Applied Mathematics
Vol.06 No.03(2015), Article ID:54511,11 pages
10.4236/am.2015.63046
Finding the Asymptotically Optimal Baire Distance for Multi-Channel Data
Patrick Erik Bradley1, Andreas Christian Braun2
1Institute of Photogrammetry and Remote Sensing, Karlsruhe Institute of Technology, Karlsruhe, Germany
2Remote Sensing and Landscape Information Systems, University of Freiburg, Freiburg, Germany
Email: patrick.bradley@kit.edu, andreas.braun@felis.uni-freiburg.de
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 16 February 2015; accepted 6 March 2015; published 10 March 2015
ABSTRACT
A novel permutation-dependent Baire distance is introduced for multi-channel data. The optimal permutation is given by minimizing the sum of these pairwise distances. It is shown that for most practical cases the minimum is attained by a new gradient descent algorithm introduced in this article. It is of biquadratic time complexity: Both quadratic in number of channels and in size of data. The optimal permutation allows us to introduce a novel Baire-distance kernel Support Vector Machine (SVM). Applied to benchmark hyperspectral remote sensing data, this new SVM produces results which are comparable with the classical linear SVM, but with higher kernel target alignment.
Keywords:
p-Adic Numbers, Ultrametrics, Baire Distance, Support Vector Machine, Classification

1. Introduction
The Baire distance was introduced to classification in order to produce clusters by grouping data in “bins” by [1] . In this way, they seek to find inherent hierarchical structure in data defined by their features. Now, if there are many different features associated with data, then it is reasonable to sort the feature vector by some criterion which ranks their contribution to this inherent hierarchical structure. We will see that there is a natural Baire distance associated to any given permutation of features. Hence, it is natural to ask for this task to be performed in reasonable time. In general, there is no efficient way of sorting 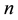 variables, but if the task is to find a per- mutation satisfying some optimality condition, then often a gradient descent algorithm can be applied. In that case, the run-time complexity is decreased considerably.
variables, but if the task is to find a per- mutation satisfying some optimality condition, then often a gradient descent algorithm can be applied. In that case, the run-time complexity is decreased considerably.
In this paper we introduce a permutation-dependent Baire distance for data with 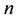 features, and we define a linear cost function depending on the pairwise Baire distances for all possible permutations. The Baire distance we use depends on a parapmeter
features, and we define a linear cost function depending on the pairwise Baire distances for all possible permutations. The Baire distance we use depends on a parapmeter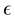 , and we argue that the precise value of this parameter is seldom to be ex- pected of interest. On the contrary, we believe that it practically makes more sense to vary this parameter and to study the limiting case
, and we argue that the precise value of this parameter is seldom to be ex- pected of interest. On the contrary, we believe that it practically makes more sense to vary this parameter and to study the limiting case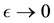 . Our theoretical result is that there is a gradient-descent algorithm which can
. Our theoretical result is that there is a gradient-descent algorithm which can
find the asymptotic minimum for  with a runtime complexity of
with a runtime complexity of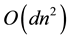 , where
, where 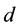 is the number of all data pairs.
is the number of all data pairs.
The Support Vector Machine (SVM) is a well known technique for kernel based classification. In kernel bas- ed classification, the similarity between input data is modelled by kernel functions. These functions are em- ployed to produce kernel matrices. Kernel matrices can be seen as similarity matrices of the input data in reproducing kernel Hilbert spaces. Via optimization of a Lagrangian minimization problem, a subset of input points is found, which is used to produce a separating hyperplane for the data of various classes. The final de- cision function is dependent only on the position of these data in the feature space and does not require esti- mation of first or second order statistics on the data. The user has a lot of freedom on how to produce the kernel functions. This offers the option of producing individual kernel functions for the data.
As an application of our theoretical result, we introduce the new class of Baire-distance kernels which are functions of our parametrized Baire distance. For the asymptotically optimal permutation, the resulting Baire distance SVM yields results comparable with the classical linear SVM on the AVIS Indian Pine dataset. The latter is a well known hyperspectral remote sensing dataset. Furthermore, the kernel target alignment [2] re- presents an a priori quality assessment and favours our new Baire distance multi-kernel SVM constructed from Baire distance kernels at difference feature resolutions. This new multi-kernel combines in a sense our first ap- proach with the approach of [1] , as it combines the different resolutions defined by their method of “bin” grouping. As our preliminary practical result, we obtain greater completeness in many of our clusters than with the classical linear SVM clusters.
2. Ultrametric Distances for Multi-Channel Data
After a short review on the ultrametric parametrized Baire distance, it is shown how to find for 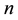 variables their asymptotically optimal permutation for a linear cost function defined by permutation-dependent Baire dis- tances. It has quadratic run-time complexity, if the data size is fixed.
variables their asymptotically optimal permutation for a linear cost function defined by permutation-dependent Baire dis- tances. It has quadratic run-time complexity, if the data size is fixed.
2.1. Baire Distance
Let 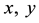 be words over an Alphabet
be words over an Alphabet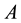 . Then the Baire distance is
. Then the Baire distance is

