Open Journal of Statistics
Vol.3 No.6(2013), Article ID:41538,5 pages DOI:10.4236/ojs.2013.36050
Distribution of the Median in Samples from the Laplace Distribution*
US Food and Drug Administration, Silver Spring, USA
Email: John.Lawrence@fda.hhs.gov
Copyright © 2013 John Lawrence. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. In accordance of the Creative Commons Attribution License all Copyrights © 2013 are reserved for SCIRP and the owner of the intellectual property John Lawrence. All Copyright © 2013 are guarded by law and by SCIRP as a guardian.
Received October 1, 2013; revised November 1, 2013; accepted November 8, 2013
Keywords: Quantile; Generalized Hypergeometric Function
ABSTRACT
The Laplace distribution is one of the oldest defined and studied distributions. In the one-parameter model (location parameter only), the sample median is the maximum likelihood estimator and is asymptotically efficient. Approximations for the variance of the sample median for small to moderate sample sizes have been studied, but no exact formula has been published. In this article, we provide an exact formula for the probability density function of the median and an exact formula for the variance of the median.
1. Introduction
Laplace is credited as first discovering the Laplace distribution in 1774 [1]. The discovery of the normal distribution, which holds a central place in many applications of statistics, predates that of the Laplace distribution. It was discovered in 1738 by de Moivre according to [2]. Gauss and Laplace were contemporaries who both made significant discoveries about the normal distribution. Keynes [3] wrote “The popularity of the normal law, with the arithmetic mean and the method of least squares as its corollaries, has been very largely due to its overwhelming advantages, in comparison with all other laws of error, for the purposes of mathematical development and manipulation... So powerful a hold indeed did the normal law obtain on the minds of statisticians, that until quite recent times only a few pioneers have seriously considered the possibility of preferring in certain circumstances other means to the arithmetic and other laws of error to the normal. Laplace’s earlier memoir fell, therefore, out of remembrance.” Over the past 100 years, the Laplace distribution has enjoyed the resurgence in many applications such as economics, engineering and finance [4]. The reader is also referred to this book for a history of the Laplace distribution, its important properties and generalizations.
Let 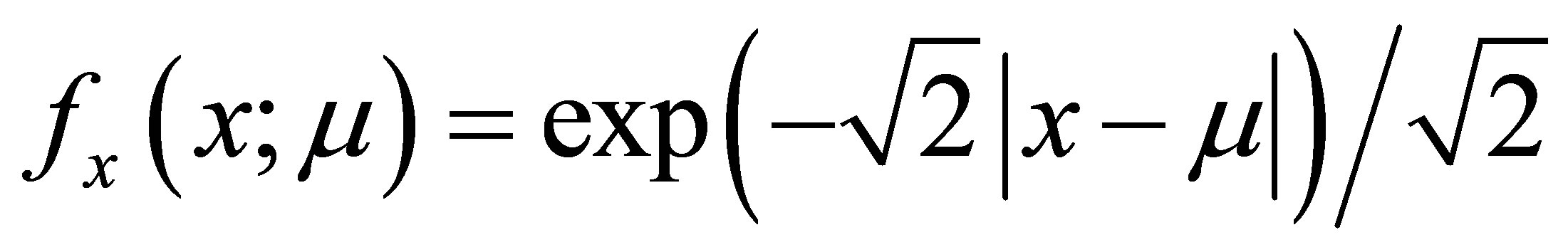 denote the probability density function of a one-parameter Laplace distribution with variance 1. It is well known that from a sample of odd size 2n + 1 where n is any positive integer, the sample median,
denote the probability density function of a one-parameter Laplace distribution with variance 1. It is well known that from a sample of odd size 2n + 1 where n is any positive integer, the sample median, 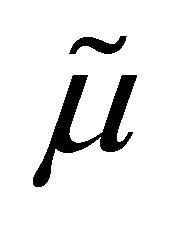 , is the maximum likelihood estimate of μ. Moreover, although the derivative does not exist at μ, the Cramer-Rao lower bound for the mean squared error of estimation of μ exists and is
, is the maximum likelihood estimate of μ. Moreover, although the derivative does not exist at μ, the Cramer-Rao lower bound for the mean squared error of estimation of μ exists and is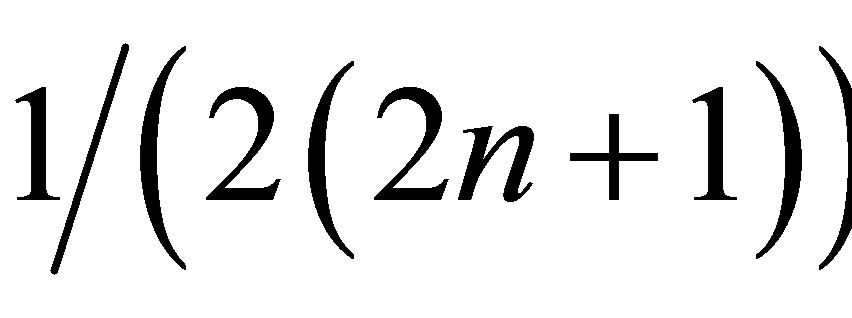 .
.
Also, we have 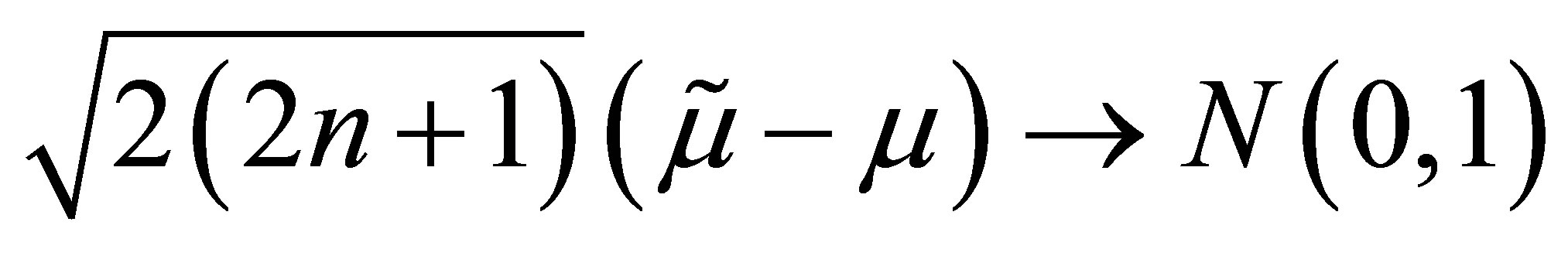 which implies the median is an efficient estimator in the asymptotic sense. However,
which implies the median is an efficient estimator in the asymptotic sense. However, 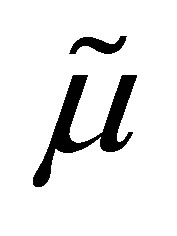 is not a sufficient statistic and there are more efficient estimators for small samples, for example the average of the middle three observations can be more efficient. Finally, the sample mean is also asymptotically normal and asymptotically the ratio of the variance of the mean to the median is 2.
is not a sufficient statistic and there are more efficient estimators for small samples, for example the average of the middle three observations can be more efficient. Finally, the sample mean is also asymptotically normal and asymptotically the ratio of the variance of the mean to the median is 2.
