S. M. Yan et al. / Natural Science 3 (2011) 430-435
Copyright © 2011 SciRes. OPEN ACCESS
431
2.3. Generating Random Walk
We use the SigmaPlot [7] with different seeds to gen-
erate random sequences ranged from –1 to 1, and then
we classify a random number as 1 if it is larger than its
previous one and as –1 if it is smaller than its previous
one. Thereafter we add the classified ±1 as random walk.
2.4. Searching for Seed
To the best of our knowledge, there is no algorithm
available to find the right seed, which produces the best
fit between random walk and observed data. However,
this is not a problem with current computational tech-
nique, because we can simply search all the seeds in
searching space and compare their outcomes.
2.5. Fitting Recorded Precipitation
Hereafter, we use a more complicated random walk
model [8] to fit the recorded precipitation, which is in
decimal format. In plain words, the simplest random
walk comes from tossing of double-sided coin, while
this random walk could be regarded as tossing of dice,
which can be not only six-sided but as many as the de-
cimal data. In this way, we generate random numbers,
and add them to construct the random walk, and the fit-
ting is again to search the best seed that generates best
fit.
2.6. Comparison
For determining the best seed, we compare the least
squared errors between precipitation walk and random
walk, and between recorded precipitation and random
precipitation generated from different seeds.
3. RESULTS AND DISCUSSION
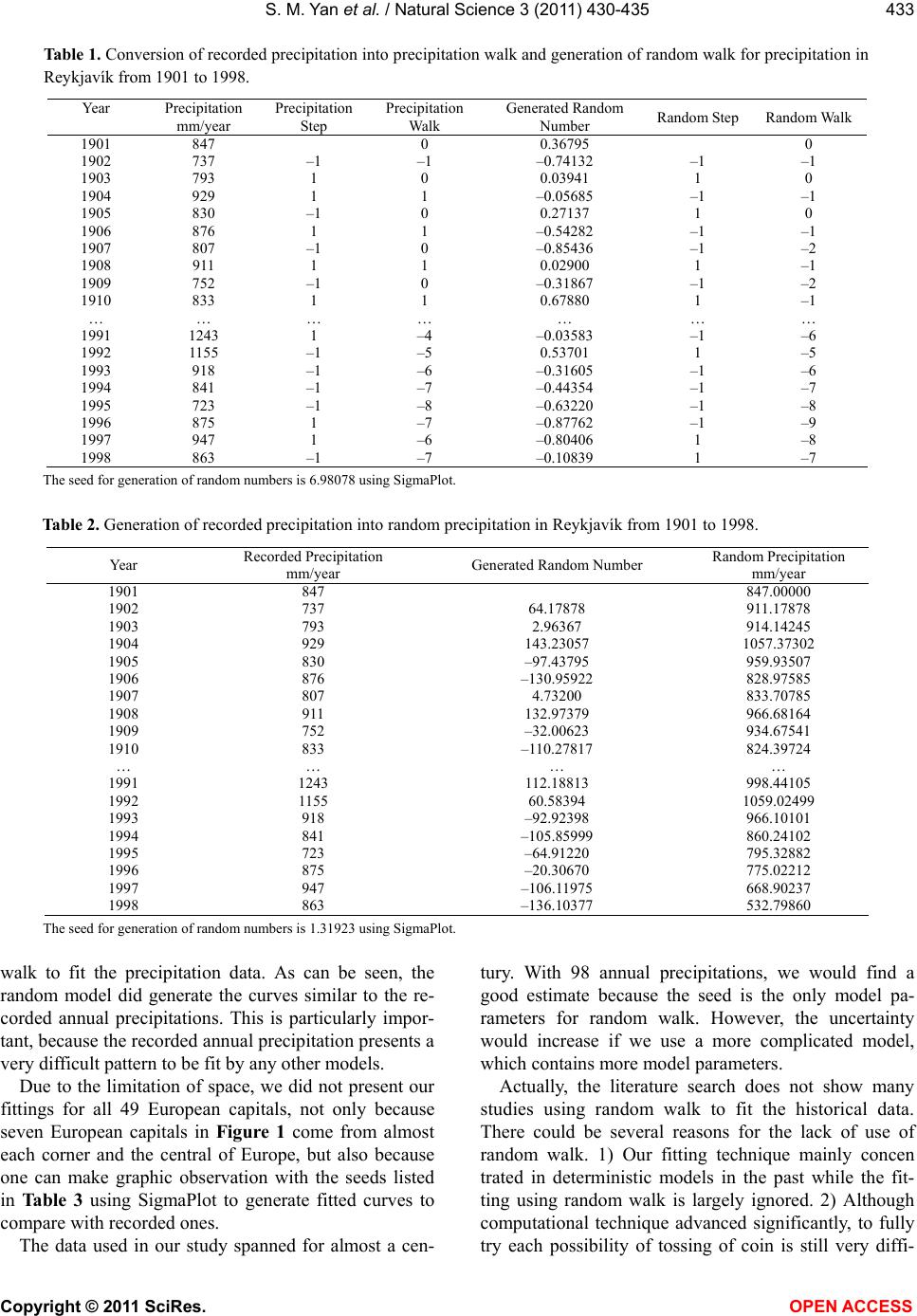
Table 1 shows how we construct a precipitation walk
and its corresponding random walk. For the precipitation
walk, we have the follows: 1) the starting point is the
annual precipitation in 1901, 847 mm (cell 2, column 2),