where 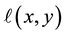 is the length of the longest common initial subword, as depicted in Figure 1. The length of a
is the length of the longest common initial subword, as depicted in Figure 1. The length of a
word is defined as the number of letters from 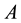 (with multiple occurrences). The reason for choosing
(with multiple occurrences). The reason for choosing  as the basis in the Baire distance is pure arbitrariness, at least to our opinion. Hence,
as the basis in the Baire distance is pure arbitrariness, at least to our opinion. Hence,  can be replaced by any fixed
can be replaced by any fixed 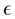 in the interval
in the interval .
.
Definition 2.1. The expression

Figure 1. Two words with common initial subword.

is the  -Baire distance.
-Baire distance.
Later on, we will study the limiting case .
.
Remark 2.2. The metrics  are all equivalent in the sense that they generate the same topologies.
are all equivalent in the sense that they generate the same topologies.
The Baire distance is important for classification, because it is an ultrametric. In particular, the strict triangle inequality

holds true. This is shown to lead to efficient hierarchical classification with good classification results [1] [3] [4] .
Data representation is often related to some choice of alphabet. For instance, the distinction “Low” and “High” leads to  and is used in [4] . The decimal representation of numbers yields
and is used in [4] . The decimal representation of numbers yields  for the method in [1] . A very general encoding with arithmetic flavour is given by subsets
for the method in [1] . A very general encoding with arithmetic flavour is given by subsets  inside the ring of integers inside a
inside the ring of integers inside a  -adic number field
-adic number field , with all
, with all  different modulo
different modulo  [5] . No knowledge of
[5] . No knowledge of  -adic number theory is required for what comes after the following Example 2.3. However, the interested reader may consult [6] for a first application of such mathematics in classification.
-adic number theory is required for what comes after the following Example 2.3. However, the interested reader may consult [6] for a first application of such mathematics in classification.
Example 2.3. The simplest example of  -adic number fields
-adic number fields  in data representation is given by taking
in data representation is given by taking  as the field of 2-adic numbers
as the field of 2-adic numbers . Then
. Then  is the ring of 2-adic integers, and as alphabet
is the ring of 2-adic integers, and as alphabet . The numbers 0.1 represent the finite field
. The numbers 0.1 represent the finite field  in a standard way which is often used when 2-adic numbers are written out as power series in 2, i.e. as finite or infinite binary numbers.
in a standard way which is often used when 2-adic numbers are written out as power series in 2, i.e. as finite or infinite binary numbers.
The role of the parameter  in classification can be described as follows. Let
in classification can be described as follows. Let  be a set of words. Then
be a set of words. Then  defines a unique dendrogram
defines a unique dendrogram , and
, and  defines a metric dendrogram
defines a metric dendrogram .
.
Observe that  depends only on the metric
depends only on the metric . By equivalence of the Baire metrics, dendrograms
. By equivalence of the Baire metrics, dendrograms  are tree-isomorphic for all
are tree-isomorphic for all . However, optimal classification results in general do depend on
. However, optimal classification results in general do depend on , as has been observed in Theorem 2 of [7] , where the result is formulated for
, as has been observed in Theorem 2 of [7] , where the result is formulated for  -adic ultrametrics.
-adic ultrametrics.
2.2. Optimal Baire Distance
Given data  and attributes
and attributes 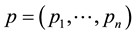 with possible values
with possible values , then a permutation
, then a permutation , where
, where  is the symmetric group of all permutations of the set
is the symmetric group of all permutations of the set , defines the expression
, defines the expression

