Intelligent Information Management
Vol.2 No.6(2010), Article ID:2031,5 pages DOI:10.4236/iim.2010.26047
Experiments with Two New Boosting Algorithms
1Software College, Shenyang Normal University, Shenyang, China
2Liaoning SG Automotive Group Co., Ltd., Shenyang, China
E-mail: junyaomail@163.com, hongbo.zhou@hotmail.com
Received April 2, 2010; revised May 5, 2010; accepted June 8, 2010
Keywords: Boosting, Combination Method, TAN, BAN, Bayesian Network Classifier
Abstract
Boosting is an effective classifier combination method, which can improve classification performance of an unstable learning algorithm. But it dose not make much more improvement of a stable learning algorithm. In this paper, multiple TAN classifiers are combined by a combination method called Boosting-MultiTAN that is compared with the Boosting-BAN classifier which is boosting based on BAN combination. We describe experiments that carried out to assess how well the two algorithms perform on real learning problems. Finally, experimental results show that the Boosting-BAN has higher classification accuracy on most data sets, but Boosting-MultiTAN has good effect on others. These results argue that boosting algorithm deserve more attention in machine learning and data mining communities.
1. Introduction
Classification is a fundamental task in fault diagnosis, pattern recognition and forecasting. In general, a classifier is a function that chooses a class label (from a group of predefined labels) for instance described by a set of features (attributes). Learning accurate classifiers from pre-classified data is a very active research topic in machine learning and data mining. In the past two decades, many classifiers have been developed, such as decision trees based classifiers and neural network based classifiers.
Boosting [1-4] is a general method for improving the performance of any “weak” learning algorithm. In theory, boosting can be used to significantly reduce the error of any “weak” learning algorithm that consistently generates classifiers which need only be a little bit better than random guessing. Despite the potential benefits of boosting promised by the theoretical results, the true practical value of boosting can only be assessed by testing the method on “real” learning problems. In this paper, we present such experimental assessment of two new boosting algorithms.
The first provably effective boosting algorithms were presented by Schapire [5] and Freund [3]. Boosting works by repeatedly running a given weak learning algorithm on various distributions over the training data, and then combining the classifiers produced by the weak learner into a single composite classifier. More recently, we described and analyzed AdaBoost, and we argued that this new boosting algorithm has certain properties which make it more practical and easier to implement than its predecessors.
TAN [6] and BAN [7] are augmented Bayesian network classifiers provided by Friedman and Cheng J. In these papers, we treat the classification node as the first node in the ordering. The order of other nodes is arbitrary; we simply use the order they appear in the dataset. Therefore, we only need to use the CLB1 algorithm, which has the time complexity of O (N2) on the mutual information test (N is the number of attributes in the dataset) and linear on the number of cases. The efficiency is achieved by directly extending the Chow-Liu tree construction algorithm [8] to a three-phase BN learning algorithm: drafting, which is essentially the Chow-Liu algorithm, thickening, which adds edges to the draft, and thinning, which verifies the necessity of each edge.
In this paper, multiple TAN classifiers are combined by a combination method called Boosting-MultiTAN that is compared with the Boosting-BAN classifier which is boosting based on BAN combination. Section 2 defines two classes of BNs, i.e., Tree augmented NaiveBayes (TANs) and BN augmented Naïve-Bayes (BANs), and describes methods for learning each. Section 3 proposes two new boosting algorithms, such as BoostingMultiTAN classifier and Boosting-BAN classifier. Section 4 presents and analyzes the experimental results. These results argue that boosting algorithm deserve more attention in machine learning and data mining communities.
2. Learning Bayesian Network Classifiers
Learning Bayesian network classifiers involves two steps: structure learning and parameter (conditional probability tables) learning. We will focus on structure learning methods for different Bayesian network classifiers in the subsections below.
2.1. Tree Augmented Naive-Bayes (TAN)
Letting X = {x1, …, xn, c} represent the node set (where c is the classification node) of the data. The algorithm for learning TAN classifier first learns a tree structure over V\{c}, using mutual information tests. It then adds a link from the classification node to each feature node in the manner as we construct a Naive-Bayes (i.e., the classifycation node is a parent of all other nodes.) A simple TAN structure is shown in Figure 1 (Note that features x1, x2, x3, x4 form a tree).
