Wireless Engineering and Technology
Vol.2 No.2(2011), Article ID:4544,10 pages DOI:10.4236/wet.2011.22010
Error Resilient IPTV for an IEEE 802.16e Channel
![]()
University of Essex, Colchester, United Kingdom.
Email: {lamoha, fleum, ghan}@essex.ac.uk
Received October 27th, 2010; revised February 23rd, 2011; accepted February 26th, 2011.
Keywords: IEEE 802.16, IPTV, mobile TV, rateless channel coding, redundant slices, WiMAX
ABSTRACT
Data-partitioning of IPTV video streams is a way of providing graceful quality degradation in a form that will work in good and difficult wireless channel conditions, as experienced by mobile devices. This paper’s proposal is to combine redundant slice protection along with an adaptive channel coding scheme that is also proposed in the paper. Adaptive channel coding is achieved by retransmission when necessary of additional redundant data to reconstruct corrupted packets. In the proposal, outright packet loss is provided for by a form of redundant slice protection. The paper finds that it is preferable: not to simply protect only the highest priority packets; that a moderate quantization level should be employed; and that video quality is differentiated by content type. It is important also to configure the partitioning correctly to remove inter-partition dependencies when possible.
1. Introduction
This paper proposes an error-resilience scheme for video streaming over a wireless access network with application to Internet Protocol TV (IPTV). The scheme combines data-partitioning as a form of error resilience with the addition of forward error correction (FEC) using rateless channel coding at the application layer together with retransmission of extra redundant data when required. Thus, the solution offered by this paper’s proposal is source-coded error resilience measures [1] which are employed in combination with adaptive rateless channel coding [2].
However, it is the adaptive channel coding system not the use of rateless coding in itself that is the contribution. In the proposal, adaptive channel coding is achieved dynamically by only sending enough redundant data to match the measured channel conditions. In addition, retransmission of extra redundant data occurs when necessary, as described in Section 3. As these measures are still insufficient if outright packet losses occur, the proposal further includes redundant slices which are transmitted alongside the original video stream. Outright packet losses can either arise because a packet is lost outright before reaching the receiver, as might occur as a result of entering a deep fade, or because a packet is dropped as a result of overflow at the base station’s send buffer. This then is the reason why the paper further proposes combining the aforesaid measures with redundant slice protection.
By way of comparison in [3], for multicast video stream distribution over the wired Internet, FEC was combined with stream replication. In this scalable video scheme [3], stream replication took place at each of the quality layers. The main motivation was that, because of packet loss, if insufficient FEC-bearing packets arrived at the receiver then sending these packets will have been in vain. Because of the multi-layered form of the video stream, the paper [3] concentrated on ways to optimize the mixture of FEC provision and stream replication. However, that paper differs from our one not just in the setting (it is not a wireless system) but in the goal of avoiding feedback.
In [3], as multicast distribution occurs, feedback is not allowed because of the risk of a feedback implosion. In the current paper, rateless coding is used specifically to allow a single request for additional redundant data. This is possible because the proposed protection system is intended for unicast distribution of Internet Protocol TV (IPTV) and because an IEEE 802.16e link, over which the system is demonstrated, represents a low-delay feedback channel by virtue of the time division duplex frames used.
In fact, application-layer FEC, in addition to physical layer protection, has been found necessary [4] for a number of error-prone network environments, because of the stringent anticipated requirements for IPTV [5]. The Digital Video Broadcast (DVB) project has specified [6] optional application-layer rateless coding, though not adaptive as herein. Similarly, 3GPP have also specified a scheme [7], though again not an adaptive coding scheme.
Our proposal may appear to contradict Shannon’s work on the separation of source from channel coding but as pointed out in [8], there are many practical situations, especially in the challenging area of video streaming across wireless links, where a combination of the two is necessary. Similarly, under some restricted conditions, according to Shannon [9], feedback does not necessarily improve the performance but nevertheless feedback can be justified when there is: a high risk of transmission errors; a need to achieve relatively high bit-rates for reasonable video quality; and/or error sensitive predictive coding is used.
IPTV is anticipated to be a key application of broadband wireless access networks such as IEEE 802.16e (mobile WiMAX) [10]. IPTV services include: live TV programs with or without interactivity; video-on-demand unrelated to the streaming of TV programs; as well as streaming of time-shifted TV programs [11]; the latter two of which certainly require unicast streaming.
Capacity studies for WiMAX [12] suggest up to 16 mobile TV users per cell in a “lossy” channel depending on factors such as the form of scheduling and whether Multiple Input Multiple Output (MIMO) is activated. The emerging IEEE 802.16m variant [13] is likely to further increase the capacity available for IPTV services, along with a corresponding improvement in device sophistication.
However, error bursts can still disrupt a fragile compressed bitstream, because of the source-coding data dependencies, which arise both from motion-compensated prediction and entropy coding within the codec. Consequently, sports scenes with high temporal complexity or those news scenes in which there is a high-spatial coding complexity are at risk, because of larger packet sizes and because of the difficulty of reconstructing pictures when prior or neighboring data are missing.
The paper now outlines the data-partitioning background in more detail in Section 2. Section 3 details the proposed adaptive rateless coding scheme for a datapartitioned compressed video stream. Section 4 describes the simulation model employed in the experimental results of Section 5. In Section 5, the proposed scheme is tested with the addition of redundant slice packets, using different levels of redundancy to gauge the impact. Also included in Section 5 are the results of applying a technique to separate out residual dependencies between the data-partitions. Finally, Section 6 makes some concluding remarks.
2. Error Resilience Methods
The H.264/AVC (Advanced Video Coding) codec standard [14] includes three main forms of error resilience: Flexible Macroblock Ordering (FMO) [15]; data-partitioning [16]; and redundant picture slices [17]. FMO allows the macroblocks (MBs) to be rearranged so that one picture slice (a unit of entropy coding synchronization) can aid the error concealment of another. However, in transmitting the FMO mapping there is some overhead, depending on the FMO type. Data-partitioning involves at the slice level the rearrangement of the compressed bitstream according to the reconstruction priority of the data components. There is less overhead than FMO and, hence, data-partitioning can operate during favorable channel conditions as well as unfavorable channel conditions.
On the other hand, redundant pictures slices should be turned off during favorable channel conditions as their transmission involves a significant overhead. To aid in the estimation of channel conditions, the IEEE 802.16e standard [10] specifies that a station should provide channel measurements, which can either be Received Signal Strength Indicators or may be Carrier-to-Noiseand-Interference Ratio measurements made over modulated carrier preambles. Therefore, to aid in this process the proposed method assumes one of these methods is implemented. However, further investigation of channel condition estimation is beyond the focus of this paper, as the subject has many technicalities.
2.1. Data-Partitioning
In H.264/AVC data partitioning, motion vectors (MVs) are packed into a partition-A packet, allowing motioncopy error concealment to partially reconstruct a picture despite missing partition-C packets containing texture data (quantized transform coefficient residuals). Partition-B slices contain intra-coded (spatially encoded) MBs which are substituted for inter-coded MBs according to encoder implementation (only the decoder input format is standardized in H.264/AVC).