i.e. a word with letters from the alphabet . This yields the Baire distance
. This yields the Baire distance .
.
In order to determine a suitable permutation for the data, consider the average Baire distance. A high average Baire distance will arise if there is a large number of singletons, and branching is high up in the hierarchy. On the other hand, if there are lots of common initial features, then the average Baire distance will be low. In that case, clusters tend to have a high density, and there are few singletons. From these considerations, it follows that the task is to find a permutation  such that
such that

is minimal, leading to the optimal Baire distance . Any method attempting to fulfil this task must overcome the problem that
. Any method attempting to fulfil this task must overcome the problem that  is quite large for large
is quite large for large .
.
Let , written as
, written as . Expanding
. Expanding  into powers of
into powers of  yields:
yields:
 (1)
(1)
where  is the number of data pairs
is the number of data pairs  with identical values exclusively in the set
with identical values exclusively in the set . The inner sum is taken over the set
. The inner sum is taken over the set
 (2)
(2)
where , and
, and  is the length of the common initial subword with the standard word
is the length of the common initial subword with the standard word  obtained by defining an ordering on any arbitrary alphabet
obtained by defining an ordering on any arbitrary alphabet .
.
Some first properties of  are listed in the following:
are listed in the following:
1.  if
if 
2. 
3. 
4. 
5. 
These properties follow from Equation (2) above, and they imply some first properties of :
:
 (3)
(3)
 (4)
(4)
 (5)
(5)
An important observation is that  depends only on the first
depends only on the first  permuted values
permuted values . This will be exploited in the following section, where it is shown how optimal permutations
. This will be exploited in the following section, where it is shown how optimal permutations  can be computed.
can be computed.
The following two examples list all values of

in the case  for
for . By effecting the permutation
. By effecting the permutation , one obtains the corresponding matrices
, one obtains the corresponding matrices , and summing over the row labelled
, and summing over the row labelled  yields
yields .
.
Example 2.4. Table for  and
and :
:

Example 2.5. Table for  and
and :
:

2.3. Finding Optimal Permutations
Let  be the simplex of
be the simplex of  channels labelled by the set
channels labelled by the set . The faces are given by subsets of
. The faces are given by subsets of  or, equivalently, by elements of the power set
or, equivalently, by elements of the power set .
.
The function

from Equation (1) is to be minimised, where  is a permutation of the set
is a permutation of the set . A combinatorialtopo- logical point of view appears to be helpful in the task. Namely, view the simplex
. A combinatorialtopo- logical point of view appears to be helpful in the task. Namely, view the simplex  as a (combinatorial) simplicial complex. A star of an
as a (combinatorial) simplicial complex. A star of an  -face
-face  is the set of
is the set of  -faces attached to
-faces attached to  with
with  (including
(including  itself). The weak topology on
itself). The weak topology on  is generated by the stars.
is generated by the stars.
To  is associated a graph
is associated a graph  whose vertices are the faces, and an edge is given by a pair
whose vertices are the faces, and an edge is given by a pair  con- sisting of an
con- sisting of an  -face
-face  and an
and an  -face
-face  such that
such that  is a face of
is a face of .
.
The counts  appearing in Equation (1) define a function
appearing in Equation (1) define a function , and this in turn yields weights on
, and this in turn yields weights on  in the following way:
in the following way:
 (6)
(6)
 (7)
(7)
Observe that all edge weights are non-negative:

because . The graph
. The graph  is a directed acyclic graph with origin vertex
is a directed acyclic graph with origin vertex  and terminal vertex
and terminal vertex .
.
An injective path  in
in  has a natural
has a natural  -length
-length

where  is given by the sequence of edges
is given by the sequence of edges .
.
Definition 2.6. A permutation  is said to be compatible with an injective path
is said to be compatible with an injective path , if
, if
 (8)
(8)
where  is given by the sequence of sets
is given by the sequence of sets .
.
Lemma 2.7. If  is compatible with
is compatible with , then
, then

where the path  is given as in Definition 2.6.
is given as in Definition 2.6.
Proof. Let  be an edge on
be an edge on  given by the pair of sets
given by the pair of sets . Then
. Then

Assume that  is compatible with
is compatible with . Then
. Then
 (9)
(9)
from which the assertion follows for  by summation over the edges along
by summation over the edges along . For arbitrary
. For arbitrary  com- patible with
com- patible with  the proof is analogue to this case.
the proof is analogue to this case.
The following is an immediate consequence:
Corollary 2.8. Let , and
, and  compatible with
compatible with . Then
. Then

