 J. Software Engineering & Applications, 2009, 2: 67-76 doi:10.4236/jsea.2009.22011 Published Online July 2009 (www.SciRP.org/journal/jsea) Copyright © 2009 SciRes JSEA Interpretation of Information Processing Regulations Sabah Al-Fedaghi Computer Engineering Department, Kuwait University, Kuwait City, Kuwait. Email: sabah@eng.kuniv.edu.kw Received February 2nd, 2009; revised April 14th, 2009; accepted April 15th, 2009. ABSTRACT Laws and policies impose many information handling requiremen ts on business practices. Comp liance with such regu- lations requires identification of conflicting interpretations of regulatory conditions. Current software engineering methods extract software requ irements by converting legal text into semiformal constraints and rules. In this paper we complement these methods with a state-based model that includes all possibilities of information flow. We show that such a model provides a fou ndation for the interpretation process. Keywords: Software Requirement, Laws, Regulation, Privacy, Personal Identifiable Informa tion 1. Introduction Laws, regulations, and policies such as the Health Insur- ance Portability and Accountability Act (HIPAA) Pri- vacy Rule and the Telecommunications Act of 1996 im- pose many requirements on business practices for han- dling information. In 2006, 161 billion gigabytes of digital information were created, captured, and replicated [1]. It is estimated “that today, 20% of the digital uni- verse is subject to compliance rules and standards, and about 30% is potentially subject to security applications” [1]. In 2005, more than 20,000 regulations were passed related to creation, storage, access, maintenance, and retention of information [2]. Compliance with these laws, regulations, and policies requires identification of conflicting interpretations of regulatory requirements. The information system needs to be aligned with legal and regulatory requirements in order to be in compliance. Statements of regulations in legal documents relevant to information processing contain a great deal of natural language ambiguity that makes it difficult to formalize requirements and constraints in software systems. The basic problem can be viewed as how to extract software requirements from regulations. Researchers have introduced different methods for converting legal language into semiformal specifications; nevertheless, the approaches to interpreting legal text lack compatibility with the software-engineering style o f problem solving. A need exists for an underlying infor- mation-processing model of the different information processing systems, similar to the classical communica- tion model of sender, receiver, and message. Terms such as “collecting,” “processing,” “disclosing,” and so forth are used loosely, without a p attern tying th em tog ether as actions based on information. We will demonstrate such aspects in an example after introducing our model. So, what is the software-engineering style of problem solving that ought to be applied to interpretation of regu- lations to meet software requirements? It involv es simply constructing an information flow model, and taking into account all possible types of actions utilized in process- ing information. While it is not practical to take into ac- count every possible interpretation, we propose a state- based model that includes a limited number of possibili- ties for software responses to all categories of informa- tion handli n g. 2. Related Work The software engineering field is rich with work related to software requirements for domain and systems de- scriptions. Methods have been proposed to extract re- quirements from policies and regulations using formal models [3], semantic parameterization [4], and ontology [5]. Several publications deal with the problem of ex- tracting goals from natural language documents and Internet privacy policies [6,7]. Breaux and Antón [4,8] developed a method to trace the words in regulations to semantic primitives. Giorgini et al. [9] described a framework that enables modeling of actors and goals and their relationships. May et al. [3] introduced a method- ology to extract formal models from regulations and ap- plied it to the HIPAA Privacy Rule.  Interpretation of Information Processing Regulations 68 Figure 1. Information states in FM with the possibility of triggering another type of flow We will concentrate on the recent methodology of Breaux and Antón [10] “to extract access rights and ob- ligations directly from regulation texts . . . [and] present results from applying this methodology to the entire regulation text of the U.S. Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule.” In our case, we will discuss a very limited portion of such a commendable venture . Information processing models have evolved from the classic 1949 Shannon-Weaver communication theory of transference of electrical signals from sender to receiver. Nevertheless, the main aspect of Shannon and Weaver’s model is communication, while information appears as a secondary component of the model. The “transmitted materials” in this communication can be information, data, meaningless signals, energy, or, with proper per- spective, other entities. We are interested more in information properties than in the communication act itself. Such an approach con- centrates solely on information, while communication aspects (as important as they are) become secondary fea- tures of the flow of information. This paper introduces an information flow model that includes five stages: collec- tion, processing, creation, disclosure, and communica- tion. Such a model provides a better framework on which to base interpretation of information handling processes. 3. Model of Information Flow The flow model (FM) has been proposed and used in several applications. In FM, the flow of flowThings in- dicates movement inside and between spheres. The sphere is the environment of the flow and includes five stages that may be sub-spheres, each with its own five-stage schema. The stages may be named differently; for example, in an information sphere, a stage may be called communication, while in action flow, the same stage is called transferring. To illustrate the notion of flowThing, we will assume that the “thing that flows” is information. We use the term information to refer to information and misinforma- tion, as in common usage where a reporting statement can be true or false. An information sphere denotes the information environment. The lifecycle of information is a sequence of states in its lifecycle, as follows: 1) Re- ceived, 2) Processed (in a way that changes its form, but not content), 3) Released, 4) Communicated (to another sphere), and 5) Created (i.e., a new piece of information). These five states of information form the main stages of the stream of flow, as illustrated in Figure 1. Each stage may include sub-stages, such as storage and usage. The states shown in Figure 1 are exclusive in the sense that if information is in one state, then it is not in any of the other four states. Consider a piece of information, , possessed by a hospital; is thus in one of the following states: 1) has just been collected from some source (patient, friend, sent by some agency) and stored in the hospital record, waiting to be used. It is collected (row) informa- tion that has not yet been processed by the hospital. 2) has been processed in some way, converted to another form (e.g., digital), translated, compressed, etc. Also, it may be stored in the hospital information system as processed data waiting for some use. 3) has actually been created in the hospital as the result of doctor’s diagnoses, lab tests, etc. Thus, is in the possession of the hospital as created data to be used. 4) is being released from the hospital infosphere. It is designated disclosed information ready for transfer. Analogous to a factory environment, represents materi- als ready to be shipped outside the factory. It may actu- Copyright © 2009 SciRes JSEA  Interpretation of Information Processing Regulations 69 ally be stored for some period waiting to be transported; nevertheless, its designation as “for export” keeps it in such a state. 5) is in a transfer state, being transferred between two infospheres. It has left the disclosure state and will enter the collection state, where it will become collected information in the new infosphere. It is not possible for processed information to directly become collected information in the same infosphere. Processed information can become collected information in another infosphere by first becoming disclosed infor- mation, and then transferred information, in order to ar- rive at the other environment. We use this model, called the information flow model (IFM), to classify information in generic theoretical categories that can be applied in any infosphere, includ- ing laws and regulations. According to Kurt Lewin, “There is nothing quite as practical as a good theory.” Consider the following extract from the Safety Offi- cer’s Briefing Book of the United States Air Force Aux- iliary [11]: Water vapor is an invisible gas, similar to nitrogen and oxygen, the two gases which make up 98% of our atmosphere. We see clouds and fog when the gaseous water vapor is cooled sufficiently to allow a change of state from gas to liquid. We see snow, sleet, and hail when the liquid water is further cooled to a solid state. And when water changes directly from gas to solid it becomes frost, through a process called “sublimation.” [Italics added.] Imagine this to be a statement of regulations with no model of water