To reduce processing complexity at the device, it is possible to specify the distribution of intra-refresh MBs across the video picture sequence. This arrangement avoids the rapid increases in data rate that result from intra-refresh through periodic I-pictures, which can be a problem for fixed capacity wireless links. The increase in data rates also results in increased buffering delay when I-pictures are sent. Gradual decoder refresh is possible, allowing channel swapping at suitable intervals, though this has not been implemented in this paper as it requires signaling to the server when channel swapping is feasible (under intra-refresh). The result of intra-refresh MB provision leads to a moderate increase in partition-B size.
The H.264/AVC codec conceptually separates the Video Coding Layer (VCL) from the Network Abstraction Layer (NAL). The VCL specifies the core compression features, while the NAL supports delivery over various types of network. Table 1 is a summarized list of different NAL unit types. NAL units 1 to 5 contain different VCL data that will be described later. NAL units 6 to 12 are non-VCL units containing additional information such as parameter sets and supplemental information. NAL units are then encapsulated in Real-Time Protocol (RTP) packets, as is normal for Internet video communication.
In the H.264/AVC codec, each video picture can be divided into one or more independently decodable slices; each of which contains a flexible number of MBs. The slices of an Instantaneous Decoding Refresh- (IDR-) or I-picture (i.e. a picture with all intra slices) are located in type 5 NAL units, while those belonging to a non-IDR picture (IP- or B-pictures [18]) are placed in NAL units of type 1, and in types 2 to 4 when data-partitioning mode is active, as now explained in more detail.
In type 1 NALs, MB addresses, MVs and the Discrete Cosine Transform (DCT) coefficient residuals of the encoding blocks, are packed into a packet, in the order they are generated by the encoder. In type 5, all parts of the compressed bitstream are equally important, while in type 1, the MB addresses and MVs are much more important than the DCT coefficients. Notice also that H.264/AVC to prevent reconstruction problems associated with floating-point representation makes use of an integer transform version of the DCT.
In H.264/AVC when data partitioning is enabled, every slice can be divided into three separate partitions and each partition is located in either of type-2 to type-4 NAL units, again as listed in Table 1. A NAL unit of type 2, also known as partition-A, comprises the most important information of the compressed video bitstream of Pand B-pictures, including the MB addresses, MVs,
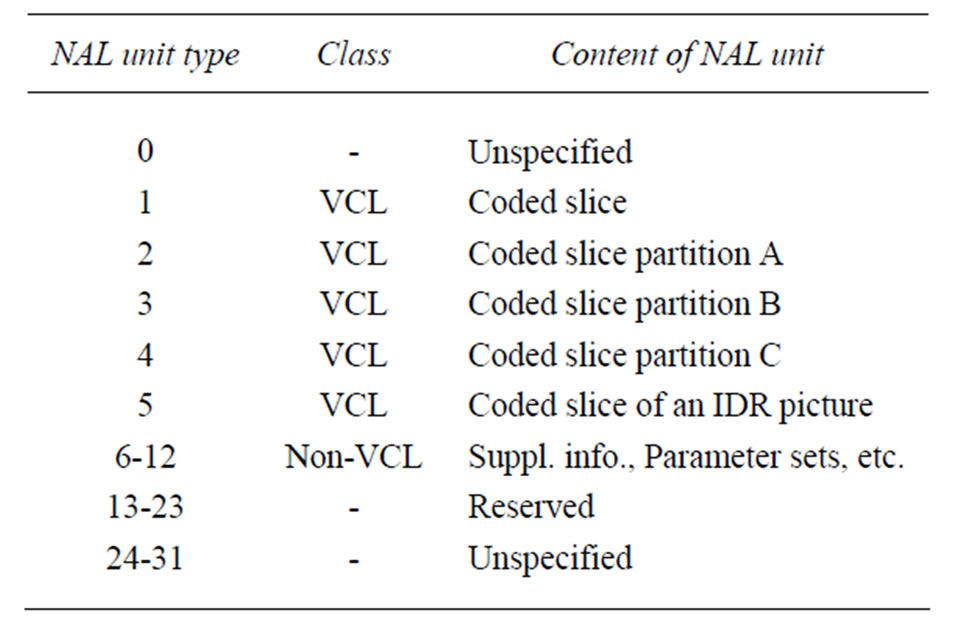
Table 1. NAL unit types.
and essential headers. If any MBs in these pictures are intra-coded, their DCT coefficients are packed into the type-3 NAL unit, also known as partition-B. Intra-coded MBS will occur either because they have been generated at intra-refresh MBs or because the encoder has sought to improve the resulting video quality by including some naturally encoded intra-coded MBs. Type 4 NAL, also known as partition-C, carries the (integer) DCT coefficients of the motion-compensated inter-picture coded MBs.
In order to decode partitions-B and -C, the decoder must know the location from which each MB was predicted, which implies that partitions B and C cannot be reconstructed if partition-A is lost. Though partition-A is independent of partitions B and C, Constrained Intra Prediction (CIP) should be set in the codec configuration [19] to make partition-B independent of partition-C. By setting this option, partition-B MBs are no longer predicted from neighboring inter-coded MBs. This is because the prediction residuals from neighboring inter-coded MBs reside in partition-C and cannot be accessed by the decoder if a partition-C packet is lost. There is a by-product of CIP in increasing packet sizes due to a reduction in compression efficiency but the increase in size may be justified in error-prone environments.
There is another dependency [19] arising from Context-Adaptive VLC (CAVLC) entropy coding, because the number of non-zero coefficients in one MB are predicted from the number of such coefficients in a neighboring MB. By design, setting CIP also results in setting the number of non-zero coefficients in data-partitioned inter-coded MBs to zero when CAVLC is in operation to code intra-coded MBs. Thus, partition-B can be made independent of partition-C. It is not possible to employ the alternative Context Adaptive Binary Arithmetic Coding (CABAC), as this option is not supported in the Extended profile of H.264/AVC, though this is the only profile in which data-partitioning is supported. As CAVLC still predicts from intra-coded MBs when coding partition-C’s inter-coded MBs, partition-C cannot normally be made independent of partition-B. However, the use of CAVLC is not a penalty of the scheme, as CABAC results in approximately 15% more computation than CAVLC, which is a drain on the battery of a mobile device and a challenge to the less powerful processors generally employed on these devices. The coding gain from using CABAC rather than CAVLC is around 5% - 10%.
3. Proposed FEC Protection Scheme
The basis of the proposed FEC protection of data-partitioned video scheme is rateless coding, which is employed in an adaptive manner by retransmission of additional redundant data as and when it is required. Raptor coding [20] is a systematic variety of rateless code that does not share the high error floors [21] of prior rateless codes. It also has O(n) decode computational complexity. Rateless codes are a probabilistic channel code in the sense that reconstruction is not guaranteed.