The minimising  can be found by travelling along a shortest path from
can be found by travelling along a shortest path from  to
to . One method for finding such shortest paths is given by the well known Dijkstra algorithm.
. One method for finding such shortest paths is given by the well known Dijkstra algorithm.
Corollary 2.9. Dijkstra’s shortest path algorithm on  finds the global minima for
finds the global minima for  with any given
with any given .
.
The main problem with applying Corollary 2.9 is the size of  for large
for large . However, we believe that it is of practical interest to consider
. However, we believe that it is of practical interest to consider  for sufficiently small
for sufficiently small . We will show below that in this case, the following gradient descent finds the global minimum in an exhaustive manner. Given an edge
. We will show below that in this case, the following gradient descent finds the global minimum in an exhaustive manner. Given an edge , the expression
, the expression  will denote the origin vertex
will denote the origin vertex , and
, and  means the terminal vertex
means the terminal vertex .
.
Algorithm 2.10. (Gradient descent) Input. .
.
Step 0. Set  and
and .
.
Step 1. Collect in  all edges
all edges  with
with  having smallest weight
having smallest weight , and set
, and set .
.
Step . Collect in
. Collect in  all edges
all edges  with
with  having smallest weight, and set
having smallest weight, and set  .
.
Output. The subgraph of  containing all paths with smallest sum of edge weights from
containing all paths with smallest sum of edge weights from  to
to .
.
This algorithm clearly terminates after  steps. The paths
steps. The paths  correspond bijectively to a set
correspond bijectively to a set  of permutations
of permutations .
.
Lemma 2.11. Let  be a permutation derived from gradient descent,
be a permutation derived from gradient descent,  , and
, and  such that
such that
 is minimal. Then there exists a constant
is minimal. Then there exists a constant  such that for all
such that for all  it holds true that
it holds true that .
.
Proof. We may assume that there exists some  such that
such that
 (10)
(10)
as otherwise  can be chosen. Assume now further that
can be chosen. Assume now further that  be minimal with property (10). Still further, we may assume that there exists some
be minimal with property (10). Still further, we may assume that there exists some  such that
such that
 (11)
(11)
as otherwise  could not be derived by gradient descent. The reason is that at step
could not be derived by gradient descent. The reason is that at step  that method would descend down to
that method would descend down to  instead of to
instead of to , since
, since  is the first occurrence of property (10). Let now
is the first occurrence of property (10). Let now  be minimal with (11). All this implies that
be minimal with (11). All this implies that

is a polynomial with real coefficients such that . Hence, by continuity of
. Hence, by continuity of , there exists a small neighbourhood of 0 on which
, there exists a small neighbourhood of 0 on which  is still positive. This neighbourhood defines the desired constant
is still positive. This neighbourhood defines the desired constant .
.
An immediate consequence of the lemma is that gradient descent is asymptotically the method of choice:
Theorem 2.12. There exists a constant  such that gradient descent on
such that gradient descent on  finds a global minimum for the cost function
finds a global minimum for the cost function  whenever
whenever .
.
Proof. Let  be the set of all
be the set of all  for which
for which  is minimal with some fixed
is minimal with some fixed . Then
. Then  has the desired property.
has the desired property.
The competitiveness of the gradient descent method is manifest in the following Remarks:
Remark 2.13. Algorithm 2.10 is of run-time complexity at most .
.
Proof. In the first step, there are  choices for possible edges to follow, and after
choices for possible edges to follow, and after  steps the possible permutations are found. Finding the minimal edge in step
steps the possible permutations are found. Finding the minimal edge in step  can be done with complexity
can be done with complexity . This proves the upper bound.
. This proves the upper bound.
Notice that the efficiency holds only for the case that the weights  of
of  are already given. However, this cannot be expected in general. Therefore, we investigate here the computational cost for
are already given. However, this cannot be expected in general. Therefore, we investigate here the computational cost for  for a gra- dient descent path
for a gra- dient descent path  in
in . The following is immediate:
. The following is immediate:
Lemma 2.14. Let . Then
. Then  is a (combinatorial) simplex of dimension
is a (combinatorial) simplex of dimension .
.
We will write  for the simplex coming from an edge
for the simplex coming from an edge  as in Lemma 2.14. An immediate consequence is
as in Lemma 2.14. An immediate consequence is
 (12)
(12)
the computation of which seems at first sight exponential in the dimension of . In particular, the weights of the
. In particular, the weights of the  very first edges
very first edges  look to be very cumbersome to compute. The problem is the function
look to be very cumbersome to compute. The problem is the function
 with its computational cost
with its computational cost  for each
for each , where
, where . Slightly more efficient is the function
. Slightly more efficient is the function

which counts all pairs  on which the channels in
on which the channels in  coincide. A trivial, but important observation is
coincide. A trivial, but important observation is
 (13)
(13)
as this allows to define a nice way of computing the weight :
:
Lemma 2.15. Let  be a vertex. Then for any edge
be a vertex. Then for any edge  with origin
with origin  and terminus
and terminus  it holds true that
it holds true that