circulation among its states of liquid (water), gas (vapor, fog), and solid (ice). We could probably manage to write safety regulations using terms such as “clouds” and “frost,” as in the following rewrite of the previous quote: Water is an invisible material, similar to nitrogen and oxygen, the two gases which make up 98% of our at- mosphere. We see clouds and fog when the water is cooled sufficiently. We see snow, sleet, and hail when the water is further cooled. And when water changes, it becomes frost, through a process called “sublimation.” A great deal of conceptual clarity is lost without specification of the three natural states of water in a model of its circulation among those states. Similarly, information handling regulations not based on the infor- mation flow model are simply vague descriptions of the proper way to handle information. As another example, consider applying the IFM to HIPAA Privacy Rule [12]. According to the Privacy Rule, “A covered entity may use or disclose, without an individual’s authorization, the psychotherapy notes . . .” [13]. We show that, in the context of IFM, use and dis- close may be interpreted in several ways. Psychotherapy notes are defined in the Rule as: . . . notes recorded (in any medium) by a health care provider who is a mental health professional document- ing or analyzing . . . that are separated from the rest of the individual’s medical record. Psychotherapy notes exclude medication prescription and monitoring, coun- seling session start and stop times, the modalities and frequencies of treatment furnished, results of clinical tests, and any summary o f the following items: diag nosis, functional status, the treatment plan, symptoms, progno- sis, and progress to date. A psychotherapist collects information from four sources: 1) The original medical record 2) Information created by the psychotherapist during a session 3) New information revealed by the patient during a session 4) Created information related to the session (e.g., start and stop times: John’s session is at 4 pm, John ar- rived late for the session). These clear categorizations of information can be sup- plemented with the type of descriptions given by the rule (e.g., summary of this type or that type). Each category may require different constraints on its use and disclo- sure. For example, releasing information of type (2) may need the approval of the psychotherapist who wrote it, while the decision to release information of category (1) has nothing to do with the psychotherapist. The point here is that the IFM allows more refined in- terpretation of natural language description involving operations on different types of information, such as dis- closure. The example above includes at least three types of disclosures: disclosure of collected information, dis- closure of created information, and disclosure of proc- essed information. Each type may need different disclo- sure constraints [14]. 4. Personal Identifying Information This paper focuses on the HIPAA Privacy Rule; for that purpose we regard personal identifiable information (PII) as the main type of information and object of study [12]. The “circulation of PII” can be modeled in IFM as in- formation f lo w. It is typically claimed that what makes data “private” or “personal” is either specific legislation (e.g., a com- pany must not disclose information about its employees) or individual agreements (e.g., a customer has agreed to an electronic retailer's privacy policy); however, this line of thought blurs the difference between personal identi- fiable information and other “private” or “personal” in- formation. Personal identifiable information has an “ob- jective” definition in the sense that it is independent of such authorities as legislation or agreement. Copyright © 2009 SciRes JSEA 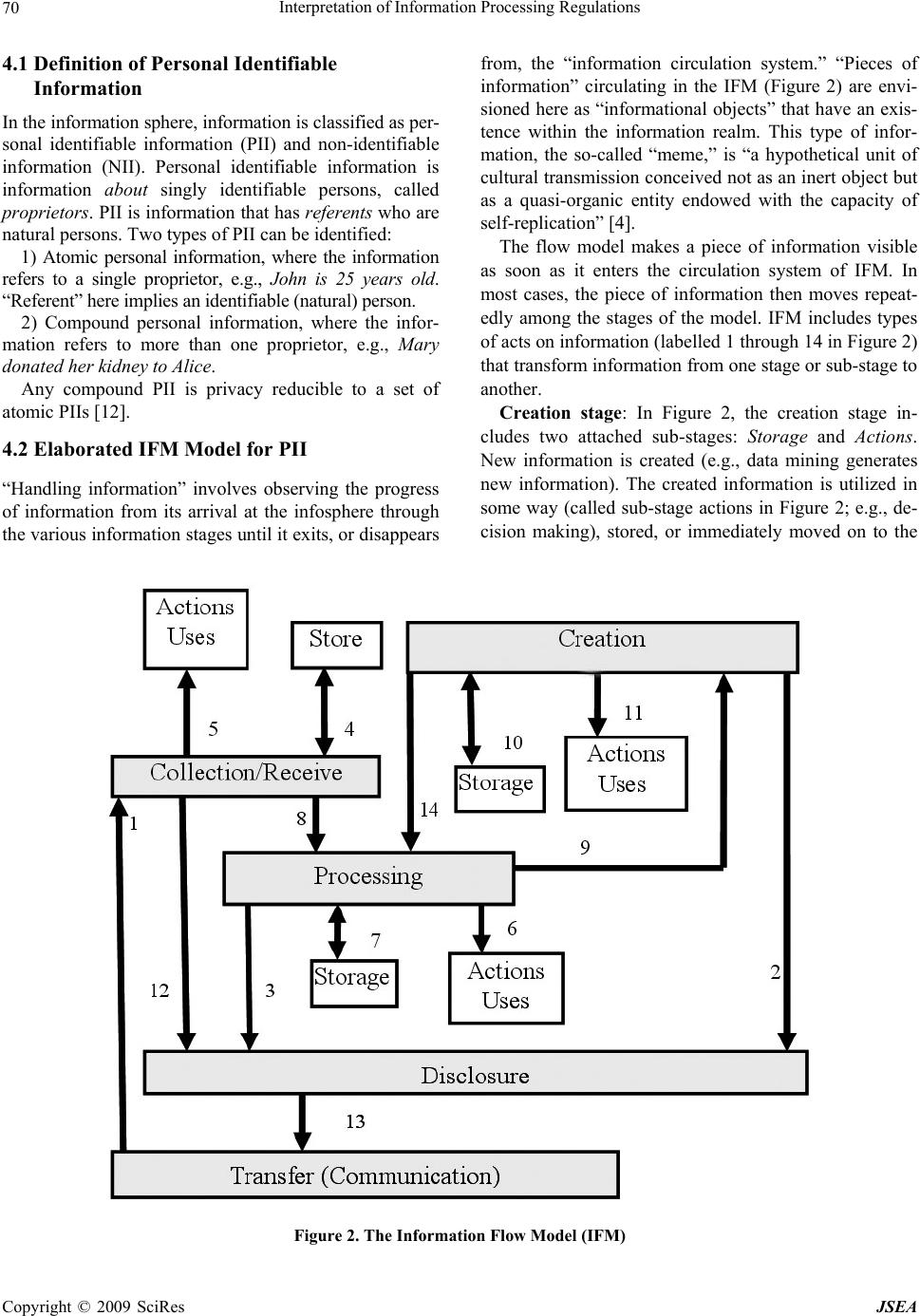 Interpretation of Information Processing Regulations Copyright © 2009 SciRes JSEA 70 4.1 Definition of Personal Identifiable Information In the information sphere, information is classified as per- sonal identifiable information (PII) and non-identifiable information (NII). Personal identifiable information is information about singly identifiable persons, called proprietors. PII is information that has referents who ar e natural persons. Two types of PII can be identified: 1) Atomic personal information, where the information refers to a single proprietor, e.g., John is 25 years old. “Referent” here implies an identifiable (natural) person. 2) Compound personal information, where the infor- mation refers to more than one proprietor, e.g., Mary donated her kidney to Alice. Any compound PII is privacy reducible to a set of atomic PIIs [12]. 