerant diagnostic tests construction is proposed. The algorithm is allowed to optimize processing time on tests construction. A matrix model of data and knowledge representation, as well as various kinds of regularities in data and knowledge are presented. Applied intelligent system for diagnostic of mental health of population which is developed with the use of intelligent system for parallel fault-tolerant DTs construction is suggested.
1. Introduction
Creating algorithms for diagnostic tests (DTs) construction and their implementation in intelligent systems is very relevant [1-5], since quality of decision-making is essentially dependent on them.
Intelligent systems are used in various semistructured scientific disciplines, such as medicine, geology, construction, engineering, sociology, psychology, military medicine, emergency medicine, genetics and others [6-10].
As a rule, the description of a mathematical model of knowledge representation for the above-mentioned scientific disciplines uses a large features space. This may cause entry or measurement errors of feature values. In order to improve the dependability of decision-making, the DTs construction was proposed in [11,12].
Fault-tolerant diagnostic tests will be called tests that are tolerant to a preassigned number of measurement (entry) errors of characteristic feature values of the objects under investigation [12].
First investigations on the dependability in the automata theory were conducted by von Neumann and Shannon [13]. They have been devoted to the problem of synthesizing reliable machines out of unreliable elements. Subsequently, this theory was developed for the synthesis of discrete automata and applied to the error-correcting coding of internal states of asynchronous automata (tolerant to failures in memory elements) [14,15]. The problems about fault-tolerant DTs construction were first described in [11]. Unlike investigations in the automata theory synthesis, described in [14,15], we applied the dependability theory in pattern recognition for fault-tolerant DTs construction [11,12,16].
The DTs construction problem is NP-hard. With a large feature space for its solution it is required more time and cost expenditures. In this regard, for fault-tolerant DTs construction was proposed to use parallel algorithms [17,18]. In this investigation we proposed modified parallel algorithm for fault-tolerant DTs construction [19,20] implemented in intelligent system. Criteria of optimization of algorithm parallelization for diagnostic tests construction [19] have been the basis for modified parallel algorithm for fault-tolerant DTs construction. Illustrative example is given in this paper. A matrix model of data and knowledge representation, as well as various kinds of regularities in data and knowledge are presented. Also the applied intelligent system for diagnostic of mental health of population developed with the use of intelligent system for parallel fault-tolerant DTs construction is suggested.
2. Matrix Model of Data and Knowledge Representation
In this investigation the construction of fault-tolerant DTs is fulfilled in k-valued data space [3].
We use matrix model [2,3] to represent the data and knowledge.
The model includes an integer description matrix (Q) that describes objects in the space of characteristic features 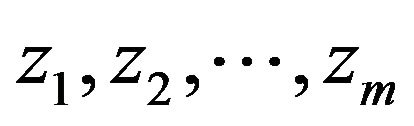 and an integer distinction matrix (R) that partitions objects into equivalence classes for each classification mechanism. A dash (“—”) in the respective element of the matrix Q shows that the value of the feature is not significant to the object. We give the range of values for each feature zj
and an integer distinction matrix (R) that partitions objects into equivalence classes for each classification mechanism. A dash (“—”) in the respective element of the matrix Q shows that the value of the feature is not significant to the object. We give the range of values for each feature zj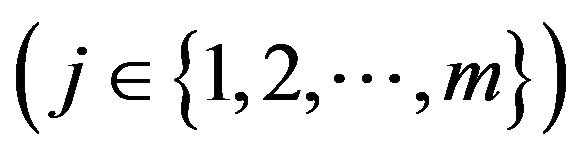 .
.
The set of all nonrepeating rows of the matrix R is compared to the number of selected patterns presented by the one-column matrix R' whose elements are the numbers of patterns.
This model allows us to represent not only data but the expert knowledge, as one row of the matrix Q can be represented as a subset of objects in the interval form, which are characterized with the same final decisions, for the relevant rows of the matrix R.
The matrix model of data and knowledge representation is given in Figure 1.
We use a binary matrix of tests (T) [21] to represent the constructed fault-tolerant DTs, with its columns matched to the columns of the matrix Q and the rows matched to tests. Unit values in each row of the matrix T mark features included in the diagnostic test associated with this row.
3. Revealing Various Kinds of Regularities in Data and Knowledge
For further survey we use the definitions and concepts described in [1,2].
A diagnostic test is a set of features that distinguishes any pair of objects that belong to different patterns.
A diagnostic test is called “irredundant” (dead-end [1]) if it includes an irredundant amount of features.
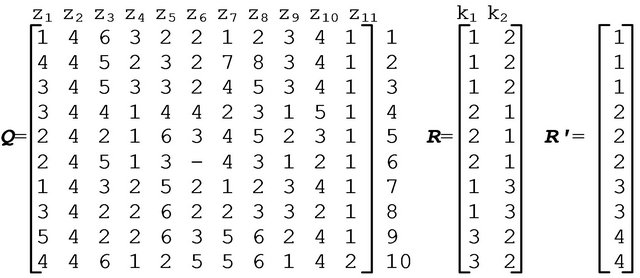
Figure 1. The matrix model of data and knowledge representation.
An irredundant unconditional diagnostic test (IUDT) is characterized by simultaneously presentation of all features of the object under investigation included in test, while decision-making.