Proof. This is an immediate consequence of the identity

which follows from Lemma 2.14.
Assume now that we are given for each pair  the subset
the subset  on which
on which  and
and  coincide. Let
coincide. Let  be the set of all pairs, and
be the set of all pairs, and . Then define for
. Then define for  the set of pairs
the set of pairs

and its corresponding cardinality

together with the conventions

Then the identity
 (14)
(14)
is immediate. Its usefulness is that the right hand side is computed more quickly than the left hand side:
Lemma 2.16 The cost of  is at most
is at most .
.
Proof. Take each  and check coincidence of each
and check coincidence of each  in channel
in channel .
.
Algorithm 2.17 Input. ,
,  ,
,  ,
, .
.
Step 1. Find minimal edge  with
with
 (15)
(15)
minimal. Set ,
,  ,
, .
.
Step . Repeat Step 1 with current values of
. Repeat Step 1 with current values of  and
and , if both sets are non-empty. Set
, if both sets are non-empty. Set  with current value of
with current value of .
.
Output. Path  for some
for some .
.
Theorem 2.18 Algorithm 2.17 has run-time complexity at most .
.
Proof. The complexity in Step  is at most
is at most  for
for  with the
with the  being the
being the  at that step. The reason is that, according to (15) and Lemma 2.16,
at that step. The reason is that, according to (15) and Lemma 2.16,  has complexity
has complexity , and there are
, and there are
 edges going out of vertex
edges going out of vertex . Bounding the cardinalities of
. Bounding the cardinalities of  by
by  from above, and summing the costs yields the desired bound
from above, and summing the costs yields the desired bound .
.
Notice that the constant  of Theorem 2.12 can be very close to zero. That would mean that the gradient descent method yields only a local minimum for most values of
of Theorem 2.12 can be very close to zero. That would mean that the gradient descent method yields only a local minimum for most values of . However, we believe that there is no poly- nomial-time algorithm which finds a minimum which is global for all
. However, we believe that there is no poly- nomial-time algorithm which finds a minimum which is global for all , or at least for all
, or at least for all  below a pre- described threshold.
below a pre- described threshold.
3. Combining Ultrametrics with SVM
Within this section the potential of integrating ultrametrics into state-of-the art classifiers―the Support Vector Machine (SVM) as introduced by [8] ―is presented. SVM has been intensely applied for classification tasks in remote sensing and several methodological comparisons have been established in previous work of the authors [9] [10] . At first, our methodology is outlined. Secondly, a classification result for a standard benchmark from hyperspectral remote sensing is shown.
3.1. Methodology
Kernel matrices are the representation of similarity between the input data used for SVM classification. To integrate ultrametrics into SVM classification the crucial step is therefore to create a new kernel function [11] [12] . Instead of representing the Euclidean distance between input data, this new kernel function represents the Baire distance between them. To have an optimal kernel based on the Baire distance, at first an optimal per- mutation  is found as outlined in Section 2.3 by using Algorithm 2.17. The new kernel is thus given as
is found as outlined in Section 2.3 by using Algorithm 2.17. The new kernel is thus given as
 (16)
(16)
where  for some choice of
for some choice of  sufficiently small, and we call it a Baire distance kernel.
sufficiently small, and we call it a Baire distance kernel.
This new kernel function could be used for classification directly. However, one feature of kernel based classification is that multiple kernel functions can be combined to increase classification performance [13] . The Baire distance is dependent on the resolution (bitrate) of the data. Two very similar features will maintain a large  -value at high bit depths, while the value of
-value at high bit depths, while the value of  of less similar features will deteriorate at higher bit-rates. Thus, by varying the bit depth of the data, one obtains additional information about the similarity of the data. Therefore, a kernel is to be created which incorporates the information about similarity at each resolution. At first, data with 8-bit depth are used. An optimal
of less similar features will deteriorate at higher bit-rates. Thus, by varying the bit depth of the data, one obtains additional information about the similarity of the data. Therefore, a kernel is to be created which incorporates the information about similarity at each resolution. At first, data with 8-bit depth are used. An optimal  is computed as described in Section 2.3. Afterwards, a kernel
is computed as described in Section 2.3. Afterwards, a kernel  is computed, which includes the Baire distance between features for the given
is computed, which includes the Baire distance between features for the given  at 8 bit. In the next step, data are compressed to 7-bit depth. Again, an optimal
at 8 bit. In the next step, data are compressed to 7-bit depth. Again, an optimal  is found, a new kernel is computed and the kernels are summed up. For bit depths
is found, a new kernel is computed and the kernels are summed up. For bit depths  kernels are computed and summed to the multiple Kernel
kernels are computed and summed to the multiple Kernel .
.
 (17)
(17)
This multiple kernel also belongs to the new class of Baire distance kernels and has the advantage of in- corporating the similarity at different bit depths. It is compared against the standard linear kernel frequently used for SVM:
 (18)
(18)
where the bracket  denotes the standard scalar product on the Euclidean space into which the data is mapped.
denotes the standard scalar product on the Euclidean space into which the data is mapped.
3.2. Application
Within this section, a comparison on a standard benchmark dataset from hyperspectral remote sensing is presented, cf. also [14] . The AVIRIS Indian Pines dataset consists of a  pixel hyperspectral image with 220 spectral channels (Figure 2). It is well known due to the complexity of the classification problem it represents. The 16 land use classes consisting mainly of crop classes are to be separated. These are difficult to separate since they are spectrally very similar (due to the early phenological stage of the vegetation).
pixel hyperspectral image with 220 spectral channels (Figure 2). It is well known due to the complexity of the classification problem it represents. The 16 land use classes consisting mainly of crop classes are to be separated. These are difficult to separate since they are spectrally very similar (due to the early phenological stage of the vegetation).
Although our implementation of Algorithm 2.17 is capable to process 220 features, only the first six principal components are considered. The reason is that there are two sources of coincidences. The first is coincidence due to spectral similarity of land cover classes (signal), the second is coincidence due to noise. For this work, only the coincidence of signal is relevant. Since the algorithm is not fit to distinguish between the two sources, only the six first principal components are considered relevant. They explain 99.66% of the sum of eigenvalues and are therefore believed to contribute considerably to coincidences due to signal and only marginally to coincidence due to noise.
At first, the dataset is classified with a linear kernel SVM as given in Equation (18). A visual result can be seen in Figure 3 (left). The overall accuracy yielded is 53.5% and the  -coefficient is 0.44. As can be seen, the dataset requires more complex kernel functions than linear ones. Then, a multiple kernel
-coefficient is 0.44. As can be seen, the dataset requires more complex kernel functions than linear ones. Then, a multiple kernel  of the form (16) is computed as described in Section 3.1. The dataset is again classified using an SVM, and a visual result can be seen in Figure 3 (right). The overall accuracy yielded is 53.7% and the
of the form (16) is computed as described in Section 3.1. The dataset is again classified using an SVM, and a visual result can be seen in Figure 3 (right). The overall accuracy yielded is 53.7% and the  -coefficient is 0.45.
-coefficient is 0.45.