and this starting point corresponds zero in sense of pre-
cipitation walk (cell 2, column 4); 2) the annual precipi-
tation in 1902 is 737 mm (cell 3, column 2), which is
smaller than the first one, 847 mm (cell 2, column 2), so
we assign –1 as precipitation step (cell 3, column 3), 3)
the precipitation walk is –1 (0 + (–1)) (cell 3, column 4),
and 4) the similar computation is applied to all the data
in columns 2, 3, and 4.
For the random walk, we have the follows: 1) a good
seed we found is 6.98078, and this seed generates a se-
ries of random numbers (column 5), 2) the first random
number, 0.36795 (cell 2, column 5), is considered as the
starting point corresponding to 0 in random walk (cell 2,
column 7), 3) the second random number, –0.74132 (cell
3, column 5), is smaller than the first random number,
0.36795 (cell 2, column 5), so we assign –1 (cell 3,
column 6), 4) the random walk is –1 (0 + (–1)) (cell 3,
column 7), and 5) the similar procedure is applied to all
the data in columns 5, 6, and 7. In the same manner, we
construct the precipitation walk and random walk.
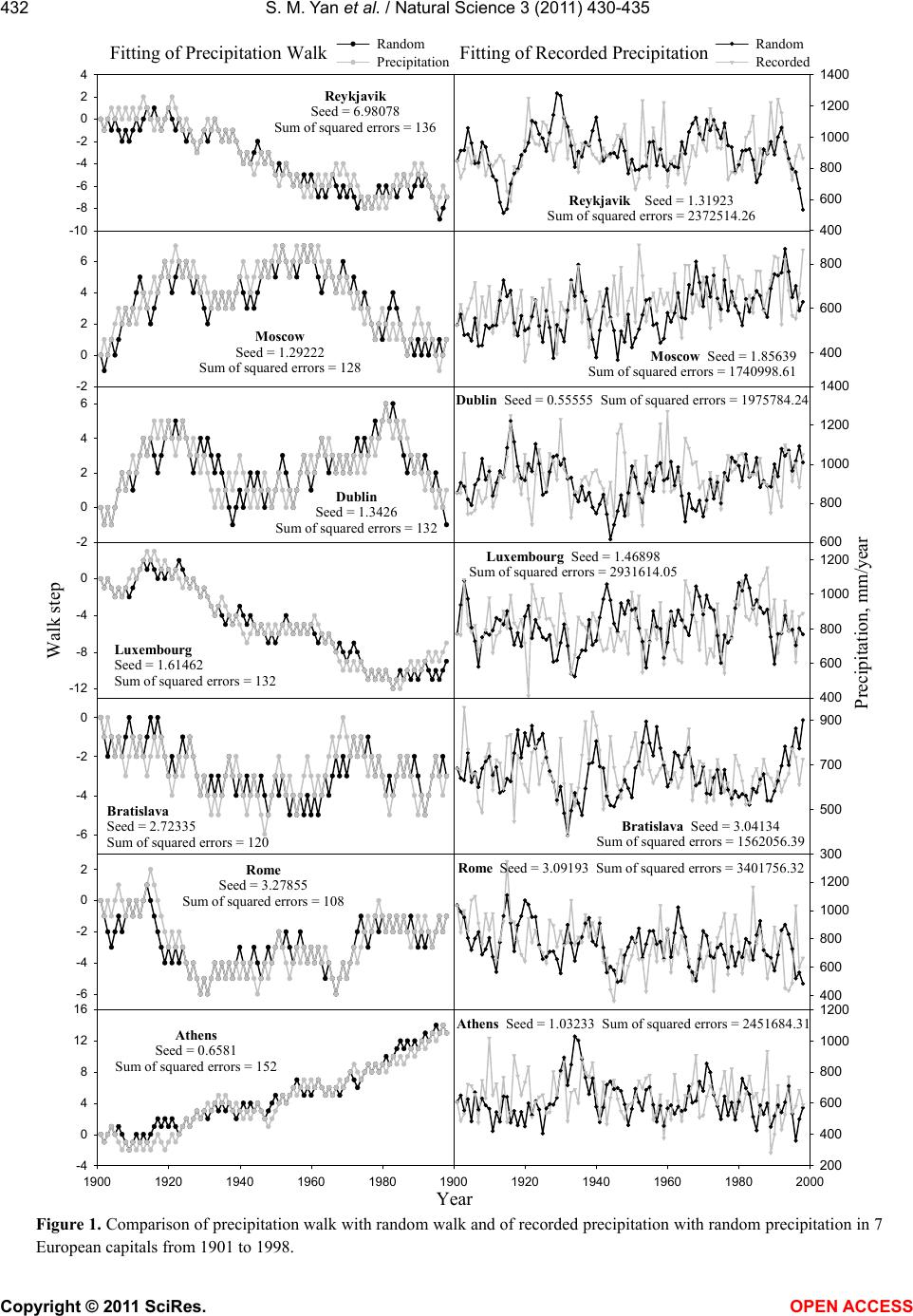
The figures in the left side of Figure 1 show the fit-
tings of precipitation walk in 7 European capitals using
random walk model. As can be seen, the curve generated
by random walk generally passes through the precipita-
tion walk. Theoretically, the chance for a completely
perfect fitting of precipitation walk is an extremely rare
event. In our case, there are 98 annual precipitations,
thus the completely perfect fitting has the chance of
(1/2)98 theoretically, which is extremely small. Clearly
this probability is very difficult to achieve in limited
time because the space of our search is limited to one