In order to model Raptor coding, we employed the following statistical model [22]:
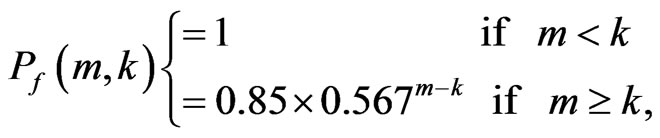 (1)
(1)
where 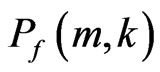 is the failure probability of the code with k source symbols if m symbols have been received. Notice that the authors of [22] remark and show that for k > 200 the model almost perfectly models the performance of the code. In the experiments reported in this paper, the symbol size was set to bytes within a packet. Clearly, if instead 200 packets are accumulated before the rateless decoder can be applied (or at least equation (1) is relevant) there is a penalty in start-up delay for the video stream and a cost in providing sufficient buffering at the mobile stations.
is the failure probability of the code with k source symbols if m symbols have been received. Notice that the authors of [22] remark and show that for k > 200 the model almost perfectly models the performance of the code. In the experiments reported in this paper, the symbol size was set to bytes within a packet. Clearly, if instead 200 packets are accumulated before the rateless decoder can be applied (or at least equation (1) is relevant) there is a penalty in start-up delay for the video stream and a cost in providing sufficient buffering at the mobile stations.
To establish the behavior of rateless coding under WiMAX the ns-2 simulator was augmented with a module from the Chang Gung University, Taiwan [23] that has proved an effective way of modeling IEEE 802.16e’s behavior. Ten runs per data point were averaged (arithmetic mean) and the simulator was first allowed to reach steady state before commencing testing.
We introduced a two-state Gilbert-Elliott channel model [24] in the physical layer of the simulation to simulate the channel model for WiMAX. To model the effect of slow fading at the packet-level, the PGG (probability of being in a good state) was set to 0.95, PBB (probability of being in a bad state) = 0.96, PG (probability of packet loss in a good state) = 0.02 and PB (probability of packet loss in a bad state) = 0.01 for the Gilbert-Elliott parameters.
Additionally, it is still possible for a packet not to be dropped in the channel but, nonetheless, to be corrupted through the effect of fast fading (or other sources of noise and interference). This byte-level corruption was modeled by a second Gilbert-Elliott model, with the same parameters (applied at the byte level) as that of the packet-level model except that PB (probability of byte loss) was increased to 0.165. The main intention of the use of this twofold Gilbert-Elliott model was to show the response of the protection scheme to both types of fading. The Gilbert-Elliott scheme, though it is simple, has been widely adopted [25], as it is thought to realistically model the error bursts that do occur and, more significantly, can be particularly damaging to compressed video streams, because of the predictive nature of source coding. Therefore, the impact of error bursts should be assessed [26] in video streaming applications.
In the proposed adaptive scheme, the probability of channel byte loss through slow fading (PL) in the Gilbert-Elliott model serves to predict the amount of redundant data to be added to the payload. Recall that slow fading represents a change of wireless environment, whereas fast fading is transitory and would result in thrashing if the adaptive scheme responded to short-term variations in wireless conditions.
If PGB and PBG are the probabilities of going from good to bad state and from going from bad to good state respectively, then
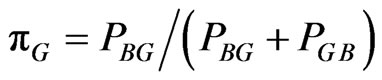 (2)
(2)
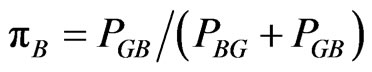 (3)
(3)
are the steady state probabilities of being in the good and bad states. Consequently, the mean probability of channel byte loss is given by
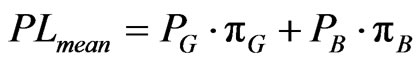 (4)
(4)
that is the mean of a Uniform distribution in this case.
The instantaneous PL (taken from a Uniform distribution with mean PLmean) is used to calculate the amount of redundant data adaptively added to the payload. In an implementation, PL is found through measurement of channel conditions (refer to Section 1 for an explanation of how is this is accomplished in WiMAX). If the original packet length is L, then the redundant data is given simply by
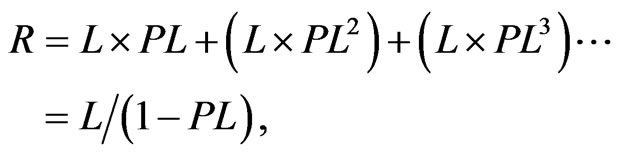 (5)
(5)
which adds successively smaller additions of redundant data, based on taking the previous amount of redundant data multiplied by PL.
Assuming perfect channel knowledge of the channel conditions when the original packet was transmitted establishes an upper bound beyond which the performance of the adaptive scheme cannot improve. However, we have included measurement noise to test the robustness of the scheme. Measurement noise was modelled as a truncated, zero-mean Gaussian (normal) distribution and added up to a given percentage (5% in the evaluation) to the packet loss probability estimate.
If it turns out that the packet cannot be reconstructed, despite the provision of redundant data then extra redundant data are added to the next packet. In Figure 1, packet X is corrupted to such an extent that it cannot be reconstructed. Therefore, in packet X + 1 some extra redundant data is included up to the level that its failure is no longer certain.
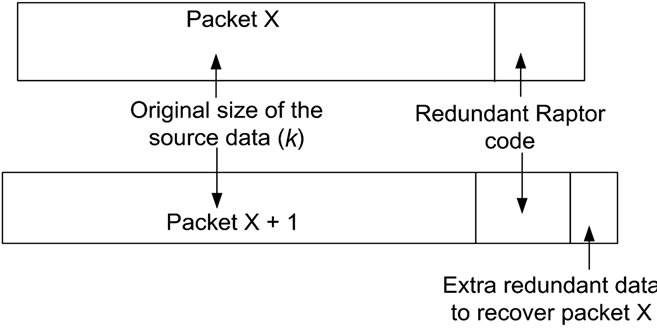
Figure 1. Division of payload data in a packet (MPDU) between source data, original redundant data and piggybacked data for a previous errored packet.
Rateless code decoding in traditional form operates by a belief-propagation algorithm [2] which is reliant upon the identification of clean symbols. This latter function is performed by PHYsical-layer FEC which passes up correctly received blocks of data (through a Cyclic Redundancy Check (CRC)) but suppresses erroneous data. Thus, in IEEE 802.16e [27], a binary, non-recursive convolutional encoder with a constraint length of 7 and a native coding rate of 1/2 operates at the physical layer. Upon receipt of the correctly received data, decoding of the information symbols is attempted, which will fail with a probability given by (1) for k > 200.
It is implied from (1) that if less than k symbols (bytes) in the payload are successfully received then a further k – m + e extra redundant bytes can be sent to reduce the risk of failure. In the evaluation tests, e was set to four, resulting in a risk of failure of 8.7% (from (1)) in reconstructing the original packet if the extra redundant data successfully arrives. This reduced risk arises because of the exponential decay of the risk that is evident from equation (1) and which gives rise to Raptor code’s low error probability floor.
