Intelligent Information Management
Vol.07 No.03(2015), Article ID:56682,13 pages
10.4236/iim.2015.73013
A Novel Approach to Disqualify Datasets Using Accumulative Statistical Spread Map with Neural Networks (ASSM-NN)
Mahmoud Zaki Iskandarani
Faculty of Science and Information Technology, Al-Zaytoonah University of Jordan, Amman, Jordan
Email: m.iskandarani@hotmail.com
Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 30 April 2015; accepted 23 May 2015; published 27 May 2015
ABSTRACT
A novel approach to detect and filter out an unhealthy dataset from a matrix of datasets is developed, tested, and proved. The technique employs a new type of self organizing map called Accumulative Statistical Spread Map (ASSM) to establish the destructive and negative effect a dataset will have on the rest of the matrix if stayed within that matrix. The ASSM is supported by training a neural network engine, which will determine which dataset is responsible for its inability to learn, classify and predict. The carried out experiments proved that a neural system was not able to learn in the presence of such an unhealthy dataset that possessed some deviated characteristics, even though it was produced under the same conditions and through the same process as the rest of the datasets in the matrix, and hence, it should be disqualified, and either removed completely or transferred to another matrix. Such novel approach is very useful in pattern recognition of datasets and features that do not belong to their source and could be used as an effective tool to detect suspicious activities in many areas of secure filing, communication and data storage.
Keywords:
Pattern Recognition, Informatics, Neural Networks, Data Mining, Classification, Prediction, Statistics

1. Introduction
In general, many neural networks applications are concerned with analyzing issues related to pattern recognition by using a supervised training method with training datasets. This will achieve and inference relationship between input patterns and output results [1] - [3] .
Neural Networks offers several algorithms and establishes models using data. Before applying any of the built-in functions for training, it is important to check that the data is reasonable, as good models can be obtained from poor or insufficient data. There is no specific procedure yet that can be used to test the quality or homogeneity and coherence of the data [4] - [6] .
One way to check for quality is to view graphical representations of the data in question in the hope of selecting a reasonable subset while eliminating problematic parts. In examining the data for a classification problem, some reasonable points should be looked at, such as:
a) Equal representation of classes by datasets;
b) The presence of dissimilar datasets from the rest or neighboring values.
In supervised training, parameters such as weights and bias matrices for the neural network are used in order to classify all patterns in the training datasets. Larger training datasets are expected to reduce the overall error and error rate. However, it is a challenging task to produce a neural network that will be able to accommodate all patterns in a large training dataset, due to some patterns are difficult to classify. Even if network layers and neurons are modified, there are still some problems in pattern classification despite the lengthy training process [7] - [10] .
The probability of occurrence of these patterns is expected to increase as a function of the size of the training dataset. Hence, the neural network will fail to recognize a pattern that approximates to one of the misclassified patterns. Also, if a new pattern is employed, which approximates to one of the misclassified patterns in the old training dataset, the neural network will not be able to classify it, and it will become a new misclassified; thus, the error rate will increase [11] -[14] .
In this paper, a new approach catching and isolating such patterns is presented. The approach uses a new Accumulative Statistical Spread Map (ASSM) to initially establish the coherence of the patterns under consideration, and will not cause a misclassification in the neural network, and then when the status is established, the neural structure is used to determine which of the datasets and patterns is causing such misclassification and raising the error rate. Thus, such a neural network structure can be used as a filter and isolator with the Accumulative Statistical Spread Map used to determine which part or parts of the datasets is causing the problem. All the matrices of weights and biases are kept in the order that originally set from the training process throughout the testing process. Moreover, analysis results are used to control the updating process for new patterns.
2. Methodology
Two datasets that belong to the same general parent category are used in the experimental process to prove the concept. Same rules applied to produce the sets; hence, many general common features exist between them. The post processed datasets obtained using the ASSM approach with groups and subgroups produced to show two aspects:
a) If the datasets that the patterns represent belong to the same main group;
b) If there are signs that there will be a conflict in using them together, as one of them has an undesirable effect.