Figure 2. Hyperspectral image.

 (a) (b)
(a) (b)
Figure 3. (a) Linear SVM; (b) Multi-Baire-kernel SVM.
The overall accuracy is the percentage of correctly classified pixels from the reference data. The  -co- efficient is a statistical measure of the agreement, beyond chance, between the algorithm’s results and the manual labelling in the reference data. Both are global measurements of performance.
-co- efficient is a statistical measure of the agreement, beyond chance, between the algorithm’s results and the manual labelling in the reference data. Both are global measurements of performance.
As can be seen, both results have a lot of resemblance in the major part. However, the result produced with the linear kernel tends to confuse the brown crop classes in the north with green pasture classes. On the other hand, the linear kernel SVM better recognizes the street in the Western part of the image.
The kernel target alignment between these kernels and the ideal kernel

was computed. The ideal kernel is defined via the label  associated to each pixel, and has value 1 if the labels coincide, otherwise its value is zero. Note that the kernel target alignment proposed by [2] represents an a-priori quality assessment of a kernel’s suitability. It is defined as
associated to each pixel, and has value 1 if the labels coincide, otherwise its value is zero. Note that the kernel target alignment proposed by [2] represents an a-priori quality assessment of a kernel’s suitability. It is defined as

where

denotes the usual scalar product between Gram matrices.
The kernel target alignment takes values in the interval  with one being the best. The kernel target alignment of
with one being the best. The kernel target alignment of  was 0.37. The
was 0.37. The  yielded a higher alignment of 0.47 thus giving reason for expecting a higher overall performance of the latter. The producers’ accuracies
yielded a higher alignment of 0.47 thus giving reason for expecting a higher overall performance of the latter. The producers’ accuracies  and users’ accuracies
and users’ accuracies  for the individual classes are shown in Table 1 and Table 2.
for the individual classes are shown in Table 1 and Table 2.
The users’ accuracy shows what percentage of a particular ground class was correctly classified. The pro- ducers’ accuracy is a measure of the reliability of an output map generated from a classification scheme which tells what percentage of a class truly corresponds to a class in the reference. Both are local (i.e. class-dependent) measurements of performance.