Regularities are subsets of features with particular, easy-to-interpret properties that affect the distinguishability of objects from different patterns that are stably observed for objects from the learning sample and are exhibited in other objects of the same nature and weight coefficients of features that characterize their individual contribution [22] to the distinguishability of objects and the information weight given, unlike [6], on the subset of tests used for a final decision-making. These subsets can include constant (taking the same value for all patterns), stable (constant inside a pattern, but non-constant), noninformative (not distinguishing any pair of objects), alternative (in the sense of their inclusion in DT), dependent (in the sense of the inclusion of subsets of distinguishable pairs of objects), unessential (not included in any irredundant DT), obligatory (included in all irredundant DT), and pseudo-obligatory (which are not obligatory, but included in all IUDT involved in decisionmaking) features, as well as all minimal and all (or part, for a large feature space) irredundant distinguishing subsets of features that are essentially minimal and irredundant DTs, respectively. The weight coefficients of characteristic features are also included in regularities [2], as well as the information weight of characteristic features.
We use a procedure for constructing the implication matrix (U) [3] for revealing various kinds of regularities at construction of fault-tolerant IUDTs.
The matrix U is an integer; its columns are matched to the columns of the matrix Q and its rows are matched to all possible pairs of objects v and l from different patterns a and b, respectively (classes, for fixed classification mechanism);
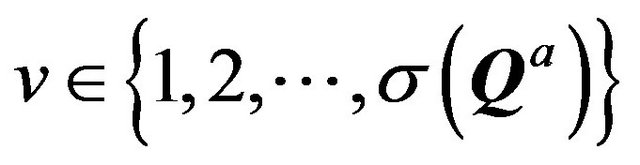 ,
, 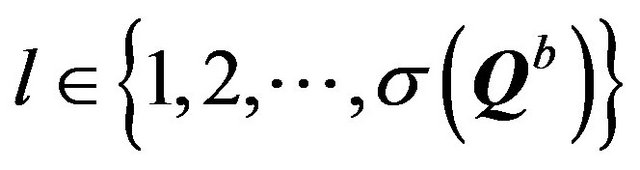 where σ(Qa) (σ(Qb)) is the number of rows in the submatrix Qa (Qb) of the matrix Q. The row Ui of the matrix U represents the value vector-function of the distinguishability, the jth
where σ(Qa) (σ(Qb)) is the number of rows in the submatrix Qa (Qb) of the matrix Q. The row Ui of the matrix U represents the value vector-function of the distinguishability, the jth 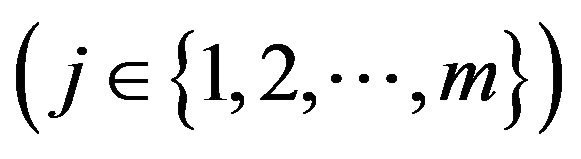 component ui,j of which is calculated by the formula
component ui,j of which is calculated by the formula
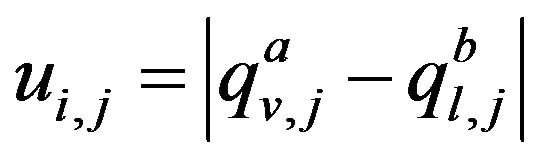 , (1)
, (1)
where 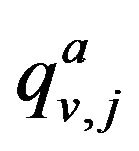
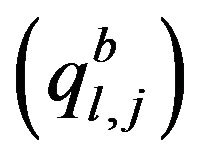 is the value of the features zj for the object v (l), and
is the value of the features zj for the object v (l), and 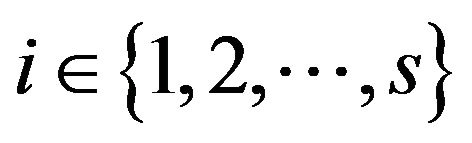 is the set of rows of the matrix U.
is the set of rows of the matrix U.
We say that the row Ub covers the row Uρ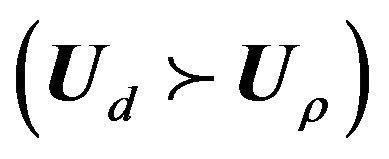 if
if
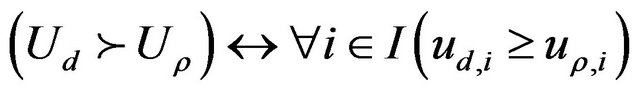
where I is the set of rows of the matrix U.
The implication matrix U' is called irredundant if it has no covering rows [2].
Note that we use the modification of the algorithm for constructing the irredundant implication matrix U' given in [23]. The covering rows with no less than h nonzero values are deleted from the matrix U' in process of its constructing. The value of h depends on the preassigned number t of the measurement (entry) errors of characteristic feature values and formula of its calculation given below. Moreover, the covered rows with less than h nonzero values are deleted. In this case, we fail to ensure the fault-tolerance condition for features matched to the columns of the matrix U included in the covered rows.
Now, we use the matrix U' to define constant, stable, alternative, and dependant features.
If all elements in the column of the matrix U' take the same value, the feature that corresponds to the column is constant. In other words, the constant feature corresponds to the column of the matrix Q consisting of identical elements. A stable feature corresponds to the column of the matrix Q that includes elements of the same value inside the pattern and is not constant.
Alternative features correspond to the same columns of the matrix U'.
Dependant features correspond to columns of the matrix U' covered by another (others) column of the matrix U'.
Data and knowledge analysis, which involves defining the most significant features and estimating their significance [24], is critical when it comes to finding regularities and decision-making.