The learning procedure can be described as follows.
1) Take the training set and X\{c} as input.
2) Call the modified Chow-Liu algorithm. (The originnal algorithm is modified by replacing every mutual information test I(xi, xj) with a conditional mutual information test I(xi, xj|{c})).
3) Add c as a parent of every xi where 1 ≤ i ≤ n.
4) Learn the parameters and output the TAN.
This algorithm, which is modified from the Chow-Liu algorithm, requires O(N2) numbers of conditional mutual information tests. This algorithm is essentially the first phase of the BAN-learning algorithm. TAN classifier is stable that can not be combined with a quite strong learning algorithm by boosting.
2.2. BN Augmented Naive-Bayes (BAN)
BAN classifier has been studied in several papers. The basic idea of this algorithm is just like the TAN learner of Subsection 2.1, but the unrestricted BN-learning algorithm instead of a tree-learning algorithm (see Figure 2).
Letting X = {x1, …, xn, c} represent the feature set (where c is the classification node) of the data, the learning procedure based on mutual information test can be described as follows.
1) Take the training set and X\{c} (along with the ordering) as input.
2) Call the modified CBL1 algorithm. (The original algorithm is modified in the following way: replace every
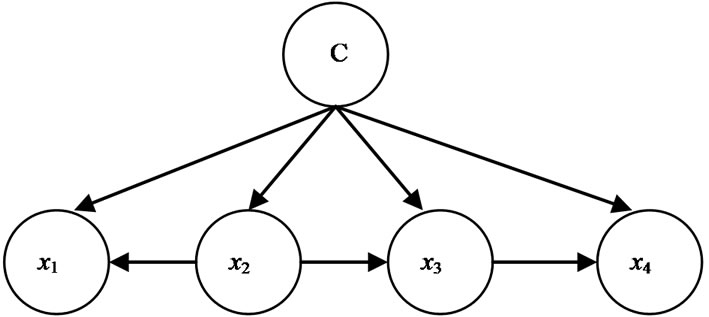
Figure 1. A simple TAN structure.
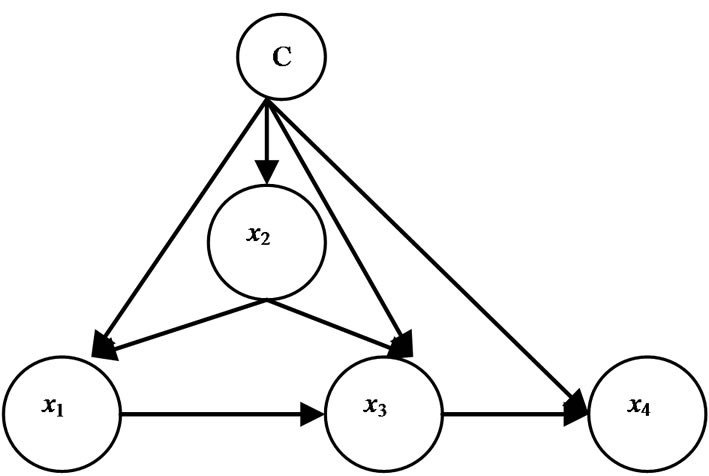
Figure 2. A simple BAN structure.
mutual information test I(xi, xj) with a conditional mutual information test I(xi, xj|{c}); replace every conditional mutual information test I(xi, xj|Z) with I(xi, xj|Z + {c}), where Z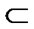 X\{c}.
X\{c}.
3) Add c as a parent of every xi where 1 ≤ i ≤ n.
4) Learn the parameters and output the BAN.