4. Simulation Model
To evaluate the proposal, transmission over WiMAX was carefully modeled. The PHYsical layer settings selected for WiMAX simulation are given in Table 2. The antenna heights are typical ones taken from the standard [10]. The antenna is modeled for comparison purposes as a half-wavelength dipole, whereas a sectored set of antenna on a mast might be used in practice to achieve directivity and, hence, better performance. The IEEE 802.16 Time Division Duplex (TDD) frame length was set to 5 ms, as only this value is supported in the WiMAX forum simplification of the standard [12]. The data rate results from the use of one of the mandatory coding modes [10] for a TDD downlink/uplink sub-frame ratio of 3:1. The WiMAX base station (BS) was assigned more bandwidth capacity than the uplink to allow the BS to respond to multiple mobile sunscriber stations (SSs). Thus, the parameter settings in Table 2 such as the modulation type and physical-layer coding rate are required to achieve a datarate of 10.67 Mbps over the downlink. Notice that there is 1/2 channel coding rate at the PHY-layer of IEEE 802.16e, in addition to the application layer channel coding that we add. However, as discussed in Section 1, application layer coding is frequently used in wireless systems because of the high error rates that can occur.
Apart from the mandatory WiMAX PHY channel coding scheme, data is also randomized [27] prior to channel coding as a form of layer 1 encryption. Optional type 1 or type 2 hybrid ARQ is supported by WiMAX, though this was not simulated and, in practice it may be avoided, as it adds complexity to an implementation. Prior to transmission each physical-layer FEC block is interleaved. Interleaving of bits can take place across OFDM sub-carriers and within the modulation constellation. Thus, the purpose of interleaving is to improve the performance of the modulation itself.
In order to introduce sources of traffic congestion into the simulations, an always available FTP source was introduced with TCP transport to a second subscriber station. Likewise a CBR source with packet size of 1000 B and inter-packet gap of 0.03 s was also downloaded to a third SS. While the CBR and FTP traffic occupy the non-rtPS (non-real-time polling service) quality-of-service queue, rather than the rtPS queue, they still contribute to packet drops in the rtPS queue for the video, if the packet rtPS buffer is already full or nearly full, while the nrtPS queue is being serviced. Buffer sizes were set to fifty packets as is normal to avoid delay and reduce energy consumption at the SSs.

Table 2. IEEE 802.16e parameter settings.
Two video clips with different source coding characteristics were employed in the tests to judge content dependency. The first test sequence was Paris, which is a studio scene with two upper body images of presenters and moderate motion. The background is of moderate to high spatial complexity. The other test sequence was Football, which has rapid movements and consequently has high temporal coding complexity. Both sequences were VBR encoded at Common Intermediate Format (CIF) (352 × 288 pixel/picture), with a Group of Pictures (GOP) structure of IPPP… at 30 Hz, i.e. one initial I-picture followed by all predictive P-pictures. This structure removes the coding complexity of bi-predictive B-pictures at a cost in increased bit rate. Similarly, in H.264/AVC’s Baseline profile, B-pictures are not supported to reduce complexity at the decoder of a mobile device.
As a GOP structure of IPPP... was employed, it is necessary to protect against error propagation in the event of inter-coded P-picture slices being lost. To ensure higher quality video, 5% intra-coded MBs (randomly placed) were included in each frame (apart for the first I-picture) to act as anchor points in the event of slice loss. The JM 14.2 version of the H.264/AVC codec software was utilized according to reported packet loss from the simulator and to assess the objective video quality (PSNR) relative to the input YUV raw video. Lost partition-C slice packets were compensated for by motion copy error concealment using the MVs in partition-A at the decoder.
5. Experimental Results
The Paris sequence was initially simulated for transmission across the IEEE 802.16e channel. Before commencing the main tests, we assessed the relative sizes of the data-partitioned NALs when using a single slice per picture. Table 3 presents the results with and without CIP (refer to Section 2) showing the increase in partition-B and -C sizes that results from the loss in compression efficiency. Notice that NALs that might be above the maximum packet size of 1024 B (Table 2) were constrained to the maximum by the encoder when forming an RTP packet prior to encapsulation by IP/UDP headers. This means that these NALs are not segmented before reaching the link layer, avoiding the possible separation of header information from NAL data.
At lower QPs, i.e. higher quality video, the relative size of partition-C NALs means that the more important partition-A and –B packets are less likely to suffer channel error. However, the larger packet sizes mean that congestion may have more of an impact, because longer packets take longer to transmit and free the channel. At higher QP, the advantage of differential packet sizes is lost but the generally smaller packet sizes compensate to some extent. There is also a small growth in partition-B and –C packet size when CIP is turned on.
The following types of erroneous packets were considered: packet drops at the BS sender buffer and packet drops through channel noise and interference, especially slow fading; together with corrupted packets that were received but affected by Gilbert-Elliott channel noise to the extent that they could not be immediately reconstructed without an ARQ triggered retransmission of piggybacked redundant data. Notice that if the retransmission of additional redundant data still fails to allow the original packet to be reconstructed then the packet is simply dropped. The Raptor code equation (1) was applied to decide if a packet could be recovered, given the number of bytes that were declared to be in error.
Figure 2 shows the effect of the various schemes on packet drops when streaming Paris. Notice that this figure and subsequent figures are slanted towards the
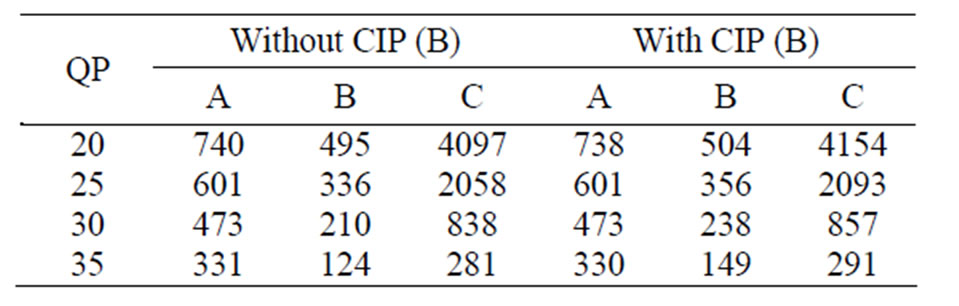
Table 3. Paris mean NAL size according to partition type.