million of seed. So the fitting results in the left side of
Figure 1 suggest that a good seed can be relatively eas-
ily found, thus we consider that the random walk can
describe the precipitation walk, although we cannot
compare our results with other results because the other
models do not set an equal-sized step.
Actually we can view the precipitation walk, which is
the conversion from its annual precipitation, as the trend
of recorded precipitation. This is so because this trend
answers the very basic question of whether the precipita-
tion at certain year is larger (1) or smaller (–1) than its
previous year.
Yet, the cities in Figure 1 cross the whole Europe,
thus there would be uncountable factors affecting the
precipitations, but the random walk still can fit them.
This furthermore suggests that the random walk can de-
scribe the precipitation patterns in terms of precipitation
walk.
Table 2 shows how we use a random walk model to
fit the recorded annual precipitation, here we only need
to construct the random precipitation: 1) the starting
point is the first recorded annual precipitation, which is
847 mm (cell 2 in column 2 and column 4), 2) the seed
for Table 2 is 1.31923, 3) the first random number gen-
erated by the seed is 64.17878 (cell 3, column 3), 4) we
add this value to the previous precipitation datum (847)
resulting in 911.17878 mm (cell 3, column 4), and 5)
along this procedure, we get the random precipitation in
column 4.
The figures in the right side of Figure 1 display the
fittings of recorded precipitation with random precipita-
tion in 7 European capitals. In these figures, the precipi-
tation demonstrates very remarkable fluctuations along
the time course, which do not show any clear sign of
visible pattern. This is the basis for conducting random-