Open Access Library Journal
Vol.02 No.05(2015), Article ID:68390,6 pages
10.4236/oalib.1101479
On a Logical Model of Combinatorial Problems
Anatoly D. Plotnikov
Department of Social Informatics and Information Systems, Dalh East-Ukrainian National University, Luhansk, Ukraine
Email: a.plotnikov@list.ru
Copyright © 2015 by author and OALib.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 21 April 2015; accepted 10 May 2015; published 19 May 2015
ABSTRACT
The paper proposes a logical model of combinatorial problems; it also gives an example of a problem of the class NP that cannot be solved in polynomial time on the dimension of the problem.
Keywords:
Logical Model, Combinatorial Problem, Class P, Class NP
Subject Areas: Combinatorial Mathematics

1. Introduction
Suppose we have a n-set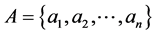 . The problem is called combinatorial if it needs to find a sample S of the elements A satisfying specified conditions. Elements of the set A can be numbers, symbols, geometric objects, etc.
. The problem is called combinatorial if it needs to find a sample S of the elements A satisfying specified conditions. Elements of the set A can be numbers, symbols, geometric objects, etc.
Logic is the natural language of mathematics. Therefore, the construction of logical models of combinatorial problems helps to better understand the features of a problem, estimate the possible ways and the complexity of the solving.
Any mass problem is characterized by some lists of parameters (in our case, this is the set A) and by predicate P(S), which determines the properties of the solution S [1] [2] . In complexity theory, it introduces the concept of problems, which form the class NP.
The problem belongs to the class NP if the solution can be checked for the time described by a polynomial 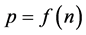 on the problem dimension n. There are many problems that belong to the class NP [1] - [3] , which can be solved for the polynomial time
on the problem dimension n. There are many problems that belong to the class NP [1] - [3] , which can be solved for the polynomial time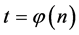 . The set of all these problems form the class P. The central question of complexity theory is the problem of the relation of classes P and NP, i.e., P = NP or P ¹ NP.
. The set of all these problems form the class P. The central question of complexity theory is the problem of the relation of classes P and NP, i.e., P = NP or P ¹ NP.
The purpose of this paper is to offer a general logical model of combinatorial problems, the solution of which is a disordered sample, as well as to estimate the complexity of solving certain problems.
2. The General Logical Model
Usually, each combinatorial problem is defined as a triple (A, P(S), W(S)), where 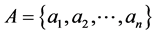 is n-set of solution elements, P(S) is a predicate that determines whether some subsets
is n-set of solution elements, P(S) is a predicate that determines whether some subsets 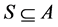 satisfy conditions of the problem, W(S) is a cost function of S.
satisfy conditions of the problem, W(S) is a cost function of S.
Each subset 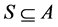 we associate with the n-dimensional Boolean tuple
we associate with the n-dimensional Boolean tuple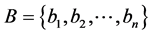 , where
, where 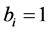 (i = 1, 2, ×××, n) if
(i = 1, 2, ×××, n) if 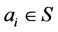 and
and 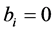 otherwise. The predicate P(S) equals to 0 or 1 for each concrete subset S. Therefore, the value of the predicate P(S) for each tuple B defines the value of a Boolean function f(B), depending on n of Boolean variables. Such Boolean function is called a pointer of feasible solutions (PFS).
otherwise. The predicate P(S) equals to 0 or 1 for each concrete subset S. Therefore, the value of the predicate P(S) for each tuple B defines the value of a Boolean function f(B), depending on n of Boolean variables. Such Boolean function is called a pointer of feasible solutions (PFS).
Thus, the combinatorial problem can be represented as the three: (A, f(B), W(B)), where W(B) = W(S).
Figure 1 shows schematically the relation between PFS and the cost function.
Consider a Few Examples
Example 1. (The maximum independent set problem). Let there be an undirected graph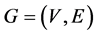 , where we want to find the maximum independent set of vertices. Here
, where we want to find the maximum independent set of vertices. Here 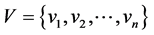 is the set of graph vertices,
is the set of graph vertices, 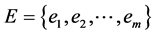 is the set of graph edges.
is the set of graph edges.
It is obvious that here A = V is the set of solution elements, the predicate P(S) is defined by a procedure that determines whether a subset of vertices 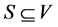 is independent, i.e. whether the vertices of S are pairwise non-adjacent. The cost function W(S) calculates the number of elements in S.
is independent, i.e. whether the vertices of S are pairwise non-adjacent. The cost function W(S) calculates the number of elements in S.
We associate each subset 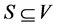 with a Boolean tuple
with a Boolean tuple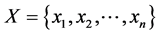 , where
, where  if
if  and
and  otherwise. Then the predicate P(S) = P(X) defines a Boolean function f(B). We will define f(B).
otherwise. Then the predicate P(S) = P(X) defines a Boolean function f(B). We will define f(B).
We associate each vertex  with the conjunction of
with the conjunction of , where
, where  are variables corresponding to all vertices of
are variables corresponding to all vertices of , adjacent to a vertex
, adjacent to a vertex  graph G. Obviously, the disjunction
graph G. Obviously, the disjunction

