Communications and Network
Vol. 4 No. 3 (2012) , Article ID: 22086 , 13 pages DOI:10.4236/cn.2012.43029
P2P Business Applications: Future and Directions
MIS and Decision Sciences, Eberly College of Business & Information Technology, Indiana University of Pennsylvania, Indiana, USA
Email: pankaj@iup.edu
Received May 20, 2012; revised June 18, 2012; accepted July 17, 2012
Keywords: Peer-to-Peer; Business Applications; P2P; Characteristics; Issues; Business Models
ABSTRACT
Since the launch of Napster in June 1999, peer-to-peer technology (P2P) has become synonymous with file sharing applications that are the bane of the recording industry due to copyright infringements and consequent revenue losses. P2P promised a revolution in business computing which has not arrived. It has become synonymous with illegal file sharing and copyright violations. Meanwhile the information systems industry has undergone a paradigm change, and we are supposedly living in a world of cloud computing and mobile devices. It is pertinent to examine if P2P, as a revolutionary technology, is still relevant and important today and will be in future. One has to examine this question in the context of the fact that P2P technologies have matured but have however had limited adoption outside file‑sharing in the consumer space. This paper provides a detailed analysis of P2P computing and offers some propositions to answer the question of the relevancy of P2P. It is proposed that P2P is still a relevant technology but may be reshaped in the coming years in a different form as compared to what exists today.
1. Introduction
Peer-to-Peer computing burst into prominence with the launch of Napster in 1999. The following few years branded P2P computing as the next killer technology. Chairman of Intel, Andy Grove said, “P2P revolution will change the world as we know it” [1]. Traffic volumes related to P2P applications surged and still account for a sizable fraction of the total traffic [2,3]. Closed P2P communities have emerged in popularity on the Internet in recent years [4]. As with all new ideas P2P, has gone through several transitions, it has evolved, and it has come to stand for various things (primarily as a tool for illegal file-sharing). It appears that even before it has matured and stabilized, it is no longer the technology everyone is talking about. The current talk is all about cloud computing (both public and private clouds). The vision of all aspects of computing as a service/utility finally seems to have taken hold. There are infrastructure services like Amazon Elastic Cloud (EC2), application services like Salesforce.com, and several others. In addition the continuous shift to mobile computing using clients with limited processing power, storage, and battery life, has shifted the focus more towards a more centralized thin-client server computing model. In this model, the server performs most of the resource-intensive tasks, and the network connectivity becomes an important consideration. Commenting upon a recent “MIT Sloan CIO Symposium”, Wall Street Journal reported that, “Pretty much everyone agrees that we are in transition from the tethered, connected world of PCs, browsers and classic data centers to the untethered, hyper-connected world of smart mobile devices and cloud computing” [5]. This is not to say that desktop computing is not important anymore. Due to the technology constraints of the mobile devices, any knowledge work requiring intense computing still needs a desktop (or desktop like) computer.
Thanks to the Internet, computing today in some fashion is becoming, and has become, more centralized, both in terms of control and location of processing. Considerations driving this trend include issues like keeping Total Cost of Operations (TCO) down, security, and the provision of enterprise desktop applications at remote locations, etc. Another big driver has been the increased use of limited-capability mobile client devices by consumers. These mobile devices necessitate the use of powerful machines at the backend to satisfy processing and storage needs that cannot be fulfilled by the client. For example, if one wants to play certain games on a mobile device, one has to resort to a backend server for generating the graphics elements that are displayed on the screen of the mobile device as the mobile device does not possess the processing power required to generate these graphics elements.
P2P is an idea based on a decentralized processing and storage architecture. Some elements of these architectures may be centralized for control purposes as in hybrid P2P configurations [6] and in grid computing; or there may be no central control elements; or there may be transient central control elements (as in Gnutella where highly reliable nodes called ultra-peers form a central backbone) [7]. Most processing is performed by a distributed pool of computing nodes as per their capability and capacity. In cases where the computing nodes have limited processing and storage capabilities, the distributed computing has to be limited to those tasks appropriate for that platform. In terms of overhead, one may need to balance the network, coordination, and control overhead with the limited processing and storage available on the nodes. This is more likely to make distributed computing costs inefficient in the case of current mobile devices. Though there have been some implementations of P2P applications in the mobile environment. For example the MediaMobile innovation project studied and experimented with P2P technologies applied to mobile terminals using JXME [8]. It demonstrated the viability of grouping different devices as peers (PCs, servers and mobile terminals) and integrated P2P functionality in a prototype game that used location-based services, advanced multimedia features, and other functionalities.
2. Research Objective
It appears that P2P may not be as relevant as it was in the world dominated by desktop computing. It may be even on its way out and it may not change the world as Andy Grove (Intel’s Chairperson) had anticipated. As mentioned previously, computing is becoming more and more centralized, driven by trends like cloud computing, infrastructure as a utility/service, increased use of limited capability mobile client devices, applications service providers, storage service providers, virtualization, etc. Forrester Research predicts that tablets will soon become the primary computing device of choice for millions around the world, with cloud services used to store the majority of data [9]. In the same vein, several pundits have predicted an industry shakeup in the next five years, which they call the Post-PC era that would be dominated by cloud computing, virtualization, virtual desktop infrastructure, and other technologies facilitating the use of mobile devices on a mass-scale [10]. In light of these developments, this paper seeks to answer the question: “Is P2P computing still relevant today and what would be the possible future of this technology”? A set of propositions are developed that answer these questions and may be explored in further research.
3. Research Approach
To answer the research question, a detailed analysis of P2P computing is provided. A detailed treatment is needed to make an informed decision about the viability of the technology and its future evolution. The goal is to define P2P computing as narrowly and specifically as possible such that subject and scope of interest is unambiguous. Secondly, some issues associated with the P2P computing paradigm that would be of concern to businesses trying to use this technology are examined. Thirdly, business models that may be employed to overcome and/or address the issues associated with P2P computing are proposed. Lastly, we will critically examine if any of the business models are viable for implementation or already have been implemented in the current environment, and what the future may hold for P2P computing. The discussion of issues and models is important since survival of P2P as a mainstream technology is directly linked to adoption, and there has not been a critical uptake of P2P technologies in the mainstream business world.
4. P2P Computing Architecture
In principle, everything offered by the current wave of P2P technologies has existed for a long time and has been used for several years. One may pose the question as to what is exciting and different from what has existed for the last three decades. If one examines the history of computer networks, one may say that it would be the involvement of consumer or end-user devices with good network connectivity and a decentralized span of control that is new.