We present formulas for calculating the value of the weight coefficient of the k-valued jth feature (wj) and the value of the weight of the ith test (Wi) given in [17], which are modifications of formulas from [21] for Boolean features:
wj is weight coefficient of the integer feature zj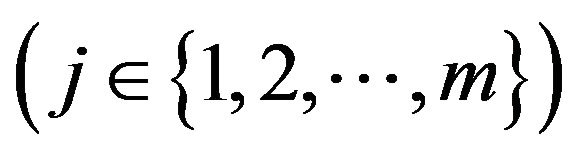 ;
;
qaj is value of feature zj for object from the pattern a;
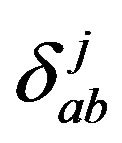 is the value of the jth component of the distinguishing vector-function for objects from different patterns a and b (a ≠ b) calculated by the formula:
is the value of the jth component of the distinguishing vector-function for objects from different patterns a and b (a ≠ b) calculated by the formula:
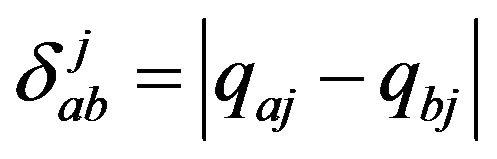 ;
;
Na is the number of rows in the description of the pattern a;
K is the number of patterns singled out;
Sj is the range of values of the jth feature matched to the jth column of the matrix Q;
pl is the repeating coefficient of the lth row given externally;
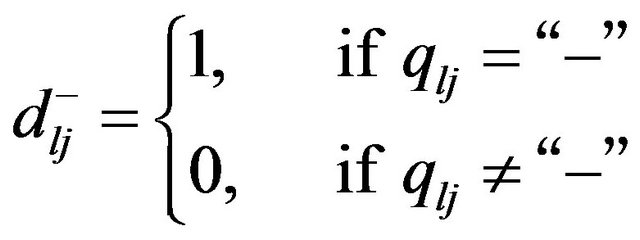 ;
;
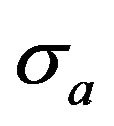 is the quantity of objects in the pattern a
is the quantity of objects in the pattern a 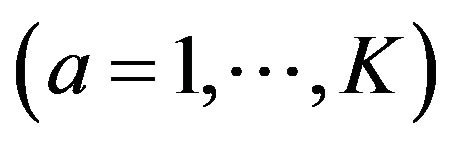 calculated by the formula:
calculated by the formula:
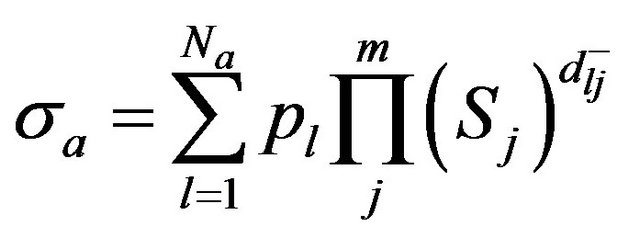 ;
;
r, s (r≠s) and a, b (a≠b) are the numbers of the patterns;
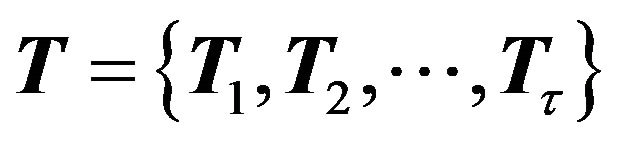 is the set of tests;
is the set of tests;
Li is the set of features included in the test Ti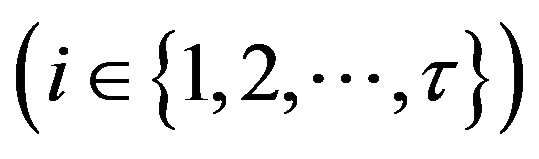 .
.
To find the weight coefficient wj of the integer feature zj, we use its distinguishing ability, which is similar to how wj is calculated for the binary feature zj [7], as follows:
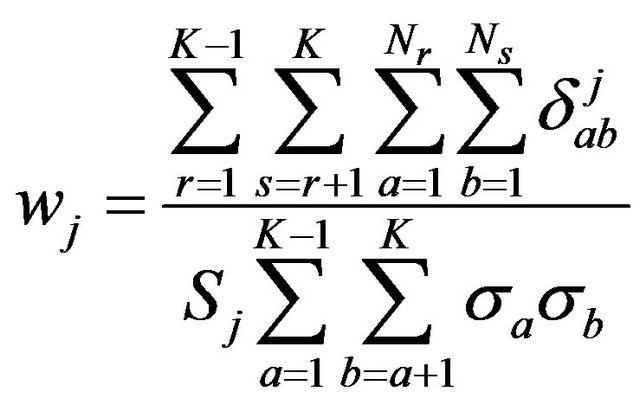 , (2)
, (2)
We call the set of obligatory features the kernel of all DTs, since exclusion of any feature from the kernel disturbs the property of each of the test to be a test.
Each test TiÎT is matched to its weight Wi calculated by the formula
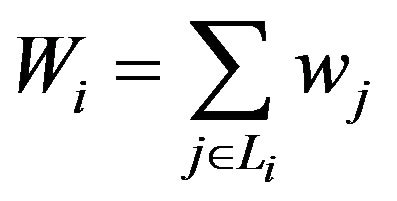 . (3)
. (3)
4. Modified Parallel Algorithm for Diagnostic Tests Construction
4.1. Modified Parallel Algorithm
To construct fault-tolerant IUDTs we will use the sufficient condition for constructing diagnostic tests that are tolerant to the preassigned number of measurement (entry) errors of characteristic features values [25].
We use Ψ(U') to denote the number of the non-zero elements in the row U', and h = 2t + 1.
Theorem 1. For data and knowledge, as well as decision-making, tolerant to the number t of measurement (entry) errors of values of characteristic features to be consistent, it is sufficient to ensure 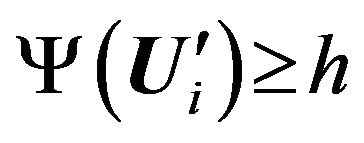 for any row of the matrix U' in the matrix Q for each pair of objects from different patterns.
for any row of the matrix U' in the matrix Q for each pair of objects from different patterns.
Corollary. If the theorem’s hypothesis is not met for the row of the matrix U', one cannot ensure DT fault-tolerance by features, including the non-zero elements of the row.