Previously, [5] investigated approximations to the variance of  for small sample sizes. They confirmed that although the variance converges to the Cramer-Rao lower bound, it does so at a slow rate. Consequently, even if the normal approximation was valid for small sample sizes, hypothesis tests and confidence intervals would not have the correct size if the asymptotic variance was used. The former provided the bounds for the ratio of the variance to the Cramer-Rao lower bound as follows:
for small sample sizes. They confirmed that although the variance converges to the Cramer-Rao lower bound, it does so at a slow rate. Consequently, even if the normal approximation was valid for small sample sizes, hypothesis tests and confidence intervals would not have the correct size if the asymptotic variance was used. The former provided the bounds for the ratio of the variance to the Cramer-Rao lower bound as follows:

where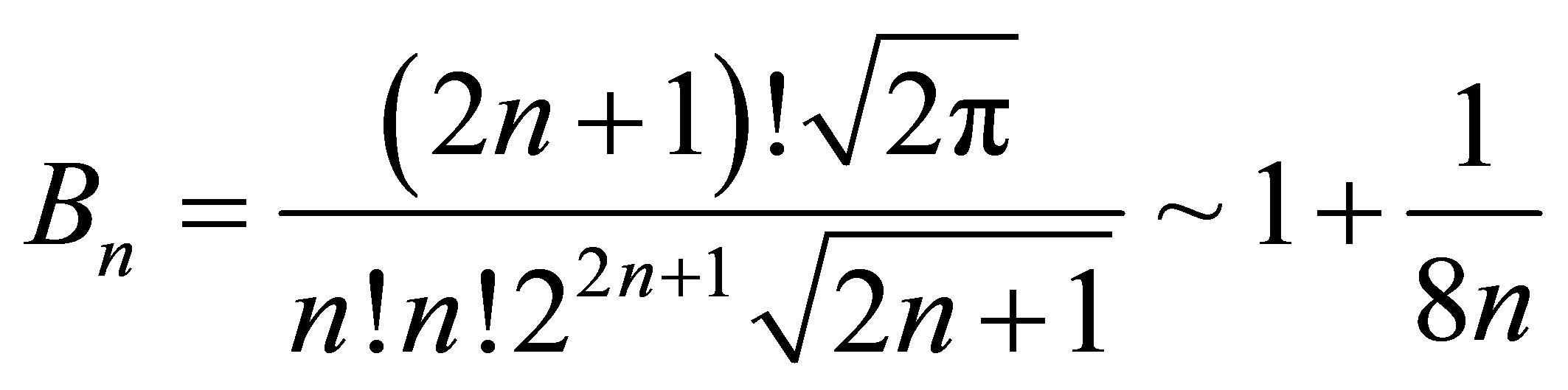 . For example, if
. For example, if
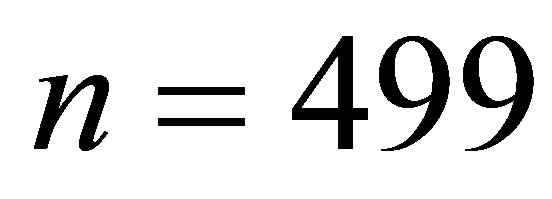 and the sample size were 999, the upper bound would be approximately 1.513. This suffices for their purpose, which was mainly to show that this ratio was less than 2, which in turn implies the median is a more efficient estimator than the sample mean. However, it seems like an inadequate upper bound since we know the ratio converges to 1. [6] attempted to tabulate the approximate variance for
and the sample size were 999, the upper bound would be approximately 1.513. This suffices for their purpose, which was mainly to show that this ratio was less than 2, which in turn implies the median is a more efficient estimator than the sample mean. However, it seems like an inadequate upper bound since we know the ratio converges to 1. [6] attempted to tabulate the approximate variance for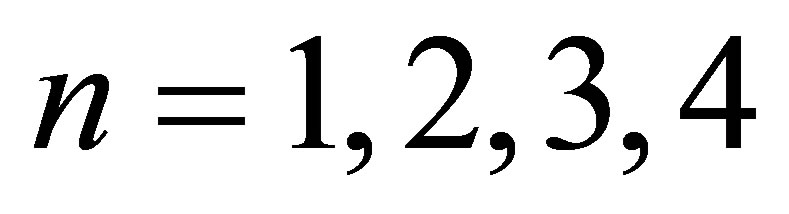 , and 8. We found that in general his approximations were close to the true values (to two digits), but were not correct in two out of these five cases (see Section 3).
, and 8. We found that in general his approximations were close to the true values (to two digits), but were not correct in two out of these five cases (see Section 3).
This paper makes two contributions. First, we find an explicit formula for the distribution of the median of a random sample from the Laplace distribution. Next, we find an exact formula for the variance of the sample median. These contributions are important because the median is the essential estimate of location for the Laplace distribution in the same way that the mean is the essential estimate of location for the normal distribution.
2. Exact Distribution of Sample Median
Without loss of generality, we will consider the case where μ = 0. The probability the median is less than x is the probability that at least n + 1 values in the sample are less than x. The distribution of the median is symmetric about 0, so it suffices to consider values of x < 0. Then, we have

In the Appendix, we show by mathematical induction that the density for x < 0 is
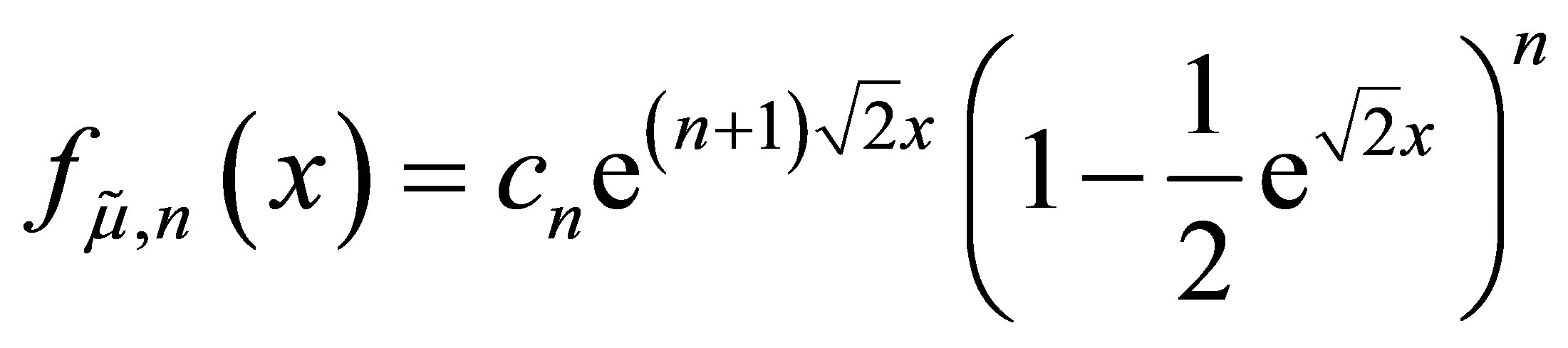
where the constants are
 .
.
Hence,  has a Beta distribution truncated on the interval
has a Beta distribution truncated on the interval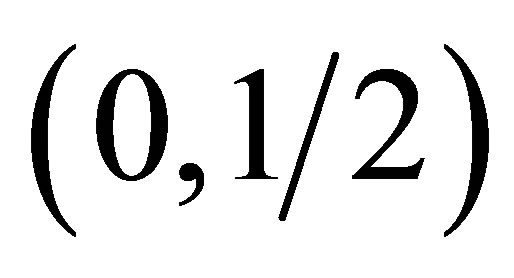 .
.
