Speech Enhancement Using Cross-Correlation Compensated Multi-Band
124 Wiener Filter Combined with Harmonic Regeneration
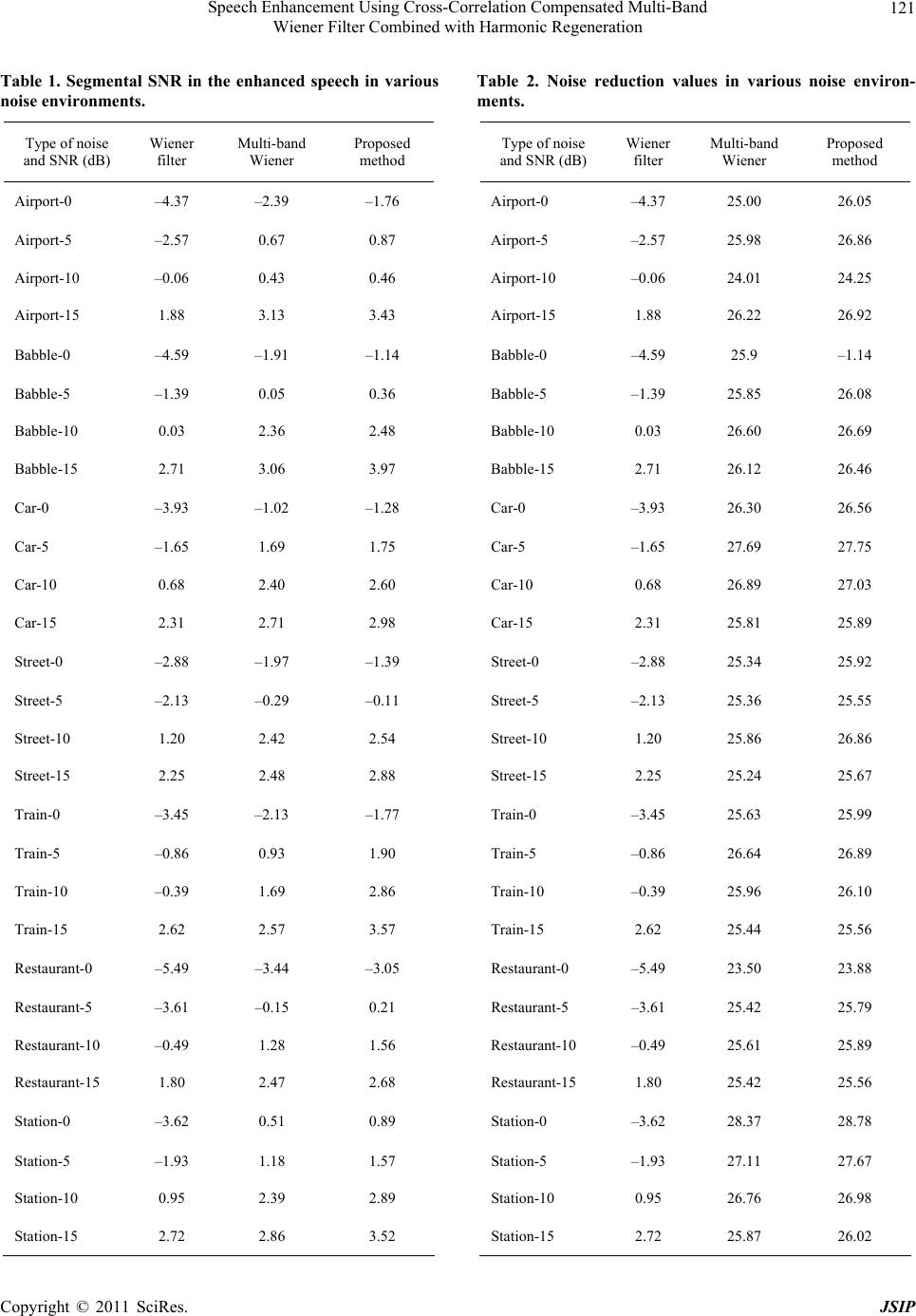
and noise reductio n values. All these results demonstrate
the good performance of the proposed method.
