Creative Education
2011. Vol.2, No.3, 292-295
Copyright © 2011 SciRes. DOI:10.4236/ce.2011.23040
Teaching PCA through Letter Recognition
Tanja Van Hecke
Faculty of Applied Engineering Sciences, University College Ghent, Ghent, Belgium.
Email: Tanja.VanHecke@hogent.be
Received February 8th, 2011; revised March 14th, 2011; accepted April 2nd, 2011.
This article presents the use of a real life problem to reach a deeper understanding among students of the benefits
of principal components analysis. Pattern recognition applied on the 26 letters of the alphabet is a recognizable
topic for the students. Moreover it is still verifiable with computer algebra software. By means of well defined
exercises the student can be guided in an active way through the learning process.
Keywords: Data Reduction, Eigenvalues, Eigenvectors
Introduction
Principal Components Analysis (PCA) is a statistical tech-
nique for data reduction which is taught to students mostly with
a pure mathematical approach. This paper describes how teach-
ers can introduce students to the concepts of principal compo-
nents analysis by means of letter recognition. The described
approach is one of an active learning environment (with
hands-on exercises can be implemented in the classroom), a
platform to engage students in the learning process and may
increase student/student and student/instructor interaction. The
activities require use of some basic matrix algebra and eigen-
value/eigenvector theory. As such they build on knowledge
students have acquired in matrix algebra classes.
Former attempts to develop a more creative instruction ap-
proach for PCA can be found with Dassonville and Hahn
(Dassonville, 2000). They developed a CD-rom geared to the
teaching of PCA for business school students. The test of this
pedagogical tool showed that this new approach, based on dy-
namic graphical representations, eased the introduction to the
field, yet did not foster more effective appropriation of those
concepts. Besides, when the program was used in self tuition
mode, the students felt disconnected from the class environ-
ment, as Dassonville and Hahn claim themselves.
A second initiative is DoLStat@d (Mori, 2003), developed at
Okayama University in Japan by Yuichi Mori and colleagues.
This web based learning system, available online at
http://mo161.soci.ous.ac.jp/@d/DoLStat/index.html, provides
real world data with their analysis stories about various topics,
PCA included. Since only applications are presented, without
any background information about the method itself, students
unfamiliar to PCA, will not reach a deeper understanding about
PCA and will keep stabbing at a recipe approach.
Principal Components Analysis
The objective of PCA (Jackson, 2003) is to obtain a
low-dimensional representation of the objects/individuals with
minimum information loss, which facilitates compression of the
initial data and extracting the most relevant characteristics.
PCA is a known data reduction technique in statistical pat-
tern recognition and signal processing (Kastleman, 1996) (Turk,
1991). It is valuable because it is a simple non-parametric
method of extracting relevant information from confusing
datasets. PCA is also called the Karhunen-Loeve Transform
(KLT, named after Kari Karhunen (Karhunen, 1947) & Michel
Loève (Loève, 1978)) or the Hotelling Transform (Hotelling,
1935).
PCA involves finding eigenvalues and corresponding eigen-
vectors of the data set, using the covariance matrix. The corre-
sponding eigenvalues of the matrix give an indication of the
amount of information the respective principal components
represent. The methodology for calculating principal compo-
nents is given by the following algorithm.
Let 12
,,,
m
xx be the variables.
Computation of the global means i
1, 2,,im
Computation of the sample covariance matrix Σ of di-
mension mm
Computation of the eigenvalues and eigenvectors of Σ
Keep only the n eigenvectors
12
,,,
ii im
vv v
i
v
1, 2,,in corresponding to the largest eigenvalues. Then
11 21, 2,,
ii n are called principal com-
ponents.
2
vx vx im
x
m
v i
Corresponding eigenvectors are uncorrelated and have the
greater variance. In order to avoid the components that have an
undue influence on the analysis, the components are usually
coded with mean as zero and variance as one. This standardiza-
tion of the measurement ensures that they all have equal weight
in the analysis.