The P2P foundations have existed for a long time, at least since Transmission Control Protocol/Internet Protocol (TCP/IP) was conceived. Computer networks, by definition, are comprised of computers that communicate with each other as peers at least till the Open Systems Interconnection (OSI) transport layer (refer to Figure 1). Routers, domain controllers, and various other infrastructure elements that control and regulate operations on a network, all operate in a peer-to-peer mode. Traditionally, it is the top three layers of the OSI model (application, session, and presentation: refer to Figure 1) that have functioned in a master-slave or non-peer mode. The master-slave roles are typically decided based on the amount of computing and storage that is required and is available. The master (server) typically performs the bulk of the task in a transaction, and client performs a limited role, and the roles are typically fixed.
The promise of the latest evolution of P2P technologies is to extend the server behavior to consumer devices like desktops, laptops, and even mobile devices, which have been typically relegated to the role of a client. This becomes possible due to the increased processing and storage capacities of these machines, and their omnipresent network connection either through residential broadband or corporate network. Most desktop and laptops sold today now have the capabilities of performing
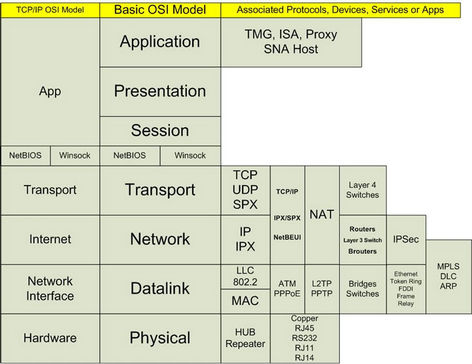
Figure 1. OSI seven layer model (http://social.technet.microsoft.com/Forums/zh/winserverNIS/thread/c2967d5c-6173-4ff4-907d-d31055c34741).
tasks that have been previously performed on more powerful computers or servers [11]. At the same time, the end-user use of resources on these computing devices is neither extensive nor continuous. As a result, these computing devices have spare resources available [12]. There is a potential for the resources to be employed for other tasks. These resources are also accessible remotely due to device’s network presence and can be tapped through an application stack that provides the needed functionality of connecting these devices on the network for accessibility, running applications from third parties, routing, etc. Creating a vast network of these end-user devices, and tapping their unused processing cycles and storage for the benefit of businesses, research institutions, etc., is the promise of the P2P technologies.
It should be pointed out that not all applications and tasks can benefit from P2P computing architecture involving multiple computing nodes acting as peers. It is contingent on both the nature of the task, and the design of the software application. An example of a task that may benefit from P2P architecture would be contentsharing amongst knowledge workers. Here the pertinent artifacts on each knowledge worker’s computing device may be made available to others without relying on central storage. This is basically file-sharing without a file server. An example of an application designed for this task would be Gnutella [13].
5. P2P Architecture Characteristics
There are some salient characteristics of a P2P architecture stemming from the use of end-user computing devices (either individually or corporate-owned). In order to be unambiguous and explicit about the architecture, these characteristics are explicated below:
1) Involves a software application that uses the resources available on multiple end-user computing equipment connected to the Internet (or a data network in a restrictive sense).
2) The resources being used on the end-user computing equipment are primarily spare computing resources available, and this equipment is being used by the end-users for their normal day-to-day work and/or routine tasks.
3) Spare processing cycles and/or storage resources from the end-user equipment are used for some useful business, organizational, or societal task(s) (at least as viewed by a segment of the society).
4) The pool of computing equipment is dynamic, and computing equipment (nodes) can enter and leave the pool at will, or in a random fashion.
5) Each node in the network can act as a server and client at the same time.
6) Computing nodes are diverse in nature. There is diversity in terms of both hardware and the software stack that these end-user computing devices are running.
All of these characteristics are important and should be present. For example, many supercomputers have been built using PCs working in unison. However the PCs being used are not end-user devices being used by an end-user. The end-user computing device in this context is solely dedicated to the supercomputing architecture, and not used by end-users, and therefore is not the purview of the P2P computing discussion that is the focus of this paper.
6. P2P, Utility, Cloud, and Grid Computing
A relevant question is how the current wave of P2P technology is related to concepts like utility computing and grid computing. Utility computing is defined as the business model and associated technologies for provisioning computing capacity to organizations based on their demand patterns [14], sometimes primarily to meet peak demands. This model has the ability to have a totally variable costing structure and not have any fixedcost component. Some “Infrastructure as a Service” (IaaS) providers like Amazon’s EC2 provide such facility. Utility computing allows organizations to save money by not requiring investment in equipment meant primarily to meet peak demands. P2P technologies may also be used to provide additional capacity for utility computing, though utility computing uses server-class computing equipment in a data center. The data center serves several organizations simultaneously. Utility computing and cloud computing are somewhat similar in their use of server-class computing equipment in a data center. However the scope of cloud computing is broader and subsumes utility computing. Cloud computing is broadly defined to include Software as a Service (SaaS), Utility Computing, Web Services (e.g. Google maps with a well-defined API), Platform as a Service (PaaS), Managed Service Providers (MSP), Infrastructure as a Service (IaaS), and Service Commerce Platforms [15]. All these services are Internet integrated, so that they can be accessed using public networks by consumers and business alike. A popular example of a cloud computing service is Google Docs where word processing and spreadsheet computing can be done inside a browser.
Grid computing involves running a single task across many (maybe thousands) computing devices under some sort of centralized or distributed control. These computing devices may be end-user computing equipment or servers, though most commercial uses of grids employ servers [16] with the aim of increasing server utilization. Grids, in general, are well suited to the execution of loosely-coupled parallel applications, such as the Bag-ofTasks (BoT) applications whose tasks are completely independent of each other [17]. Grid computing involves splitting up a task into several subtasks which may be run on various computers. The subtasks in most cases are all essentially similar and can be run independently of each other. Subtasks may be decomposed to a level such that they can be run on machines with progressively smaller and smaller computing power. The results from the subtasks are combined to achieve the final results. Grid computing is an apt application for the P2P architecture to harness the idle capacity of end-user equipment connected to the Internet.
Trends also show that the future P2P grids will be composed of an extremely large number of individual machines [17]. Grid computing projects like SETI@ home [18] and the Folding@home have used end-user computers connected to the Internet to achieve significant milestones. Table 1 shows the statistics from Folding@home updated on June 18, 2012 detailing the computing power availed through grid computing. Table 2 provides salient differences in the P2P and the traditional server-based grid computing [19]. Traditional grid computing can be, and has been, successfully extended to the P2P architecture by ameliorating some of the limitations of the P2P architecture, e.g., using the Globus toolkit [20, 21]. Tasks in areas like risk, assessment, simulating economic conditions etc. can benefit from grid computing applications [16].
