Open Journal of Social Sciences
Vol.04 No.03(2016), Article ID:64090,4 pages
10.4236/jss.2016.43002
Regression Mathematical Model of Impact Factors for Social Science Journals Based on Information Reused Analysis Method
Xuexia Wei*, Xiao Dong, Shiqiang Zhang
Medical Information College, Chongqing Medical University, Chongqing, China



Received 12 January 2016; accepted 26 February 2016; published 1 March 2016
ABSTRACT
A regression mathematical model of impact factors for social science journals was given based on information reused analysis method. This regression mathematical model could evaluate and predict change tendency of the impact factor of the social science journals.
Keywords:
Impact Factor, Regression, Mathematical Model, Social Science

1. Introduction
In the era of big data, it is important to find out the information hiding behind the data. Journal Citation Reports [1] published by the institute for scientific information is known as the most authoritative journal evaluation system. According to journal citation report published by ISI, we can get the data of impact factors for social science journals. Based on these data, a regression mathematical model of impact factors for social science journals was given based on information reused analysis method [2].
2. Information Reused Analysis Method
Hypothesis t = {t1, t2, ∙∙∙, tn} indicates time series, the original data sequence corresponding to the time series is x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)}. The differential operation of time series t = {t1, t2, ∙∙∙, tn} is ∆tk = tk − tk−1, when differential ∆tk = const, the original data sequence x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)} is equal-space sequence. When differential ∆tk ≠ const, the original data sequence x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)} is non-equal-space sequence. According to the grey system theory [3] One-accumulated generate sequence of the original data sequence x(0) = {x(0)(t1), x(0)( t2), ∙∙∙, x(0)(tn)} is x(1) = {x(1)(t1), x(1)(t2), ∙∙∙, x(1)(tn)}, where in
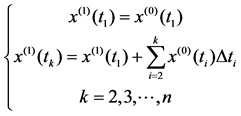 (1)
(1)
When sequence x(1) = {x(1)(t1), x(1)(t2), ∙∙∙, x(1)(tn)} was close to nonhomogeneous exponential law change, the solution x(1)(t) of differential equation (2) was called the response function.
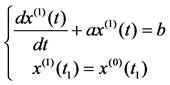 (2)
(2)
This response function x(1)(t) was
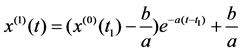 .
.
In response function x(1)(t), the constants a and b were called uncertain parameters. Discrete response function x(1)(t) of the differential equation (2) was
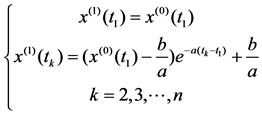 (3)
(3)
In response function x(1)(t), for determining constants a and b, we could use differential operation of difference Equation (2). That is
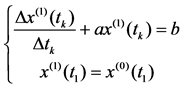 (4)
(4)
In differential operation (4), we could get
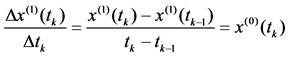 .
.
In differential operation (4), let l∈[0,1],smoothing x(1)(tk) of differential Equation (4) by formula z(1)(tk) = λx(1)(tk) + (1 − λ)x(1)(tk−1), we could get differential equation as follow
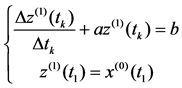 (5)
(5)
In above differential Equation (5), l was called as background parameters and z(1)(tk) was called as background value At present, there is still no optimum getter for background parameters l, in order to be used simply and easily, we generally take background parameters for 1/
Substituting one-accumulated generate sequence of original sequence x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)} into above differential equation, with matrix equation a and b could be [a b]T = (BTB)−1BTY determined, inside Y = [x(0)(t2), x(0)(t3), ∙∙∙, x(0)(tn)]T, and
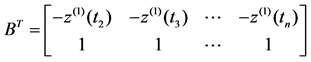 .
.
Substituting obtained parameters a and b into differential operation (4), we could get traditional GM(1.1) model of sequence x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)}:
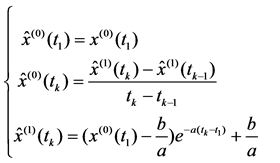 (6)
(6)
Fitting and forecast precision sometimes of the traditional GM(1.1) model was poor. We put forward a information reused analysis method. Firstly, we could call traditional GM (1.1) model (6) of original sequence x(0) = {x(0)(t1), x(0)(t2), ∙∙∙, x(0)(tn)} as rough model. Then we rewrote third formulas of rough model (6) as lollow, wherein, a and b were new uncertain parameters.
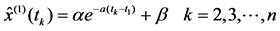 (7)
(7)
Third, using the accumulated generate sequence and corresponding time series of original sequence again, substituting the accumulated generate sequence x(1) = {x(1)(t1), x(1)(t2), ∙∙∙, x(1)(tn)} and corresponding time series of original sequence t = {t1, t2,∙∙∙, tn} into above formula (7), we could determine uncertain parameters a and b with matrix equation [4] [a b]T = (BTB)−1BTY, inside Y = [x(1)(t1), x(1)(t2), ∙∙∙, x(1)(tn)]T and
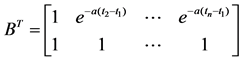 .
.
Substituting parameters a and b into Equation (7), we could get the reducing value of original sequence x(0) = {x(0)(t1), x(0)( t2), ∙∙∙, x(0)(tn)}
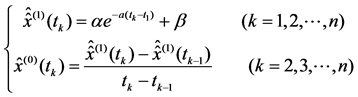 (8)
(8)
The formula (8) was the regression mathematical model based on information reused analysis method.
3. Regression Mathematical Model of Impact Factors for Social Science Journals
Accoding to the average impact factor (IF) data [1] of the top 20 social science journals, that is {(2004, 14.47655),(2005,14.2287),(2006,15.3813),(2007,16.2098),(2008,16.7604),(2009,17.3631),(2010,18.34185),(2011,18.5654),(2012,18.53725),(2013,18.7618)},the regression mathematical model based on information reused analysis method as follow
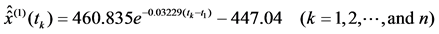
Figure 1 is a diagram of the curve of original data for social science journals and its simulation data based on information reused analysis method from 2004 to 2013.
Figure 2 is a diagram of the curve of simulation data of the average impact factor (IF) for social science journals form 2004 to 2019.
From 2004 to 2019 the simulation data of the average impact factor (IF) for social science journals over time trend graph can be seen that the number of the average impact factor (IF) for social science journals is gradually slowly increase trend. The simulation data of the average impact factor (IF) for social science journals form 2015 to 2019 could be forecasted as follow:{(2015, 20.88736246), (2016, 21.57282944), (2017, 22.2807916), (2018, 23.01198718), (2019, 23.76717862)}.

