Communications and Network
Vol. 4 No. 3 (2012) , Article ID: 22076 , 13 pages DOI:10.4236/cn.2012.43027
A Service Discovery Approach Based on a Quantitative Similarity Measure for M-Tourism Platforms
Department of Computer Science, University of Sciences and Technology Houari Boumediene, Algiers, Algeria
Email: fbouyakoub@usthb.dz
Received April 14, 2012; revised May 17, 2012; accepted June 16, 2012
Keywords: Mobile Location Services; Location Based Services; Services Discovery; Similarity Measure; M-Tourism
ABSTRACT
This paper presents a localization architecture for an m-tourism services delivery platform. The aim of the system is to deliver services for nomads (e-tourists) according to their localization and according to the results given by the search engine. This engine is based on a quantitative similarity measure. The discovered services are presented via a Web Map Service. Moreover, the platform integrates an adaptation sub-system for heterogeneous environments and an e-negotiation module.
1. Introduction
Recently, a new evolution is taking place among the numerical applications in the tourist domain. The m-tourism or mobile tourism relates to the applications of information technologies usable either only on computers, but on a variety of mobile terminals, thus complementing the process of e-tourism (transactions and information access before and after the voyage): information access during the voyage.
Thanks to the development of smartphones, satisfying the fans of the all-in-one (phone calls, Internet, etc.) as well as unlimited Internet offers, m-tourism is in constant evolution.
With the development of these high technologies, it became possible to develop new services, well beyond simple projection of Web contents on smartphones screens.
In this paper, we present a new Services Delivery Platform (SDP), based on tourists’ localization. The platform offers to services providers (travel agencies) tools to host and to describe their services in order to simplify the search process. On the client side, the system offers a search engine based on a new quantitative similarity measure to define the correspondence rate between the client request and services descriptions.
This article is organized as follows: Section 2 presents briefly the telephony evolution and we make an overview of the different techniques of localization used in location based services (LBS) and Mobile Location Services (MLS). Section 3 presents our service delivery platform: first we present the system architecture and it basic components, and then we present the platform functionalities, in particular the search engine. The performance evaluation of the proposed similarity measure, used in the search engine, is presented in Section 4 and finally Section 5 concludes this paper.
2. Telephony Advancement: From SMS to LBS and MLS
Since its advent in 1973 by a Motorola company team, mobile phones have shown a continuous evolution. This innovation, enabling persons to be joined anywhere and at any time, became essential and very useful. Over the past few years, the use of mobile phones was limited to vocal calls, but actually its use is extended to several services like MMS (Multimedia Messaging Service), VoD (Video on Demand) … etc.
The boom in mobiles market and the emergence of new services bring current GSM networks to their limit. The defined rate (9.6 kb/s) for these networks is insufficient to support new services, in particular multimedia services.
As 2G and 2.5G supports, respectively functionalities of voice and data, the 3G and 3G+ technologies adds multimedia functionalities.
Unlike 2G-3G evolution (hardware and software changes), the 3G-3G+ evolution needs only software changes. Based on the same CDMA (Code division multiple access) and the same waveband, the deployment of 3G+ does not need physical changes. The entire 3G infrastructure is preserved; the operator has just to update codecs, access network modulations ….
The development of the 3G+ generation satisfied the strong needs of multimedia services, by offering a very high rate. Moreover, this generation makes it possible to extend Internet network, by supporting mobile phones besides to personal computers: the mobile internet was born.
The development of mobile applications is in continuous progress and the new generations of mobiles support multiple services which were not supported by the first generations, and among these services we cite Location Based Services (LBS) and Mobile Location Services (MLS).
LBS refer to any application that uses location of a device or a person as a primary source to deliver context sensitive service. Therefore it covers a wide range of applications and devices. The popularity of LBS makes it one of most essential and useful asset in almost all industries. However, its market is divided into various categories including navigation, emergency assistance, tracking, advertising, billing, management, games and leisure. However, its application is growing with innovative ideas day by day with the expansion of mobile phone market.
On the other hand, MLS refer to services that are based on the location of a mobile phone.
MLS are value-added services that utilize the user’s position information.
From the user’s perspective these services provide:
• Localized and up-to-date information: Up-to-date information that is relevant in a particular location is given at the right moment;
• Personalized information;
• Increased efficiency and pertinence: The information can be more focused and of higher quality , when it is also tailored according to the user’s location;
• Increased safety: The positioning functionality increase user safety by being able to locate someone in distress.
The location information has no value in itself; it is only a parameter for provisioning valuable applications relevant to a user at a specific location and at a specific point in time [1].