7. Issues in P2P Business Applications
There are several pertinent issues when considering P2P applications. These issues are in some sense all related to one another, and affect one another. Various researchers including some in the Information Systems (IS) area have focused their attention on this topic [22-24]. Most of these issues stem from the scale and decentralization associated with the use of end-user computing equipment
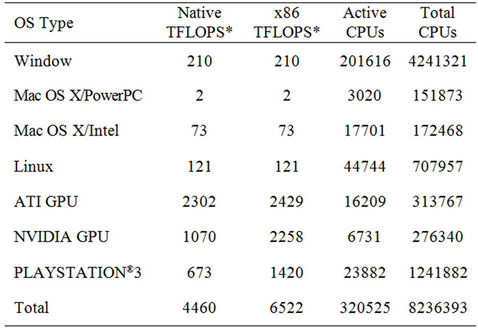
Table 1. Folding@home statistics (June 20, 2012), (http://fah-web.stanford.edu/cgi-bin/main.py?qtype=sstats).
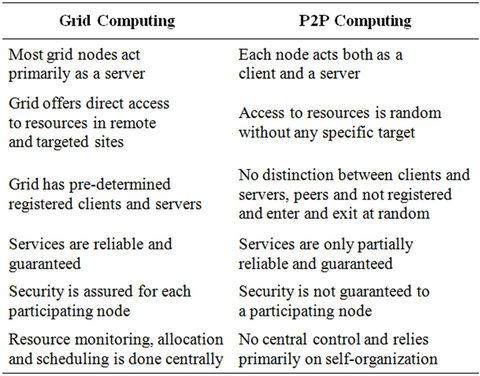
Table 2. P2P and grid computing.
accessible through the Internet. For instance, decentralization opens up a host of issues primarily on account of several dimensions of what may be decentralized and how they may be decentralized [25]. The most important of these issues is the issue of control. Technical and business solutions do exist for the mentioned issues (though they are not discussed in detail in this paper). For instance, security issues related to the propagation of polluted files and indices can be controlled using an immune approach and the file propagation-chain tracing technique [26].
7.1. Control
In a network comprising of end-user computing devices, the span of control plays an important role. Most of the other issues in P2P architecture stem from the issue of control. The span of control can result in a network that is totally decentralized without any central control, to one that is centralized and one or more servers maintain the necessary information to run the applications in a more efficient fashion. Control influences aspects such as predictable performance with service levels, reliability, overhead, liability, and security. Table 2 which highlights the differences between P2P and grid computing illustrates these challenges.
P2P computing on a big scale, like that employed by applications like Seti@Home, takes an organization far beyond its boundaries. A business has certain performance expectations that it needs to meet [27]. To meet its performance requirements, every business needs to control resources so that those resources can be employed as per the business needs. In information systems terminology, one may talk about Service Level Agreements (SLAs) for the resources. To ensure that the employed resources meet the SLAs implies that a business should be able to control the resources through some means. A decentralized collection of computing devices with inherent heterogeneity amongst the nodes, and the dynamic constitution of the pool, poses the significant co-ordination and control burden. The only way to establish and maintain control of end-users’ devices is to communicate the service level requirements to them, and motivate them to meet these by means of a rewards system. For example, Jarraya and Laurent propose a P2P-based storage application running on the Internet where users are rewarded for offering storage space on their computers [28]. Some grid-computing applications like SETI@Home induce participation for philanthropic reasons since the organization running SETI@Home is a non-profit organization working for the betterment of the human race. SETI@Home has a recognition-based reward system. SETI@Home does not have any control over the enduser computing devices. Issues related to rewarding or paying the end-users range from assigning a fair value to the resources used on an end-user computing device, payment mechanisms, cost of acquiring and running a comparable big computer in-house, etc. Additional cost items like the transaction costs of dealing with thousands of end-users whose computing devices are being used also needs to be considered. These end-users will need to be serviced for problems ranging from application faults on their computers, unpaid credits for work done, etc.
7.2. Performance
The possibility of performance degradation due to lack of control and high decentralization is a real issue [29]. The degree of the distribution of nodes also affects performance negatively. For example, one of the primary performance issues in P2P networks deals with distributed data management. P2P applications distribute their data over several nodes. Storage and retrieval of information by maintaining and storing indexes from this large distributed data space is a non-trivial issue [30]. In the P2P computing infrastructure, the pool of computers providing storage and processing is dynamic and often may not be under the control of the organization. Nodes can enter and exit at will, the performance across available nodes may vary widely depending upon how they are being used, and the performance of the network interconnecting these nodes may be variable. Overall, the dynamic pool makes meeting SLAs much more difficult. A dynamic pool of computing equipment affects predictable performance. Redundancy may be used to ensure that exit of a node does not cause failure. A computing task and its associated storage may run on more than one node. However this redundancy usually results in maintenance overheads at the central or control machine(s), increased network traffic, and/or performance degradation.
SLAs may be better met if an organization can exert some amount of control on some or all participating nodes. From a performance perspective, P2P literature broadly divides the architectures into two types: structured P2P networks and unstructured P2P networks [30, 31]. In structured P2P networks, data space is partitioned and mapped into the identifier space by using a randomization function: the Distributed Hash Table (DHT). The well-known DHT-based systems include CAN, Chord, Pastry, Tapestry, Kademlia, Viceroy, etc. These networks maintain a tightly controlled topology and keep the routing table updated globally. For example, ROME provides a mechanism for controlling the size (in terms of number of machines) of the P2P network so as to manage networks of nodes with highly dynamic workload fluctuations [32]. ROME can accommodate a burst of traffic and/or massive node failure rate. Maintaining the topology, distribution as per hash, etc. in structured P2P networks is all done using one or distributed central authorities. Typically performance (e.g., searching for content) is linearly proportional to the number of nodes. Unstructured P2P networks lack a strong central authority. Examples of such networks include Gnutella, Freenet, FastTrack/KaZaA, BitTorrent, and eDonkey. Maintaining a tightly controlled topology is not feasible due to the highly dynamic nature of the node population and lack of central control. Unstructured P2P networks are commonly organized in a flat, random, or simple hierarchical manner without a permanent central authority [30]. They exhibit properties of a scale-free network [33]. In a scale-free network, regardless of the size of the network, even as a small network grows into a large network some nodes are highly connected while most nodes in the network are much less connected. In other words, there are relatively few nodes in scale-free networks that are connected to a large degree to other nodes, while there are a great proportion of nodes that are connected to a lesser degree. The highly connected nodes that are typically more reliable are known as the supernodes, and enable some performance improvements. For example Skype makes extensive use of supernodes or clients that become major switching points for Skype traffic and support Skype clients outside the Skype network. Skype supernodes make it possible to have diverse paths through the Internet to get around performance problems and deal with clients using Network Address Translation [34]. In unstructured P2P networks, data is duplicated within the system depending on its popularity and the queries use flooding or random walks. In practice, the unstructured P2P network appears to be more efficient at fetching very popular content. However, because of its ad hoc nature and flooding-based routing, the correctness and performance of routing, system scalability, and consumption of network bandwidth are all uncertain [30]. Scale-free P2P networks like Gnutella do not scale well and exhibit the small network effect [13].