 (a)
(a)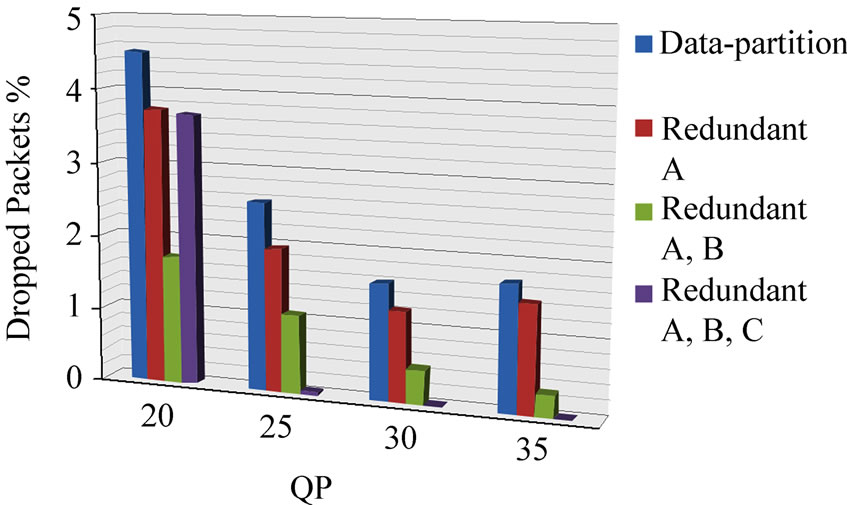 (b)
(b)
Figure 2. Paris sequence protection schemes packet drops, (a) with and (b) without CIP.
viewer to aid the view of the 3D bar charts. “Data-partition” in the figure legend refers to sending no redundant packets. “Redundant X” refers to sending duplicate redundant packets containing data-partitions of partition type(s) X in addition to the rateless coded data-partition packets.
The proposed redundant schemes were also assessed for the presence of CIP or its absence. From Figure 2, the larger packet drop rates at QP = 20 will have a significant effect on the video quality. However, the packet size changes with and without CIP have little effect on the packet drop rate.
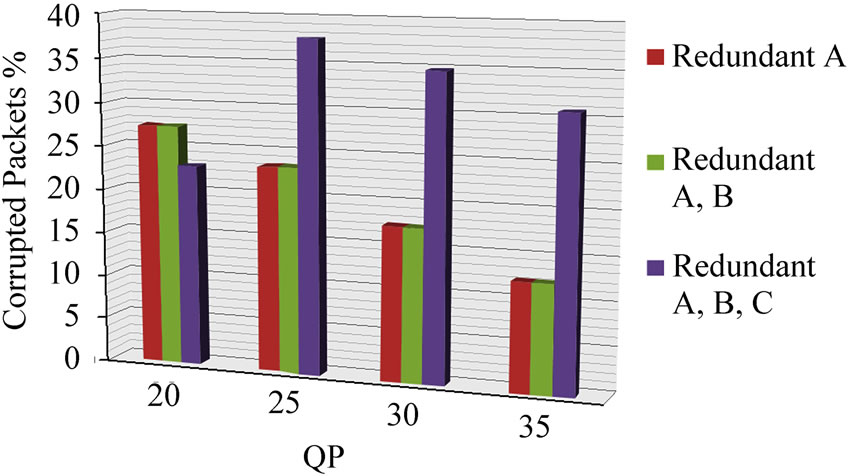
Figure 3 shows the pattern of corrupted packet losses arising from simulated fast fading. There is actually an increase in the percentage of packets corrupted if a completely redundant stream is sent (partitions A. B, and C), though this percentage is taken from corrupted original and redundant packets.
However, the effect of the corrupted packets on video quality only occurs if a packet cannot be reconstructed after application of the adaptive retransmission scheme.
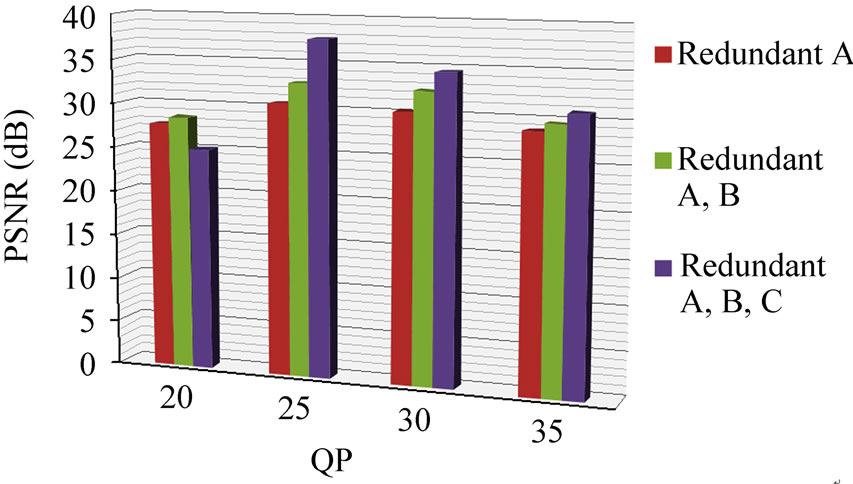
Examining Figure 4 for the resulting video quality (PSNR), one sees that data partitioning with FEC protection, when used without redundancy, is insufficient to bring the video quality to above 31 dB, that is to a good quality. PSNRs above 25 dB, we rate as of fair quality. However, it is important to note that sending duplicate redundant partition-A packets alone (without redundant packets from other partitions) is also insufficient to raise the video quality to a good rating (above 31 dB). Therefore, to raise the video quality to a good level (above 31 dB) requires not only the application of the adaptive rateless channel coding scheme but also the sending of duplicate data streams. As previously mentioned in Section 1, this is similar in general terms to the experience reported in [3], though for multicast streaming and without feedback.
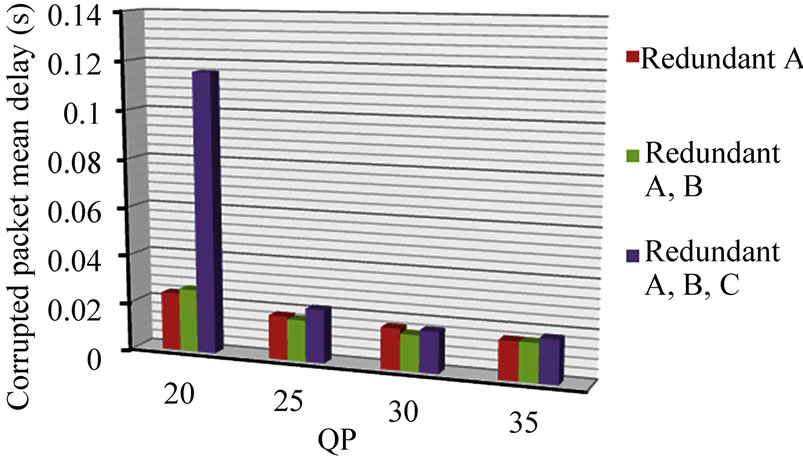
The impact of corrupted packets, given the inclusion of re-transmitted additional redundant data, is largely seen in additional delay. There is an approximate doubling in per packet delay between the total end-to-end delay for corrupted packets, Figure 5, and normal packet end-to-end delay, Figure 6. Normal packets do not, of course, experience the additional delay of a further retransmission prior to reconstruction at the decoder. Therefore, the main penalty arising under the FEC protection scheme from an increased percentage of corrupted packets is an overall increase in delay. Nevertheless, the delays remain in the tens of millisecond range, except for when QP = 20. It must be recalled though that, for the redundant slice schemes, there is up to twice the number of packets being sent. Therefore, delay is approximately further doubled, still though with end-to-end delays remaining in the tens of millisecond range. This type of delay range is acceptable even for interactive applications, but may contribute to additional delay if it forms part of a longer network path.
