Journal of Computer and Communications
Vol.02 No.14(2014), Article ID:52497,7 pages
10.4236/jcc.2014.214006
Research of Collaborative Filtering Recommendation Algorithm for Short Text
Chunxu Chao1, Shouning Qu2*, Tao Du1
1School of Information Science and Engineering, University of Jinan, Jinan, China
2The Center of Information Network, University of Jinan, Jinan, China
Email: chaochunxu@126.com, *qsn@ujn.edu.cn, dt@ujn.edu.cn
Copyright © 2014 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 20 October 2014; revised 15 November 2014; accepted 18 December 2014
ABSTRACT
Short text, based on the platform of web2.0, gained rapid development in a relatively short time. Recommendation system analyzing user’s interest by short texts becomes more and more important. Collaborative filtering is one of the most promising recommendation technologies. However, the existing collaborative filtering methods don’t consider the drifting of user’s interest. This often leads to a big difference between the result of recommendation and user’s real demands. In this paper, according to the traditional collaborative filtering algorithm, a new personalized recommendation algorithm is proposed. It traced user’s interest by using Ebbinghaus Forgetting Curve. Some experiments have been done. The results demonstrated that the new algorithm could indeed make a contribution to getting rid of user’s overdue interests and discovering their real-time interests for more accurate recommendation.
Keywords:
Short Text, Personalized Recommendation, Time Weight Function

1. Introduction
Recent years, like Facebook, Twitter, short texts are very popular in the social field all over the world. One of the most prominent short texts is micro-blog in China. Depending on the advantage of brief, real-time in information sharing, spreading and acquisition, weibo gains sharp development and begins to influence people’s lives and their way of thinking. In July 2014, 34th China Internet network development state statistic report [1] given by CNNIC pointed out that, up to June 30, 2014, the scale of Chinese weibo users has reached 275 million. Micro-blog has already become one of the social networks used to broaden one’s reach and realize social interaction, especially an important tool of acquiring latest information. Users play a role as information consumers; at the same time, they are data producers, too.
With the influx of large quantities of users, weibo surged in a short time. People have lost in the ocean of microblog information already. In the fast-pace today, how to acquire the most accurate information needed by users in the shortest time, has become a hot issue nowadays.
At present, there are two main recognized way to solve the problem of information overload: information retrieval and information filtering technology. Represented by Google, Yahoo, information retrieval technology has indeed achieved great success. However, it draws on the requirement that users must be able to accurately describe their personal needs. Once users cannot describe their demands well, information search quality of it cannot be guaranteed, which often leads to search results undesirable. Information filtering technology can solve this problem very well. As an important application of information filtering, recommendation system has become an indispensable part of individualized information service form among the new generation of Web applications. Collaborative filtering algorithm (CFA) is the most efficient recommendation algorithm at present. CFA analyzes user’s interest and finds others who have the same interest with him and then integrates these similar users’ evaluation with some information and forms recommendations for him. It is quite precise on locating users’ interest. It can also filter some concepts complex and indescribable, which is obvious superior to other algorithms. However, CFA can’t make a distinction between real-time interest and overdue interest well, which results in an unsatisfactory precision. This paper gives a new algorithm, time weight algorithm (TWA), which can tell user’s real-time interest well and improve the precision of recommendation.
The rest of paper is organized as follows: Section 2 presents the research status home and aboard. Section 3 gives the preliminary concepts, regarding forgetting curve and the details of TWA. Section 4 analyzes the experiments results. Section 5 concludes and gives the pointer to the future work.
2. Related Work
As a new thing, weibo filtering has not caused widely concern relatively. Western scholar Ernesto [2] combined with the effectiveness of micro-blog, found and ranked weibo topics, according this to recommend to users. Sriram [3] firstly divided weibo into several parts, such as news, transaction, private information and so on, then studied with different classes and achieved good results. Golbeck [4] presented some problems and challenges on weibo filtering. He demonstrated that some problems have been still existed among weibo filtering nowadays. Hannon [5] recommended similar users to specific user by using CFA based on content. Research of weibo on aboard has made some achievements, but these are only for western texts, most of them do not apply for Chinese texts. Domestic studies are still in its infancy. Wang Lin [6] proposed a filtering method faced with weibo, which is effective on noise discrimination and content similarity detection. Although the method could effectively purify micro-blog data, it needed constantly to gain new rules and characteristics to face the change of variety and feature about noise weibo. Shen Jing [7] in virtue of non-structured DM platform designed an efficient distributed text filtering algorithm, which acquired a good filtering result, but low efficiency. In addition, Shao Jianshuang [8] constructed a text filtering model based on concept lattice and gave its usage. For tracing and capturing the changing of users’ interest, Xing Chunxiao [9] proposed data weight based on time-window and item-similar. They used linear function because they believe that the changing of user’s interest follows the law of linear forgotten. Zhang [10] used exponential function as time function to solve the decline of recommendation quality with the changing of users’ interest. These researches all made contribution to weibo filtering, but not very satisfactory.
Under this background, this paper proposed TWA based on Ebbinghaus Forgetting Curve [11] to further optimize CFA and improve the precision of recommendation.
3. The Design of TWA Based on Forgetting Curve
3.1. Forgetting Curve
German psychologist H. Ebbinghaus studied carefully and systematically about the phenomena of memory loss and made a forgetting curve using the testing results from the experiments about featureless syllables and letters. This is the famous Ebbinghaus Forgetting Curve, shown in Figure 1.