Diversity in end-user equipment means multiple versions of the P2P application is optimized for performance for different platforms. Continuous evolution of the platform (e.g., feature additions and bug-patching) and technologies means a maintenance overhead to continuously update, to accommodate evolution, and maintain backward compatibility. Distribution of the updated application is also an issue to consider. The maintenance issue can cause significant overhead, and put a question mark on the economics and the viability of a P2P network.
Hence the absence of a stable node pool, tight control, and homogeneity of nodes, most likely to be encountered when utilizing end-user computing devices, makes predictable, fast, and reliable performance an issue.
7.3. Security and Liability
Associated with ensuring SLAs and the desirability/inclination to control the end-user equipment is the question of security and liability. Several security challenges arise due to the increased complexity that is introduced when computers are allowed to connect directly to other computers and to share resources such as files and CPU time [6]. Polluted files and indices can propagate quickly through the network thereby destroying content and compromising search and even host machines [26]. This can compromise corporate networks and lead to all kinds of security breaches. If corporate data is stored outside the organizational boundary on multiple computers, even with encryption and other precautions it can be accessed by today’s sophisticated hackers. Perceptions about lack of security arise from lack of trust that is associated with most machines in the node population and an inability to pinpoint accountability. Lack of trust may also arise from lack of control. On the end-user side, vulnerabilities in the P2P application that is running on the end-user machine can lead to security breaches. Once a breach occurs, the trust between the business and end-users may be severely damaged. The greater the diversity of the platforms on which the application runs, the greater is the probability that one or more versions of the application destined for different platforms may be vulnerable through zero-day attacks and/or undocumented vulnerabilities.
Liability and accountability are of concern also. A business may not want to be held liable for issues related to damage of the end-user equipment, violation of privacy due to bugs in application, etc. The other side of the security and liability coin relates to the end-user liability in case data is stolen from the end-user computer through a hack attack, backdoor, Trojan, or corrupted results are deliberately sent back to the business, etc. The use of P2P applications may cause unwarranted costs as in the case of Skype. In Skype, a computer on the organization’s network might function as a supernode thereby routing calls in and out of the organization’s network. It will, in this case, eat up Internet bandwidth, even when no one in the organization’s network is a direct participant in the call [34].
8. P2P Business Models for Organizations
As mentioned earlier, there are several applications based on the P2P architecture that can benefit business organizations, however the adoption of P2P applications by businesses has been low. P2P has been thriving in consumer-oriented application space mainly through filesharing and media streaming applications [35]. In the business world, applications such as private file-sharing networks like Groove, Grouper, PiXPO, and Qnext that can be used to establish virtual communities, and where users can collaborate and interact with each other, exist, but again their uptake has been limited [36]. Within businesses, grid computing is extensively used in areas like oil exploration, risk analysis, protein folding and so forth, however it does not utilize end-user computers. Even at its peak (around 2002), applications based on P2P architecture did not become mainstream in the business sector [37]. This assertion most likely holds true today also (based on a general knowledge of the industry over the last few years as formal statistics are not available). Though there has been no formal study on the reasons for the lack of uptake of P2P technology, one may logically argue that it may be due to issues discussed earlier, the issues of control being the primary amongst all of them.
In order to provide a path for the uptake of P2P applications, a set of business models are presented based on the dimensions of scope (distribution of the node pool) and control (refer to Table 3). These business models for P2P applications exist at four distinct levels. We compare these levels as akin to intranet, extranet, and Internet for information sharing. We brand them using the popular ecommerce classification/terminology as business-to-employee, business-to-business, business-to-customer, and consumer-to-consumer modes. As an organization moves from one level to another it expands the scope of the node pool both in terms of diversity and geographical distribution. The scope expands from completely internal, to partners, to completely external, leading to an increase in the complexity of issues discussed earlier. As the scope moves from being completely internal to completely external, the level of direct control that an organization can exert on the node pool diminishes and the organization needs to resort to complex mechanisms to ensure performance. In discussing the models the issue of pricing or rewarding resource use and enabling technologies are also briefly discussed.
8.1. Business to Employee
As discussed before and generally accepted in the industry, all knowledge-intensive and creative work is best done on desktop type machines [9], with good processing and storage power, and ability to run an appropriate userinterface. Gartner consulting also supports this assertion stating the desktop computer is not going to be replaced entirely [38]. It is anticipated that organizations will continue using desktop machines for a foreseeable future. These desktops and other machines can be centrally managed using technologies such as Microsoft Active Directory and Group Policies. This along with system-level management utilities like Intel System Management allows a fine grained and low level control of hardware and software on a machine (e.g., powered off machines can be powered on). Routing, searching, and other resource co-ordination can be done much more efficiently since the pool of computing devices is relatively static and deterministic. As such, an organization should be able to use the resources on the employee end-user machines while having a high level of control. This model would be ideal for most organizations to deploy their P2P applications. Hence we can offer the following propositions:
Proposition 1: For most organizations, the way forward with P2P computing would be a B2E model using employee desktops.
A distributed model spread across thousands of enduser machines is most likely to be infeasible for most practical business applications since, in the highly distributed model, sufficient control for performance and liability (security) cannot be implemented with reasonable overhead.
Proposition 2: For business applications, a strong central control is desirable and recommended so that reasonable SLAs can be ensured.
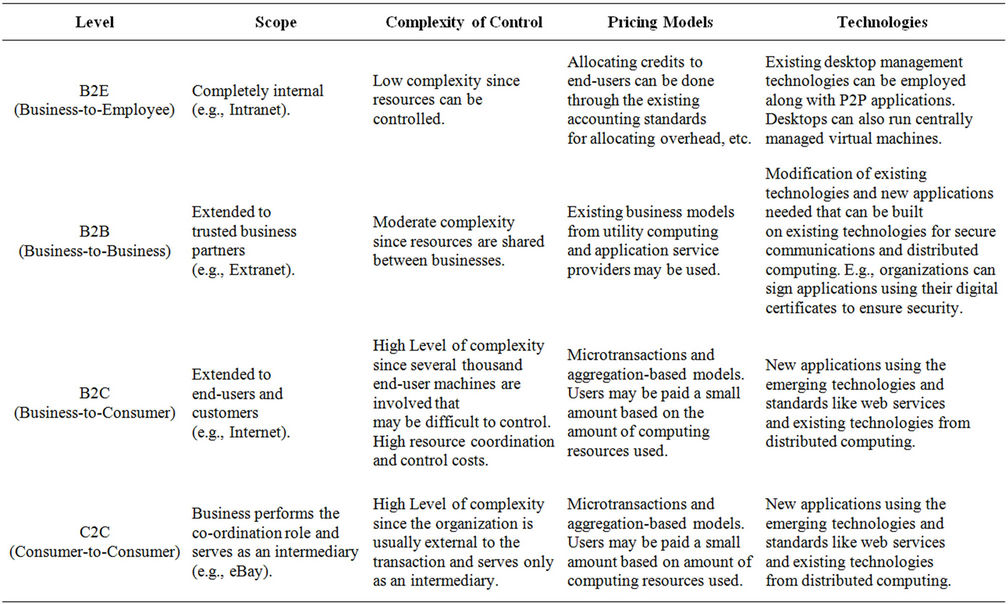
Table 3. P2P business application models.