is the desired pointer of feasible solutions f(B).
Thus, the solution to the problem is to find a tuple B, which has the maximum number of unities, on which the function f(B) equals to one (true).
For example, suppose, there is the undirected graph  as shown in Figure 2, in which we must find the maximum number of independent vertices.
as shown in Figure 2, in which we must find the maximum number of independent vertices.

Figure 1. Illustration of the proposed model.

Figure 2. Undirected graph.
We associate each vertex  with a Boolean variable
with a Boolean variable 
 , where
, where  if the vertex
if the vertex  belongs to the set of independent vertices and
belongs to the set of independent vertices and  otherwise. We find:
otherwise. We find: ,
,  ,
,  ,
,  ,
, .
.
So, we must find the values of Boolean variables , corresponding to the vertices
, corresponding to the vertices  of the graph G, for where the function
of the graph G, for where the function

is maximum provided that the Boolean function
 .
.
Example 2. (The Hamiltonian cycle problem). Let there be an undirected graph , for which it is necessary to find a Hamiltonian cycle if it exists. The graph G is Hamiltonian if there exists a simple cycle that includes all the vertices of the graph.
, for which it is necessary to find a Hamiltonian cycle if it exists. The graph G is Hamiltonian if there exists a simple cycle that includes all the vertices of the graph.
It is obvious that here A = E is the set of solution elements―the set of graph edges. Predicate P(S) defines procedure that determines whether the basic condition of Hamiltonian graph is executed, namely, a subset of edges  is a subgraph, in which each vertex is incident with at most two edges. The cost function W(S) determines whether a subgraph S is a simple cycle of the graph G.
is a subgraph, in which each vertex is incident with at most two edges. The cost function W(S) determines whether a subgraph S is a simple cycle of the graph G.
In this case it is convenient initially to construct a function , the inverse to the pointer of feasible solutions f.
, the inverse to the pointer of feasible solutions f.
We associate each edge 
 with Boolean variable
with Boolean variable . We believe
. We believe  if the edge
if the edge  belongs the selected set of edges S, and
belongs the selected set of edges S, and  otherwise.
otherwise.
The function  is unity on such the tuple of Boolean variables
is unity on such the tuple of Boolean variables , which correspond to the collection of three or more edges incident to the same vertex of G. For example, if the vertex
, which correspond to the collection of three or more edges incident to the same vertex of G. For example, if the vertex  of the graph G is incident
of the graph G is incident  edges
edges  then there is
then there is

conjunctions in the form
 ,
,
which correspond to tuples containing three edges that incident to the same vertex. Obviously, one should not write conjunction with more than three variables, as they are absorbed by conjunctions of the three variables.
Writing down all such conjunctions for vertices with local degree equals to or more than three, we obtain the inverse function for PFS. For the graph shown in Figure 2, we have:

Therefore, the function , inverse for PFS, would be:
, inverse for PFS, would be:
 .
.
Hence, we have the final form for the pointer of feasible solutions:

As for the function W(B), then it is given by the procedure which establishes that the considered subgraph is a Hamiltonian cycle. This can be executed by depth-first search (DFS) in the graph.
Example 3. (The satisfiability problem). In the satisfiability problem, some Boolean function  is given, and requires to establish the existence of such Boolean variables
is given, and requires to establish the existence of such Boolean variables , which deliver a unit value function F. It is generally believed that function F is defined as a conjunctive normal form (CNF).
, which deliver a unit value function F. It is generally believed that function F is defined as a conjunctive normal form (CNF).
Obviously, in this case literals of Boolean variables are the elements of the solution, that is, the variables  with negation or without negation. Literals x and
with negation or without negation. Literals x and  called alternative (contraries). Any tuple of non-alternative literals would represent a feasible solution to the problem. Since each tuple B of n Boolean variables determines the feasible set of literals, then the pointer of feasible solutions f(B) = 1 for all tuples. In other words, in this case, the PFS is a constant unity.
called alternative (contraries). Any tuple of non-alternative literals would represent a feasible solution to the problem. Since each tuple B of n Boolean variables determines the feasible set of literals, then the pointer of feasible solutions f(B) = 1 for all tuples. In other words, in this case, the PFS is a constant unity.
The cost function is defined by the given Boolean function, that is, .
.
3. On the Complexity of Solutions
In the process of solving the problem, we have two stages:
• Input of initial data of the problem;
• The proper stage of solving the problem.
The number of symbols, which is required for recording initial data, is the dimension of the problem. To solve the problem, it is obviously necessary at least once “view” all of its initial data. Therefore, the complexity of solving any problem cannot be less than O(n), where n is the dimension of the problem. An example of such a problem can be a problem to find the maximum element of the array M.
In principle, the problem of the search of the maximum element of an array (PME) M can be represented in the form of our logical model. For example, the binary address of the cell of the array can be considered as a set of abstract Boolean variables. The pointer of feasible solutions in this case is a constant 1. The cost function is given by the comparison procedure given numbers. Clearly, to solve this problem, it is necessary to consider all elements of the array, since we do not know how its values of these elements are arranged in an array.
Next, we consider the following example.
Let there be a Boolean tuple of length 4 (a tetrad) . We associate each such tuple with the number T = w1 + w2 + w3 + w4―a weight of the tetrad X. Summands
. We associate each such tuple with the number T = w1 + w2 + w3 + w4―a weight of the tetrad X. Summands 
 is calculated as follows:
is calculated as follows:
• if x1 = 0 then w1 := 5 else w1 := 13;
• if x1 = 0 and x2 = 0 then w2 := 7;
• if x1 = 0 and x2 = 1 then w2 := 10;
• if x1 = 1 and x2 = 0 then w2 := 12;
• if x1 = 1 and x2 = 1 then w2 := 4;
• if x3 = 0 then w3 := 3 else w3 := 8;
• if x3 = 0 and x4 = 0 then w4 := 2;
• if x3 = 0 and x4 = 1 then w4 := 15;
• if x3 = 1 and x4 = 0 then w4 := 3;
• if x3 = 1 and x4 = 1 then w4 := 17.
We assume that the values of the summands , depending on the specified conditions, are determined by some random process. We believe that the weight of the tetrad T equals to T = w1 + w2 + w3 + w4.
, depending on the specified conditions, are determined by some random process. We believe that the weight of the tetrad T equals to T = w1 + w2 + w3 + w4.
Also suppose that there is a pointer of feasible solutions , it’s presented in the table below. Furthermore, in this table, weights of the corresponding tetrads are calculated.
, it’s presented in the table below. Furthermore, in this table, weights of the corresponding tetrads are calculated.
It is easy to see that we have an equilibrium Boolean function, that is, on half of tuples, this Boolean function equals to 0, and the other half equals to 1. The formula for calculating the given Boolean function (the pointer of feasible solutions) has the form:

Let it be required to find a tuple X of the maximum weight at which f(X) = 1.
In general, the considered problem (we call it as “Heavy tuple (HT)”) can be formulated as follows.
Suppose we have n Boolean variables . For simplicity, we assume that n = 4k (k ³ 1). For each tuple
. For simplicity, we assume that n = 4k (k ³ 1). For each tuple  of Boolean variables
of Boolean variables , we define its weight w(S) as the sum of the weights of its tetrads.
, we define its weight w(S) as the sum of the weights of its tetrads.

In addition, let be the given the equilibrium Boolean function , whose value can be computed in polynomial time by n:
, whose value can be computed in polynomial time by n: .
.
It is required to find a tuple  of the maximum weight
of the maximum weight  such that f(S) = 1.
such that f(S) = 1.
The same problem in the decision form was formulated in [4] . It was also shown that the problem belongs to the class NP. A difference problem “Heavy tuple” from problems, presented in Examples 1-3, is the absence of knowledge of the predicate P(S), that is, we do not know the properties that must be satisfied of every feasible solution.
Theorem 1. The problem “Heavy tuple” cannot be solved in polynomial time on the dimension of the problem.
Obviously, the problem HT is formulated as an analogue of the problem of finding the maximum element of the given array (PME).
In fact, in the problem “Heavy tuple”, addresses (binary tuples) of the array of feasible solutions are determined by the pointer of feasible solutions f. Calculation of the address in this case can be performed by brute force only, because otherwise we have a problem searching for the function , the inverse of the PFS , that is, find a tuple of values of Boolean variables, where the pointer of feasible solutions equals to 1. The procedure for calculating such an address is not associated with the weight of the array element. Only after obtaining the address of the array element, we find (calculate) its value. The same sequence of operations is used for PME.
, the inverse of the PFS , that is, find a tuple of values of Boolean variables, where the pointer of feasible solutions equals to 1. The procedure for calculating such an address is not associated with the weight of the array element. Only after obtaining the address of the array element, we find (calculate) its value. The same sequence of operations is used for PME.
Assuming that we can calculate the tuple S, where there is the maximum weight. However, such tuple may not be the feasible solution, as the pointer f(S) = 0. Since we do not know the predicate P(S) explicitly, this does not allow considering other ways to solve the “preview” of all elements of a given array of feasible solutions, the number of which is not less than .
.
Corollary 1. The class P does not coincide with the class NP, that is, P É NP.
4. Conclusion
The proposed combinatorial model allows considering not only the well-known combinatorial problems, but also considering new problems such as “Heavy tuple” with single point of view. The most important consequence of the proposed model is to establish the inequality of classes P and NP on the example of the problem “Heavy tuple”. The conclusions, obtained in the study of this problem, cannot be extended to problems, considered in Examples 1-3, as predicate P(S) explicitly specified in them.
Cite this paper
Anatoly D. Plotnikov, (2015) On a Logical Model of Combinatorial Problems. Open Access Library Journal,02,1-6. doi: 10.4236/oalib.1101479
References
- 1. Garey, M.R. and Johnsonm D.S. (1979) Computers and Intractability. W. H. Freeman and Company, San Francis-co.
- 2. Papadimitriou, C.H. and Steiglitz, K. (1982) Combinatorial Optimization: Algorithms and Complexity. Prentice-Hall Inc., Upper Saddle River, NY.
- 3. Crescenzi, P. and Kann,V. (1997) Approximation on the Web: A Compendium of NP Optimization Problems. Proceedings of International Workshop RANDOM’97, Bologna, 11-12 July 1997, 111-118.
- 4. Plotnikov, A.D. (2013) On the Structure of the Class NP. Computer Communication & Collaboration, 1, 19-25.