The characteristic function is

and the moment generating function is
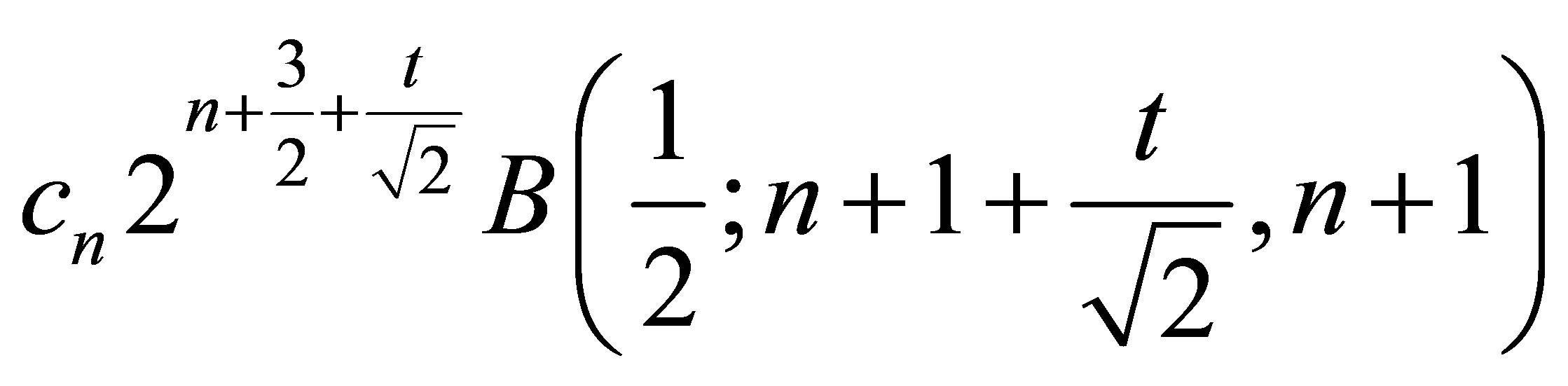 .
.
In both cases, the formulas involve the incomplete beta function
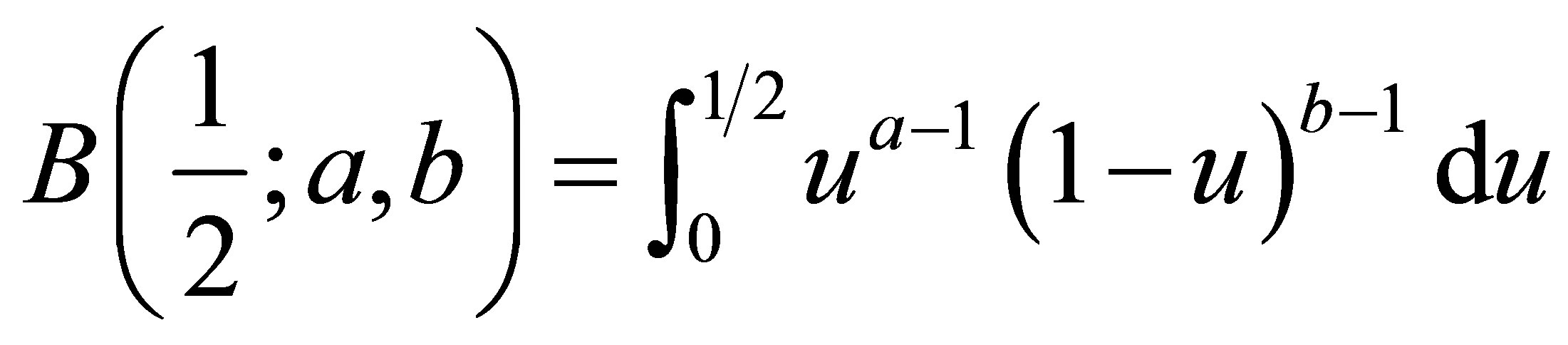 .
.
3. Variance of the Median
The variance can be calculated exactly using the Binomial expansion as
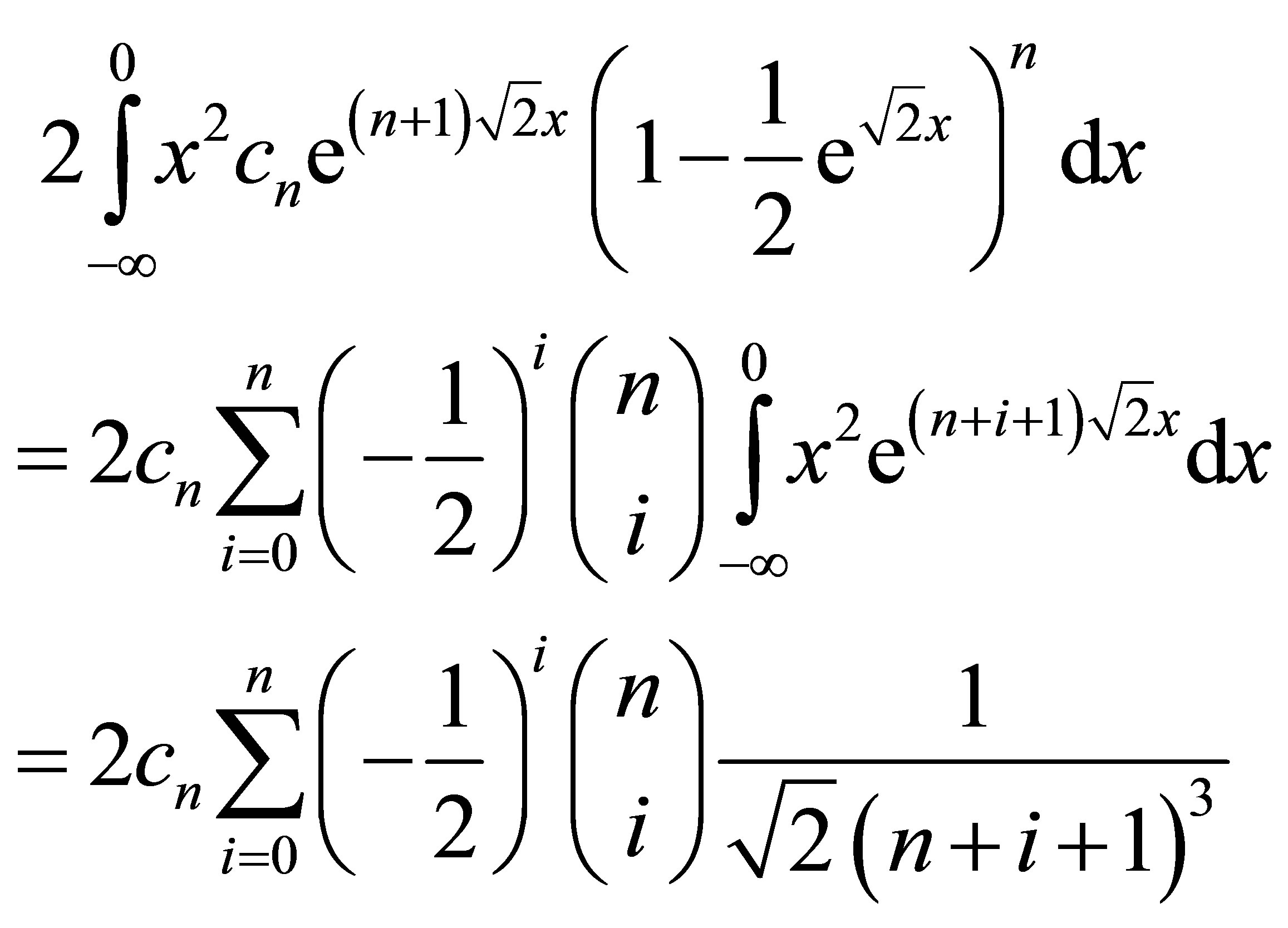
This variance also evaluates to
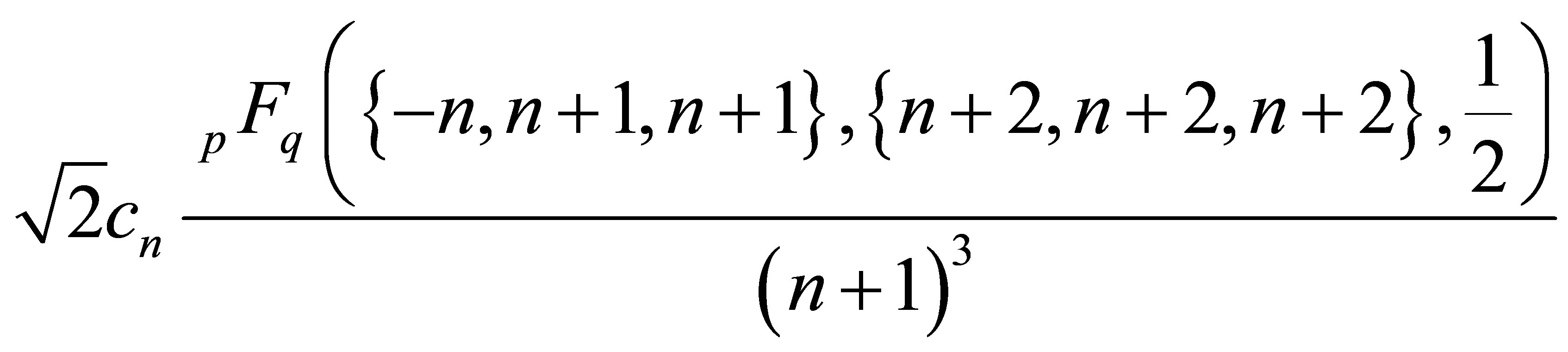
where 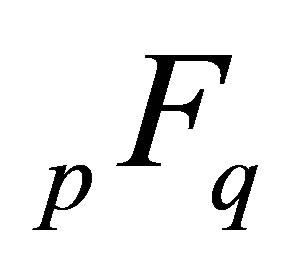 is the generalized Hypergeometric function.
is the generalized Hypergeometric function.