Below we introduce some notations to describe the algorithm:
i is the level number of matrices Q и R' decomposition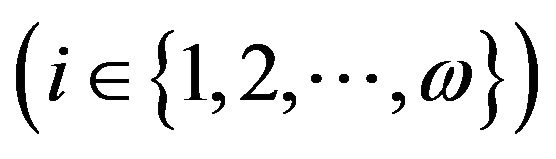 ;
;
j is the number of submatrix Qi,j on ith decomposition level, j is the function of i, viz. j(i) and jÎ{1,2 ![]() ri};
ri};
f is the quantity of patterns in the matrix R';
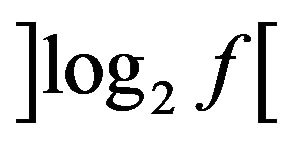 is the least from above whole to
is the least from above whole to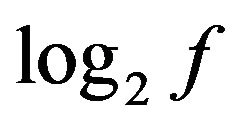 ;
;
ω is the quantity of decomposition level calculated by the formula:
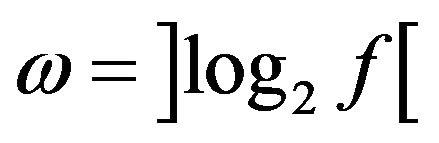 ;
;
η is the coefficient which takes the value η=0 for i ≠ ω and η = 1 for I = ω;
ri is the quantity of submatrix Qi,j on ith decomposition level calculated by the formula:
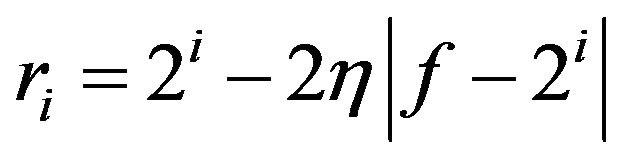 .
.
In this investigation we describe a modified algorithm of fault-tolerant DTs construction taking into account the optimization criteria developed in [19,20]. We propose to optimize loading of processors by the use of starting of decomposition from the last level, viz. from the level ω. The amount of computation in the processing of matrices (Qa, R'a) and (Qb, R'b) the construction of the matrix U' is directly proportional to the value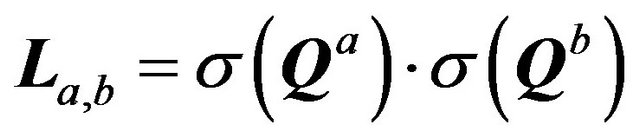 .
.
The decomposition of matrices into submatrices in each ith level of the partition is fulfilled so that the processing time of each pair of submatrix in the ith level was as close to each other (exact equality is not always possible due to the solution of real problems in which typically, the number of objects in each pattern is not the same). Then time to the matrix U' construction processors at the same level of the partition will be as close to each other, thus providing a more balanced processors loading [19].
Amount iterate by the construction of the matrix U' in the processing of each pair of submatrices (Qa, R'a) and (Qb, R'b) is proportional to the quantity of La,b.
When the number of patterns is equaled to 2n (where n is an integer in the original matrices Q, R'), the goal of determining the pairs reduces to constructing 2n–1 pairs of submatrices (Qa, R'a) and (Qb, R'b), each of which contains only one pattern, then the construction of 2n–2 pairs of submatrices, each of which contains two patterns, etc. as long as each pair of submatrices do not contain 2n-1 patterns.
When the number of patterns is not equaled to 2n, the decomposition process ends for some submatrices at level ω-1 and for the other—at level ω.
Below modified parallel algorithm for k-valued faulttolerant IUDTs construction is given.
1) Sort matrices Q and R' rows along membership patterns.
2) i = 1, j = 1.
3) Decomposition of each pair submatrices Qi,j and 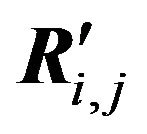 on two pair submatrices (Qi+1,j and
on two pair submatrices (Qi+1,j and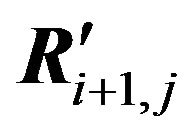 ) and (Qi+1,j+1 and
) and (Qi+1,j+1 and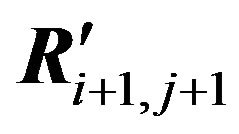 ) so that σ(Qi+1,j) and σ(Qi+1,j+1) will be maximally close.
) so that σ(Qi+1,j) and σ(Qi+1,j+1) will be maximally close.
4) Parallel construction of submatrices 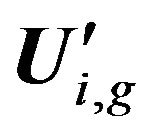 (where g is a number of submatrices
(where g is a number of submatrices 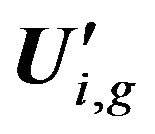 on ith decomposition level,
on ith decomposition level,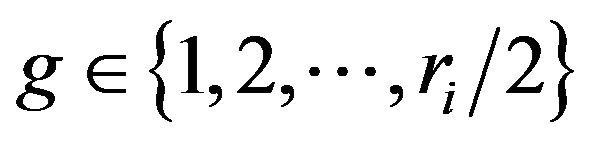 ) to submatrices Qi,j and
) to submatrices Qi,j and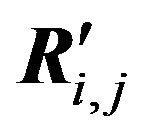 . Submatrices
. Submatrices 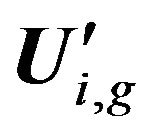 construction is fulfilled by using Formula (1). Each submatrix
construction is fulfilled by using Formula (1). Each submatrix 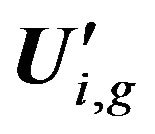 added in matrix U' with simultaneously deleting covers rows and calculating weight coefficients of features by Formula (2). Note that the matrix U' received after deleting of the covered rows newly is also denoted by U'.
added in matrix U' with simultaneously deleting covers rows and calculating weight coefficients of features by Formula (2). Note that the matrix U' received after deleting of the covered rows newly is also denoted by U'.