This is most likely achievable with a strong central control that is present in a B2E model. Strict central control ensures that issues of performance, end-user compensation, business liability, end-user liability, and security are in a deterministic state at all times. Totally or highly decentralized models are not desirable, though with a deterministic node population they can implemented more effectively.
The B2E model has been successfully implemented in several companies. Many financial institutions use servers with spare capacity to execute computationally intensive tasks through the use of grids [16]. An instance of a serverless file system was implemented within Microsoft using desktops [39]. Medical image sharing has been implemented using a collaborative P2P and hybrid P2P architecture [40]. Another example is of cloud-bursting (a need for additional resources when the cloud resources run out) to manage the IT infrastructure. An organization may add resources from a P2P grid to the resources they purchase from a commercial cloud provider because although cloud resources are cheap, they are not actually free. P2P resources may be obtained for example by organizational employees without budgetary powers, or the organization may use cloud resources for required applications and P2P resources for discretionary applications without Quality of Service requirements [41].
8.2. Business to Business
The B2B P2P model can offer many of the same advantages as with a B2E model such as a predictable and a static end-user computing node population, strong central control, service level agreements, and security. However the expansion of the span of control will lead to some of the issues discussed earlier related to point of responsibility amongst the organizations. For instance, who is responsible and liable if data is compromised? Some of the issues may be easier to resolve since it can be assumed that all organizations involved in the partnerships will exercise due diligence in maintaining and securing their computing infrastructure, and contractual agreements can be signed between parties. Here utility pricing models [42] and emerging cloud computing pricing models may be used to compensate partners.
There are some examples of B2B P2P models that can be used for content distribution and distributed processing. An example of content distribution involves Deloitte UK and ABG Professional Information. Deloitte UK aggregates massive amounts of diverse regulatory information, corporate policies, and best practices, some of which is generated internally and some of which comes from outside vendors like B2B provider ABG Professional Information. It would be virtually impossible to maintain up-to-date versions of all of this material on centralized servers. Deloitte and ABG deployed NextPage’s “content network,” a variety of P2P technology that knits together servers within the company along with those of external providers to create a virtual repository of information. The data is maintained and resides on servers at different offices and even companies, but to the auditor at Deloitte, the information is all available from a single web page interface and looks as if it all sits in one place [43]. Another application involves sharing data on proteins [44]. This platform uses fully distributed P2P technologies to share specifications of peer-interaction protocols and service components that is no longer centralized in a few repositories but gathered from experiments in peer proteomics laboratories.
Distributed or grid computing can be done using software like Legion (development stopped in 2005) and Global ROME [32]. In ROME, size of the network can be controlled. Each node runs a ROME process that continually monitors the node’s workload to determine whether it is within bounds or under/overloaded. Through a number of defined actions, extra nodes can be recruited into the network structure to deal with overload and unnecessary nodes removed to deal with underload, thus optimizing the size and therefore lookup cost of the network. Nodes that are not currently members of the structure are held in a node pool on a machine designated as the bootstrap server. Global ROME (G-ROME), is designed to provide an interconnection of multiple independent ROME-enabled P2P networks, thus constructing a two-layered hierarchy of networks. The overlay network of G-ROME is used for node discovery by the ROME bootstrap servers that need extra capacity not available locally to cope with their ring’s workload. Since node utilization is monitored, cost metrics or revenue metrics may be used to compensate partners in the B2B P2P network.
8.3. Business to Consumer
For implementing applications at the B2C level, we stress that a specialized intermediary is needed who can take care of the technological, business, and other issues; keep the costs down; and ensure P2P application affordability. This intermediary may control a pool of nodes for content distribution or distributed processing. A technology like ROME/G-ROME discussed previously may be employed. The end-user nodes may be compensated using a variety of incentives like points and/or credits, most of which may be based on microtransactions (transactions of very small value, even to the extent of a fraction of a cent). Accounting models which can measure the overall contribution of a computing resource to a task can facilitate this. Example of a simplistic model might be a couple of cents for rendering one frame of an animation.
Grid computing applications for the B2C space may be developed using the Globus toolkit [20,21]. Globus complies with the Open Grid Services Architecture (OGSA) and provides grid security, remote job submission and control, data transfer, and other facilities which may ensure some level of service (though not necessarily high performance) and does address some liability issues, but it does not have any mechanism for compensating endusers. Content distribution especially audio and video streaming applications have been successfully implemented in the P2P B2C space [8,45]. Pando networks (http://www.pandonetworks.com) has a content distribution model that can work in conjunction with the Content Delivery Networks (CDNs) like Akamai and optimize bandwidth utilization through the use of a P2P network [46]. There are some commercial and non-commercial applications that already stream media over P2P architectures; for example, Peercast, freecast, ACTLab TV, ESM, Vatata, NodeZilla, Coolstreaming and PPlive [8]. An Internet-based storage application that compensates users for their participation while implementing features like security etc. has been proposed [28].
8.4. Consumer to Consumer
A P2P C2C application may either operate through an intermediary (e.g. Skyrider [47]), which is the same as a B2C model, or operate on a totally decentralized fashion. The C2C model is perhaps the most distributed and decentralized in its scope. This is also where most of the current P2P activity is underway. However as outlined before, the lack of central control and inability to guarantee performance levels does not make this configuration appropriate for business applications (proposition 2). However due to lack of centralized control and their vast distributed nature, such networks are suitable of preserving privacy of users and users are endowed with anonymity. For example, The Onion Router (TOR) is used by a spectrum of population all over the world to escape government censorship, and report on oppressive governments [48]. As tracking of activity and control of the Internet becomes more pervasive, the C2C P2P will come to play a more important part on the Internet. It appears that anonymity and privacy based on decentralization has been a prime aim of application design in the C2C P2P realm [49], but that is not a prime consideration for a business P2P application.
Proposition 3: The C2C P2P model that is highly decentralized and distributed will form the backbone of most anonymity and privacy mechanisms on the Internet.
