A. Choudhury, S. Nagaswamy
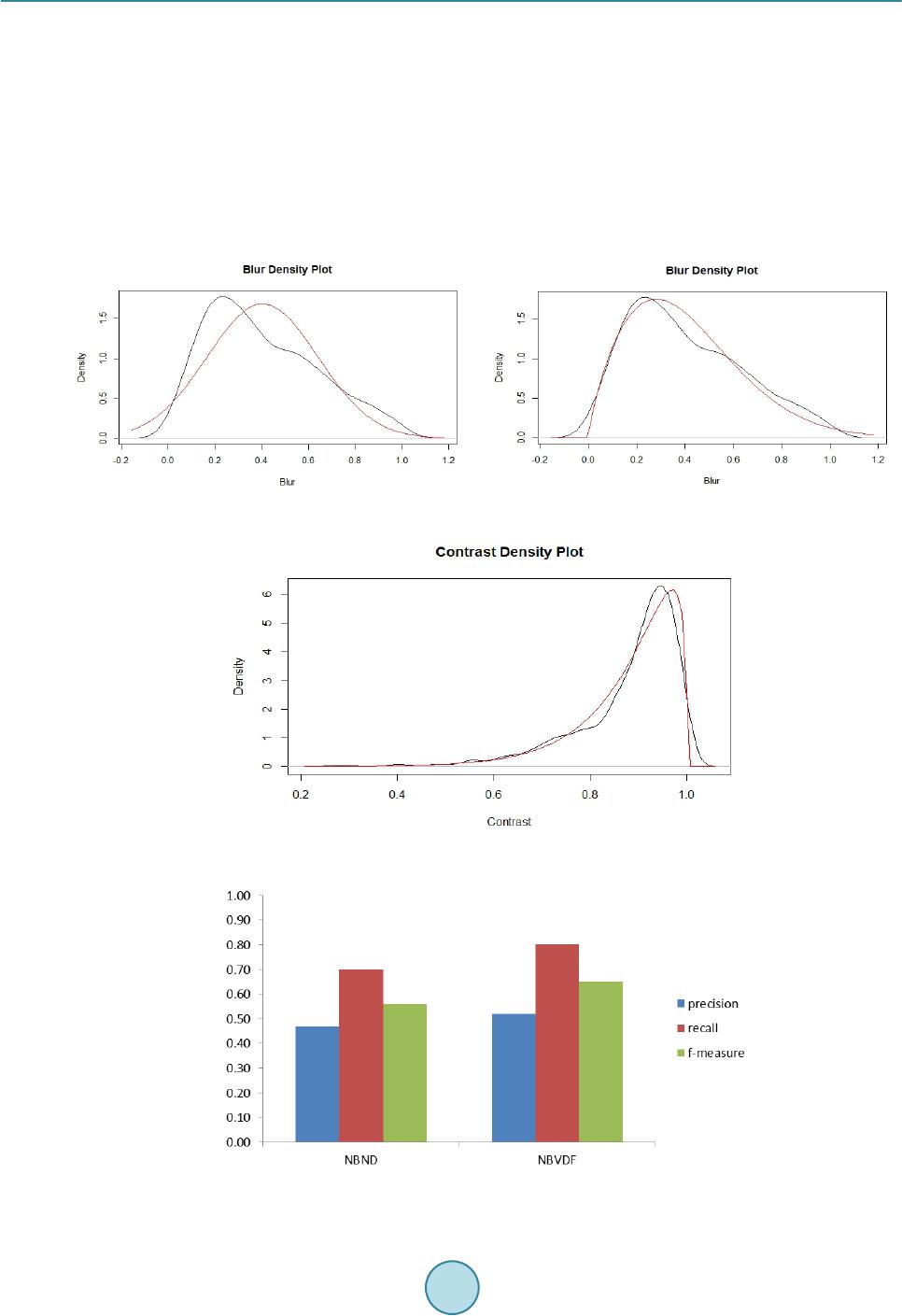
Table 4. Goodness of fit (p-values) .