5) If j ≠ ri than j = j + 2. Else j = 1, i = i + 1.
6) If i ≠ ω then go to point 3.
7) Construction of Boolean matrix 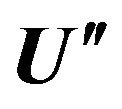 by substitution of all non-zero elements value in matrix U' on value (1).
by substitution of all non-zero elements value in matrix U' on value (1).
8) Check to ensure sufficient condition for fault-tolerant diagnostic tests construction (theorem 1). If the check is fulfilled then go to point 12.
9) Revealing various kinds of regularities of matrix 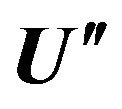 by algorithm described in [2].
by algorithm described in [2].
10) Parallel construction of all irredundant h-fold column coverings of matrix 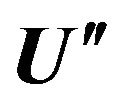 or part thereof if quantity of irredundant h-fold column coverings exceeds preassigned value g in process of their construction. The construction is fulfilled by algorithm described in [18].
or part thereof if quantity of irredundant h-fold column coverings exceeds preassigned value g in process of their construction. The construction is fulfilled by algorithm described in [18].
11) Construction all fault-tolerant IUDTs by found irredundant h-fold column coverings of matrix 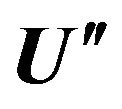 and go to point 13.
and go to point 13.
12) Extension of a definition of matrix Q and go to point 2.
13) End.
Figure 2 shows the tree of constructing the matrix U' based on multilevel decomposition of the matrices Q and R' into submatrices. We match the root of the tree with the matrices Q and R'. We match the tops of the ith 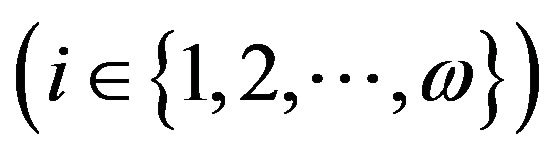 level of a tree with the submatrices Qi,j
level of a tree with the submatrices Qi,j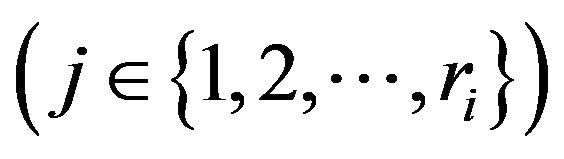 ,
, 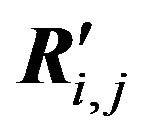 and Qi,j+1,
and Qi,j+1, 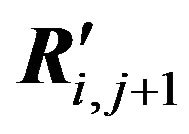 , and submatrices
, and submatrices 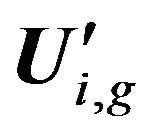 constructed using these tops, where
constructed using these tops, where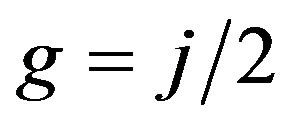 .
.
4.2. Illustrative Example
We present example of submatrices U'i,g construction using modified parallel algorithm.
Let the number of patterns in matrices Q and R' be 9.
Step 1. Ordering rows of matrices Q and R' along membership patterns. Let in result ordering the number of objects in patterns 1-9 equal respectively 12, 10, 9, 8, 6, 5, 4, 3, 3.
Step 2. i: = 1, j: = 1.
Step 3. Decomposition of patterns set {1, 2, 3, 4, 5, 6, 7, 8, 9} into two subsets {2, 3, 6, 8, 9} and {1, 4, 5, 7}. In this case, the number of rows in each subset equals 30.
Step 4. Construction of the submatrix U'1,1. Herewith the amount of calculations at submatrix U'1,1 construction is directly proportional to value 900.
Step 5. j: = 1, i: = 2, since j = r1 = 2 (r1 is calculated by formula 3).
Step 6. Condition of algorithm point 6 is not satisfied and go to algorithm point 3, since i ≠ ω + 1 (ω=4, ω is calculated by formula 4).
Step 7. Decomposition of patterns subset {2, 3, 6, 8, 9} into subsets {2, 6} and {3, 8, 9}. In this case, the number of rows in pair of subsets equals 15 and 15 respectively.
Step 8. Construction of the submatrix U'2,1. Herewith the amount of calculations of submatrix U'2,1 construction is directly proportional to value 225.
Step 9. j: = 4 and go to algorithm point 3, since j = 2 and r2 = 4 (r2 is calculated by formula 3).
Step 10. Decomposition of patterns subset {1, 4, 5, 7} into subsets {1, 7} and {4, 5}. In this case, the number of rows in pair of subsets equals 16 and 14 respectively.
Step 11. Construction of the submatrix U'2,2. Herewith the amount of calculations of submatrix U'2,2 construction is directly proportional to value 224.
Step 12. j: = 1, i: = 3, since j = r2 = 4.
Step 13. Condition of algorithm point 6 is not satisfied and go to algorithm point 3, since I ≠ ω + 1.
Step 14. Decomposition of patterns subset {2, 6} into subsets {2} and {6}.
Step 15. Construction of the submatrix U'3,1. Herewith the amount of calculations of submatrix U'3,1 construction is directly proportional to value 50.
Step 16. j: = 4 and go to algorithm point 3, since j = 2 and r3 = 8 (r3 is calculated by formula 3).
Step 17. Decomposition of patterns subset {3, 8, 9} into subsets {3} and {8, 9}.
Step 18. Construction of the submatrix U'3,2. Herewith the amount of calculations of submatrix U'3,2 construction is directly proportional to value 54.
Step 19. j: = 6 and go to algorithm point 3, since j = 4 and r3 = 8.
Step 20. Decomposition of patterns subset {1, 7} into subsets {1} and {7}.
Step 21. Construction of the submatrix U'3,3. Herewith the amount of calculations of submatrix U'3,3 construction is directly proportional to value 48.