Given the structure of connectivity of the Internet and the ability to control traffic at various exchange and access points, a P2P C2C architecture may be the only feasible way to protect anonymity and privacy.
Incentive to participate in a P2P network in important for its success [36]. In spite of the fact that users do not get compensated for participating in decentralized C2C P2P networks, they are the most in use today. Users participate on their own accord and most often the rewards are indirect. Participation in networks like TOR is for altruistic and humanitarian reasons. Participation in the file sharing by end-users may be rebelling against the big corporations, and monetary benefit (without any explicit compensation mechanism). The end-users may also participate for reciprocation or in a spirit to give back when they have gained something. With all the networks, including those like TOR, liability questions are complex and the subject of various lawsuits across the globe. For example, use of TOR has stymied some FBI inquiries into illegal file sharing. On file-sharing networks, security has been a concern with spyware and viruses spreading through innocuous looking files.
On the infrastructure level, an important application in the P2P C2C realm is the standards for ad-hoc networks especially wireless ad-hoc networks (part of the 802.11 specification). Mobile ad-hoc networks, wireless mesh networks, and wireless sensor networks are all important applications in this area [50]. These networks standards developed by the Internet Engineering Task Force (IETF) enable the formation of networks on the fly without the need for central routing with nodes entering and leaving the network at will. Ad-hoc network standards have been successfully used by the US Army on the battlefield. The ability of mobile devices to come together and make a functioning network as these devices become more popular and powerful, creates possibilities for some interesting applications [51].
9. Mobile Devices and P2P Computing
The growing popularity of mobile devices has been discussed earlier in this paper. Another example of the increasing importance of mobile devices is illustrated by the recent discussion on the IPO of Facebook (the social networking site), where several experts have pointed out that Facebook has a mobile problem since it does not monetize mobile traffic [52]. Mobile devices in use today have limited capabilities due to various technology constraints (e.g., limitations on battery life, heat generation) and hence tend to act more like thin clients. While there seems to more and more cases made for mobile device-centered cloud computing-backed centralized computing, thick computing still has its place. All serious work that requires any significant computing power is better done on thick clients like desktops and workstations. Within business enterprises and other organizations, the primary mode of work is still anticipated to be desktop machines and other thick clients for some years to come. In addition many external legal, political, and environmental constraints may still keep desktop computing in fashion. For instance, most cellular network providers in the USA have imposed caps and restrictions on the maximum amount of data usage that a user is allowed within a given mobile service plan. The costs of using cellular data is significantly higher than a few years ago and the speeds pale in comparison to wired networks. The implication of this may be that most users may connect through Wi-Fi networks rather than cellular networks and the true mobility of a device is significantly hindered. This may also hinder uptake of these devices as the primary computing device is backed by cloud computing and render them as secondary or supplementary computing devices. Hence we may state our fourth proposition as follows:
Proposition 4: Desktops and thick clients are likely to retain their status as the primary computing device for a majority of the population, especially businesses. Mobile devices are more likely to be used as supplementary devices by most knowledge workers.
This implies that P2P business applications would still remain pertinent in the enterprise realm.
Given the popularity of mobile devices, one may like to explore how P2P may be used with mobile devices and the kind of applications that may be implemented. This discussion is based on the P2P features discussed earlier and hence one is not focused on application that can serve as clients to a P2P infrastructure, but have to participate in that infrastructure in some server capacity. For instance an application like PeerBox [53] which allows connection to P2P networks for downloading, but does not allow for serving any files, may not qualify.
There are several mobile P2P applications in existence: mBit P2P application allows mobile phone users to share files, pictures, music, etc. [54]; Magi P2P collaboration platform for mobile devices [55]; Skype; etc. The uptake of these applications apart from Skype and certain messaging applications may be questionable. Given the dependency of the mobile devices on the cloud at the backend to handle heavy-duty processing and storage tasks, they may not be too apt to resource intensive applications. Some lightweight tasks that rely on processing and storage which happens as a matter of routine on these mobile devices may be good candidates for P2P applications. Applications that take the benefits of ad-hoc networks which these devices can form automatically when they are in the vicinity of each other, are other natural candidates. It is however natural to assume that till there is a significant increase in the processing and storage capacity of these devices, they will continue to operate in a cloud-coupled mode. From an historical lesson/perspective, as the power of these devices increase and they reach and/or exceed the power of the current desktops and laptops, they may become suitable candidates for P2P computing and subject to the economics of the network connectivity. For example, there is the new Android Botnet that is being used to send spam through the Yahoo email services [56]. Hence we can forward the following propositions:
Proposition 5: Current generation of mobile devices that are not apt for P2P computing and can mostly perform satisfactorily in a cloud-coupled mode, will be ready for P2P applications in another three to four years (based on hardware and battery power trends).
Proposition 6: The economics of wireless network connectivity will be an important factor in determining the success of P2P computing model on the mobile platforms.
10. Conclusion, Future Research, and Limitations
The current breadth and depth of research in P2P computing points to its potential as a viable and useful infrastructure for business applications. It can be used for several useful applications like content distribution, load balancing, and grid computing. P2P is a natural evolution of decentralized computing and the increase in the power of the client machines. Though businesses have not fully utilized its potential, business P2P applications operating in a B2E mode should be easy for enterprises to implement and are a viable way for uptake and forward movement in this area.
Though mobile devices supported by cloud computing are reigning big in today’s computing paradigm, the thick client machines are still required for knowledge-intensive and creative work and are here to stay for the foreseeable future. These client machines will predominantly reside within enterprises and hence the B2E and B2B P2P computing models will still remain viable and useful even within the current computing shift to mobile devices at the consumer levels.
Hence moving forward we can say that the P2P computing model does not lose its viability due to increased uptake in mobile devices by the consumers, at least for most businesses and enterprises. If we can learn something from history and plot a trend, we can safely state that power of the mobile computing devices will increase and in a few years match or exceed those of the thick clients today. Similar to how computing became more distributed and moved out of the confines of mainframes and powerful servers, the same trend may follow with mobile devices. Though the network connectivity will be pervasive, the computing may be moved back from the cloud to the mobile client devices. One reason for this may be the cellular data price structure and wireless spectrum issues that are likely to restrict the replacement of wired connectivity by wireless connectivity. Another reason is likely to be that end-users demand and enjoy freedom, flexibility, and having their own span of control. While some control has been given up by users to the cloud-based services due to the limitations of the mobile devices, they would be more inclined to gain it back as the capacity of these devices increase. At that stage, P2P computing on the mobile devices will once again become feasible and they can be incorporated into the P2P infrastructure Anonymity and privacy can only be reasonably preserved through a C2C P2P architecture. As the desire of governments and businesses to control the Internet increases, the architecture will become more and more popular for this purpose. Hence one can infer that P2P computing is still an architecture that will stay relevant in both consumer and business spaces in the foreseeable future, even in this era of cloud-coupled mobile computing. It is therefore important for the MIS academicians to take a holistic and practical approach to the P2P applications. Understanding what is feasible will allow us to channel our energies into the study of issues that will bring in both immediate and practical benefits to the business organizations. Detailed study of issues related to applications running on end-user machines to benefit the organizations by better uses of slack resources, should be undertaken.