Like the TAN-learning algorithm, this algorithm dose not require additional mutual information tests, and so it requires O(n2N) (where n is the number of node attributes; N is the number of training examples) mutual information tests. The longest time spent in the algorithm is to calculate mutual information. In BAN structure, the second step in the three-phase is used 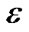 to sort mutual information. The
to sort mutual information. The 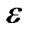 is a given small positive threshold, it is not fixed, and can be changed in many times. By setting different thresholds
is a given small positive threshold, it is not fixed, and can be changed in many times. By setting different thresholds 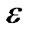 can construct many BAN classifiers. BAN classifier is unstable that can be combined with a quite strong learning algorithm by boosting.
can construct many BAN classifiers. BAN classifier is unstable that can be combined with a quite strong learning algorithm by boosting.
3. Two New Boosting Algorithms
3.1. Boosting-MultiTAN Algorithm
GTAN [9] is proposed by Hongbo Shi in 2004. GTAN used conditional mutual information as CI tests to measure the average information between two nodes when the statuses of some values are changed by the condition-set C. When I(xi, xj|{c}) is larger than a certain threshold value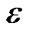 , we choose the edge to the BN structure to form TAN. Start-edge and
, we choose the edge to the BN structure to form TAN. Start-edge and 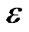 are two important parameters in GTAN. Different Start-edges can construct different TANs. GTAN classifier is unstable that can be combined with a quite strong learning algorithm by boosting.
are two important parameters in GTAN. Different Start-edges can construct different TANs. GTAN classifier is unstable that can be combined with a quite strong learning algorithm by boosting.
The Boosting-MultiTAN algorithm may be characterized by the way in which the hypothesis weights wi are selected, and by the example weight update step.
Boosting-MultiTAN (Dataset, T):
Input: sequence of N example Dataset = {(x1, y1),…, (xN, yN)} with labels yi ∈ Y = {1,…, k}, integer T specifying number of iterations.
Initialize 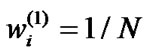 for all i, TrainData-1 = Dataset Start-edge = 1; t = 1; l = 1 While ((t ≤ T) and (l ≤ 2T))
for all i, TrainData-1 = Dataset Start-edge = 1; t = 1; l = 1 While ((t ≤ T) and (l ≤ 2T))
1) Use TrainData-t and start-edge call GTAN, providing it with the distribution.
2) Get back a hypothesis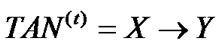 .
.
3) Calculate the error of TAN(t):
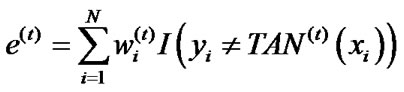 .
.
If e(t) ≥ 0.5, then set T = t – 1 and abort loop.
4) Set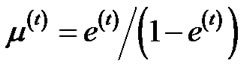 .
.
5) Updating distribution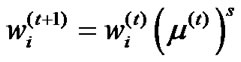 , where
, where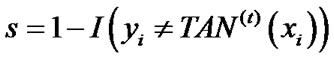 .
.
6) Normalize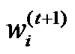 , to sum to 1.
, to sum to 1.
7) t = t + 1, l = l + 1, start-edge = start-edge + n/2T.
8) end While Output the final hypothesis:
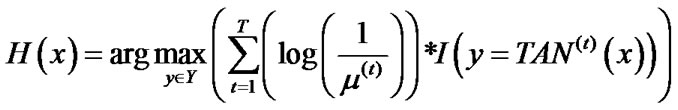
3.2. Boosting-BAN Algorithm
Boosting-BAN works by fitting a base learner to the training data using a vector or matrix of weights. These are then updated by increasing the relative weight assigned to examples that are misclassified at the current round. This forces the learner to focus on the examples that it finds harder to classify. After T iterations the output hypotheses are combined using a series of probabilistic estimates based on their training accuracy.
The Boosting-BAN algorithm may be characterized by the way in which the hypothesis weights wi are selected, and by the example weight update step.
Boosting-BAN (Dataset, T):
Input: sequence of N example Dataset = {(x1, y1),…, (xN, yN)} with labels yi ∈ Y = {1, …, k}, integer T specifying number of iterations.
Initialize 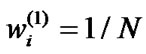 for all i, TrainData-1 = Dataset Do for t = 1, 2,…, T 1) Use TrainData-t and threshold
for all i, TrainData-1 = Dataset Do for t = 1, 2,…, T 1) Use TrainData-t and threshold 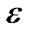 call BAN, providing it with the distribution.
call BAN, providing it with the distribution.