If the result in b is a confirmation, then a neural network algorithm is used to determine which one of the datasets and their patterns is the unhealthy one by carrying out the following steps:
1) Training and testing the considered datasets according to:
a) Dataset 1;
b) Dataset 2;
c) Combined Datasets 1 & 2;
2) Reporting margins of errors covering all three combinations of training;
3) Noticing the pattern that is least affected and classifying it as the unhealthy pattern.
The sorting algorithm is based on the expressions in Equations (1) and (2):
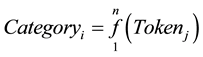 (1)
(1)
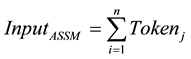 (2)
(2)
where
f: Correlation function between the Tokens;
n: Range of classification;
j: Range of Tokens (in this work j = 4);
The ASSM carries out initial re-organization and sorting by correlation according to Equation (3), before it produces the final output:
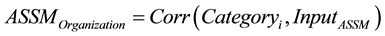 (3)
(3)
3. Results
Table 1 and Table 2 show the used and categorized Datasets 1 and 2. These Datasets are used in the experimental process.

Table 1. Initial categorization results obtained for dataset 1.
Table 2. Initial categorization results obtained for dataset 2.
4. Discussion and Conclusions
Figure 1 and Figure 2 show Accumulative Statistical Spread Map (ASSM) for Datasets 1 and 2. The maps represent the correlated statistical features in both Dataset 1 and Dataset 2 in relation to the sequence numbers assigned to them due to sorting.


Figure 1. ASSM-dataset 1.


Figure 2. ASSM-dataset 2.
From the maps, the following is realized:
1) The concentration of feature spread into the second and fourth quarters of the ASSM (counterclockwise);
2) The similarity in feature spread confirms that the two patterns representing Datasets 1 and 2 derive from similar source with common features.
Each ASSM is processed to produce clustered representation, as shown in Figure 3 and Figure 4, in order to obtain a similar representation to genetic code. This is shown in groups 1 and 2.
Dataset 1 ® {3, 5, 0, 0, 0}, {5, 45, 4, 6, 0}, {0, 4, 1, 2, 1}, {0, 6, 3, 48, 3}, {0, 0, 0, 4, 4} (1)
Dataset 2 ® {5, 3, 0, 0, 0}, {3, 45, 5, 15, 0}, {0, 4, 1, 3, 0}, {0, 14, 2, 46, 6}, {0, 2, 0, 4, 2} (2)
From groups 1 and 2, the following is deduced:
1) The existence of inverted digits (features position swapping) between dataset 1 and dataset 2; Inverted digit values are expected to have a destructive effect on the system learning and classification process;
2) The presence of common features (features of similar value and position);
3) The presence of different features (features of different values in similar positions);
Placing the code groups into matrices 3 and 4 and carrying out row and column summation, shows the following:
1) Each dataset follows an overall mathematical code that is specific to its representational pattern;
2) The symmetrical relationship between each Row and Column of each matrix. This is the result of using ASSM and indicates that both patterns belong to the same process;
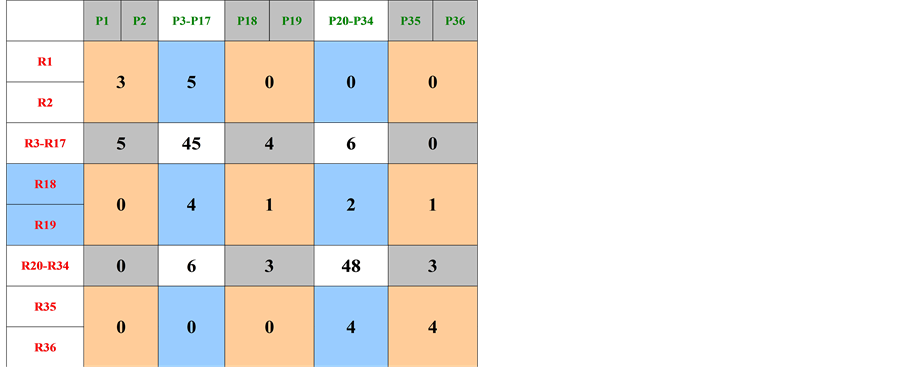
Figure 3. Clustered representation of dataset 1.