Features Normal Gamma Weibull
Brightness 0.641 0.003 0.60
Blur 0.0 0.175 0.455
Motion Blur 0.004 0.036 0.703
Over Exposure 0.0 0.0 0.228
Contrast 0.0 0.047 0.034
5. Conclusion
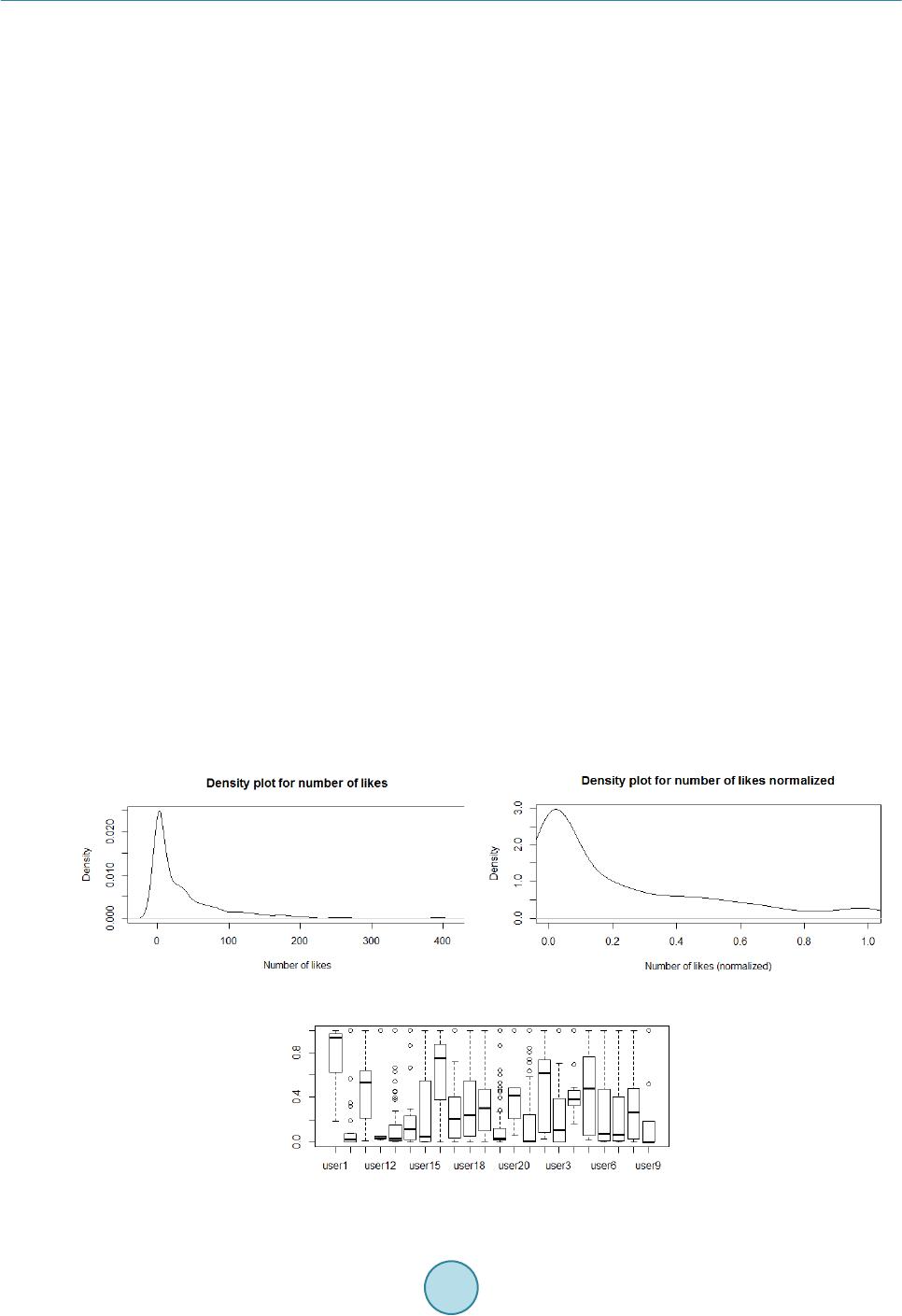
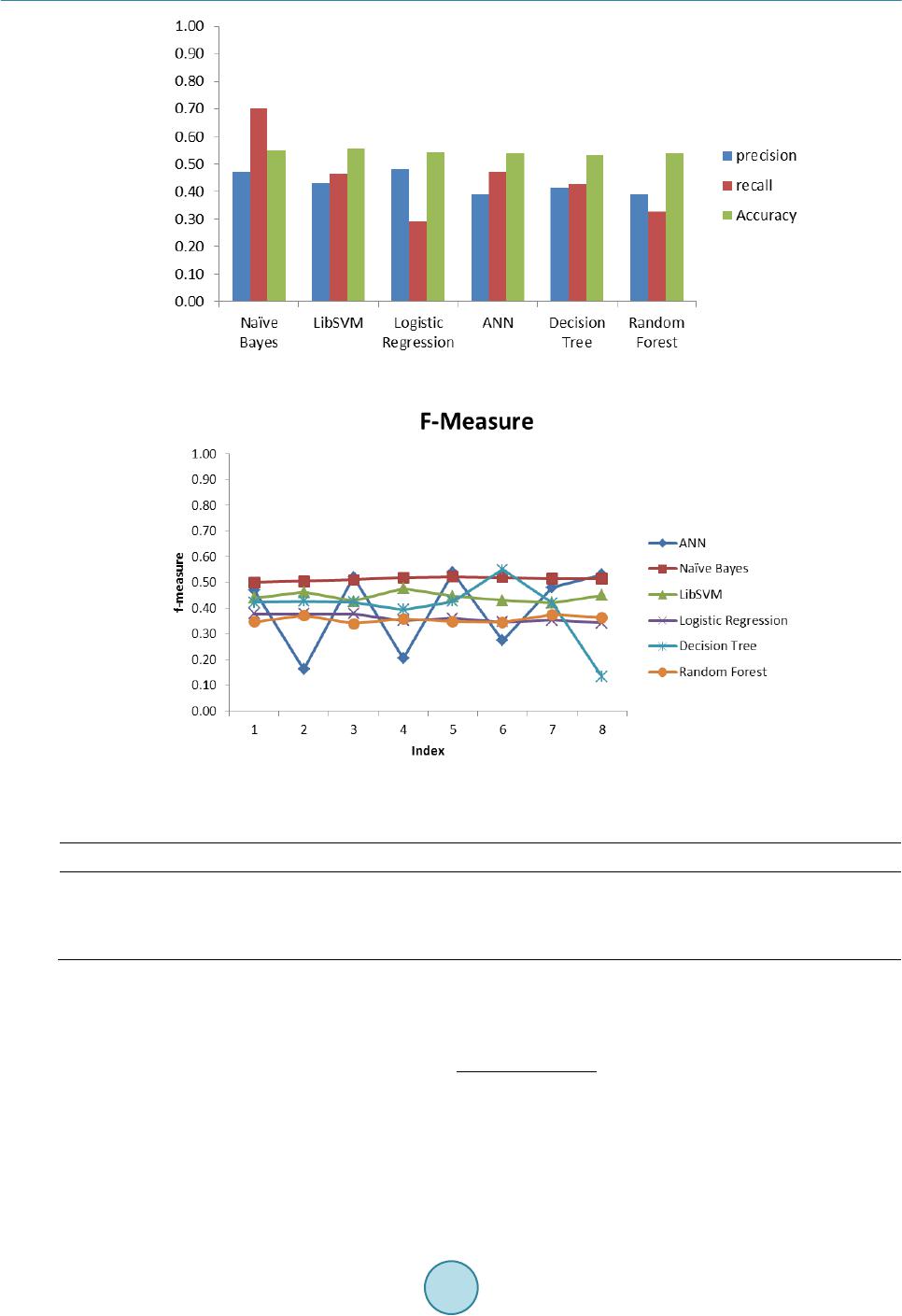
A regression based popularity prediction has constrains such as: low accuracy when only image content is used,
system overhead due to large number of features and highly dependent on social data which may not always be
available. In most cases one is concerned with the final decision on whether or not an image is going to be pop-
ular and not be concerned about the number of views or likes. Thus solving the classification problem is much
more intuitive and a simple Naïve Bayes variant works well without much system overhead. In future we plan to
add contextual information to improve the overall precision and recall. In our work we have been able to show
that one may choose to ignore any social aspect associated with the image and still achieve significant precision
and recall to predict popularity of an image purely based on image features.
References
[1] Petrovic, S., Osborne, M. and Lavrenko, V. (2011) Rt to Win! Predicting Message Propagation in Twitter. ICWSM.
[2] Hong, L., Dan, O. and Davison, B.D. (2011) Predicting Popular Messages in Twitter. WWW (Companion Volume),
57-58. http://dx.doi.org/10.1145/1963192.1963222
[3] Pinto, H. , Almeida, J.M. and Goncalves, M.A. (2013) Using Early View Patterns to Predict the Popularity of Youtube
Videos. WSDM, 365-374.