2) Get back a hypothesis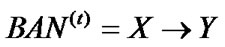 .
.
3) Calculate the error of BAN(t):
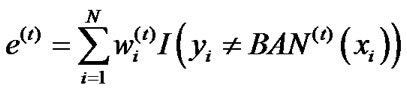 .
.
If e(t) ≥ 0.5, then set T = t – 1 and abort loop.
4) Set 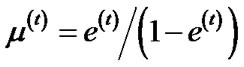
5) Updating distribution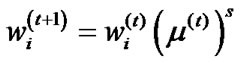 , where
, where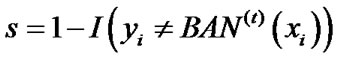 .
.
6) Normalize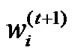 , to sum to 1.
, to sum to 1.
Output the final hypothesis:
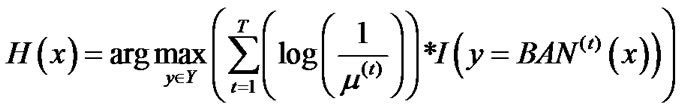
4. The Experimental Results
We conducted our experiments on a collection of machine learning datasets available from the UCI [10]. A summary of some of the properties of these datasets is given in Table 1. Some datasets are provided with a test set. For these, we reran each algorithm 20 times (since some of the algorithms are randomized), and averaged the results. For datasets with no provided test set, we used 10-fold cross validation, and averaged the results over 10 runs (for a total of 100 runs of each algorithm on each dataset).
In our experiments, we set the number of rounds of boosting to be T = 100.
The results of our experiments are shown in Table 2. The figures indicate test correct rate averaged over multiple runs of each algorithm. The bold in the table show that the classification is superior than another one obviously. From Table 2 in the 20 datasets, Boosting-BAN did significantly and uniformly better than BoostingMultiTAN.