Step 22. j: = 8 and go to algorithm point 3, since j = 4 and r3 = 8.
Step 23. Decomposition of patterns subset {4, 5} into subsets {4} and {5}.
Step 24. Construction of the submatrix U'3,4. Herewith the amount of calculations of submatrix U'3,4 construction is directly proportional to value 48.
Step 25. j: = 1, i: = 4, since j = r3 = 8.
Step 26. Condition of algorithm point 6 is not satisfied and go to algorithm point 3, since I ≠ ω + 1.
Step 27. Decomposition of patterns subset {8, 9} into subsets {8}, {9}.
Step 28. Construction of the submatrix U'4,1. Herewith the amount of calculations of submatrix U'4,1 construction is directly proportional to value 9.
Step 29. j: = 1, i: = 5, since j =r4 = 2 (r4 is calculated by formula 3).
Step 30. Since condition of algorithm point 6 is satisfied then go to algorithm point 7.
Thus, the total time of processors loading necessary to construct submatrices U'i,g is directly proportional to the value 1198.
Since the example illustrates the total time of processors loading necessary to construct submatrices U'i,g then omit the rest points of the algorithm.
We give an example where the decomposition is fulfilled without optimization criteria.
We fulfill the decomposition of the patterns subset {1, 2, 3, 4, 5, 6, 7, 8, 9} into two subsets {1, 2, 3} and {4, 5, 6, 7, 8, 9}. Moreover the number of rows in the subsets equals 31 and 29 respectively, and the amount of calculations is directly proportional to the value 899. Subsequent decomposition will lead to irregular processors loading: maximal processor loading on the second level is directly proportional to the value 228, maximal processor loading on the third level is directly proportional to the value 90 and maximal processor loading on the fourth level is directly proportional to the value 30. Thus, the total time of processors loading at all levels is directly proportional to the value 1347.
The above-mentioned example shows the advantage of the modified algorithm.
5. Description of Intelligent System
The above modified parallel algorithm for fault-tolerant DTs construction is implemented in intelligent system. This system is created as a dynamically plug-in and is included in intelligent instrumental software (IIS) IMSLOG [26]. The IIS IMSLOG is intended for the construction of intelligent systems for different application areas.
The IIS IMSLOG architecture is open and represents a hierarchic system of software modules developed in the environment in Builder C++.
One module, which was implemented as residential, has a built-in system of commands, acts as a coordinating center, and is called a kernel. All other modules are
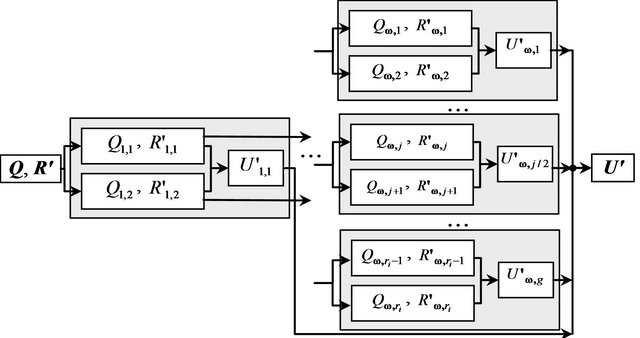
Figure 2. Three of matrix U' construction.
dynamically pluggable (called plug-ins) and divided into functional modules, system data modules, and a basic module of the intelligent user interface.
Functional modules implement particular subsystems and functions, including different approaches and algorithms of test pattern recognition.
The intelligent system for parallel fault-tolerant DTs construction is one of the functional modules. The library of this module classes consists of mathematical objects (k-valued vectors and k-valued, Boolean matrices), which are created, processed, and deleted dynamically. The original matrices Q and R', the range of values of characteristic features, and the preassigned number t of measurement (entry) errors of values of characteristic features are the input data for the functional module. All (or part, for a big feature space) k-valued fault-tolerant IUDTs are output data.
System data modules store informational structures used in the process. The basic module of the intelligent interface ensures the interactive interaction of the user and the kernel on a limited natural language via an intelligent graphic shell or (if needed) a console application. The kernel consists of an interpreter of the built-in system of commands and a plug-in manager that ensure automatic connection and registration of all plug-ins, their real-time dynamic upload and download, transfer of control and information exchange between plug-ins, and control of their correct performance.
All plug-ins consist of a registration block, which is needed for them to be automatically connected to the kernel and for the dynamic invocation to perform, and a software gateway to ensure the registered system commands are called correctly, RAM required to store system data structures is allocated dynamically, the results of command execution are transferred, and control is returned to the kernel once the function corresponding to this plug-in ends its operation.
The built-in subsystem that creates and implements the operation scenarios (templates) is used to synchronize operation of separate components and control information flows as plug-ins are performed in IIS IMSLOG. The subsystem allows the real-time formation of a connected component network and establishes the interconnection relations (one-to-one or one-to-many) between the inputs and outputs of functional modules.
In the constructed scenario, we can monitor the executed processes, view the obtained intermediary values of the system variables, and (if needed) change the course of information processing by correcting values of transmitted data or by blocking/activating components of the template, which undoubtedly adds flexibility, which is especially useful in scientific research.
The IIS IMSLOG software leverages ideas and principles of structural nonlinear and object-oriented programming. The final software product is implemented in Borland C++ Builder and Windows API and GUI.
The OpenGL library was used to create cognitive tools. User interactions are carried out as an intelligent multiwindow MDI interface.
6. Applied Intelligent System for Diagnostic of Population Mental Health
The described above intelligent system for fault-tolerant DTs construction is designed to applied intelligent systems for a number of problem areas.
In this section we will present an applied intelligent system for diagnostic of population mental health.