Table 1. Hyperspectral image (channels R:25, G:12, B:1).
Table 2. Hyperspectral image (continued).
As had to be expected, each classification approach outperformed the other for some classes. The approach based on  yields higher producers’ accuracy values than
yields higher producers’ accuracy values than  in seven cases. For five cases,
in seven cases. For five cases,  is su- perior. For users’ accuracy,
is su- perior. For users’ accuracy,  is superior in five cases,
is superior in five cases,  in eight cases.
in eight cases.
Since producers’ accuracy outlines which amount of pixels from the reference are found in the classification (completeness) while users’ accuracy outlines which amount of the pixels in one class are correct, it can be concluded, that the proposed approach produces more complete results for many classes than with the standard linear kernel approach. Of course, due to the low overall accuracy values yielded, the approach should be ex- tended by applying e.g. Gaussian functions over the similarity matrices.
4. Conclusion
Finding optimal Baire distances defined by permutations of  variables can be done in quadratic time, if the data size is fixed and a gradient descent algorithm is used. For the Baire distance parametrised by the base
variables can be done in quadratic time, if the data size is fixed and a gradient descent algorithm is used. For the Baire distance parametrised by the base , this becomes the global minimum if
, this becomes the global minimum if  is sufficiently small. In practice the outcome will be not a unique permutation, but a more or less large set
is sufficiently small. In practice the outcome will be not a unique permutation, but a more or less large set  of optimal permutations
of optimal permutations . The
. The  can be viewed in a natural way as words over some alphabet. This implies that the symmetric group
can be viewed in a natural way as words over some alphabet. This implies that the symmetric group  of the
of the  variables has a well- defined dendrogram
variables has a well- defined dendrogram  in which we can view
in which we can view  as a cluster. The common initial word
as a cluster. The common initial word  of
of  de- fines a ranking of
de- fines a ranking of  of the variables which we conjecture to contain the most relevant inherent hierarchical information of the dataset
of the variables which we conjecture to contain the most relevant inherent hierarchical information of the dataset , after removing variables with very small variation. We expect further hierarchical information about
, after removing variables with very small variation. We expect further hierarchical information about  by finding optimal classifications of
by finding optimal classifications of  with respect to the ultrametric defined by its dendrogram
with respect to the ultrametric defined by its dendrogram . Apart from theoretically providing an algorithm which finds the optimal permutation, the applicability of the methodology was demonstrated. To this end, an initial experiment to in- tegrate the Baire distance into state-of-the-art SVM classification is provided. By defining a new multiple kernel function based on Baire distances, classification accuracy on a benchmark dataset is increased. This finding emphasizes the usefulness of the optimal Baire distance in classification. In future work, Gaussian kernels based on the Baire distance will be studied. Furthermore, unsupervised classification algorithms using the permu- tation-dependent ultrametrics will be dealt with in future work.
. Apart from theoretically providing an algorithm which finds the optimal permutation, the applicability of the methodology was demonstrated. To this end, an initial experiment to in- tegrate the Baire distance into state-of-the-art SVM classification is provided. By defining a new multiple kernel function based on Baire distances, classification accuracy on a benchmark dataset is increased. This finding emphasizes the usefulness of the optimal Baire distance in classification. In future work, Gaussian kernels based on the Baire distance will be studied. Furthermore, unsupervised classification algorithms using the permu- tation-dependent ultrametrics will be dealt with in future work.