On the data sets “Car”, “Iris” and “LED”, the BoostingMultiTAN was inferior to the Boosting-BAN. The Boosting-BAN correct rate was better than the BoostingMultiTAN correct rate in another 17 datasets. The reason is, in these cases the rate of attributes and classes are less than other Datasets. This reveals that the features in the three datasets are most dependent to each other. These weak dependencies can improve the prediction accuracy significantly, as we see from Table 2. These experiments also indicate that when the dataset is small and data loss, the boosting error rate is worse.
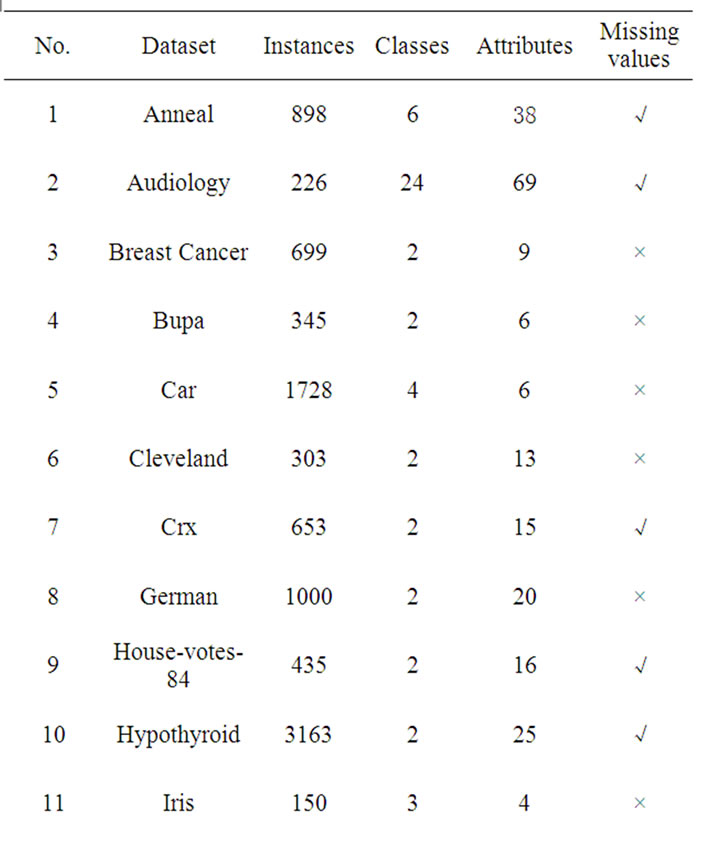
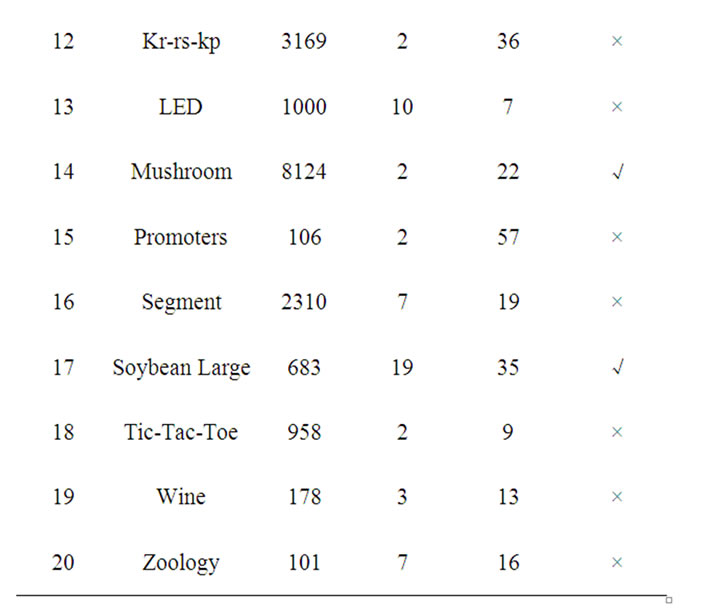
Table 1. Dataset used in the experiments.
5. Conclusions
GTAN and BAN classifiers are unstable, by setting different parameters, we can form a number of different TAN and BAN classifiers. In this paper, multiple TAN classifiers are combined by a combination method called Boosting-MultiTAN that is compared with the BoostingBAN classifier which is boosting based on BAN combination. Finally, experimental results show that the Boosting-BAN has higher classification accuracy on most data sets.
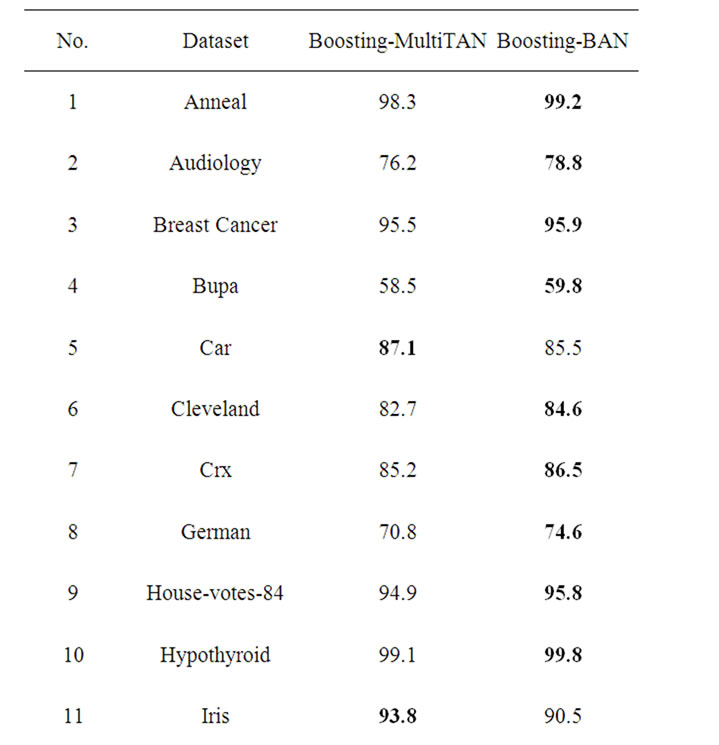
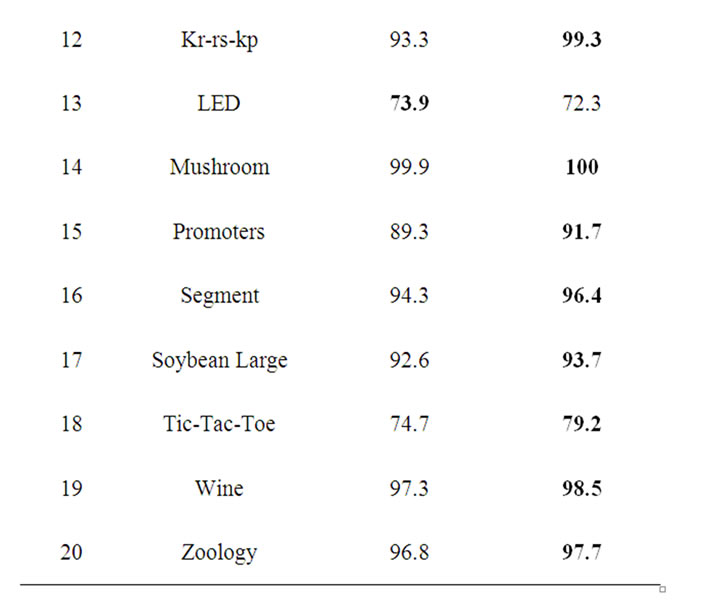
Table 2. Experimental results.
When implementing Boosting classifiers, we were able to calculate the value of c directly given our prior knowledge. Of course, in a real situation we would be very unlikely to know the level of class noise in advance. It remains to be seen how difficult it would prove to estimate c in practice.
6. References
[1] Y. Freund and R. E. Schapire, “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting,” Computational Learning Theory: 2nd European Conference (EuroCOLT’95), Barcelona, 13-15 March 1995, pp. 23-37.
[2] R. E. Schapire, Y. Freund, Y. Bartlett, et al., “Boosting the Margin: A New Explanation for the Effectiveness of Voting Methods,” In: D. H. Fisher, Ed., Proceedings of the 14th International Conference on Machine Learning, Morgan Kaufmann Publishers, San Francisco, 1997, pp. 322-330.