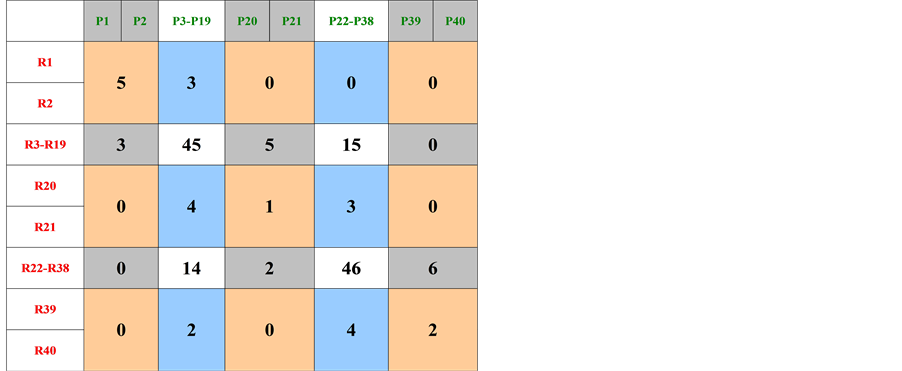
Figure 4. Clustered representation of dataset 2.
3) The difference in the Column values with higher values appearing in Dataset 2 supports the evidence of Dataset 2 capability to overshadow Dataset 1 and negatively affect the overall learning and classification process.
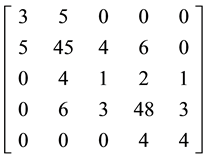 ® Row = {8, 60, 8, 60, 8}, Column = {8, 60, 8, 60, 8} (3)
® Row = {8, 60, 8, 60, 8}, Column = {8, 60, 8, 60, 8} (3)
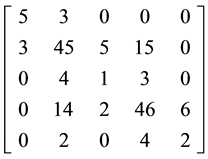 ® Row = {8, 68, 8, 68, 8}, Column = {8, 68, 8, 68, 8} (4)
® Row = {8, 68, 8, 68, 8}, Column = {8, 68, 8, 68, 8} (4)
The previous results indicate the presence of conflicting patterns, where one of them would cause a problem when used with the rest of similar patterns. To uncover the unhealthy pattern responsible for such condition, a back propagation neural algorithm is employed to train and test both datasets.
Table 3 and Table 4 show the results for sorting, categorization, and neural networks training and testing
Table 3. Sorting, training, and testing of dataset 1.
Table 4. Sorting, training, and testing of dataset 2.
results for similarly processed datasets with the neural engine trained using dataset 1 in isolation from dataset 2, and dataset 2 in isolation from dataset 1 with RED Sequential Numbers pointing towards the records with difference between Actual and Desired data, while Table 5 and Table 6 show the results for the same datasets merged and sorted in relation to each other, and presented to the neural engine for training and testing.
From Table 7 and Table 8, it is deduced that Dataset 2 prediction starts with larger initial error, and stays unaffected after merging with Dataset 2 as a training set. For Dataset 1 , the result is almost opposite, as its prediction starts with much smaller error and suffers large error increase after merging with Dataset 2 as a training set. This indicates a marked increase in the level of total pattern destruction and mutation due to effect of Dataset 2. So, Dataset 2 disabled the proper functionality of the Neural Structure and inhibited its performance.
The previous is supported by the following percentage errors appearing in Table 9, where it is clear that Dataset 2 is not affected by Dataset 1, while Dataset 1 is greatly and adversely affected by the presence of Dataset 2.
Table 5. Sorting, training, and testing of dataset 1 merged with dataset 2.
Table 6. Sorting, training, and testing of dataset 2 merged with dataset 1.
Table 7. Margin comparison-dataset 1.
Table 8. Margin comparison dataset 2.
Table 9. Margin change for datasets 1 and 2.