Figure 1. The tendency curve of the average impact factor with time.

Figure 2. The curve of simulation data of the average impact factor (IF) form 2004 to 2019.
4. Conclusions
This paper gives a modeling way based on information reused analysis method. On the one hand, this way based on information reused analysis method greatly improved GM (1,1) model’s fitting precision and prediction accuracy; on the other hand, it maintains the advantage of the traditional modeling method which is simple. The model based on information reused analysis method evaluates and predicts the average impact factor (IF) trend of the top 20 social science journals. Case analysis verified the validity and usefulness of the model based on information reused analysis method. The way based on information reused analysis method can provide reference for social science researchers.
Cite this paper
Xuexia Wei,Xiao Dong,Shiqiang Zhang, (2016) Regression Mathematical Model of Impact Factors for Social Science Journals Based on Information Reused Analysis Method. Open Journal of Social Sciences,04,7-10. doi: 10.4236/jss.2016.43002
References
- 1. Institute Science Information (ISI). Journal Citation Reports, JCR. http://admin.isiknowledge.com/JCR
- 2. Zhang, S.Q. (2009) Modeling Method of Grey System GM(1.1) Model Based Information Reused and It’s Application. Mathematics in Practice and Theory, 39, 97-104.
- 3. Deng, J.L. (1982) Control Problems of Grey Systems. Systems & Control Letters, 1, 288-294. http://dx.doi.org/10.1016/S0167-6911(82)80025-X
- 4. Zhang, S.Q. and Jiang, Z. (2010) Modeling Method of Logisitic Model Based Grey System. Mathematics in Practice and Theory, 40, 144-148.
NOTES

*Corresponding author.