Acknowledgements
This work has grown out of a talk given at the International Conference on Classification (ICC 2011) and the discussions afterwards. The first author is funded by Deutsche Forschungsgemeinschaft (DFG), and the second author by the Deutsches Zentrum für Luft-und Raumfahrt e.V. (DLR). Thanks to Fionn Murtagh, Roland Glantz, and Norbert Paul for valuable conversation, as well as Fionn Murtagh and David Wishart for the organising of the International Conference on Classification (ICC 2011) in Saint Andrews, Scotland. The article processing charge was funded by the German Research Foundation (DFG) and the Albert Ludwigs University Freiburg in the funding programme Open Access Publishing.
Cite this paper
Patrick ErikBradley,Andreas ChristianBraun, (2015) Finding the Asymptotically Optimal Baire Distance for Multi-Channel Data. Applied Mathematics,06,484-495. doi: 10.4236/am.2015.63046
References
- 1. Contreras, P. and Murtagh, F. (2010) Fast Hierarchical Clustering from the Baire Distance. In: Locarek-Junge, H. and Weighs, C., Eds., Classification as a Tool for Research, Springer Berlin Heidelberg, Germany, 235-243.
http://dx.doi.org/10.1007/978-3-642-10745-0_25 - 2. Cristianini, N., Shawe-Taylor, J., Elisseeff, A. and Kandola, J. (2006) On Kernel Alignment. In: Holmes, D.E., Ed., Innovations in Machine Learning, Springer Berlin Heidelberg, Germany, 205-256.
- 3. Murtagh, F. (2004) On Ultrametricity, Data Coding, and Computation. Journal of Classification, 21, 167-184.
http://dx.doi.org/10.1007/s00357-004-0015-y - 4. Benois-Pineau, J., Khrennikov, A.Y. and Kotovich, N.V. (2001) Segmentation of Images in p-Adic and Euclidean Metrics. Doklady Mathematic, 64, 450-455.
- 5. Bradley, P.E. (2010) Mumford Dendrograms. The Computer Journal, 53, 393-404.
http://dx.doi.org/10.1093/comjnl/bxm088 - 6. Bradley, P.E. (2008) Degenerating Families of Dendrograms. Journal of Classification, 25, 27-42.
http://dx.doi.org/10.1007/s00357-008-9009-5 - 7. Bradley, P.E. (2009) On p-Adic Classification. p-Adic Numbers, Ultrametric Analysis, and Applications, 1, 271-285.
- 8. Cortes, C. and Vapnik, V. (1995) Support-Vector Networks. Machine Learning, 20, 273-297.
http://dx.doi.org/10.1007/BF00994018 - 9. Braun, A.C. (2010) Evaluation of One-Class SVM for Pixe-Based and Segment-Based Classification in Remote Sensing. International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 38, 160-165.
- 10. Braun, A.C., Weidner, U., Jutzi, B. and Hinz, S. (2011) Integrating External Knowledge into SVM Classification—Fusing Hyperspectral and Laserscanning Data by Kernel Composition. In: Heipke, C., Jacobsen, K., Rottensteiner, F., Müller, S. and Sörgel, U., Eds., High-Resolution Earth Imaging for Geospatial Information, International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 38, Part 4/W19 (on CD).
- 11. Amari, S. and Wu, S. (1999) Improving Support Vector Machine Classifiers by Modifying Kernel Functions. Neural Networks, 12, 783-789.
http://dx.doi.org/10.1016/S0893-6080(99)00032-5 - 12. Braun, A.C., Weidner, U., Jutzi, B. and Hinz, S. (2012) Kernel Composition with the One-against-One Cascade for Integrating External Knowledge into SVM Classification. Photogrammetrie-Fernerkundung-Geoinformation, 2012, 371-384.
http://dx.doi.org/10.1127/1432-8364/20/0124 - 13. Sonnenburg, S., Rätsch, G., Schäfer, C. and Schölkopf, B. (2006) Large Scale Multiple Kernel Learning. The Journal of Machine Learning Research, 7, 1531-1565.
- 14. Braun, A.C., Weidner, U. and Hinz, S. (2010) Support Vector Machines for Vegetation Classification? A Revision. Photo-grammetrie-Fernerkundung-Geoinformation, 2010, 273-281.
http://dx.doi.org/10.1127/1432-8364/2010/0055