Figure 1. Ebbinghaus forgetting curve.
Among Figure 1, vertical coordinates of the curve representative the memorial quantity of a learner, while x-coordinates show the time after learning. As is shown by Figure 1, man forgets things not a simple process of gradual oblivion, but presents such a trend that oblivion in a short period of time after memorization was relatively quick and after a long interval oblivious speed slowed.
Weibo behavior of a man is a reaction of his psychology. So changing of user’s interest on publishing, transmitting and commenting a weibo also follows this forgetting law. As the shape of forgetting curve much mat- ches exponential function, we use exponential function to simulate user’s interest changing over time. Yu Hong [12] took the advantage of ZGrapher [13] to fit Ebbinghaus Forgetting Curve and acquired a mathematical expression:
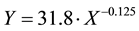 (1)
(1)
where, 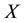 represents days after learning,
represents days after learning, 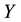 is forgotten percentage.
is forgotten percentage.
3.2. TWA Based on Forgetting Curve
According to man’s oblivious nature, we divide man’s interest into real-time interest which includes long-term interest and recent interest, and overdue interest. Then use TWA based on Forgetting Curve to better explore user’s real-time interest and get rid of his overdue interest to improve the precision of personalized recommendation. TWA formula is as follows:
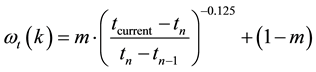 (2)
(2)
where,  represents current time,
represents current time, 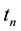 is the publish time of target weibo and
is the publish time of target weibo and  is the publish time of the weibo before target weibo under the same class
is the publish time of the weibo before target weibo under the same class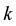 .
.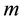 , weight factor, values between 0 and 1.
, weight factor, values between 0 and 1.
We analyze the rationality of formula (2) from three aspects.
1) User has involved frequently on the theme 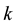 in the past, but recently does not focus on it [14] . This shows that user has been very interested in the theme
in the past, but recently does not focus on it [14] . This shows that user has been very interested in the theme 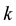 in a period of time in the past, but now he is not interested in the theme. In the algorithm, there are many weibo under
in a period of time in the past, but now he is not interested in the theme. In the algorithm, there are many weibo under 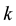 and time intervals between them are very short. For they published in the past, all of them have long time intervals with the current time, that is to say, denominator
and time intervals between them are very short. For they published in the past, all of them have long time intervals with the current time, that is to say, denominator
 very small, but numerator
very small, but numerator 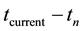 very big, so
very big, so 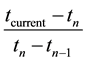 very big and
very big and  very small. This
very small. This
situation describes user’s interest rightly.
2) User has involved frequently on the theme k in the past and recently. This shows that user has been interested in  and
and  is user’s long-term interest. In the algorithm, time intervals between weibo under theme
is user’s long-term interest. In the algorithm, time intervals between weibo under theme  are relatively long,so denominator
are relatively long,so denominator  very big,
very big,  very big.This situation describes user’s interest rightly.
very big.This situation describes user’s interest rightly.
3) User has involved frequently on the theme  recently. This shows that theme
recently. This shows that theme  is user’s recent interest. In the algorithm, there are many weibo under
is user’s recent interest. In the algorithm, there are many weibo under , and time intervals between each other are very short, but they
, and time intervals between each other are very short, but they
all published in the recent, have short time intervals with the current time, that is to say,  would be
would be
smaller than the first situation, so  would be bigger than the
would be bigger than the  in the first situation. This situation describes user’s interest rightly, too.
in the first situation. This situation describes user’s interest rightly, too.
3.3. Recommendation Algorithm and Process Description
The algorithm of improved ITC [15] is the improvement of TF-IDF. It includes two parameters that the Infor-
mation of the term in a category  and the weight of position distribution
and the weight of position distribution . It has already
. It has already
been demonstrated that it is very useful and efficient on short text classification. In our algorithm, it is used to acquire the weight of each item preliminarily. The process description of our new algorithm is given as follows:

The flow chart of this algorithm is given in Figure 2.
4. Experimental Evaluation
4.1. Data Set
Data set in this paper is grasped from the open platform [16] provided by Sina Micro-blog. It mainly includes 7113 weibo which was published by 15 users in recent 3 months. Most of weibo include weibo id, user id, user name, screen name, re-tweeting id, content, weibo url, resource, picture url, audio url, video url, geographic coordinate, re-tweeting number, comment number, the number that who like it, publishing time.
For those weibo that user re-tweets or comments, we regard the previous weibo and the content of user’s comment as its real content. Then we begin to pre-process. Pre-processing covers eliminating the stop list and function words, such as “haha”, “too”, “also” and so on. We treat weibo whose number of words after pre- process less than 5 as pointless weibo and wipe out it. In addition, this experiment is only for Chinese content. If weibo is completely foreign language, we will wipe it out, too. Thus, after pre-process, our data set still contains 4981 weibo. Then, we select 14 randomly from 15 users and regard their 4707 weibo which were tweeted

Figure 2. Flow chart of TWA.
by them in recent 3 months as training set. 274 weibo published by another one comes into being test set. The classification of training set and test set is shown in Table 1.
We try to manually annotate weibo of training set to tell user’s real-time interest and overdue interest. After training and calculating, we reach when m take 0.4, the result simulated by formula (2) is the most similar to the result we mark. What’s more, we depend on the statistics and set threshold. Then, we bring  into formula (2) and test on the test set.
into formula (2) and test on the test set.
4.2. Evaluation Criterion
According to TWA based on forgetting curve, we compare the weight of weibo with threshold. If the weight is greater than threshold, we set the result of weibo as 1. Otherwise set its result as −1. Then put all weibo under a theme  together and plus their values as sum, if sum > 0, we mark this theme as user’s real-time interest, if not, mark the theme as overdue interest.
together and plus their values as sum, if sum > 0, we mark this theme as user’s real-time interest, if not, mark the theme as overdue interest.
In this paper, we take Precision, Recall and MAPE as evaluation criterion.
Precision is the radio of the number of related documents which were retrieved and the number of all do- cuments which were retrieved. It measures the precision of a recommendation system. Recall is the radio of the number of related documents which were retrieved and the number of all related documents. It measures the comprehensive radio of a recommendation system. Their formulas are shown as follows:
 (3)
(3)
 (4)
(4)
where,  is the set of documents which were retrieved,
is the set of documents which were retrieved,  is the set of documents which were related with request.
is the set of documents which were related with request.
MAPE (Mean Absolute Percentage Error) measures the precision of algorithm by computing the mean absolute percentage error between predicted value and true value. The smaller the value of MAPE, the smaller the gap of predicted value and true value, which means predicting much closer to the true choice of user, the higher precision of recommendation. We make prediction score set of user  and the true score set
and the true score set , then the formula of MAPE is:
, then the formula of MAPE is:
 (5)
(5)
4.3. Experimental Result
Experiment one show the traditional difference of Precision and Recall between TWA and improved ITC. We set two classifications on this experiment. The result is shown in Table 2 and Table 3.
For a better intuitive effect, we give histograms of Table 2 and Table 3 in Figure 3 and Figure 4.

Table 1. The classification of training set and test set.
Table 2. The precision and recall of improved ITC.
Table 3. The precision and recall of TWA.
Figure 3 and Figure 4 show clearly that Precision and Recall of interest classification of user u totally goes down by using TWA. It’s because that TWA aims at separating user’s real-time interest from his overdue interest and abandons those documents of overdue interest. It leads to the decrease of numerator  of formula (3), (4), but denominator
of formula (3), (4), but denominator ,
,  of formula (3), (4) remains unchanged. Both of them make contribution to the decline of Precision and Recall. These two tradi- tional parameters going down, is the inevitable result of optimization on the basis of the original one. But on the other hand, it is more certain the necessity and importance to optimize the original algorithm.
of formula (3), (4) remains unchanged. Both of them make contribution to the decline of Precision and Recall. These two tradi- tional parameters going down, is the inevitable result of optimization on the basis of the original one. But on the other hand, it is more certain the necessity and importance to optimize the original algorithm.
Experiment two shows the difference between improved ITC and TWA at capturing user’s real-time insterest. For MAPE, we set  if
if  is the designated kind of interest by user
is the designated kind of interest by user . Otherwise,
. Otherwise, . Then use algorithm to estimate user’s interest and compare with
. Then use algorithm to estimate user’s interest and compare with . If the kind of interest corresponds to
. If the kind of interest corresponds to , we set
, we set , otherwise
, otherwise . The result of MAPE is in Table 4.
. The result of MAPE is in Table 4.
From Table 4, we can see that compared with traditional algorithm, using TWA makes the result of MAPE decline 16.6%. It also demonstrates that TWA based on collaborative filtering algorithm is obviously prefer to the traditional algorithm. TWA indeed promotes the quality of recommendation. It can be more precise to capture the change of user’s real-time interest.
5. Conclusion and Future Work
Traditional collaborative filtering algorithms haven’t consider sufficiently about the change of user’s interest.