There is three generation of localisation services [1]: In the first generation, users were obliged to specify their position before receiving the service. In the second generation, the localization is done automatically when the user asks for a service. The third generation is characterized by a bigger precision of localization. It can also, in some cases, send alerts to users.
2.1. MLS Components
A common MLS architecture is composed of three elements: A Mobile Operator (MO), a Service Provider and a Mobile User (MU). Usually, the MO works as an intermediary between the provider and the MU. This includes the identification of customers for payment purposes, the transmission of user’s location to the Provider and the delivery of services via mobile communication networks.
2.2. Localization Technologies
Localization technologies provide means to locate a subscriber and/or a valid mobile equipment in order to optimize, to adapt and to deliver services.
Positioning technologies can basically be divided into handset-based and handset-assisted, and similarly network-based and network-assisted, each of which offer different levels of accuracy. Hybrid positioning solutions combine two or more positioning technologies thus achieving an improved accuracy in positioning.
A successful positioning technology must meet the accuracy requirements set by the specific service, at the lowest possible cost and with good sensitivity and minimal impact on the network and subscriber equipment.
We can classify these techniques into three classes:
• The first class (based on the mobile terminal) is composed of: Observed Time Difference of Arrival (OTDOA) [2], Enhanced Observed Time Difference (EOTD) [3], Global Positioning System (GPS) [4] and Assisted Global Positioning System (AGPS) [5].
• The second class we have user-self-locating and for example, complementary local area technologies, such as Bluetooth [6] may be used to improve coverage.
• In the third class (based on the mobile network), several techniques have been developed like Cell Identification (Cell-ID) and variations [7]. In this class, mobile network localize the user and determine his position. This solution is simple and little expensive to achieve, however, the localization is not very precise, it localizes a mobile at 250 meters in an urban area and about 10 kilometres in rural area [1].
Each localization technology has its advantages and its inconveniences; the choice of a localization technology is relative to the application domain. According to an achieved comparative study in [1], we note that the main comparison criterion is the accuracy. For non-critical services, Cell-ID is sufficient, especially in an urban area. For critical services (security domain), the accuracy is very important; the usage of the GPS or A-GPS is required.
In general, there is a trade-off between the accuracy of the location method and the modification needed for the mobile terminals. As a rule of thumb, the better the measurement accuracy the more modifications are needed for the mobile terminals and, therefore the higher the added costs are for terminals.
Currently most commercial applications use information-based services over Cell-ID due to its broad coverage and cost applications [1].
Figure 1 presents accuracy of most important positioning methods.
The idea presented in this article consists on proposing a service delivery platform based on clients’ localization (first level of search). Next, we propose to the subscribers, a search engine based on a quantitative similarity measure, to improve the result of the first search level by weighting up the correspondence rate between the client request and services descriptions.
3. A Service Delivery Platform for Tourism Mobile Location Based Services
With the development of new communication systems we assist to the birth of a new generation of users called “nomads”. Indeed, with the appearance of wireless networks and mobile devices (PDA, smartphones…), it became possible to connect from any place to search for services; however these nomads prefer to have services near of their position. The constraint of localization is important in many domains like tourism.
Electronic tourism or e-tourism, representing all the activities of tourism using Internet, proposes means to organize travels via Internet. E-tourism makes it possible to reserve hotel rooms, to define a travel route or to exchange information with other e-tourists via forums.
Several actors intervene in the market of e-tourism, we enumerate:
• Virtual travel agency: Thanks to the novel modes of communication, and in particular Internet, travel agencies present their services on the Web.
• Tour operator: These organizations aim to gather different services offers, and to sell them as packages.
• The e-tourist.
The m-tourism use mobile communications (PDAs, mobile phones, tablets…) for tourism services. The mtourism is more personal as you hold your mobile de-
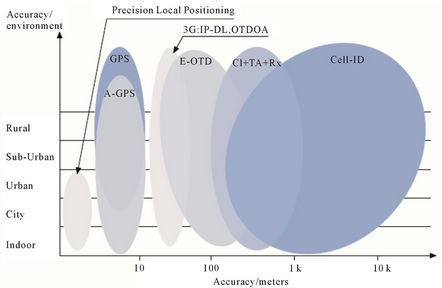
Figure 1. Accuracy of localization technologies.
vice all the time with you and can easily send or receive information at any time.
The proposed solution, presented in this paper, is a services delivery platform (SDP) for m-tourism, based on the functional diagram (Figure 2) of Web services (SOA architecture).