[4] Shamma, D.A., Yew, J., Kennedy, L. and Churchill, E.F. (2011) Viral Actions: Predicting Video View Counts Using
Synchronous Sharing Behaviors. ICWSM.
[5] Nwana, A.O., Avestimehr, S. and Chen, T. (2013) A Latent Social Approach to Youtube Popularity Prediction. C oRR .
[6] Khosla, A., Sarma, A.D. and Hamid, R. (2014) What Makes an Image Popular? IW3C2.
[7] Figueiredo, F. (2013) On the Prediction of Popularity of Trends and Hits for User Generated Videos. Proceedings of
the Sixth ACM International Conference on Web Search and Data Mining, 741-746.
http://dx.doi.org/10.1145/2433396.2433489
[8] Figueiredo, F., Benevenuto, F. and Almeida, J.M. (2011) The Tube over Time: Characterizing Popularity Growth of
YouTube Videos. Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, 745-
754. http://dx.doi.org/10.1145/1935826.1935925
[9] Vanwinckelen, G. and Meert, W. (2014) Predicting the Popularity of Online Articles with Random Forests. ECML/
PKDD Discovery Challenge on Predictive Web Analytics, Nancy, September 2014.
[10] Yu, B., Chen, M. and Kwok, L. (2011) Toward Predicting Popularity of Social Marketing Messages. Salerno, J., et al.,
Eds., SBP 2011, LNCS 6589, 317-324. http://dx.doi.org/10.1007/978-3-642-19656-0_44
[11] He, X., et al. (2014) Practical Lessons from Predicting Clicks on Ads at Facebook. ADKDD’14, 24-27 August 2014.
http://dx.doi.org/10.1145/2648584.2648589
[12] Cheng, J., Adamic, L.A. , Dow, P.A., Kleinberg, J. and Leskovec, J. Can Cascades Be Predicted? WWW’14, Seoul,
Republic of Korea.
[13] Daume III, H. A Course in Machine Learning. Chapter 5.1, 69.