For , and 8, the ratios of the variance of the median to the variance of the mean (rounded to 6 digits) are 0.958333, 0.877951, 0.824767, 0.787808, and 0.708761. In comparison to the approximations listed in the bottom row of Siddiqui, these are close in all cases. In the case of n = 3, (corresponding to a sample size of N = 7 in his notation) he gives the approximate value of 0.81, but it should be 0.82 rounded to 2 digits. Also, in the case of n = 4, he gives the approximation 0.78, while it should be 0.79.
, and 8, the ratios of the variance of the median to the variance of the mean (rounded to 6 digits) are 0.958333, 0.877951, 0.824767, 0.787808, and 0.708761. In comparison to the approximations listed in the bottom row of Siddiqui, these are close in all cases. In the case of n = 3, (corresponding to a sample size of N = 7 in his notation) he gives the approximate value of 0.81, but it should be 0.82 rounded to 2 digits. Also, in the case of n = 4, he gives the approximation 0.78, while it should be 0.79.
As a further example, consider the case n = 499, corresponding to a sample size of 999. This would be a rather large dataset by most standards and one might think the asymptotic variance would be accurate. However, the ratio of the actual variance to the asymptotic value is 1.05122, or about 5% larger than the CramerRao lower bound. Although not very close to 1, it is substantially closer than the upper bound of 1.513 provided by the Chu and Hotelling approximation (see Section 1).
For very large values of n, it will still not be possible to calculate the variance exactly using the formula at the beginning of this Section. One way to estimate the ratio of the true variance compared to the asymptotic variance is