Currently highly relevant research topics worldwide are mental and behavioral disorders, such as affective [27-31]. Depression refers to affective disorders. Mortality in depression is only slightly inferior to mortality from cardiovascular diseases. Therefore, the need for development of applied intelligent systems for diagnostic of depression is not in doubt.
For the applied intelligent system as a feature space the space of k-valued symbols is used [30]. Their values are determined from the responses to the inquirer, analogically constructed as in [31].
However, as used in this paper the inquirer also revealing one of the three severity degrees of depression (mild, moderate or severe) differs by greater number of questions, viz. it contains 24 questions. The increase in the number of questions is related to fault-tolerant DTs construction. Thus, wrong answer(s) on some questions can be compensated by the decision-making by taking into account fault-tolerance of DTs.
To clarify it, the basis of inquirer is the diagnostics criteria of international classification of diseases, tenth revision (ICD-10) [32] and Beck conception [30]. The Beck conception allows taking into account the severity degree of symptoms (features), which significantly affects the result of the reliability of decision-making. Thus, complex of features and their degree of severity has been used for revealing of depression and its severity form.
Currently, the applied intelligent system for diagnostic of mental health of the population is on stage of approbation.
7. Conclusions
The intelligent system for parallel fault-tolerant diagnostic tests construction is described. The modified parallel algorithm for fault-tolerant diagnostic tests construction, which implemented in intelligent system, is given. The algorithm provides a more uniform loading of processors for irredundant implication matrix construction thereby reducing the time spent in parallelizing process of the DTs construction.
The applied intelligent system for diagnostic of mental health of population which is developed with the use of intelligent system for parallel fault-tolerant DTs construction is suggested.
For the first time, a combination of different approaches [30,32] for the diagnostic of population mental health is used. It is allowed to get a synergistic effect in diagnostic decision-making.
Future investigation is connected with construction of complex of intelligent systems for diagnostic and prevention of depression, which is based on intelligent system for parallel fault-tolerant diagnostic tests construction.
8. Acknowledgements
This research is funded by grant from the Russian Foundation for Basic Research (project No. 13-07-00373a and project No. 12-07-31109-mol_a) and by grant from the Russian Humanitarian Scientific Foundation (project No. 13-06-00709).
Professor MD department chief of clinical psychology of Siberian State Medical University Kornetov A. N. and department assistant of clinical psychology of Siberian State Medical University Silaeva A. V. are greatly appreciated for consultation in area of depression diagnostic by creation of applied intelligent system.
REFERENCES
- Y. I. Zhuravlev, V. V. Ryazanov and O. V. Sen’Ko, “Recognition. Mathematical Methods. Program System,” Practical Applications, Fazis, 2006 [in Russian].
- A. E. Yankovskaya, “Logical Tests and Means of Cognitive Graphics in Intelligent System,” Proceedings of the 3rd Russian National Conference with Foreign Participants of the New Information Technologies in Investigations of Discrete Structures, Tomsk, 12-14 September 2000, pp. 163-168 [in Russian].
- A. E. Yankovskaya, “Construction of k-Valued Diagnostic Tests in an Intelligent System with Matrix Knowledge Representation,” Proceedings of 6th National Conference with International Participation on Artificial Intelligence, Pushchino, 5-8 October 1998, pp. 264-269 [in Russian].
- A. Yankovskaya and A. Gedike, “Finding of All Shortest Column Coverings of Large Dimension Boolean Matrices,” Proceedings of the 1st International Workshop on Multi-Architecture Low Power Design (MALOPD), Moscow, 13-14 September 1999, pp. 52-60.
- A. I. Gedike and A. E. Yankovskaya, “Construction of All the Irredundant Unconditional Diagnostic Tests in the IMSLOG Intelligent Software Tool,” Proceedings of International Scientific-Technical Conference of AIS’05, CAD-2005, Gelendzhik, 3-10 September 2005, pp. 209- 214 [in Russian].
- F. P. Krendelev, A. N. Dmitriev and Y. I. Zhuravlev, “Comparing the Geological Structure of Foreign Depositions of Precambrian Conglomerates by Means of Discrete Mathematics,” Reports of the Sciences Academy USSR, Vol. 173, No. 5, 1967, pp. 1149-1152 [in Russian].
- A. E. Yankovskaya, “Test Recognition Medical Expert Systems with Cognitive Graphics Elements,” Komp’ Yuternaya Khronika, No. 8-9, 1994, pp. 61-83 [in Russian].
- A. E. Yankovskaya, A. I. Gedike, N. N. Il’Inskikh and G. E. Chernogoruk, “The Principles of the Development of an Intelligent Test Biomedical System,” Pattern Recognition and Image Analysis, Vol. 11, No. 2, 2001, pp. 484- 487.
- A. E. Yankovskaya and S. V. Kitler, “Hybrid Intelligent System for Organizational Stress Diagnostics and Correction by Using Combination of Matrix and Criteria Approaches,” Proceedings of VIth International ScientificTechnical Conference of Integrated Models and Soft Calculations in Artificial Intelligence, Vol. 2, Kolomna, 16- 19 May 2001, pp. 832-843 [in Russian].
- A. E. Yankovskaya and S. V. Kitler, “Innovative Technology for Intelligent Extension of Geoinformation Systems,” Proceedings of the Congress on Intelligent Systems and Information Technology, Vol. 2, Gelendzhik, 2- 9 September 2009, pp. 43-50 [in Russian].
- A. E. Yankovskaya, “Choosing an Optimal Number of Features in the Presence of Measurement Error as Applied to Medical Diagnostics Problems,” Proceedings of All-Union Conference of Technical Problems in Medicine, Tomsk, 1983, pp. 18-19 [in Russian].