There are many areas for future potential research, the most important of which is a payment or compensation scheme using microtransactions that will allow for-profit businesses to make a transition to the B2C model. Other potential interesting areas of research are examining issues of return-on-investment (ROI) on P2P computing applications. For instance, running applications on desktops inside the organization may increase the TCO for the desktop but lead to savings in server-related costs. Green computing has been another new emerging trend in the area of computing and P2P architectures have the potential to contribute significantly in this area since an increase in the utilization of machines is not accompanied by significant use in power consumption.
Finally the authors realize that propositions forwarded are based on logical reasoning and may not be supported by empirical data. The primary reason for this is that while there is a lot of research that has been done in the P2P area, and the technologies exist for virtually any application or task one can think of, there has not been any significant uptake. There also appears to be a lack of proper understanding on the nature and potential of the P2P computing technology. This was inferred in an informal fashion with few IS managers during this research. The technology is complex and issues span a myriad of domains. The purpose here is to propose some preliminary work in terms of business models and highlight issues such that first steps can be taken towards the adoption of this technology/architecture. As computing becomes more pervasive and omnipresent P2P can bring about significant benefits to both businesses and endusers.
REFERENCES
- E. Rutheford, “The P2P Report 2000,” 2001. http://www.cio.com/knowledge/edit/p2p.html
- G. Ruffo and R. Schifanella, “Fairpeers: Efficient Profit Sharing in Fair Peer-to-Peer Market Places,” Journal of Network and Systems Management, Vol. 15, No. 3, 2007, pp. 355-382. doi:10.1007/s10922-007-9066-9
- F. Mata, J. L. Garcia-Dorado, J. Aracil and E. L. V. Jorge, “Factor Analysis of Internet Traffic Destinations from Similar Source Networks,” Internet Research, Vol. 22, No. 1, 2012, pp. 29-56. doi:10.1108/10662241211199951
- R. Torres, M. Hajjat, S. Rao, M. Mellia and M. Munafo, “Inferring Undesirable Behaviour from P2P Traffic Analysis,” Proceedings of ACM SIGMETRICS, Seattle, 15-19 June 2009, pp. 25-36.
- I. Wladawsky-Berger, “How CIOs Can Pilot the Untethered Enterprise,” 2012. http://blogs.wsj.com/cio/2012/06/10/how-cios-can-pilot-the-untethered-enterprise/
- D. Schoder and K. Fischbach, “Peer-to-Peer Prospects,” Communications of the ACM, Vol. 46, No. 2, 2003, pp. 27-35. doi:10.1145/606272.606294
- W. G. Yee, L. T. Nguyen and O. Frieder, “A View of the Data on P2P File-sharing Systems,” Journal of the American Society for Information Science and Technology, Vol. 60, No. 10, 2009, pp. 2132-2141. doi:10.1002/asi.21106
- R. M. Martin, J. Casanovas, J. F. Crespo and J. Giralt, “Sharing Audiovisual Content Using a P2P Environment Based in JXTA,” Internet Research, Vol. 17, No. 5, 2007, pp. 554-562. doi:10.1108/10662240710830244
- E. Frank, C. M. Gillett, E. Daley, S. R. Epps, B. Wang, T. Schadler and M. Yamnitsky, “Tablets Will Rule the Personal Computing Landscape,” Forrestor Research, 2012.
- J. Perlow, “Post-PC Era Means Mass Extinction for Personal Computer OEMs,” 2012. http://www.zdnet.com/blog/perlow/post-pc-era-means-mass-extinction-for-personal-computer-oems/20514?pg=2&tag=content;siu-container
- C. Shirky, “What Is P2P… and What Isn’t?” 2000. http://www.openp2p.com/lpt/a/1431
- B. Hayes, “Collective Wisdom,” 1998. http://www.amsci.org/amsci/issues/Comsci98/copmsci1998-03.html
- M. A. Jovanovic, F. S. Annexstein and K. A. Berman, “Scalability Issues in Large Peer-to-Peer Networks—A Case Study of Gnutella,” University of Cincinnati Technical Report, 2001.
- Anonymous_2, “DRFortress Launches the First Local Pay-As-You-Use Cloud Computing Service for Hawaii and the Pacific Rim,” Business Wire, New York, 2012.
- E. Knorr and G. Gruman, “What Cloud Computing Really Means?” 2012. http://www.infoworld.com/d/cloud-computing/what-cloud-computing-really-means-031?page=0,1
- Anonymous_1, “Gearing up for Grid,” 2004. http://www.itutilitypipeline.com
- S. Di and C. L. Wang, “Decentralized Proactive Resource Allocation for Maximizing Throughput of P2P Grid,” Journal of Parallel and Distributed Computing, Vol. 72, No. 2, 2012, pp. 308-321. doi:10.1016/j.jpdc.2011.10.010
- Anonymous_3, “The Science of SETI@Home,” 2012. http://setiathome.berkeley.edu/sah_about.php
- X. Zhang, “Research Issues for Building and Integrating Peer-Based and Grid Systems,” 2002. http://www.nesc.ac.uk/talks/china_meet/zhang_beijing_talk.pdf
- Anonymous_8, “Status and Plans for Globus Toolkit 3.0,” 2004. http://www-unix.globus.org/toolkit/
- Anonymous_9, “About the Globus Alliance,” 2012. http://www.globus.org/alliance/about.php
- R. Krishnan, M. D. Smith and R. Telang, “The Economics of Peer-Peer Networks,” JITTA: Journal of Information Technology Theory and Application, Vol. 5, No. 3, 2003, pp. 31-45.
- P. J. Alexander, “Peer-to-Peer File Sharing—The Case of Music Recording Industry,” Review of Industrial Organization, Vol. 20, 2002, pp. 151-161. doi:10.1023/A:1013819218792
- J. A. Clark and A. Tsiaparas, “Bandwidth-on-Demand Networks—A Solution to Peer-to-Peer File Sharing,” BT Technology Journal, Vol. 20, No. 1, 2002, pp. 5-16. doi:10.1023/A:1014518008964
- T. Boyle, “Independent Axes for Centralization/Decentralization of Transaction Systems,” 2001. http://www.ledgerism.net/P2Paxes.htm
- X. Meng and W. Cui, “Research on the Immune Strategy for the Polluted File Propagation in Structured P2P Networks,” Computers & Electrical Engineering, Vol. 38, No. 2, 2012, pp. 194-205. doi:10.1016/j.compeleceng.2011.12.013
- J. R. Galbraith, “Organization Design,” Addison Wesley, Reading, 1977.
