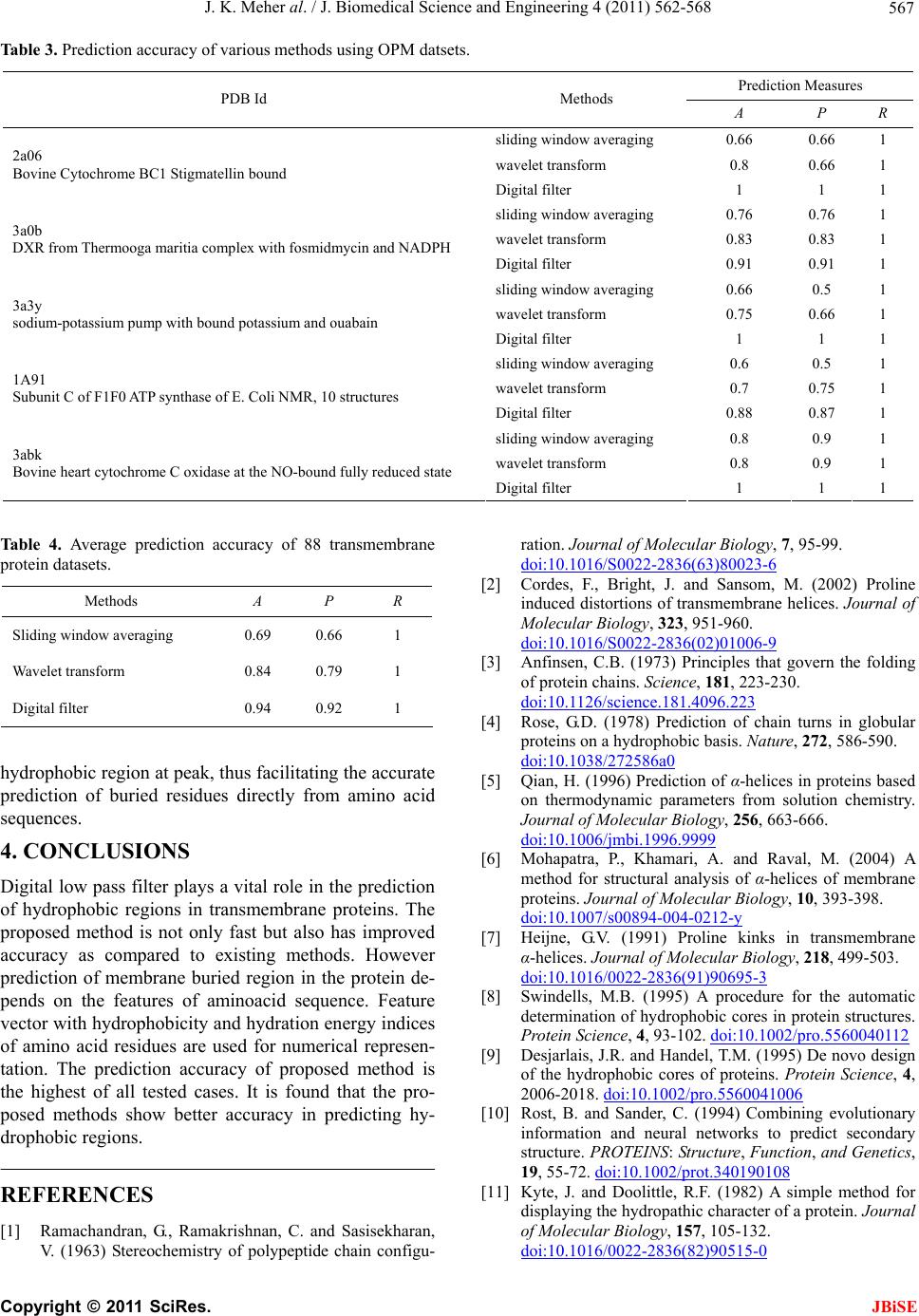
J. K. Meher al. / J. Biomedical Science and Engineering 4 (2011) 562-568 563
A
B
C
D
H
G
F
E
I
J
K
L
Figure 1. Definition of transmembrane structures. [A;D] is a
transmembrane helix (TMH) and [B;C] represents the trans-
membrane segment (TMS)which is the embedded part of
TMH.
chemical value for each residue inside the frame is
summed up and assigned in the middle of the window.