REFERENCES
[1] Y. Ephraim, “Statistical-Model-Based Speech Enhance-
ment Systems,” Proceedings of IEEE, Vol. 80, No. 10,
1992, pp. 1526-1555. doi:10.1109/5.168664
[2] J. R. Deller, H. G. Proakis and J. H. L. Hansen, “Dis-
crete-Time Processing of Speech Signals,” Macmillan,
New York, 1993.
[3] S. V. Vaseghi, “Advanced Digital Signal Processing and
Noise Reduction,” 2nd Edition, John Wiley & Sons ltd.,
Chichester, 2000. doi:10.1002/0470841621
[4] Y. Gui and H. K. Kwan, “Adaptive Subband Wiener Fil-
tering for Speech Enhancement Using Critical-Band
Gammatone Filterbank,” 48th Midwest Symposium on
Circuits and Systems, Vol. 1, 7-10 August 2005, pp. 732-
735.
[5] J. S. Lim and A. V. Oppenheim, “Enhancement and
Bandwidth Compression of Noisy Speech,” Proceedings
of IEEE, Vol. 67, No. 12, 1979, pp. 1586-1604.
doi:10.1109/PROC.1979.11540
[6] Y. Ephraim and D. Malah, “Speech Enhancement Using a
Minimum Mean Square Error Short-Time Spectral Am-
plitude Estimator,” IEEE Transaction on Speech Audio
Processing, Vol. 32, No. 6, 1984, pp. 1109-1121.
[7] S. F. Boll, “Suppression of Acoutics Noise in Speech
Using Spectral Subtraction,” IEEE Transaction on
Acoustics, Speech, Signal Processing, Vol. 27, No. 2,
1979, pp. 113-120. doi:10.1109/TASSP.1979.1163209
[8] E. Zwicker and H. Fastl, “Psychoacoustics,” Springer
Verlag, Berlin, 1990.
[9] K. A. Sheela, Ch. V. R. Rao, K. S. Prasad and A. V. N.
Tilak, “A New Noise Reduction Pre-Processor for Mobile
Voice Communication Using Perceptually Weighted
Spectral Subtraction Method,” 3rd International Confer-
ence on Mobile Ubiquitous and Pervasive Computing,
VIT University, 16-19 December 2006.
[10] G. Farahani, S. M. Ahadi and M. M. Homayounpoor,
“Robust Feature Extraction of Speech via Noise Reduc-
tion in Autocorrelation Domain,” Lecture Notes in Com-
puter Science 4105, Springer-Verlag, 2006, pp. 466-473.
[11] P. Scalart and J. V. Filho, “Speech Enhancement Based
On a Priori Signal to Noise Estimation,” Proceedings of
IEEE International Conference on Acoustics, Speech
Signal Processing, Atlanta, Vol. 2, May 1996, pp. 629-
632. doi:10.1109/ICASSP.1996.543199
[12] J. E. Porter and S. F. Boll, “Optimal Estimators for Spec-
tral Restoration of Noisy Speech,” Proceedings of IEEE
International Conference on Acoustics, Speech Signal
Processing, Vol. 9, March 1984, pp. 53-56.
[13] I. Cohen, “Optimal Speech Enhancement under Signal
Presence Uncertainty Using Log-Spectral Amplitude Es-
timator,” IEEE Signal Processing Letters, Vol. 9, No. 4,
2002, pp. 113-116. doi:10.1109/97.1001645
[14] A Noisy Speech Corpus for Evaluation of Speech En-
hancement Algorithms, 2011.
http://www.utdallas.edu/~loizou/speech/noizeus/
[15] Y. Hu and P. C. Loizou, “Evaluation of Objective Quality
Measures for Speech Enhancement,” IEEE Transaction
on Audio, Speech and Language Processing, Vol. 16, No.
1, 2008, pp. 229-238. doi:10.1109/TASL.2007.911054
Copyright © 2011 SciRes. JSIP