 (a)
(a)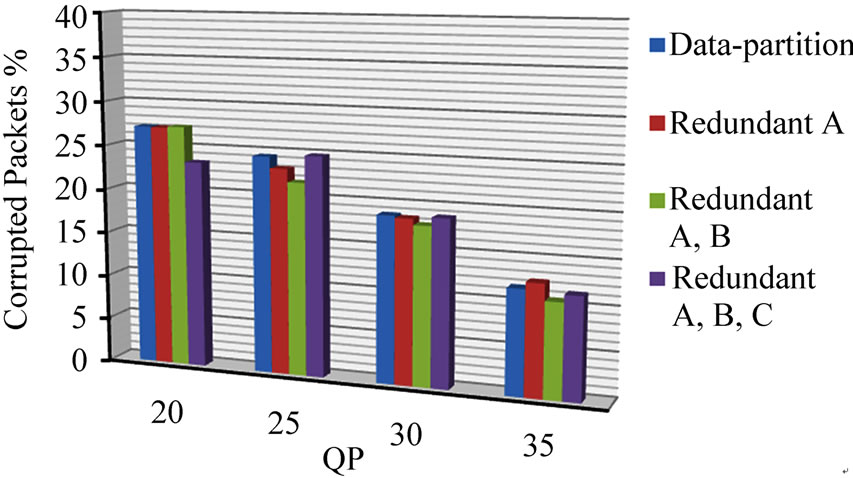 (b)
(b)
Figure 3. Paris sequence protection schemes corrupted packets, (a) with and (b) without CIP.
 (a)
(a)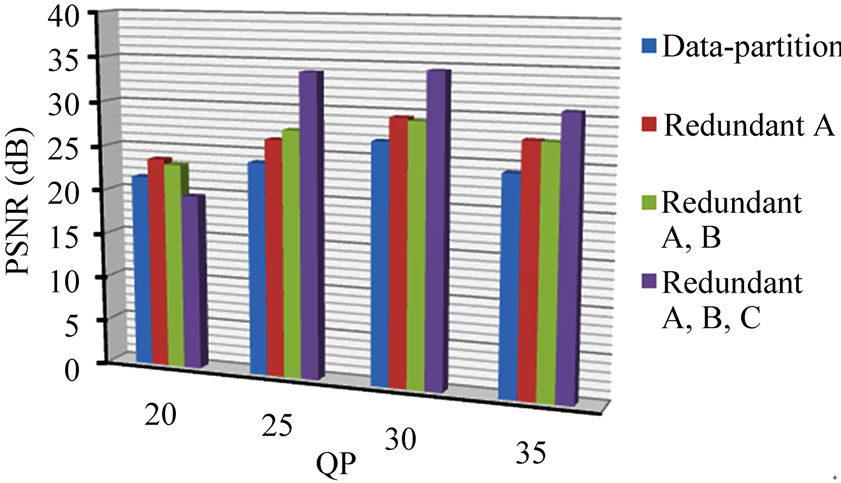 (b)
(b)
Figure 4. Paris sequence protection schemes video quality (PSNR), (a) with and (b) without CIP.
 (a)
(a)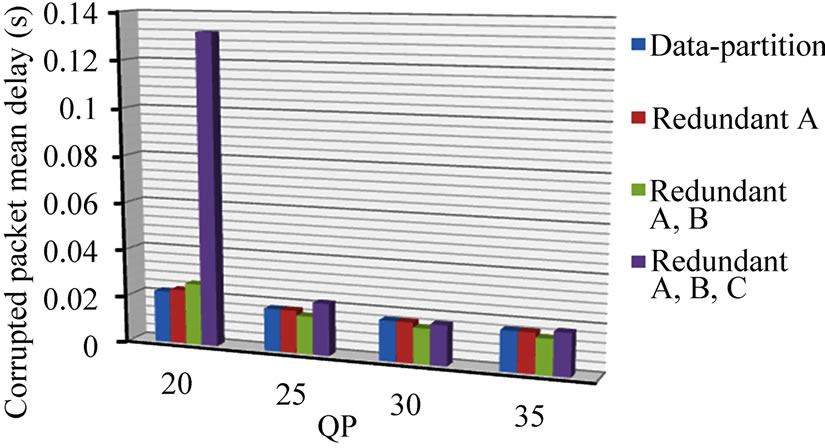 (b)
(b)
Figure 5. Paris sequence protection schemes end-to-end delay for corrupted packets, (a) with and (b) without CIP.
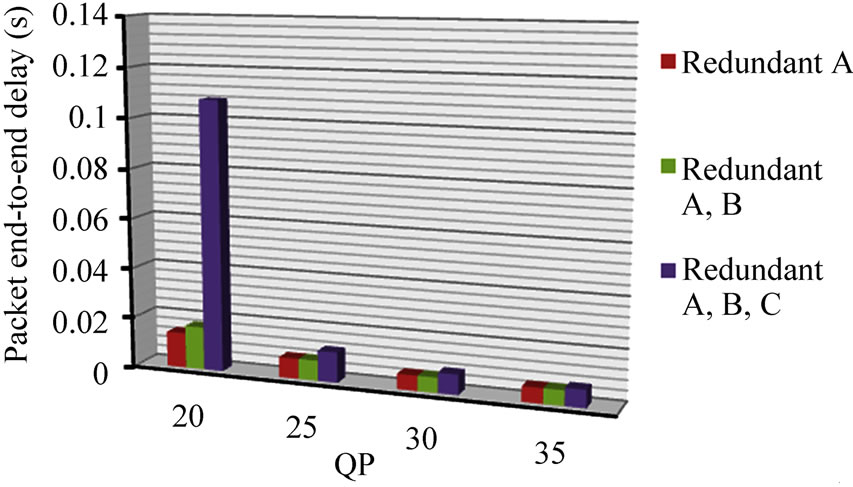 (a)
(a)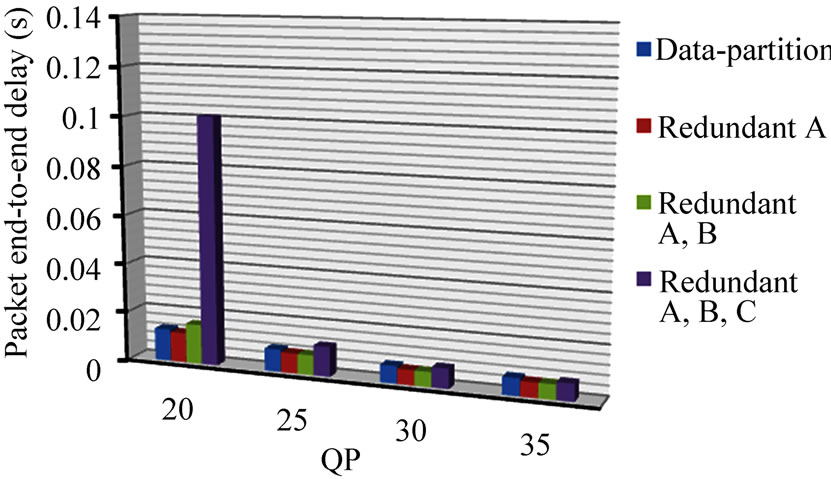 (b)
(b)
Figure 6. Paris sequence protection schemes end-to-end delay for packets, (a) with and (b) without CIP.