where Z is standard normal with distribution function 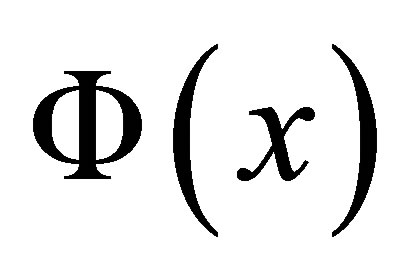 and density function
and density function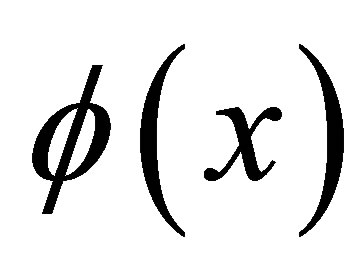 . The numerator can be estimated by Monte Carlo simulation or the integral in the second to the last line can be estimated by numerical integration such as the Riemann sum
. The numerator can be estimated by Monte Carlo simulation or the integral in the second to the last line can be estimated by numerical integration such as the Riemann sum

where  denotes the integrand and N is a large integer.
denotes the integrand and N is a large integer.
It is also possible to sample values having the density 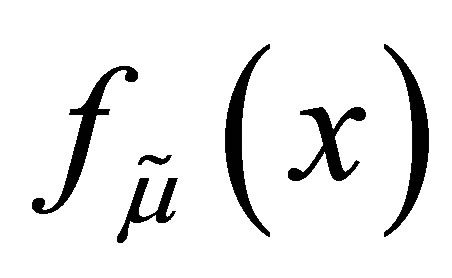 by using acceptance-rejection sampling. To do this, one needs a candidate distribution with density
by using acceptance-rejection sampling. To do this, one needs a candidate distribution with density
 such that
such that 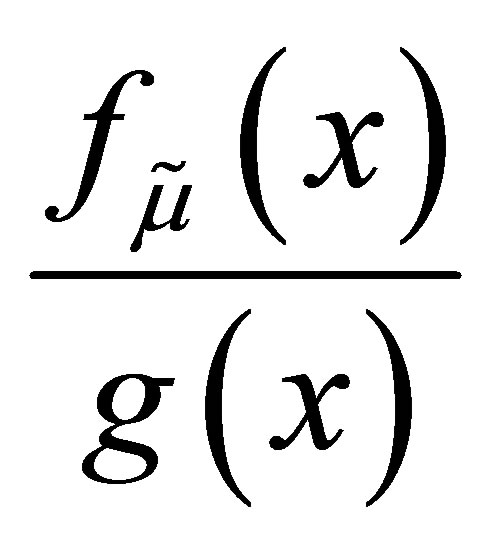 is bounded by a fixed upper bound M. In addition, it is best if M is close to 1 since the proportion of candidate values that will be accepted is
is bounded by a fixed upper bound M. In addition, it is best if M is close to 1 since the proportion of candidate values that will be accepted is . The Laplace distribution with variance 2 is a very good candidate distribution to sample from. Note that the ratio
. The Laplace distribution with variance 2 is a very good candidate distribution to sample from. Note that the ratio
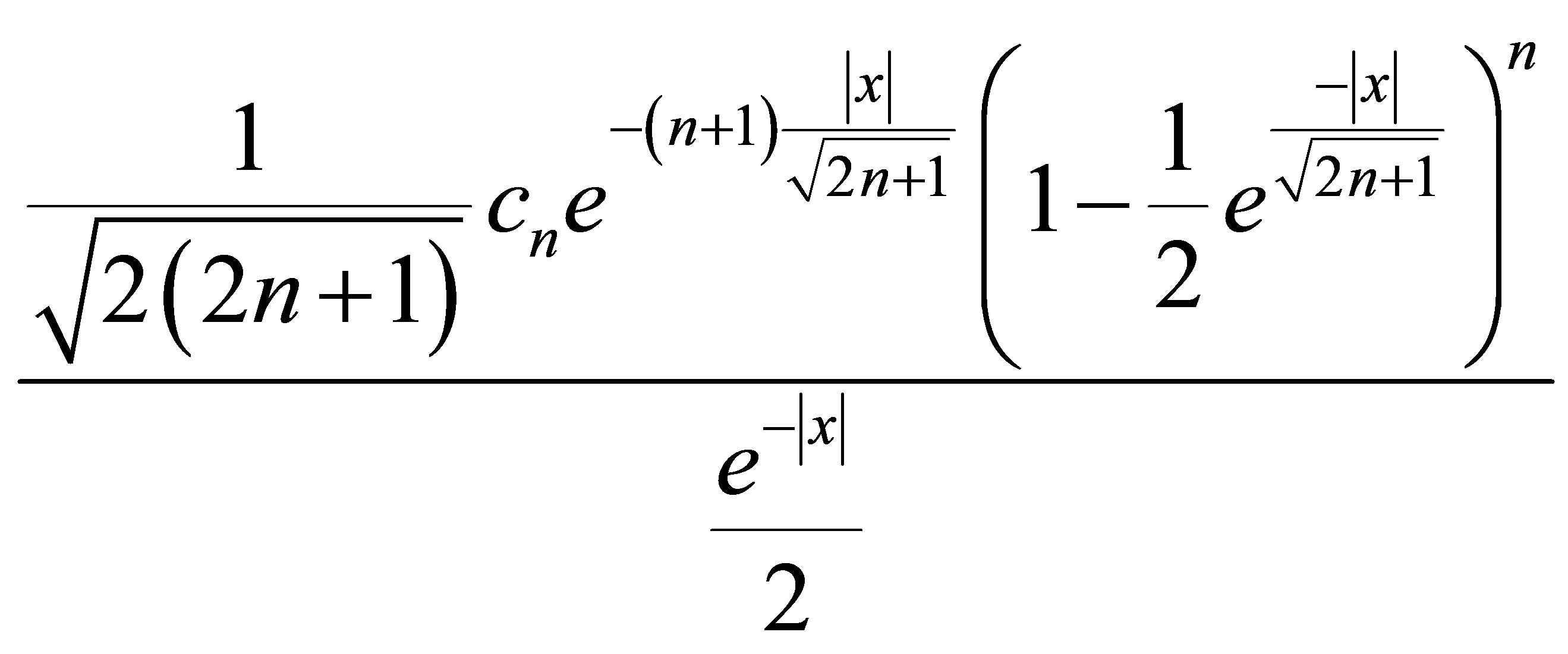
attains its maximum at
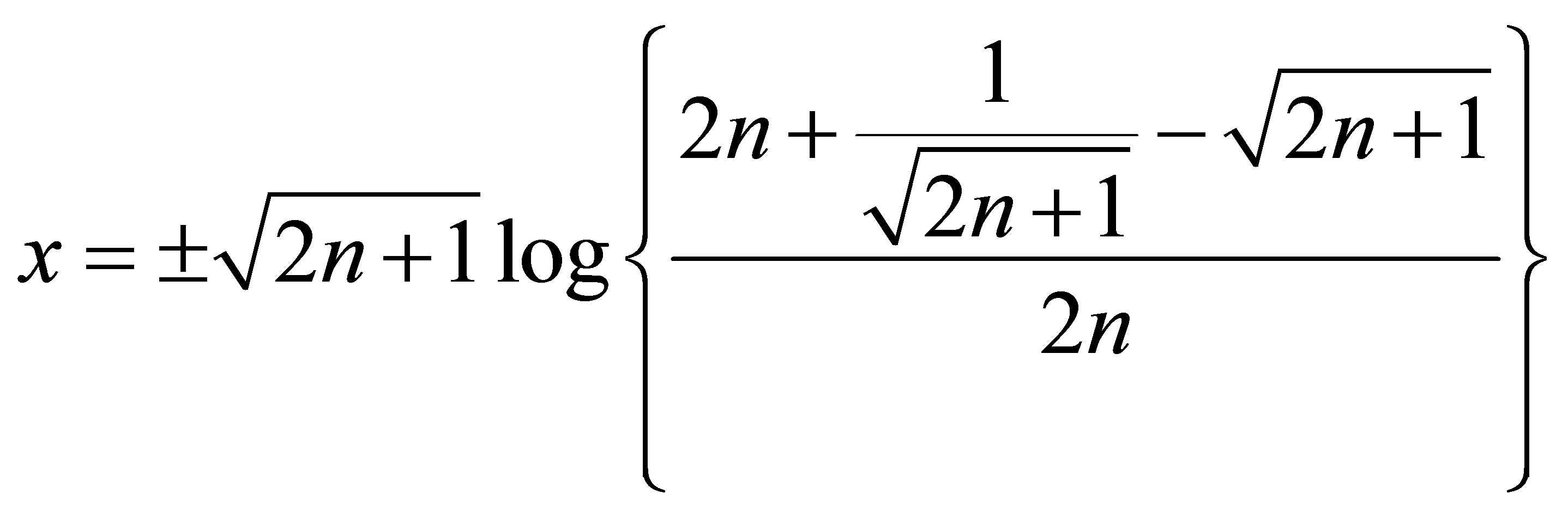
and that maximum is
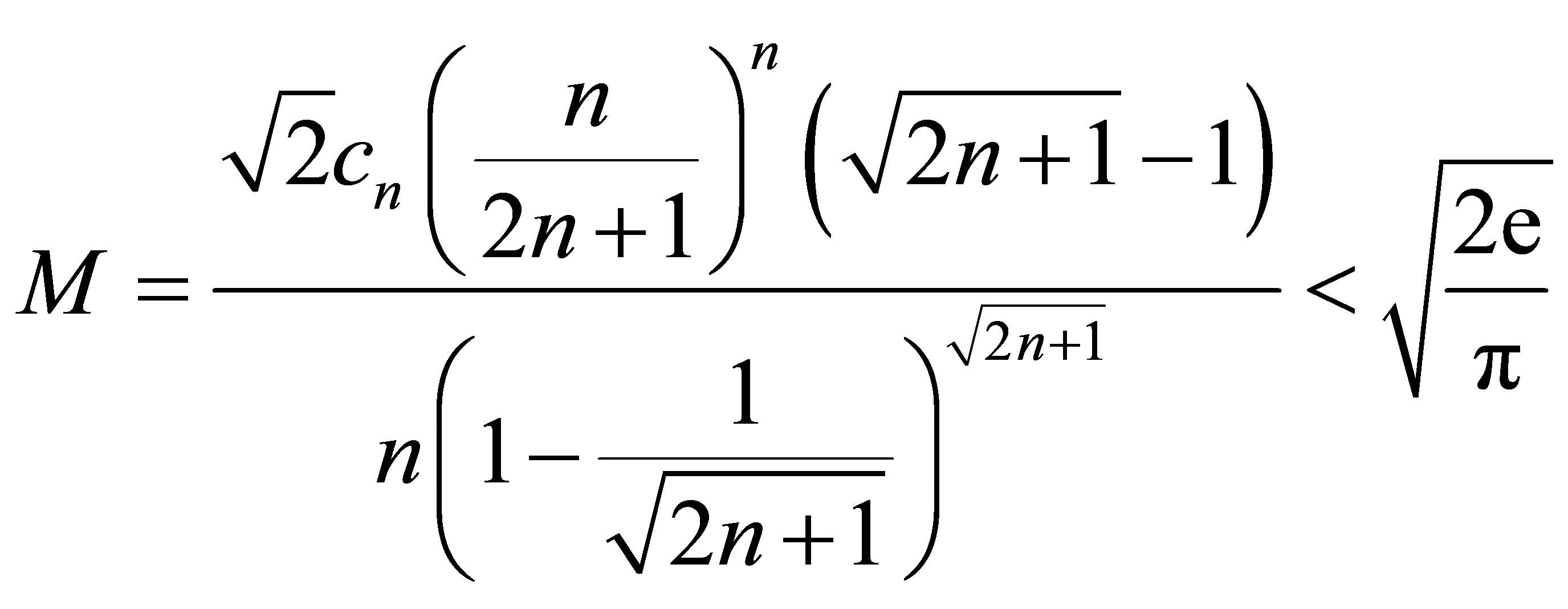 .
.
4. Conjecture about the Rate of Convergence
Start with values of n that were the closest integers to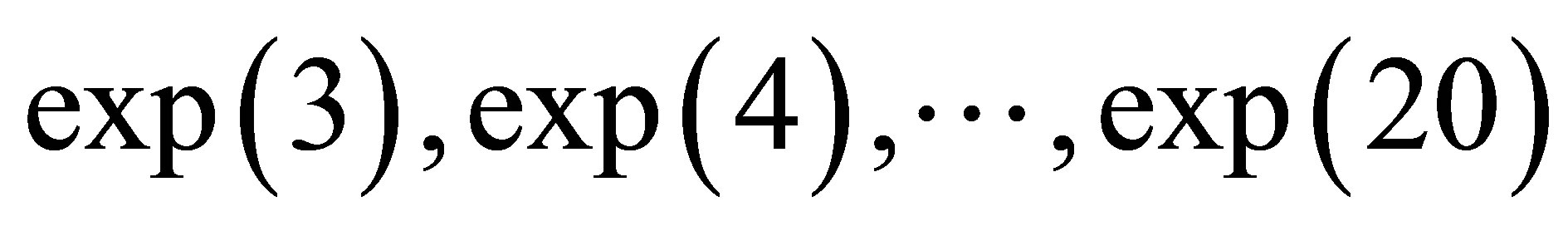 .
