Journal of Data Analysis and Information Processing
Vol.03 No.04(2015), Article ID:61363,5 pages
10.4236/jdaip.2015.34016
A Proposed Method for Choice of Sample Size without Pre-Defining Error
Loc Nguyen1, Hang Ho2
1Huong Duong Company, Ho Chi Minh, Vietnam
2Vinh Long General Hospital, Vinh Long, Vietnam

Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).


Received 28 October 2015; accepted 20 November 2015; published 23 November 2015

ABSTRACT
Sample size is very important in statistical research because it is not too small or too large. Given significant level α, the sample size is calculated based on the z-value and pre-defined error. Such error is defined based on the previous experiment or other study or it can be determined subjectively by specialist, which may cause incorrect estimation. Therefore, this research pro- poses an objective method to estimate the sample size without pre-defining the error. Given an available sample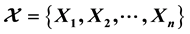 , the error is calculated via the iterative process in which sample X is re-sampled many times. Moreover, after the sample size is estimated completely, it can be used to collect a new sample in order to estimate new sample size and so on.
, the error is calculated via the iterative process in which sample X is re-sampled many times. Moreover, after the sample size is estimated completely, it can be used to collect a new sample in order to estimate new sample size and so on.
Keywords:
Sample Size, Choice of Sample Size, Pre-Defined Error

1. Introduction
Given a sample of size n,
 from a normal distribution with theoretical unknown mean μ and known variance σ2, it implies that the sample mean
from a normal distribution with theoretical unknown mean μ and known variance σ2, it implies that the sample mean
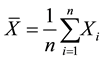
is also normally distributed with mean μ and known variance σ2/n. Given a confident level 100(1 − α) percentage, the confident interval [1] [2] of theoretical unknown mean μ is:

where Zα/2 which is the z-value at significant level α is the upper 100α/2 percentage point of standard normal distribution. Let E is the absolute deviation between the sample mean
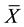 and the theoretical mean μ, we have:
and the theoretical mean μ, we have:
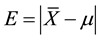
The value E is also called estimated error, which is always less than or equal to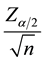 .
.
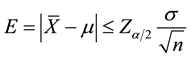
There is a requirement that how to estimate the sample size n so as to the deviation
 is less than or equal to the pre-defined error E at given a 100(1 − α) % confident level. This is the choice of sample size. Following formula [1] indicates that
is less than or equal to the pre-defined error E at given a 100(1 − α) % confident level. This is the choice of sample size. Following formula [1] indicates that
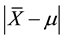 does not exceed the error E if the sample size n is:
does not exceed the error E if the sample size n is:
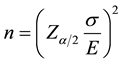
(Readers can refer to [1] with regard to pages 252 - 253, 293 - 297, 304 - 305, 309 - 310, 312 - 314, 331 - 333, 344 - 345, 359, 364 - 365 for more details about choice of sample size). There is an issued problem that how to define the error E. Normally, E is defined based on the previous experiment or other study or it can be determined subjectively by specialist. Therefore, this research proposes an objective method to calculate the error E given an available sample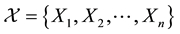 . This is an iterative method which is described in next section.
. This is an iterative method which is described in next section.
2. Proposed Method to Choose Sample Size
The formula of choice of sample size is re-written:
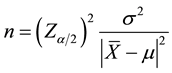
The z-value Zα/2 is totally determined and so what we need to do is to calculate the variance σ2 and the error
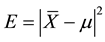 . We will use a novel method when n is considered as a variable. The formula of sample size above
. We will use a novel method when n is considered as a variable. The formula of sample size above
is reduced as below:

where
 is sample mean and h(i) is proportional to sample size n and the notation
is sample mean and h(i) is proportional to sample size n and the notation
 denotes the proportion.
denotes the proportion.
Fixing variance σ(i)2 and mean μ(i), we have:

Suppose there is an available
 and given m iteration times, for example, m = 100 and a new sample
and given m iteration times, for example, m = 100 and a new sample
 containing n elements is sampled randomly from
containing n elements is sampled randomly from
 at the ith iteration. This is a form of bootstrap sampling with replacement.
at the ith iteration. This is a form of bootstrap sampling with replacement.

Note that Yij (s) are taken randomly from with replacement.
Let M(i) is the sample mean of , we have:
, we have:

where,

We assume that the sample mean M(i) is approximated to the sample mean
 and is random variable with theoretical mean μ. We have:
and is random variable with theoretical mean μ. We have:



Note that
 is approximated by M(i).
is approximated by M(i).
Summing accumulatively
 through m iterations corresponding to m sample
through m iterations corresponding to m sample
 (s), we have:
(s), we have:

Dividing both sides of formula above by , we have:
, we have:

Let

It is easy to infer that Δ2 is sample variance of the set of sample means M(i) (s).