- H. Jarraya and M. Laurent, “A Secure Peer-to-Peer Backup Service Keeping Great Autonomy while under the Supervision of a Provider,” Computers & Security, Vol. 29, No. 2, 2010 , pp. 180-195. doi:10.1016/j.cose.2009.10.003
- E. Miller, “Decentrlaization, Gnutella and Bad Actors,” 2002. http://research.yale.edu/lawmeme/modules.php?name=News&file=article&sid=291
- Y. Gu and A. Boukerche, “HD Tree: A Novel Data Dtructure to Support Multi-Dimensional Range Query for P2P Networks,” Journal of Parallel and Distributed Computing, Vol. 71, No. 8, 2011, pp. 1111-1124. doi:10.1016/j.jpdc.2011.04.003
- M. Xu, S. Zhou and J. Guan, “A New and Effective Hierarchical Overlay Structure for Peer-to-Peer Networks,” Computer Communications, Vol. 34, No. 1, 2011, pp. 862-874. doi:10.1016/j.comcom.2010.10.005
- G. Exarchakos, N. Antonopoulos and J. Salter, “G-ROME: Semantic-Driven Capacity Sharing Among P2P Networks,” Internet Research, Vol. 17, No. 1, 2007, pp. 7-20. doi:10.1108/10662240710730461
- D. O. Rice, “Protecting Online Information Sharing in Peerto-Peer (P2P) Networks,” Online Information Review, Vol. 31, No. 5, 2007, pp. 682-693. doi:10.1108/14684520710832351
- P. Morrissey, “RTGuardian Delivers Skype Smackdown,” Network Computing, Vol. 17, No. 13, 2006, pp. 22-24.
- Anonymous_6, “Managed Peer-to-Peer Networking,” 2012. http://www.pandonetworks.com/p2p
- C. Metz, “P2P Goes Private,” PC Magazine, February 2005, p. 92.
- Anonymous_5, “Cybermanagement: Correction—CommerceNet and PeerIntelligence Galvanize Peer-to-Peer (P2P) Community with Groundbreaking Research for Business Environment,” M2 Presswire, Coventry, 2001, p. 1.
- E. Messmer, “Gartner: Top 10 Emerging Infrastructure Trends—The Tablet, the Cloud, Big Data All on the List,” 2012. http://www.networkworld.com/news/2012/060512-gartner-trends-259883.html
- W. J. Bolosky, J. R. Douceur, D. Ely and M. Theimer, “Feasibility of a Serverless Distributed File System Deployed on an Existing Set of Desktop PCs,” 2001. http://research.microsoft.com/sn/Farsite/Sigmetrics2000.pdf
- C. C. Costa, C. C. Ferreira, L. L. Bastiao, L. L. Riberio, A. A. Silvo and J. L. Oliveira, “Dicoogle—An Open Source Peer-to-Peer PACS,” Journal of Digital Imaging, Vol. 24, No. 5, 2011, pp. 848-856. doi:10.1007/s10278-010-9347-9
- P. D. Maciel, F. Brasilerio, R. A. Santos, D. Candeia, R. Lopes, M. Carvalho, R. Miceli, N. Andrade and M. Mowbray, “Business-Driven Short-Term Management of a Hybrid IT Infrastructure,” Journal of Parallel and Distributed Computing, Vol. 72, No. 2, 2012, pp. 106-119. doi:10.1016/j.jpdc.2011.11.001
- Anonymous_7, “Stortext: Stortext Launches DOXZONE,” M2 Presswire, Coventry, 2001.
- S. Smith, “P2P in B2B,” EContent, Vol. 26, No. 7, 2003, pp. 20-24.
- M. M. Schorlemmer, J. J. Abian, C. C. Sierra, D. D. Cruz, L. L. Bernacchioni, E. E. Jaen, A. A. P. Pinninck and M. M. Atencia, “P2P Proteomics—Data Sharing for Enhanced Protein Identification,” Automated Experimentation, Vol. 4, No. 1, 2012, p. 1. http://www.aejournal.net/content/4/1/1
- Y. He, Z. Xiong, Y. Zhang, X. Tan and Z. Li, “Modeling and Analysis of Multi-Channel P2P VoD Systems,” Journal of Network and Computer Applications, Vol. 10, No. 16, 2012, pp. 1568-1578. doi:10.1016/j.jnca.2012.02.004
- W. Sun, and C. King, “ORN: A Content-Based Approach to Improving Supplier Discovery in P2P VOD Networks,” Journal of Parallel and Distributed Computing, Vol. 71, No. 12, 2011, pp. 1558-1569. doi:10.1016/j.jpdc.2011.08.004
- Anonymous_13, “Skyrider Extends Peer-to-Peer (P2P) Leadership Role with Search Marketing Platform and Series C Round of Funding,” Business Wire, New York, 2006.
- Anonymous_10, “TOR: Overview,” 2012. https://www.torproject.org/about/overview.html.en
- D. Schoder and K. Fischbach, “Peer-to-Peer Prospects,” Communications of the ACM, Vol. 46, No. 2, 2003, pp. 27-35. doi:10.1145/606272.606294
- Wikipedia, “Wireless Ad-Hoc Nework,” 2012. http://en.wikipedia.org/wiki/Wireless_ad-hoc_network
- L. Hardesty, “Explained: Ad Hoc Networks,” 2011. http://web.mit.edu/newsoffice/2011/exp-ad-hoc-0310.html
- M. Wood, “If Facebook Dies (and It Might) Its Killer Will Be Born Mobile,” 2012. http://news.cnet.com/8301-31322_3-57443289-256/if-facebook-dies-and-it-might-its-killer-will-be-born-mobile/?tag=nl.e703
- A. Bruno, “UpFront: Mobile—Two New Apps Take P2P Mobile,” Billboard, Vol. 118, No. 5, 2006, p. 8.
- Anonymous_11, “mTouche, Indian Partner to Offer P2P Mobile Content,” New Straits Times, Kuala Lumpur, Malaysia, 2009, p. 5.
- Anonymous_12, “Endeavors Technology: Endeavors Technology’s Magi P2P Collaboration Software for PDAs to Run Insignia’s Industry-Leading Jeode Platform,” M2 Presswire, Coventry, 2001.
- D. Lonescu, “UPDATE: New Android Malware Uses Phones as Spam Botnet,” 2012. http://www.pcworld.com/article/258794/update_new_android_malware_uses_phones_as_spam_botnet.html#tk.nl_dnx_h_crawl