Then the window slides across the sequence [9]. How-
ever, the relationship between segments and structure
does not always correspond. As extracting structural
information from amino acid sequences alone is difficult,
various prediction methods have been developed using
evolutionary information and neural network [10].
The span of window size is investigated in [11], which
reflected the interior and exterior portions of proteins.
Hydrophobicity profiles using the shortest window size
were noisy, and size less than seven residues produce
unsatisfactory result. On the other hand, long spans
tended to lose structural segments. Thus the optimum
choice between hydrophobic region and position of
amino acid residues was obtained with a nine for globu-
lar proteins. The problem with this technique is noisy in
the smoothed profiles, which makes it particularly diffi-
cult to find segments in case of globular proteins.
Recently signal processing methods play a major role
in predicting hydrophobic regions. Fourier analysis has
been applied to predict secondary structures from a se-
quential dotted hydrophobicity index [12]. The utilities
of the Fourier transform lie in its ability to analyze a
signal in the time domain for its frequency content. The
transform works by first translating a function in the
time domain into a function in the frequency domain.
The signal can then be analyzed for its frequency content
because the Fourier coefficients of the transformed func-
tion represent the contribution of each sine and cosine
function at each frequency. Although the Fourier analy-
sis is useful for acquiring structural information, this
method tends to cause positional error.
Wavelets are mathematical functions that divide data
into different frequency components. This approach has
advantages over traditional Fourier methods in analyzing
data where the signal contains discontinuities or high
frequency noise. Recently, the use of wavelet transform,
both continuous and discrete in the Bioinformatics field
is promising [13]. Continuous Wavelet Transform (CWT)
allows one-dimensional signal to be viewed in a more
discriminative two-dimensional time-scale representa-
tion. CWT is calculated by the continuous shifting of the
continuously scalable wavelet over the signal. In discrete
wavelet transform (DWT) a subset of scales and posi-
tions are chosen, in which the correlation between the
signal and the shifted and dilated waveforms are calcu-
lated. Consequently, the signal is decomposed into sev-
eral groups of coefficients, each containing signal fea-
tures corresponding to a group of frequencies. Small
scales refer to compressed wavelets, depicted by rapid
variations appropriate for extracting high frequency fea-
tures of the signal. An important attribute of wavelet
methods is that, due to the limited duration of every
wavelet, local variations of the signal are better extracted
and information on the location of these local features is
retained in the constituent waveforms. DWT has been
applied on hydrophobicity signals in order to predict
hydrophobic cores in proteins [14,15]. Protein sequence
similarity has also been studied using DWT of a signal
associated with the average energy states of all valence
electrons of each amino acid [16]. Wavelet transform
has been applied for transmembrane structure prediction
[17]. DWT has been used to decompose the amino acids
of TM proteins into a series of structures in different
layers, then predicting the location of TMHs according
to the information of the amino acids sequence in dif-
ferent scales [18]. A method based on discrete wavelet
transform has been developed to predict the number and
location of TMHs in membrane proteins [19].
The existing methods have their limitations in terms
of accuracy. As mentioned above, numerous attempts
have been made by researchers to define the relation
between interior and exterior regions directly from the
amino acid sequence. However, it is difficult to divide
interior and exterior position of amino acid residues by
assigning a hydrophobicity threshold, because of unac-
ceptable noise level. Hence there is a need to develop
advanced algorithm for faster and accurate prediction of
hydrophobic regions. This motivates to develop novel
approach based on digital filtering method to effectively
predict these regions in transmembrane α-helices.
The rest of the paper is organised as follows. Sec-
tion-2 deals with the proposed method for prediction of
hydrophobic regions in transmembrane α-helices. This
paper focuses on the development of signal processing
algorithms based on digital filter. Section-3 deals with
discussion of simulation results of proposed methods
using standard data set in terms of prediction measures.
Section-4 presents the conclusions of this paper.
C
opyright © 2011 SciRes. JBiSE