Turning to NAL sizes for Football, from Table 4 one sees that though the relative ranking of sizes between the partition types is similar, the actual sizes are larger than those for Paris (see Table 3). The larger sizes are due to the temporal coding complexity of Football. For high QP, the relatively larger size of partition-A NALs compared to the other partitions NALs may create a problem, as it does not result in a relatively reduced risk of loss of packets bearing partition-A NALs. Also of concern is the number of NAL sizes that are above the maximum packet size, causing more than one packet to be sent.
We continue the presentation of the experimental results for Football with Table 5, which shows how packet drops and losses reflected in video quality (PSNR). Very large numbers of packets are dropped at QP = 20. However, there is a threshold effect, as the numbers of dropped packets decline quickly with increasing QP. The protection pattern for redundant packets is accentuated compared to Paris, in the sense that providing duplicate redundant versions of more than just partition-A packets is now clearly seen to be preferable. Given that in quality-of-experience subjective tests for mobile devices [28], news scenes rather than sport are preferred by viewers, it may be advisable to favor content without rapid motion, especially if small footballs or similar sports’ balls need to be tracked by the viewer.
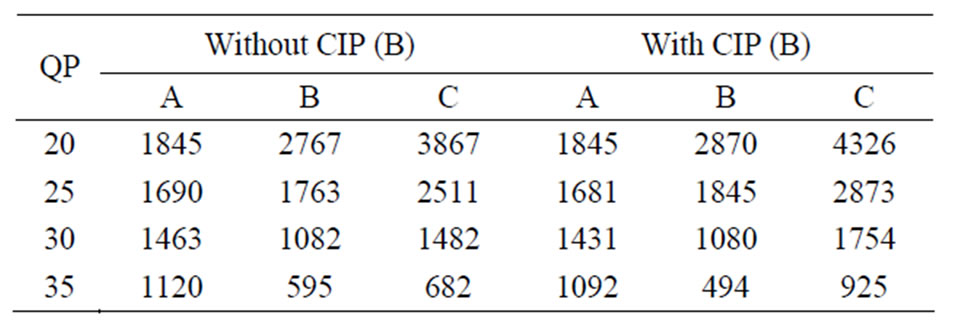
Table 4. Football mean NAL size according to partition type.
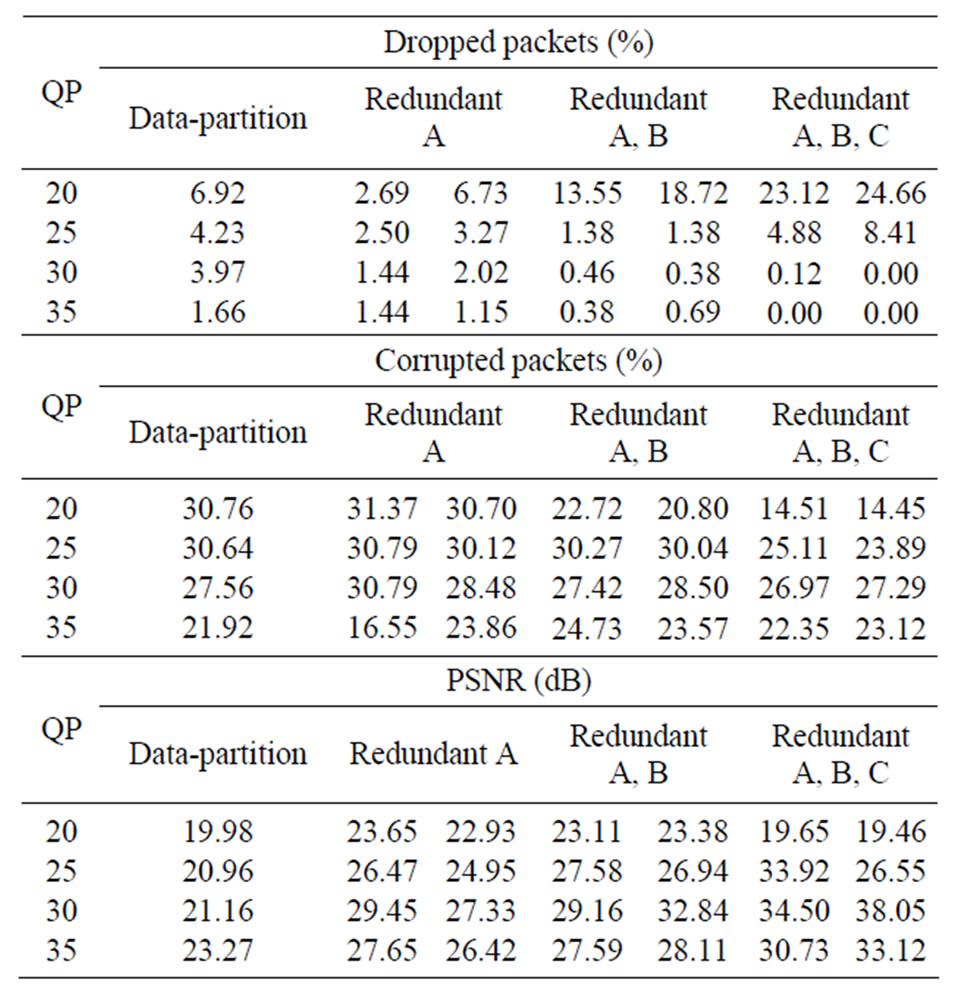
Table 5. Football protection schemes, with and without CIP.
6. Conclusions
Data-partitioning of IPTV video streams is a way of providing graceful quality degradation in a form that will work in good and difficult wireless channel conditions. We have employed uniform application-layer FEC but augmented this with redundant slices, which can themselves be withdrawn depending on measured channel conditions. The use of uniform protection is a way of taking advantage of the natural packet size differential of data partitioning, which is in inverse order of the priority of the data partitions. Thus, smaller packet lengths already confer a lower risk of channel error. However, this inverse order was seen to occur only when smaller QPs were chosen.
It was confirmed that for a moderate increase in mean packet size, making partition-B completely independent of partition-C resulted in a small but significant improvement in video quality. However, this is dependent on choice of QP, as a low QP can lead to high packet drop rates with poor video quality. In general, in poor channel conditions resulting from slow and fast fading, it is not sufficient to employ just application FEC, or just FEC without adaptation, or without stream replication. Rather, as in the proposed scheme, a number of measures are required in order to realistically allow good-quality video to be delivered. Account should also be taken of the coding complexity of the sequence along with its suitability for display on mobile devices.