Figure 3. The recall of two different algorithms.

Figure 4. The precision of two different algorithms.
Table 4. MAPE of using two algorithms.
This leads to a big difference between the result of recommendation and user’s real demands. Under this context, we propose the TWA based on collaborative filtering algorithm. As the experimental result suggests that TWA is obviously prefer to other traditional algorithms on the precision and it can promotes the quality of recommendation in a large extent. It can do user more effective personalized recommendation indeed. However, for the limitation of Sina Micro-blog open platform, our privilege is so low that we can only test for 15 users one time, which inevitably leads to the experimental subjects slightly single. We expect that Sina Mirco-blog open platform could open more user privilege in future. Thus we can trace and test more users in real-time. It can not only further improve the precision of personalized recommendation, but also be the highlight of our next work.
References
- (2014) China Internet Network Development State Statistic Report. China Internet Network Information Center, Beijing, 27.
- Diaz-Aviles, E., Drumond, L. and Gantner, Z. (2012) What Is Happening Right Now…That Interests Me? Online Topic Discovery and Recommendation in Twitter. Proceedings of the 21th ACM International Conference on Information and Knowledge Management, 1592-1596.
- Sriram, B., Fuhry, D. and Demir, E. (2010) Short Text Classification in Twitter to Improve Information Filtering. Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 841-842.
- Globeck, J. (2012) The Twitter Mute Button: A Web Filtering Challenge. Proceedings of the 30th International Conference on Human Factors in Computing Systems, 2755-2758.
- Hannon, J., Bennett, M. and Smyth, B. (2010) Recommending Twitter Users to Follow Using Content and Collaborative Filtering Approaches. Proceedings of the 4th ACM Conference on Recommendation Systems, 9, 199-206.
- Wang, L., Feng, S. and Xu, W.L. (2012) A Filtering Approach for Spam Discrimination and Content Similarity Double Detection for Microblog Text Stream. Computer Applications and Software, 2, 25-29.
- Shen, J. and Jiang, Q. (2011) A Distributed Short Text Filtering Algorithm. Journal of Sichuan Ordnance, 32, 151-153.
- Shao, J.S., Li, G.Y. and Zhang, J. (2011) Design of Text Filtering Model Based on Concept Lattice. Computer Engineering and Design, 32, 1047-1050.
- Xing, C.X., Gao, F.R. and Zhan, S.N. (2007) A Collaborative Filtering Recommendation Algorithm with User Interest Change. Journal of Computer Research and Development, 44, 296-301.http://dx.doi.org/10.1360/crad20070216
- Zhang, Y.C. and Liu, Y.Z. (2010) A Collaborative Filtering Algorithm Based on Time Period Partition. The Proceeding of 3rd International Symposium on Intelligent Information Technology and Security Informatics, 777-780.
- Forgetting Curve. Wikipedia. http://zh.wikipedia.org/wiki/%E9%81%97%E5%BF%98%E6%9B%B2%E7%BA%BF
- Yu, H. and Li, Z.Y. (2010) A Collaborative Filtering Recommendation Algorithm Based on Forgetting Curve. Journal of Nanjing University (Natural Science), 46, 522-523.
- Palam Software. ZGrapher-Grahping Calculator Software.
- Wang, G.X. (2013) User Interest Analysis and Personalized Information Recommendation Based on Microblog. Shanghai Jiao Tong University, Shanghai.
- Li, L.L. and Qu, S.N. (2013) Short Text Classification Based on Improved ITC. Journal of Computer and Communication, 1, 22-27. http://dx.doi.org/10.4236/jcc.2013.14004
- Sina Micro-Blog Open Platform. http://open.weibo.com/
NOTES

*Corresponding author.