4.2 Elaborated IFM Model for PII “Handling information” involves observing the progress of information from its arrival at the infosphere through the various information stages until it ex its, or disap pears from, the “information circulation system.” “Pieces of information” circulating in the IFM (Figure 2) are envi- sioned here as “informational objects” that have an exis- tence within the information realm. This type of infor- mation, the so-called “meme,” is “a hypothetical unit of cultural transmission conceived not as an inert object but as a quasi-organic entity endowed with the capacity of self-replication” [4]. The flow model makes a piece of information visible as soon as it enters the circulation system of IFM. In most cases, the piece of information then moves repeat- edly among the stages of the model. IFM includes types of acts on information (labelled 1 through 14 in Figure 2) that transform information from on e stage or sub-stag e to another. Creation stage: In Figure 2, the creation stage in- cludes two attached sub-stages: Storage and Actions. New information is created (e.g., data mining generates new information). The created information is utilized in some way (called sub-stage actions in Figure 2; e.g., de- cision making), stored, or immediately moved on to the Figure 2. The Information Flow Model (IFM)  Interpretation of Information Processing Regulations 71 stages of processing or departure (disclosure and trans- fer). In IFM, “action” refers to any utilization of infor- mation. For example, suppose a physician makes a new diag- nosis of a disease (creates new information), such as John Smith has AIDS. Such new information may be generated by examining (mining) some data. John Smith has AIDS is then communicated to an expert (disclosed and transferred), or processed further (cycled through processing-mining-creation-processing) to verify the medical judgment. The physician creates (act 9) new information and also uses the information in the pa tient’s file for “treatment” (physical action). Another example of uses in this context is “home delivery of medicin e to a patient” (physical action) that uses the address informa- tion. Collection stage: The collection stage is the informa- tion acquisition stage, when information is accepted from external suppliers and fed into the IFM circulation sys- tem. This stage includes the possibility of using the ar- riving (raw) information; the sub-stage, Actions, in IFM is therefore a way for information to exit the system (i.e., arriving information generates the action of physical treatment, without further propagation in IFM). It also includes the possibility of storing the collected informa- tion. Processing stage: The processing stage involves act- ing on information (e.g., anonymization, data mining, summarizing). Processing is performed on acquired in- formation from the collection stage or the creation stage; see Figure 2. In actual processing, information is modi- fied in form or content. IFM distinguishes between two types of processing: ordinary processing, which does not produce new or in- ferred information, and creation of new information (e.g., by mining). An example of creation of new information is the categorization of diverse information used to reach a decision, e.g., John is a risk. Other types of processing that do not generate new information, but only change the appearance of information, include comparing, com- pressing, translating, and deleting. Disclosure and transfer/communication stages: The disclosure stage involves releasing information to those outside the infosphere. It relies on the transfer stage to carry information from the current infosphere to the col- lection stage in another infosphere. When information is in the transfer state, it is flowing (e.g., through a channel) between two infospheres. 5. Application to Extraction Constraints Healthcare regulations, such as HIPAA, are often diffi- cult to grasp and interpret. Interpretation of HIPAA regulations is of utmost importance because of the costs associated with any misinterpretation. According to the U.S. Department of Health and Human Services., the healthcare industry will spend $17 .6 billion ov er the next few years to bring their systems and procedures into compliance with HIPAA [15]. Consequen tly, we limit this paper to applying the IFM model to the problem of extracting software require- ments from HIPPA regulations; however, this focus does not mean the model cannot be applied to any other area with information-handling regulations. Additionally, our treatment is obviously incomplete in the sense that it is not a rewriting of the entire regulation, since it aims mainly to present a general methodo logy for interpreting informational privacy regulations. We will concentrate specifically on methodology re- cently introduced by Breaux and Antón [10] for extract- ing access rights and obligations