REFERENCES
- T. Stockhammer and W. Zia, “Error-Resilient Coding and Decoding Strategies for Video Communication,” In: P. A. Chou and M. van der Schaar, Eds., Multimedia in IP and Wireless Networks, Academic Press, Burlington, 2007, pp. 13-58. doi:10.1016/B978-012088480-3/50003-5
- D. J. C. MacKay, “Fountain Codes,” IEE Proceedings: Communications, Vol. 152, No. 6, 2005, pp. 1062-1068. doi:10.1049/ip-com:20050237
- S.-H. G. Chan, X. Zheng, Q. Zhang, W.-W. Zhu and Y.-Q. Zhang, “Video Loss Recovery with FEC and Stream Replication,” IEEE Transactions on Multimedia, Vol. 8, No. 2, 2006, pp. 370-381. doi:10.1109/TMM.2005.864340
- M. Luby, T. Stockhammer and M. Watson, “Application Layer FEC in IPTV Services,” IEEE Communications Magazine, Vol. 45, No. 5, 2008, pp. 95-101.
- ITU-T Recommendation Y. 1541, “Internet Protocol Aspects—Quality of Service and Network Performance: Network Performance Objectives for IP-Based Services,” May 2002.
- ETSI TS 102 034 v1.3.1, “Transport of MPEG 2 Transport Stream (TS) Based DVB Services over IP Based Networks,” DVB Blue Book A086rev5, October 2007.
- 3GPP TS26.346, “Multimedia Broadcast/Multicast Service (MBMS): Protocols and Codecs,” December 2005.
- T. Stockhammer, H. Jenkač and C. Weiß, “Feedback and Error Protection Strategies for Wireless Progressive Video Transmission,” IEEE Transactions on Circuits and Systems for Video Technology, Vol. 12, No. 6, 2002, pp. 465- 482. doi:10.1109/TCSVT.2002.800317
- C. E. Shannon, “The Zero-error Capacity of a Noisy Channel,” IRE Transactions on Information Theory, Vol. IT-2, 1956, pp. 8-19. doi:10.1109/TIT.1956.1056798
- IEEE, 802.16e-2005, IEEE Standard for Local and Metropolitan Area Networks, Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems, 2005.
- N. Degrande, K. Laevens and D. de Vleeschauwer, “Increasing the User Perceived Quality for IPTV Services,” IEEE Communications Magazine, Vol. 46, No. 2, 2008, pp. 94-100. doi:10.1109/MCOM.2008.4473090
- C. So-In, R. Jain and A.-K. Tamini, “Capacity Evaluation for IEEE 802.16e Mobile WiMAX,” Journal of Computer Systems, Networks, and Communications, Special Issue on WiMAX, LTE, and WiFi Interworking, Vol. 2010, 2010, pp. 1-12. doi:10.1155/2010/279807
- O. Oyman, J. Foerster, Y.-J. Tcha and S.-C. Lee, “Towards Enhanced Mobile Video Services for WiMAX and LTE,” IEEE Communications Magazine, Vol. 48, No. 8, 2010, pp. 68-77. doi:10.1109/MCOM.2010.5534589
- T. Wiegand, G. J. Sullivan, G. Bjontegaard and A. Luthra, “Overview of the H.264/AVC Video Coding Standard,” IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, 2003, pp. 560-576. doi:10.1109/TCSVT.2003.815165
- P. Lambert, W. de Neve, Y. Dhondt, R. Van de Walle, “Flexible Macroblock Ordering in H264/AVC,” Journal of Visual Communication and Image Representation, Vol. 17, No. 2, 2006, pp. 358-375. doi:10.1016/j.jvcir.2005.05.008
- T. Stockhammer and M. Bystrom, “H.264/AVC Data Partitioning for Mobile Video Communication,” Proceedings of IEEE International Conference on Image Processing, Singapore, 24-27 October 2004, pp. 545-548.
- J. Radulovic, Y.-K. Wang, S. Wenger, A. Hallapuro, M. H. Hannuksela and P. Frossard, “Multiple Description H.264 Video Coding with Redundant Pictures,” Proceedings of International Workshop on Mobile Video, Augsburg, 24-27 September 2007, pp. 37-42.
- M. Ghanbari, “Standard Codecs: Image Compression to Advanced Video Coding,” The Institution of Engineering and Technology, London, June 2003.
- Y. Dhondt, S. Mys, K. Vermeirsch and R. Van de Walle, “Constrained Inter Prediction: Removing Dependencies between Different Data Partitions,” Proceedings of Advanced Concepts for Intelligent Visual Systems, Delft, 28-31 August 2007, pp. 720-731.
- A. Shokorallahi, “Raptor Codes,” IEEE Transactions on Information Theory, Vol. 52, No. 6, 2006, pp. 2551-2567. doi:10.1109/TIT.2006.874390
- R. Palanki and J. S. Yedidia, “Rateless Codes on Noisy Channels,” Proceedings of International Symposium on Information Theory, Chicago, 27 June-2 July 2004, p. 37.
- M. Luby, T. Gasiba, T. Stockhammer and M. Watson, “Reliable Multimedia Download Delivery in Cellular Broadcast Networks,” IEEE Transactions on Broadcasting, Vol. 53, No. 1, 2007, pp. 235-246. doi:10.1109/TBC.2007.891703
- F. C.-D. Tsai, et al., “The Design and Implementation of WiMAX Module for ns-2 Simulator,” Proceedings of Workshop on ns2: The IP Network Simulator, Pisa, 10 October 2006, pp. 1-8.
- M. Zorzi and R. Rao, “On the Statistics of Block Errors in Bursty Channels,” IEEE Transactions on Communications, Vol. 45, No. 6, 1997, pp. 660-667. doi:10.1109/26.592604
- C. Jiao, L. Schwiebert and B. Xu, “On Modeling the Packet Error Statistics in Bursty Channels,” Proceedings of IEEE Conference on Local Computer Networks, Tampa, 6-8 November 2002, pp. 534-541.
- Y. J. Liang, J. G. Apostolopoulos and B. Girod, “Analysis of Packet Loss for Compressed Video: Effect of Burst Losses and Correlation between Error Frames,” IEEE Transactions on Circuits and Systems for Video Technology, Vol. 18, No. 7, 2008, pp. 861-874. doi:10.1109/TCSVT.2008.923139
- J. G. Andrews, A. Ghosh and R. Muhamed, “Fundamentals of WiMAX: Understanding Broadband Wireless Networking,” Prentice Hall, Upper Saddle River, 2007.
- F. Agboma and A. Liotta, “Addressing User Expectations in Mobile Content Delivery,” Mobile Information Systems, Vol. 3, No. 3-4, 2007, pp. 153-164.