.
For each of those values of n, calculate the ratio given in the previous Section viathe Riemann sum described in Section 4 with 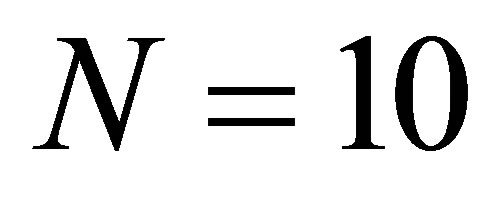 million. In Figure 1, we show the values of
million. In Figure 1, we show the values of 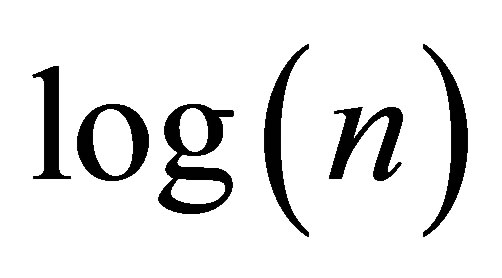 on the x-axis and log(ratio -1) on the y-axis where the ratio means the ratio of the actual variance to the asymptotic variance computed by numerical integration. We noticed that the points fell very close to the straight line defined by
on the x-axis and log(ratio -1) on the y-axis where the ratio means the ratio of the actual variance to the asymptotic variance computed by numerical integration. We noticed that the points fell very close to the straight line defined by
 .
.
Hence, at least in this range of n, the ratio is approximately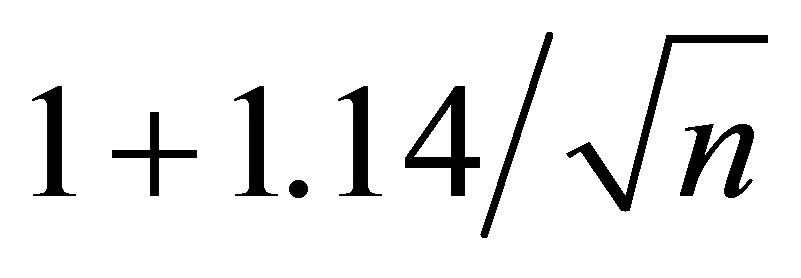 . Note, the largest n here is approximately 500 million, which corresponds to a sample size of about 1 billion.
. Note, the largest n here is approximately 500 million, which corresponds to a sample size of about 1 billion.
This leads to a conjecture about the rate of convergence of the variance. In addition, from the formula near the beginning of Section 3, this is also a conjecture about the asymptotic behavior of the Hypergeometric function for large n. Specifically,

using Stirling’s approximation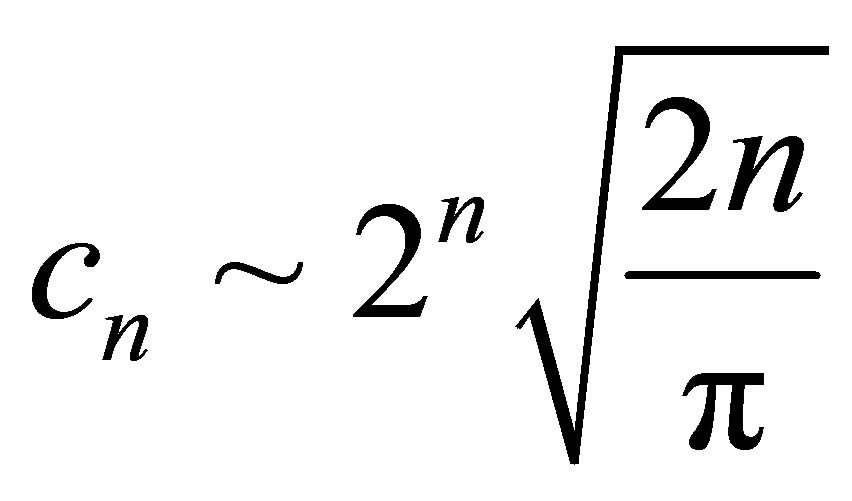 .
.
5. Summary and Conclusion
We found an exact formula for the density and the variance of the one-parameter Laplace distribution. The moment generating function and characteristic function are also derived. We also describe several methods for approximating moments or other features of the distribution by an algorithm to sample directly from the distribution. This article only deals with the case of odd sample sizes. The median is the (n + 1)th order statistic and the same
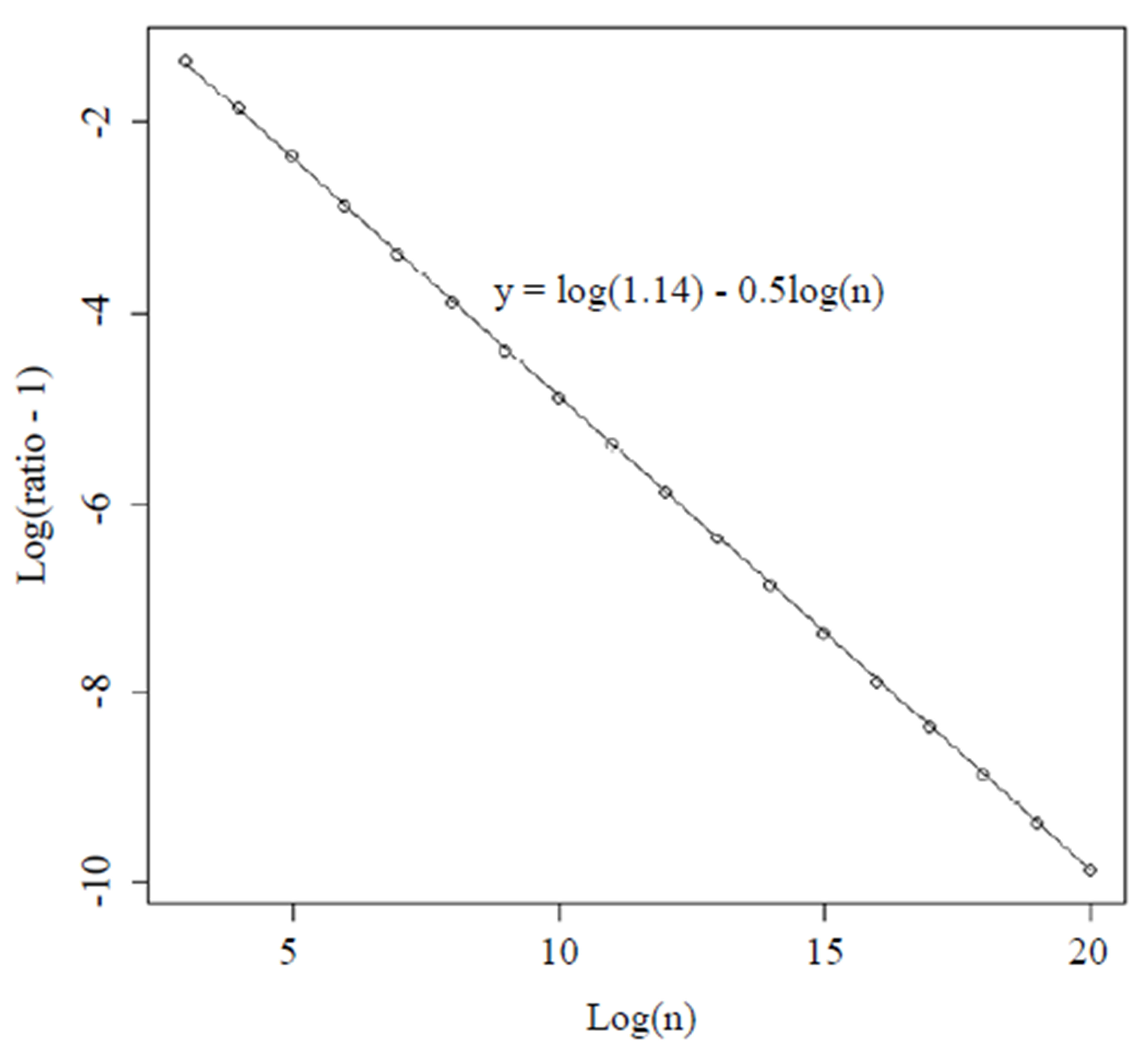
Figure 1. Transformed values of ratio (actual variance of the median divided by asymptotic variance estimated by numerical integration) for different large values of n.