Therefore, the formula for calculating variable h with fixed variance σ2 is:

Because the theoretical variance σ2 is not defined, it is approximated by sample variance s2 of sample .
.

where
 is sample mean.
is sample mean.
Substituting s2 into the formula for calculating variable h, we have:

Finally, the sample size n is calculated by following formula:

It is necessary to have an example for illustrating the proposed formula to calculate sample size without pre-defined error. Given 10-element sample
 = {X1 = 8.05, X2 = 9.60, X3 = 2.98, X4 = −20.26, X5 = −6.52, X6 = −10.85, X7 = 8.14, X8 = 26.48, X9 = 10.57, X10 = 2.26}, we will estimate the optimal size of the next sample based on
= {X1 = 8.05, X2 = 9.60, X3 = 2.98, X4 = −20.26, X5 = −6.52, X6 = −10.85, X7 = 8.14, X8 = 26.48, X9 = 10.57, X10 = 2.26}, we will estimate the optimal size of the next sample based on . Suppose there are 10 iteration times (m = 10), we have 10 new sample
. Suppose there are 10 iteration times (m = 10), we have 10 new sample
 (s) is sampled randomly from
(s) is sampled randomly from
 with replacement. Table 1 shows such 10 new sample
with replacement. Table 1 shows such 10 new sample
 (s) and their means M(i) (s).
(s) and their means M(i) (s).
The sample variance Δ2 of sample means M(i) (s) is:

The mean
 of sample
of sample
 is:
is:

The sample variance s2 of sample
 is:
is:

Given the confident level 95% (α = 0.05), it is easy to calculate the optimal sample size as follows:

According to results from many experiments, if the origin sample (previous sample ) conforms normal distribution, the optimal sample size is 4 - 5 times larger than the size of such origin sample so that it is possible to gain better experiment (testing, analysis, estimation, etc.) because the origin sample that conforms normality is itself good sample. We can implement the proposed formula of sample size choice by R language [3] so that it is convenient to do many experiments on such formula. Following is R language code for implementing the proposed formula.
) conforms normal distribution, the optimal sample size is 4 - 5 times larger than the size of such origin sample so that it is possible to gain better experiment (testing, analysis, estimation, etc.) because the origin sample that conforms normality is itself good sample. We can implement the proposed formula of sample size choice by R language [3] so that it is convenient to do many experiments on such formula. Following is R language code for implementing the proposed formula.

Table 1. Ten new samples and their means.

3. Conclusions
I invent this method when discussing with the co-author Dr. Hang Ho about choice of sample size. At that time, I make the simile that the ideology of this method is similar to the problem “hen and egg”. Regardless that hen exists before or egg exists before, you feed hen to lay new egg and incubate such egg to hatch new hen. Therefore, given an available random sample is used to estimate the sample size and such sample size is applied to collect new random sample; after that new sample size is estimated based on the new random sample and so on. Now, we analyze the formula for estimating sample size:

The variance s2 in numerator expresses the coherent variation of data and the value Δ2 in denominator specifies the variation of disturbed data (data is disturbed for many times). It means that Δ2 specifies the variation of change (or variation of variation). The smaller the value Δ2 is, the more precise the variance s2 is and so the sample size is much proportional to s2. In other words, the small Δ2 makes an increase in sample size. Ratio

approaches 1 when m approaches +∞ and so, the larger the number of iterations is, the more precise the sample size is. If m is small, the sample size tendentiously increases, but the balance is established because Δ2 will increase if m is small, and as known the large Δ2 makes decrease in sample size. But why the small m makes an increase in Δ2 and otherwise? As known the number of iterations m specifies the variation of disturbed data. The larger the number m is, the much more the data is disturbed and so it is easier for the tendency that data is reverted in equilibrium, which causes the decrease in Δ2. In other words, the small m makes increase in Δ2.
Cite this paper
LocNguyen,HangHo, (2015) A Proposed Method for Choice of Sample Size without Pre-Defining Error. Journal of Data Analysis and Information Processing,03,163-167. doi: 10.4236/jdaip.2015.34016
References
- 1. Montgomery, D.C. and Runger, G.C. (2003) Applied Statistics and Probability for Engineers. 3rd Edition, John Wiley & Son, Inc., Hoboken.
- 2. Walpole, R.E., Myers, R.H., Myers, S.L. and Ye, K. (2007) Probability & Statistics for Engineers & Scientists. 9th Edition, Pearson Education, Inc.
- 3. R Development Core Team (2010) R: A Language and Environment for Statistical Computing. R Foundation for Statistical computing, Vienna, Austria. http://www.R-project.org