directly from the text of regulations. According to Breaux and Antón [10], “‘rules’ are often precursors to software requirements that must undergo considerable refinement and analysis before they are implementable.” Breaux and Antón [10] then present “a methodology to extract access rights and obligations directly from regulation texts . . . to support the software engineering effort to derive security re- quirements from regulations.” The methodology will then “identify and infer six types of data access con- straints, handle complex cross-references, resolve ambi- guities, and assign required priorities between access rights and obligations to avoid unlawful information dis- closures.” The following excerpt from Privacy Rule §164.510 (b)(1)(i) will be used to illustrate use of IFM to develop a complete picture of situation s specified by the Rule. A CE [Covered Entity] ma y, in accordance with pa ra- graphs (b)(2) or (3) of this section, disclose to a family member, other relative, or a close personal friend of the individual, or any other person identified by the individ- ual, the PHI [Protected Health Information] directly relevant to such person’s involvement with the individ- ual’s care or payment related to the individual’s health- care. We discuss some of the constraints extracted by Breaux and Antón [10] to exemplify ambiguities uncov- ered by the definitions of PII and IFM. Constraint 1: The PHI is directly relevant to the per- son’s involvement in the individual’s care. Comments: We should explicitly declare whether the atomic PII is collected PII, processed PII, or created PII. For example, the proprietor may agree to release his or her telephone number (collected information), but not the results of his or her lab examination (created PII), or his or her doctor’s diagnosis (created PII). Notice that the point here is not constraints on the scope of information (e.g., address and phone number); it Copyright © 2009 SciRes JSEA  Interpretation of Information Processing Regulations 72 is, rather, the right of the proprietor to be presented with all alternative actions to which he or she can consent, and the obligations of the stakeholder to provide the pro- prietor with complete information for making informed consent. The choices here are as follows: - Disclosing only PII collected by the stakeholder from other sources - Disclosing PII processed by the stakeholder, such as implied PII, translated PII, anonymized PII, etc. - Disclosing created PII by the stakeholder, such as lab results, doctors’ diagnoses, etc. These actions deal with categories of PII and not spe- cific PIIs; thus, it is practical to list this small number of categories of which the proprietor approves disclosure. Such classification of PII is also suitable for software design and implementation in a decision-making system. In general, the Privacy Rule permits uses and disclo- sures for “treatment, payment and health care opera- tions,” as well as certain other disclosures, without the individual’s prior written authorization. What we pro- pose is that such permission be categorized by the sys- tem according to the type of PII, for example, - Collected PII uses and disclosures for “treatment, payment and health care operations” has a different ac- cess policy than - Created PII uses and disclosures for “treatment, pay- ment and health care operations.” For example, “uses and disclosures” of created PII may need the approv al of its creator (e.g., the physician). Constraint 2: PHI is directly relevant to the person’s involvement in payment related to that person’s health- care. Comment: PII “directly relevant to the person’s in- volvement in payment related to the individual’s health- care” may also be collected PII, processed PII, or created PII. For example, disclosing such information may not include a hospital’s own evaluation of the proprietor’s financial reliability. It is similar to releasing “information I have” (collected PII), but not “information I have in- ferred” (created PII). Constraint 3: The use is to carry out treatment, pay- ment, or healt hcare operations. Comments: The “uses” of collected PII, processed PII, and created PII are different. In particular, created in- formation carries different types of responsibilities from those of collected PII that is then disclosed. The disclo- sure that (According to our diagnoses) John Smith is an AIDS patient (collected PII) has a different weight than the disclosure that John Smith is an ABC employee (col- lected PII) even though both disclosures are for the same use. We conclude that IFM can enhance such a methodol- ogy for extracting constraints from regulation texts. IFM simply reveals all paths of information circulation; thus, we can take into account all possible interpretations in the text. Next, we apply IFM to the process called “se- mantic parameterization,” proposed by Breaux and Antón [10]. 