approach could be used to find the distribution of any other order statistic. For even sample sizes, the median is the average of the two middle observations, which makes it slightly more complicated to analyze because the joint distribution of two order statistics is needed. However, a similar approach used here may also handle the even sample size case. Furthermore, this approach could also be useful in analyzing the variance of other estimators such as the average of the middle three or middle five and observations. And it could be helpful in finding the optimal estimator for small sample sizes. This exact variance may be useful in constructing approximate confidence intervals or hypothesis tests. But, caution should still be used in using the normal approximation. Exact tests and confidence intervals can be constructed from the exact distribution. Lastly, in the two-parameter Laplace model, not considered here, a further adjustment may be needed in such procedures due to the estimation of the scale parameter.
REFERENCES
- P. S. Laplace, “Mémoire sur la Probabilité des Causes par les Évènemens,” Mémoires de Mathematique et de Physique, Presentés à l’Académie Royale des Sciences, Par Divers Savans & Lûs Dans ses Assemblées, Tome Sixième, 1774, pp. 621-656.
- N. L. Johnson, S. Kotz and N. Balakrishnan, “Continuous Univariate Distributions,” Vol. 1, Wiley, Hoboken, 1994.
- J. M. Keynes, “The Principal Averages and the Laws of Error Which Lead to Them,” Journal of the Royal Statistical Society, Vol. 74, No. 3, 1911, pp. 322-331. http://dx.doi.org/10.2307/2340444
- S. Kotz,, T. J. Kozubowski and K. Podgorski, “The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering, and Finance (No. 183),” Springer, Berlin, 2001. http://dx.doi.org/10.1007/978-1-4612-0173-1
- J. T. Chu and & H. Hotelling, “The Moments of the Sample Median,” The Annals of Mathematical Statistics, Vol. 26, No. 4, 1955, pp. 593-606. http://dx.doi.org/10.1214/aoms/1177728419
- M. M. Siddiqui, “Approximations to the Moments of the Sample Median,” The Annals of Mathematical Statistics, Vol. 33, No. 1, 1962, pp. 157-168. http://dx.doi.org/10.1214/aoms/1177704720
Appendix
First, note that for any positive integers m and i with i < m,
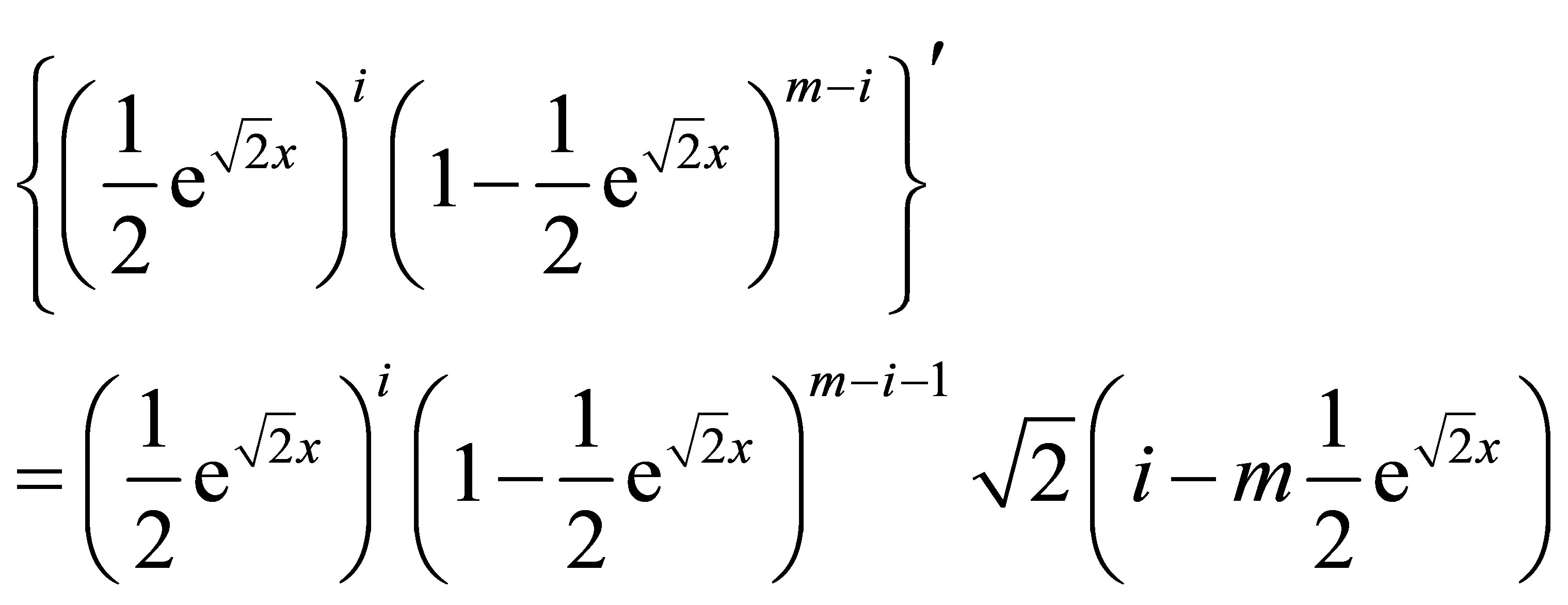
when n = 1,
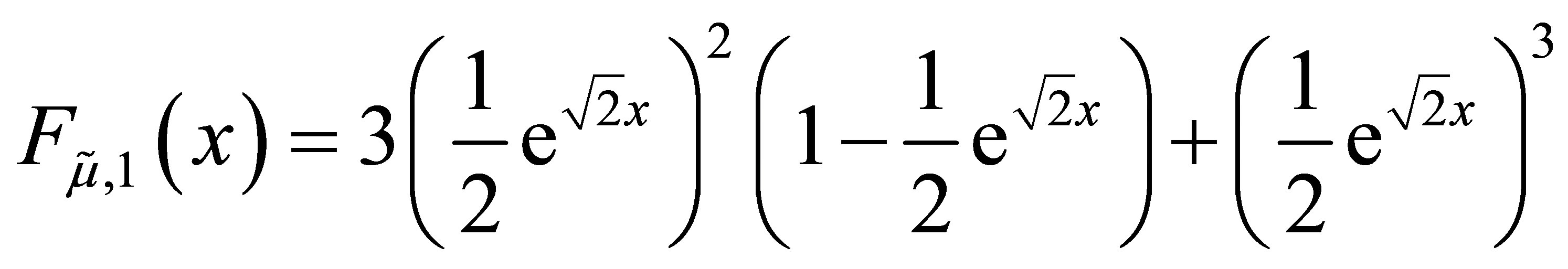
and
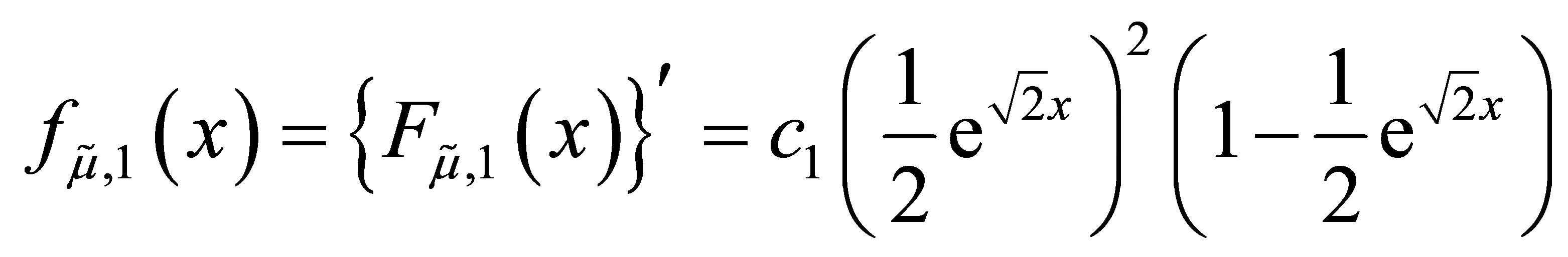
We suppose that the formula for the density is true for some positive integer n.