The aims of the platform are to:
• Propose publishing functionalities to travel agencies to hosts services and services descriptions in UDDI (Universal Description, Discovery and Integration), to make easy the discovery process;
• Carry out the communication between the m-tourist and the system;
• Allow users to search for services according to their localization, theirs requirements and theirs needs;
• Manage users’ heterogeneity;
• Manage contents heterogeneity;
• And finally, manage users’ profiles.
Figure 3 summarizes the delivery process. In our preceding work, we have presented solutions for different stages of services delivery (adaptation, E-negotiation…). In this paper we will focus our work on services’ discovery process by proposing a service search engine based on a new quantitative similarity measure.
3.1. The System Architecture
Our localization solution is based on the Cell-ID [7] technique. Figure 4 describes the system architecture composed of three basic components:
3.1.1. The M-Tourist
The client application manages the user interface to access the system functionalities like the newsletter, the forum and the search engine. The client request is sent to the Services Localization Centre (SLC) to search for services according to tourist position and needs. The discovered services (description) are presented via a Web Map Service (WMS). Furthermore, we associate to each service description a multimedia presentation making the service description richer in information.
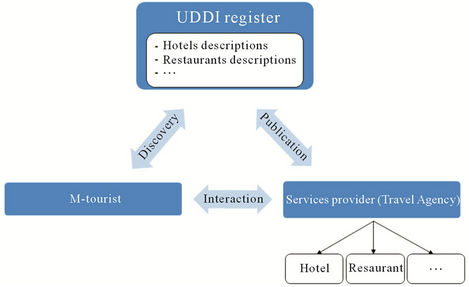
Figure 2. Web services SOA architecture.
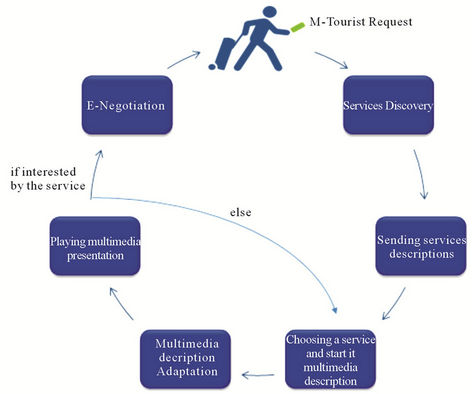
Figure 3. Services delivery stages.
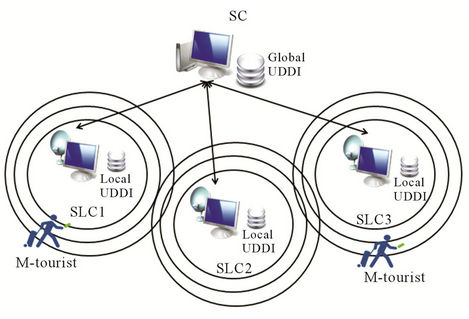
Figure 4. System architecture based on the Cell-ID.
However, with the heterogeneity of users’ terminals we attend the appearance of heterogeneous environments, thus the system have to adapt the multimedia service description according to the features of each user; these features are called the profile.
This need of adaptation is due to the fact that each user wants to access services corresponding to his preferences and compatible with his device characteristics [8].
Dey defines in [6] a profile as “any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between the user and the application, including the user and the applications themselves”.
So, we can say that a profile is a set of information that allows the system to filter contents and to adapt them according to this information [8]. The profile is composed of the material capacities (screen size, memory size…), the installed software (OS, codecs…), and on the user’s personal preferences (the language…) [9]. A universal profile format, proposed by the W3C [10], is used to describe the users’ preferences and their terminals capacities: this standard is the Composite Capability/ Preference Profiles (CC/PP) [8].
3.1.2. The Central Server
The CS carries out:
• The management of clients’ accounts: it includes the creation/deletion of accounts, generation of CC/PP users’ profiles and profiles updates;
• The management of services and services’ versions;
• Services adaptation;
• The management of the services registry (global UDDI), which includes services publication (adding/deleting of services) and services descriptions updates;
• Dispatching services to the various SLC according to the location of each service and the region covered by each SLC. Moreover, the CS dispatches also services information from the global UDDI to the associated local UDDI.
3.1.3. The Services Localization Centre
The SLC have the role of a BTS in a GSM network. Each SLC manage a local UDDI register containing descriptions of available services in the covered zone. Moreover, each SLC host SMIL (Synchronized Multimedia Integration Language) multimedia services’ descriptions [11], of the available services located in the covered zone.
The localization of each user will depend on the SLC on which he is connected (the SLC covering the region).
After presenting the system architecture, next we present the system functionalities provided by our SDP and we will detail the services’ discovery process based on the use of a new quantitative similarity measure.
3.2. Communication Protocols
We use SIP (Session Initiation Protocol) [12] and SDP (Session Description Protocol) [13] protocols for the communication between the client, the SLC and the CS.