6. Enhanced Semantic Parameterization According to Breaux and Antón [10], semantic parame- terization is a process to “support engineers who map natural language domain descriptions to models ex- pressed in first-order predicate logic for the purpose of performing automated reasoning and analysis” [16]. It provides: 1) A reference system that systematically detects and resolves such ambiguities. 2) Automated support for placing natural language-li- ke inquiries across collections of requirements that an- swer who, what, where, when , how, and why questions. 3) A means to formalize and compare different stake- holder viewpoints. Breaux and Antón [10] consider the following “prop- erties” of information to be access–related activities: a) The subject is the actor who performs an action on an object in the activity. In the IFM, the subject is one of the entities that acts on PII. b) The action is the verb that affects information, such as access, use, disclose, etc. The IFM limits the number of acts on PII that can be applied here. c) The modality modifies the action by denoting the action as a right, obligation, or refrainment. Such a “mo- dality” can be added after the backbone of the informa- tion handli ng processes is de signed, as described next . d) The object is limited to information, including the name or date of birth of a patient, or an accounting of disclosures. In IFM, information is limited to PII and includes all acts and uses of information defined by the model in Figure 2. e) The target is the recipient in a transaction, such as the recipient of a disclosure. The target in IFM is one of the agents in PII transactions. There may be several agents, as illustrated in Figure 3. It is also possible that both sides of the transaction belong to the same organi- zation. In the IFM, we can identify all entities that may be in- volved in handling PII in order to accomplish the same thing that Breaux and Antón [10] extract from legal wording. IFM gives a complete picture that includes all entities and processes needed to produce a design descrip- tion of the software, and no more. For example, a policy for access-related activities can be specified according to the type of entity (e.g., a collector—a clerk who fills pa- tient data cannot access processed information). Thus, the software engineer can design a system that takes into consideration all cases of information flow. The entities that may be involved in handling PII are several, including proprietor, possessor, collector, proc- essor, different types of users, different types of store- keepers, (data) miner, creator, releaser, and transferor. Copyright © 2009 SciRes JSEA  Interpretation of Information Processing Regulations Copyright © 2009 SciRes JSEA 73 Figure 3. PII flow involving a proprietor and two agents Consider the following example from Breaux and Antón [10]: Excerpt from Privacy Rule §164.522(a)(1): (i) A CE must permit an individual to request that the CE restrict: (A) Uses or disclosures of PHI about the individual to carry out treatment, payment or healthcare opera- tions; and (B) Disclosures permitted under §164.510(b) (ii) A CE is not required to agree to a restriction. (iii) A CE that agrees to a restriction under paragraph (a)(1)(i) of this section may not use or disclose PHI in violation of such restriction, except that, if the individual who requested the restriction is in and the restricted PHI is needed to provide emergency treatment, the CE may use the restricted PHI, or may disclose such informatio n to a HCP, to provide such treatment to the individual. Applying the Breaux and Antón [10] method to this excerpt yields constraints and rules, some of which are as follows: - The use is to carry out treatment, payment, or health- care operations. - The disclosure is to carry out treatment, payment, or healthcare operations. - The CE agrees to a restriction. - The individual requested the restriction. - The individual is in need of emergency treatment. - The PHI is needed to provide emergency treatment. - A CE must permit an individual to request a restric- tion. - A CE is not required to agree to a restriction. A software engineer then applies pa tterns to identify rights, obligations, and constraints. For example, “the basic activity pattern describes a subject who performs an action on an object and modality distinguishes the activity as a right, obligation or refrainment. Each rule uses these two patterns to ensure that the statement has precisely one subject, action, obj ect and modality” [10]. The IFM introduces an intermediate stage of analysis that provides a foundation for the legal text. The excerpt from Privacy Rule §164.522(a)(1) specifies relationships between