Consider the random sample of size  and recalculate the distribution function for the median of this random sample by conditioning on the number of values among the first 2n + 1 elements in the sample that are less than x. If the median of the entire sample is less than x, then there are three possible cases for such numbers: exactly n, exactly n + 1, or at least n + 2. We have
and recalculate the distribution function for the median of this random sample by conditioning on the number of values among the first 2n + 1 elements in the sample that are less than x. If the median of the entire sample is less than x, then there are three possible cases for such numbers: exactly n, exactly n + 1, or at least n + 2. We have
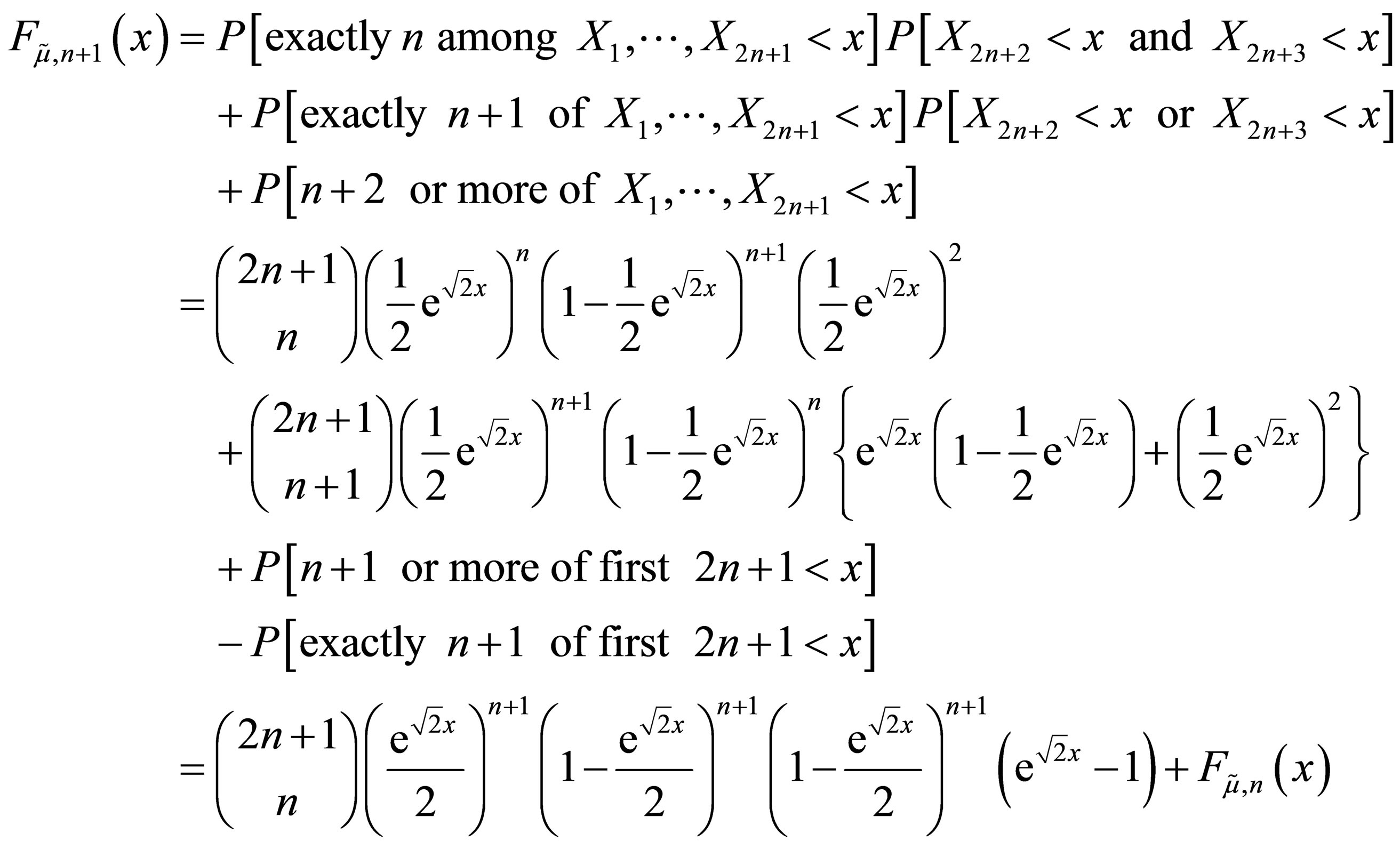
The derivative is
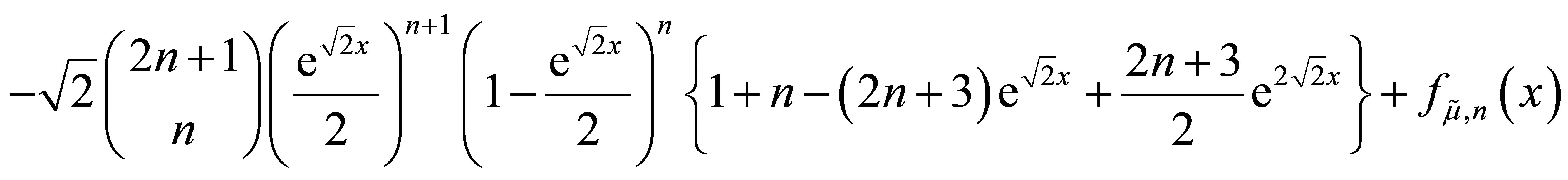
and by the induction hypothesis, this equals
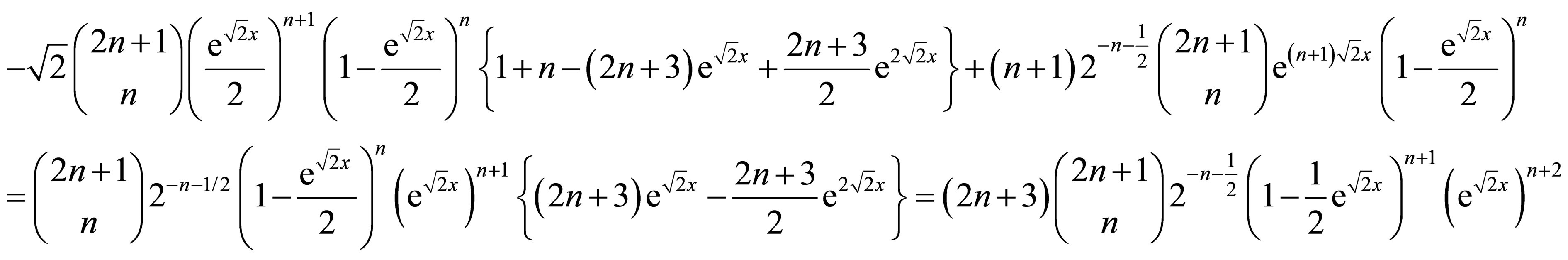
Finally, notice that

NOTES
*The views expressed are those of the authors and not necessarily those of the US Food and Drug Administration.