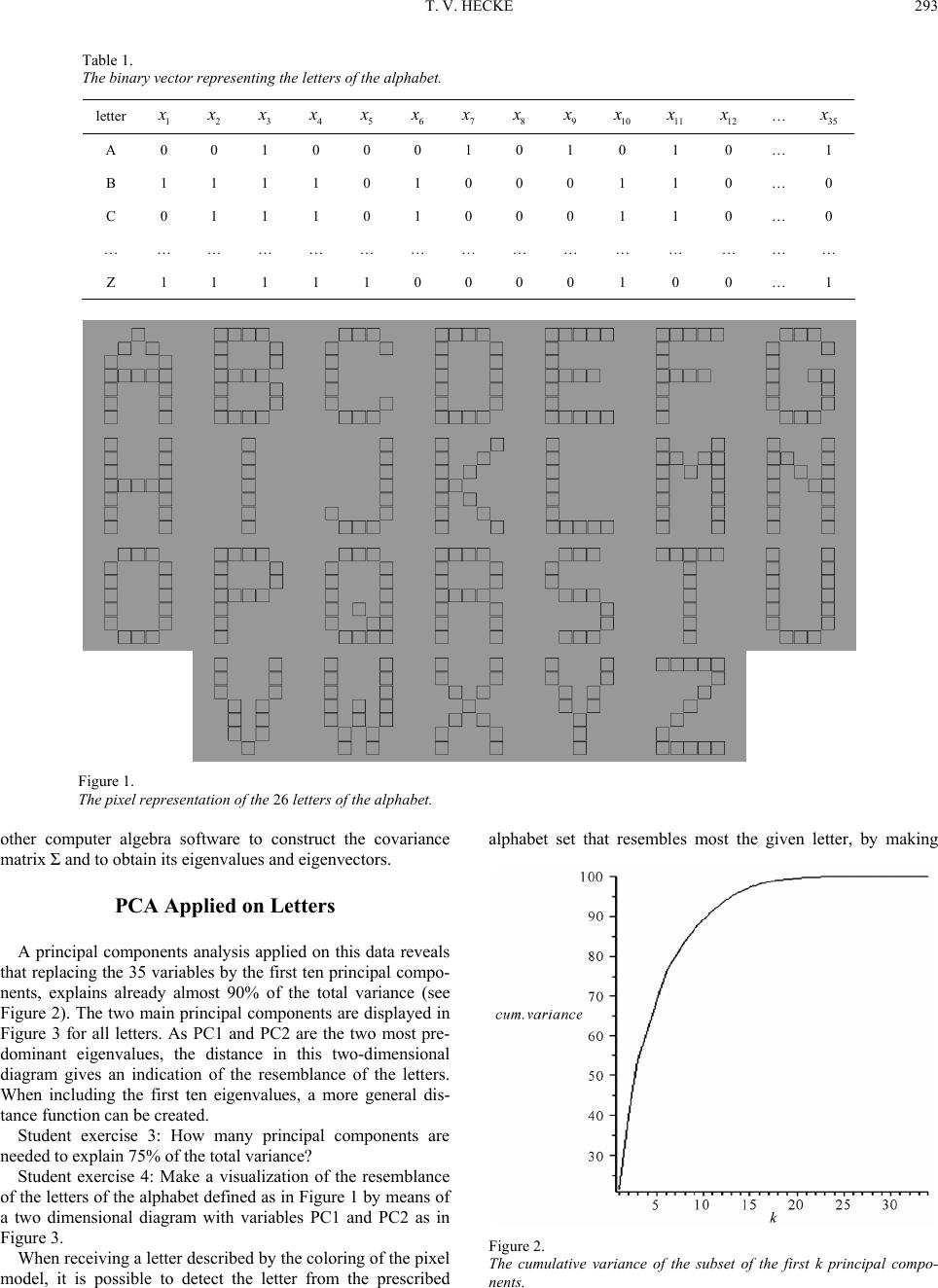
Representation of Letters by Binary Variables
We use the pixel representation with seven rows and five
columns as in Figure 1 for the alphabet. This image is trans-
formed into a binary vector representation (see Table 1). This
was accomplished by using 35 variables i
by running the figure from top to down and from left to right
assigning 1 to an occupied pixel and 0 to a non-occupied pixel.
1, 2,, 35i
Student exercise 1: Make the binary vector representation of
the 26 letters of the alphabet (less time consuming: each student
makes one).
Student exercise 2: Use Maple (www.maplesoft.com) or some