a CE and a proprietor: use and disclosure, as described next. 6.1 The Use Relationship Figure 4 shows the Use relationship embedded in the excerpt. The CE is a possessor of PII about the propr ietor. The CE may be a collector, processor, creator, store- keeper, or (data) miner of this PII, or all or some of these roles. In all cases, the relationship between the CE and proprietor leads to some use (actions in IFM). The uses are of two types: - Use to “carry out treatment, payment, or healthcare operations” - Use for “need of emergency treatment” (dotted lines in Figure 4). The software engineer can represent all possible cases in this situation. Thus, he or she can put constraints and rules on the use of PII generated by the CE that are dif- ferent from constraints and rules on use of PII collected from outsiders, including the proprietor him/herself. If PII, e.g., a bank account number, is given by the proprietor, then obviously there are no restrictions on the use of such PII to “carry out payment.” It would make no sense for a patient to give his or her bank account number and then request restrictions on CE use of such information to “carry out payment;” therefore, the software engineer can design a system such that it traces the source of PII, hence focusing the rules accordingly. The IFM magnifies all types of relationships between entities such that ambigu- ty in the legal text can be easily spotted. i 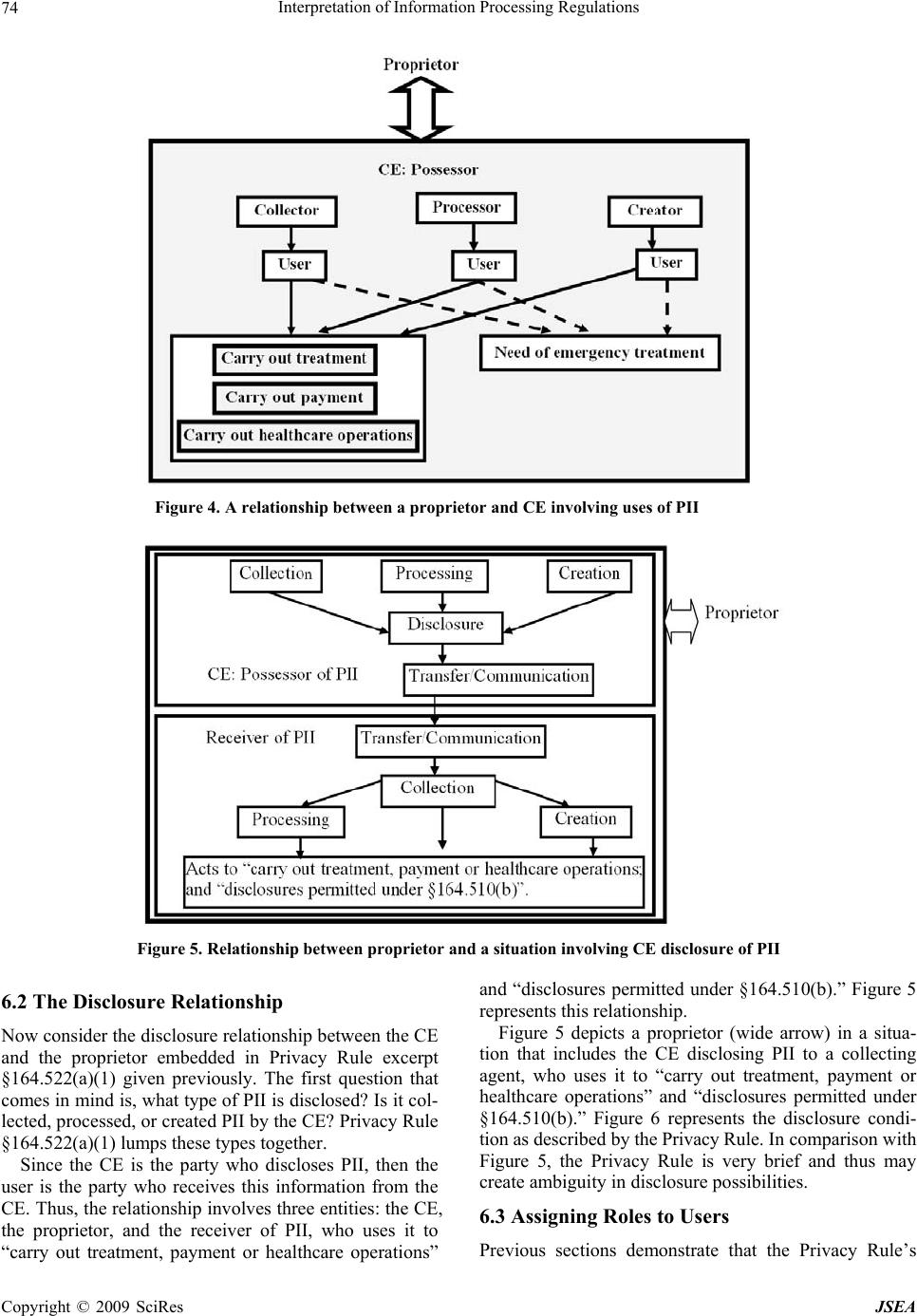 Interpretation of Information Processing Regulations 74 Figure 4. A relationship between a proprietor and CE involving uses of PII Figure 5. Relationship between proprietor and a situation involving CE disclosure of PII 6.2 The Disclosure Relationship Now consider the disclosure relationship between the CE and the proprietor embedded in Privacy Rule excerpt §164.522(a)(1) given previously. The first question that comes in mind is, what type of PII is disclosed? Is it col- lected, processed, or created PII by the CE? Privacy Rule §164.522(a)(1) lumps these types together. Since the CE is the party who discloses PII, then the user is the party who receives this information from the CE. Thus, the relationship involves three entities: the CE, the proprietor, and the receiver of PII, who uses it to “carry out treatment, payment or healthcare operations” and “disclosures permitted under §164.510(b).” Figure 5 represents this relationship. Figure 5 depicts a proprietor (wide arrow) in a situa- tion that includes the CE disclosing PII to a collecting agent, who uses it to “carry out treatment, payment or healthcare operations” and “disclosures permitted under §164.510(b).” Figure 6 represents the disclosure condi- tion as described by the Privacy Rule. In comparison with Figure 5, the Privacy Rule is very brief and thus may create ambiguity in disclosure possibilities. 6.3 Assigning Roles to Users Previous sections demonstrate that the Privacy Rule’s Copyright © 2009 SciRes JSEA 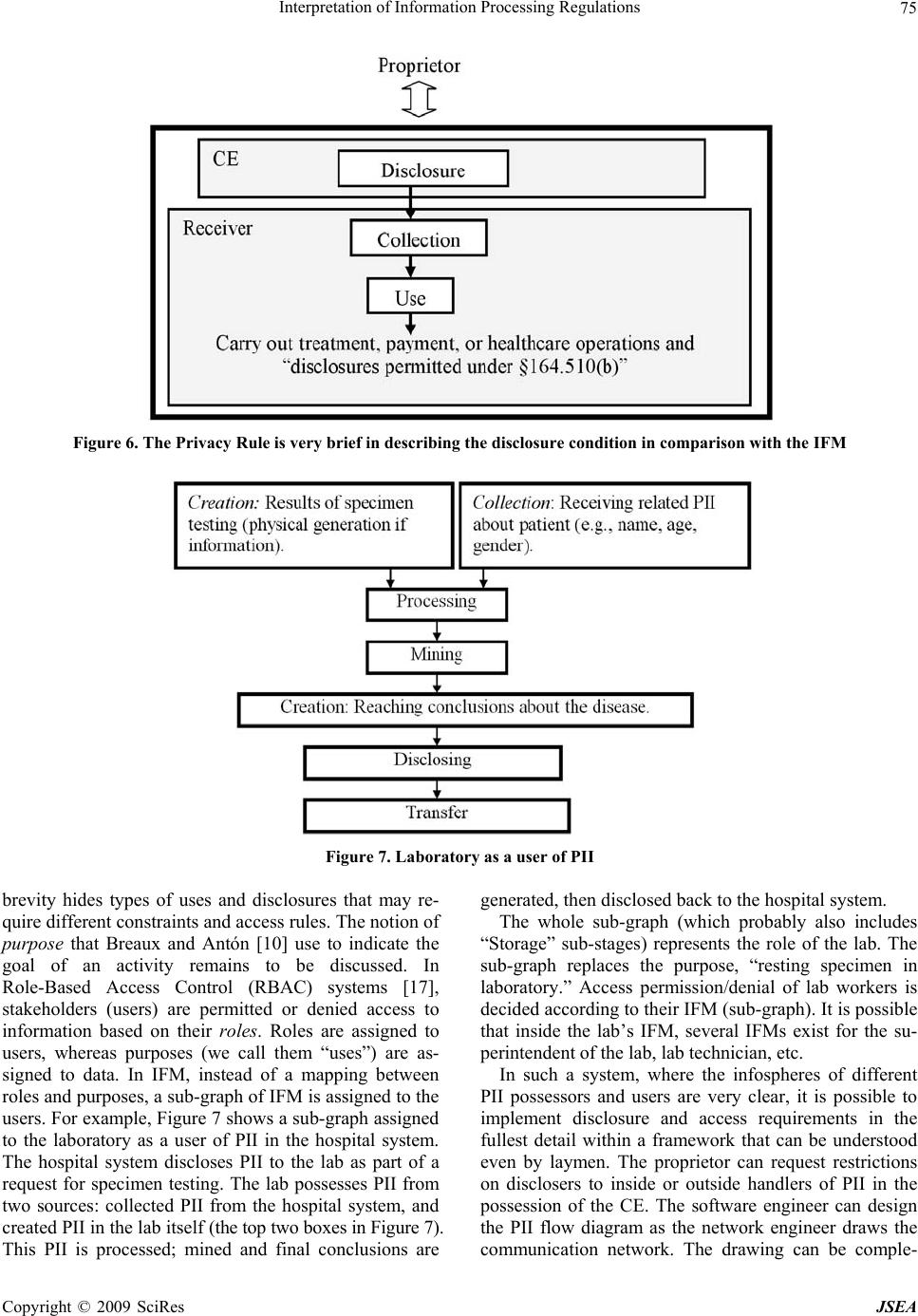 Interpretation of Information Processing Regulations 75 Figure 6. The Privacy Rule is very brief in describing the disclosure condition in comparison with the IFM Figure 7. Laboratory as a user of PII brevity hides types of uses and disclosures that may re- quire different constraints and access rules. The notion of purpose that Breaux and Antón [10] use to indicate the goal of an activity remains to be discussed. In Role-Based Access Control (RBAC) systems [17], stakeholders (users) are permitted or denied access to information based on their roles. Roles are assigned to users, whereas purposes (we call them “uses”) are as- signed to data. In IFM, instead of a mapping between roles and purposes, a su b-grap h of IFM is assigned to the users. For example, Figu re 7 shows a sub-graph assigned to the laboratory as a user of PII in the hospital system. The hospital system discloses PII to the lab as part of a request for specimen testing. The lab possesses PII from two sources: collected PII from the hospital system, and cre a t e d PII in th e l a b i t s e l f (the top two boxes in Figure 7). This PII is processed; mined and final conclusions are generated, then disclosed back to the hospital syste m. The whole sub-graph (which probably also includes “Storage” sub-stages) represents the role of the lab. The sub-graph replaces the purpose, “resting specimen in laboratory.” Access permission/denial of lab workers is decided according to their IFM (sub-graph). It is possible that inside the lab’s IFM, several IFMs exist for the su- perintendent of the lab, lab technician, etc. In such a system, where the infospheres of different PII possessors and users are very clear, it is possible to implement disclosure and access requirements in the fullest detail within a framework that can be understood