[3] Y. Freund, “Boosting a Weak Learning Algorithm by Majority,” Information and Computation, Vol. 121, No. 2, 1995, pp. 256-285.
[4] J. R. Quinlan, “Bagging, Boosting, and C4.5,” In: R. BenEliyahu, Ed., Proceedings of the 13th National Conference on Artificial Intelligence, Portland, 4-8 August 1996, pp. 725-730.
[5] R. E. Schapire, “The Strength of Weak Learnability,” Machine Learning, Vol. 5, No. 2, 1990, pp. 197-227.
[6] N. Friedman, D. Geiger and M. Goldszmidt, “Bayesian Network Classifiers,” Machine Learning, Vol. 29, No. 2-3, 1997, pp. 131-163.
[7] J. Cheng and R. Greiner, “Comparing Bayesian Network Classifiers,” In: K. B. Laskey and H. Prade, Ed., Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence, Morgan Kaufmann Publishers, San Francisco, 15 October 1999, pp. 101-108.
[8] J. Cheng, D. A. Bell and W. Liu, “An Algorithm for Bayesian Belief Network Construction from Data,” In: Proceedings of Conference on Artificial Intelligence and Statistics, Lauderdale, January 1997, pp. 83-90.
[9] H. B. Shi, H. K. Huang and Z. H. Wang, “BoostingBased TAN Combination Classifier,” Journal of Computer Research and Development, Vol. 41, No. 2, 2004, pp. 340-345.
[10] UCI Machine Learning Repository. http://www.ics.uci. edu/~mlearn/ML.Repository.html
[11] Y. Freund and R. E. Schapire, “Experiments with a New Boosting Algorithm,” In: L. Saitta, Ed., Proceedings of the 13th International Conference on Machine Learning, Bari, 3-6 July 1996, pp. 148-156.
[12] X. W. Sun, “Augmented BAN Classifier,” Proceedings of International Conference on Computational Intelligence and Software Engineering, Wuhan, 11-13 December 2009.