In conclusion, the ASSM proved its capability to detect and filter out undesirable datasets, which would greatly assist optimizing the neural network structure. Such functionality is critical in facilitating both good neural network designs and isolating certain datasets to study their behavior and reach a conclusion regarding the causes behind such abnormalities. The ASSM can be very useful in Health and Medical applications, such as cases where tumors are involved.
References
- Albarado, K., Ledlow, T. and Hartfield, R. (2015) Alternative Analysis Networking: A Multicharacterization Algorithm. Computing in Science & Engineering, 17, 54-63. http://dx.doi.org/10.1109/MCSE.2015.10
- Li, W., Amsaleg, L., Morton, A. and Marchand-Maillet, S. (2015) A Privacy-Preserving Framework for Large-Scale Content-Based Information Retrieval. IEEE Transactions on Information Forensics and Security, 10, 152-167. http://dx.doi.org/10.1109/TIFS.2014.2365998
- Cheng, Q., Zhou, H.B., Cheng, J. and Li, H.Q. (2014) A Minimax Framework for Classification with Applications to Images and High Dimensional Data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36, 2117-2130. http://dx.doi.org/10.1109/TPAMI.2014.2327978
- Xu, J.L., Ramos, S., Vazquez, D. and Lopez, A.M. (2014) Domain Adaptation of Deformable Part-Based Models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36, 2367-2380. http://dx.doi.org/10.1109/TPAMI.2014.2327973
- Thanh, M.N., Wu, Q.M.J. and Zhang, H. (2015) Asymmetric Mixture Model with Simultaneous Feature Selection and Model Detection. IEEE Transactions on Neural Networks and Learning Systems, 26, 400-4008. http://dx.doi.org/10.1109/TNNLS.2014.2314239
- Araujo, A. and Soares, M. (2015) Weights Based Clustering in Data Envelopment Analysis Using Kohonen Neural Network: An Application in Brazilian Electrical Sector. IEEE―Latin American Transactions, 13, 188-194. http://dx.doi.org/10.1109/TLA.2015.7040647
- Sabri, A. (2014) Further Analysis of Stability of Uncertain Neural Networks with Multiple Time Delays. Advances in Difference Equations, 41, 1-16.
- Shabtai, A., Moskovitch, R., Feher, C., Dolev, S. and Elovici, Y. (2012) Detecting Unknown Malicious Code by Applying Classification Techniques on OpCode Patterns. Security Informatics, 1, 1-22. http://dx.doi.org/10.1186/2190-8532-1-1
- Zuech, R., Taghi, T.M. and Wald, R. (2015) Intrusion Detection and Big Heterogeneous Data: A Survey. Journal of Big Data, 2, 1-41. http://dx.doi.org/10.1186/s40537-015-0013-4
- Goyal, R., Chandra, P. and Singh, Y. (2013) Identifying Influential Metrics in the Combined Metrics Approach of Fault Prediction. SpringerPlus, 2, 1-8. http://dx.doi.org/10.1186/2193-1801-2-627
- Bashiri, M., Farshbaf-Geranmayeh, A. and Mogouie, H. (2013) A Neuro-Data Envelopment Analysis Approach for Optimization of Uncorrelated Multiple Response Problems with Smaller the Better Type Controllable Factors. Journal of Industrial Engineering International, 9, 1-10.
- Schiezaro, M. and Pedrini, H. (2013) Data Feature Selection Based on Artificial Bee Colony Algorithm. EURASIP Journal on Image and Video Processing, 2013, 1-8. http://dx.doi.org/10.1186/1687-5281-2013-47
- Chen, J., Takiguchi, T. and Ariki, Y. (2015) A Robust SVM Classification Framework Using PSM for Multi-Class Recognition. EURASIP Journal on Image and Video Processing, 2015, 1-12.
- Dimou, I. and Zervakis, M. (2013) On the Analogy of Classifier Ensembles with Primary Classifiers: Statistical Performance and Optimality. Journal of Pattern Recognition Research, 8, 98-122. http://dx.doi.org/10.13176/11.497