even by laymen. The proprietor can request restrictions on disclosers to inside or outside handlers of PII in the possession of the CE. The software engineer can design the PII flow diagram as the network engineer draws the communication network. The drawing can be comple- Copyright © 2009 SciRes JSEA  Interpretation of Information Processing Regulations 76 mented with al l t y pes of requi rements at di fferent poi nt s of PII flow. Complacence level can be claim ed accordi ngly. 7. Conclusions In this paper we have proposed complementing current software engineering methods to extract requirements from legal text, with a model that includes all possibili- ties of information flow. We have shown through exam- ples that such a model provides a foundation for the in- terpretation process. The IFM is very general, such that it can be applied in all kinds of work in this area. We have concentrated on the analysis of Breaux and Antón [10] in order to reach some depth in illustrating the application of the IFM. A great deal of work is needed to integrate the IFM into a workable product that generates the software re- quirement. The most productive approach is to incorpo- rate the model into an existing methodology, rather than developing an IFM-based scheme from scratch. On the other hand, as a future work, theoretical analysis can be developed for the methodology to formally characterize its features. REFERENCES [1] D. Reinsel, C. Chute, W. Schlichting, J. McArthur, I. Xheneti, A. Toncheva, and A. Manfrediz, “A for- ecast of worldwide information growth through 2010.” An IDC White Paper, 2007. http://www.emc.com/about/destina- tion/digital_universe/pdf/Expanding_Digital_Universe_I- DC_WhitePaper_022507.pdf [2] Nexsan Technologies Inc, White paper on enabling in- formation lifecycle management, 2005. http://www.me- ganet1.com/pdf/Enabling%20Information%20Lifecycle% 20management.pdf [3] M. J. May, C. A. Gunter, and I. Lee, “Privacy APIs: Ac- cess control techniques to analyze and verify legal pri- vacy policies,” 19th IEEE Workshop Computer Security Foundations, pp. 85-97, 2006. [4] T. D. Breaux and A. I. Antón, “Deriving semantic models from privacy policies,” 6th IEEE International Workshop on Policies for Distributed Systems and Networks, pp. 67-76, 2005. [5] S-W. Lee, R. Gandhi, D. Muthurajan, D. Yavagal, and G- J. Ahn, “Building problem domain ontology from secu- rity requirements in regulatory documents,” International Workshop on Software Engineering for Secure Systems, Shanghai, China, pp. 43-50, 2006. [6] A. I. Antón, J. B. Earp, Q. He, W. Stufflebeam, D. Bol- chini, and C. Jensen, “Financial privacy policies and the need for standardization,” IEEE Security and Privacy, Vol. 2, No. 2, pp. 36-45, 2004. [7] A. I. Antón, “Goal-based requirements analysis,” 2nd IEEE International Conference on Requirements Engi- neering, pp. 136-144, 1996. [8] T. D. Breaux and A. I. Antón, “Analyzing goal semantics for rights, permissions and obligations,” 13th IEEE In- ternational Conference on Requirements Engineering, pp. 177-186, 2005. [9] P. Giorgini, F. Massacci, J. Mylopoulos, and N. Zannone, “Modeling security requirements through ownership, permission and delegation,” 13th IEEE International Conference on Requirements Engineering, pp. 167-176, 2005. [10] T. Breaux and A. I. Antón, “Analyzing regulatory rules for privacy and security requirements,” IEEE Transac- tions on Software Engineering, Vol. 34, No. 1, pp. 5-20, January 2008. [11] D. Tindal, “Safety officer’s briefing book,” Civil Air Patrol, United States Air Force Auxiliary, February 1 2000. http://www.iawg.cap.gov/archives/ iawgsafety- manual.pdf. [12] S. Al-Fedaghi, “Scrutinizing the rule: Privacy realization in HIPAA,” International Journal of Healthcare Informa- tion Systems and Informatics (IJHISI), Vol. 3, No. 2, 2008. [13] HHS, “Summary of the HIPAA privacy rule,” U.S. De- partment of Health & Human Services, 2003. http://www. hhs.gov/ocr/privacysummary.pdf. [14] S. Al-Fedaghi, “Software engineering interpretation of information processing regulations”, IEEE 32nd Annual International Computer Software and Applications Con- ference (IEEE COMPSAC 2008), Turku, Finland, July 28–August 1, 2008. [15] Office for Civil Rights, US Department of Health and Human Services, “Medical privacy: National standards to protect the privacy of personal health information,” 2000 http://www.hhs.gov/ocr/hipaa/finalreg.html. [16] T. D. Breaux and A. I. Antón, “Semantic parameteriza- tion: A conceptual modeling process for domain descrip- tions,” North Carolina State University Computer Sci- ence Technical Report TR-2006-35, October 2006. [17] R. S. Sandhu, E. J. Coyne, H. L. Feinstein, and C. E. Youman, “Role-based access control models,” IEEE Computer, Vol. 29, No. 2, pp. 38-47, 1996. Copyright © 2009 SciRes JSEA
|