- A. E. Yankovskaya, “Decision-Making, Tolerant to Measuring Errors of Features Values in Intelligent Systems,” Proceedings of the 10th International Science Technical Conference of Artificial Intelligence, Intelligent Systems, Taganrog, 28 September-3 October 2009, Gelendzhik, pp. 127-130 [in Russian].
- C. Shannon and Von Neumann’s, “Contributions to Automata Theory,” Bulletin of the American Mathematical Society, Vol. 64, No. 2, 1958, 123 Pages.
- A. E. Yankovskaya, “Noise Resistant Coding of Internal State of Asynchronous Finite State Machines,” Proceedings of 3rd Symposium on Redundancy Application in Information Systems, Leningrad, 17-22 June 1968, pp. 61- 63 [in Russian].
- A. D. Zakrevskij and A. E. Yankovskaya, “Noise Resistant Coding of Internal States of Asynchronous Finite State Machines,” Information Materials, Vol. 3, No. 50, 1971, pp. 53-58 [in Russian].
- A. E. Yankovskaya and S. V. Kitler, “Intelligent Subsystem of Tolerant Diagnostic Tests Construction in K-Valued Feature Space,” Proceedings of the Congress on Intelligent Systems and Information Technology, Vol. 3, Gelendzhik, 2-9 September 2010, pp. 343-350 [in Russian].
- A. E. Yankovskaya and S. V. Kitler, “Decision-Making on the Basis of Parallel Algorithms of Test Pattern Recognition,” Artificial Intelligence, No. 3, 2010, pp. 151- 159 [in Russian].
- A. E. Yankovskaya and S. V. Kitler, “Parallel Algorithm for Constructing k-Valued Fault-Tolerant Diagnostic Tests in Intelligent Systems,” Pattern Recognition and Image Analysis, Vol. 22, No. 3, 2012, pp. 473-482. doi:10.1134/S105466181203008X
- A. E. Yankovskaya, “Optimization Algorithm Parallelization of Diagnostic Tests Construction,” Proceedings of 15th All-Russian Conference of Mathematical Methods for Pattern Recognition, Moscow, Petrozavodsk, 17-19 September 2011, pp. 92-95 [in Russian].
- A. E. Yankovskaya and S. V. Kitler, “Optimization of Parallel Algorithm for k-Valued Fault-Tolerant Diagnostic Tests Construction,” Proceedings of 4th Russian National Multiconference on Problems Management, Vol. 1, Gelendzhik, 3-8 October 2011, pp. 53-56 [in Russian].
- A. E. Yankovskaya and V. I. Mozheiko, “Optimization of a Set of Tests Selection Satisfying the Criteria Prescribed,” Proceedings of 7th International Conference on Pattern Recognition and Image Analysis: New Information Technologies (PRIA-7-2004), Vol. I, Moscow, 21-25 January 2004, pp. 145-148.
- A. E. Yankovskaya and A. I. Gedike, “Construction of the Implication Matrixes for Regularities Revealing in Intelligent Recognition Systems,” MEPhI-2008 Scientific Session. Collection of Papers, Vol. 10, 2008, pp. 81-82 [in Russian].
- S. I. Kolesnikova and A. E. Yankovskaya, “Estimation of Significance of Features for Tests in Intelligent Systems,” Journal of Computer and Systems Sciences International, Vol. 47, No. 6, 2008, pp. 930-943.
- A. E. Yankovskaya, “Minimization of Orthogonal Disjunctive Normal Forms of Boolean Function to be Used as a Basis for Similarity and Difference Coefficients in Pattern Recognition Problems,” Pattern Recognition and Image Analysis, Vol. 6, No. 1, 1996, pp. 60-61.
- A. E. Yankovskaya, “Suboptimal Decisions-Making in Intelligent Systems Based on Test Methods of Pattern Recognition,” Proceedings of 12th National Conference on Artificial Intelligence with International Participation, Vol. 3, Tver, 20-24 September 2010, pp. 170-178 [in Russian].
- A. E. Yankovskaya, A. I. Gedike, R. V. Ametov and A. M. Bleikher, “IMSLOG-2002 Software Tool for Supporting Information Technologies of Test Pattern Recognition,” Pattern Recognition and Image Analysis, Vol. 13, No. 4, 2003, pp. 650-657.
- J. Angst and K. R. Merikangas, “Multi-Dimensional Criteria for Thediagnosis of Depression,” Journal of Affective Disorders, Vol. 62, No. 1, 2001, pp. 7-15. doi:10.1016/S0165-0327(00)00346-3
- P. Svanborg and M. Asberg, “A Comparison between the Beck Depression Inventory (BDI) and the Self-Rating Version of the Montgomery Asberg Depression Rating Scale (MADRS),” Journal of Affective Disorders, Vol. 64, No. 2-3, 2001, pp. 203-216. doi:10.1016/S0165-0327(00)00242-1
- “Depression,” Bulletin of the World Health Organization, No. 369, 2012. http://www.who.int/mediacentre/factsheets/fs369/en/
- A. T. Beck, C. Ward and M. Mendelson, “Beck Depression Inventory (BDI),” Archives of General Psychiatry, Vol. 4, No. 6, 1961, pp. 561-571. doi:10.1001/archpsyc.1961.01710120031004
- A. E. Yankovskaya, A. E. Silaeva and S. S. Rakitin, “Informational Technology of Diagnostic and Prevention of Depression of Surveyed which Based on Threshold and Fuzzy Logic,” Proceedings of International Conference New Informational Technology and Management of Quality, Moscow, 25 May-1 June 2012, pp. 179-182 [in Russian].
- World Health Organization, “The International Classification of Diseases, Tenth Revision (ICD-10). Clinical Descriptions and Diagnostic Guidelines,” World Health Organization, Geneva, 1992.