When the client sends a SIP message “INVITE” containing identification information, as well as an SDP description containing his profile, he will be localized by the nearest SLC, which send this information to the CS for authentication.
On the CS side, the localization of the client is materialized by the SLC ID. If authentication information is erroneous, the SC sends to the client a SIP answer “401 ERROR” via the SLC, the client will be invited to logon another time. If the information is valid, the CS returns a SIP message “200 OK” to the client.
When the client receives the “200 OK” message, he sends to the CS, via the SLC, an “ACK” message to confirm the establishment of the session.
To manage the communication between clients and the SLC, we propose a SIP extension. This extension is materialized by adding new methods like “REQ” and “REQdev” as well as response codes like “201” and “202” [14].
3.3. Services Hosting
The publication process assumes the following tasks:
• Management of services’ providers: Each travel agency, wishing to host a service, in order to publish it, must have a single identifier PID (Provider ID) to login. The publication sub-system manage:
Ø The registration of new services’ providers (travel agencies) within the UDDI server (global UDDI) by introducing information like Agency-Description, Agency-URL... Following each validated registration, a repertory will be associated to the provider to host his services (description and multimedia presentation).
Ø Deletion of providers and that automatically imply the deletion of all his services and their descriptions.
• Management of services: A travel agency announces new service by publishing it description (Figure 5 step 1). Therefore, the travel agency is invited to fill a form to describe the published service. This description will be used during the discovery stage. The management of services must assume the following tasks:
Ø Registration and description of services within the UDDI directory: in this stage, services’ descriptions are high level (no technical information is described). Among stored information, we have: Service-Name, Service-Description, Service URL, reference towards its WSDL (Web Services Description Language) description and a reference towards the CC/PP repertory (Figure 5 step 3), containing all contextual descriptions of the various versions of the service.
At the end of this step, the CS sends the service’s description to the corresponding SLC according to the service localisation (Figure 5 step 4). The SLC register the new service within his local UDDI.
Ø Deletion of the service that implies the deletion of all its versions.
• Management of services’ versions: the management of versions must deal with the following operations:
Ø Registration of versions: While creating a new service version, the publication system registers it in the service repertory referenced by the Tmodel [15]. The description publication process of the version is the same one as the service publication process, except that this publication is done only within the local UDDI.
Ø Updating data: The provider can update a version.
Ø Removing services’ versions.
• Deletion functionalities: Various removing functionalities, such as deletion of publishers’ accounts as well as deletion of information relating to services and services’ versions.
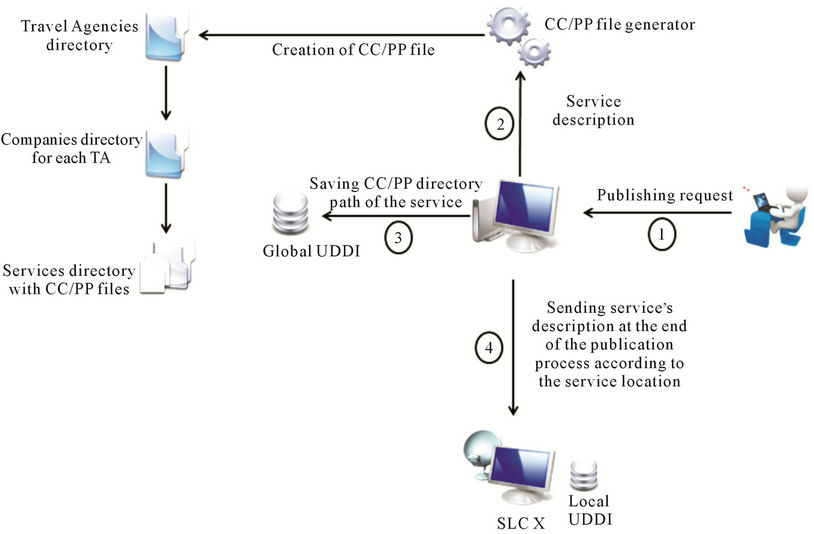
Figure 5. Services hosting process.
3.4. QSim: A New Quantitative Similarity Measure for Services’ Discovery
3.4.1. Services’ Discovery
Services discovery is based generally on a syntactic search on the UDDI register. The services’ descriptions are used during the discovery process to select services corresponding as well as possible to the user request. The discovery process is based on the use of a similarity measure, which estimates the correspondence degree between the client needs and services.
Various discovery mechanisms were proposed in the literature. In [16], authors define the discovery process as being “the act of localizing a description, manageable by a machine, of an unknown Web service before describing certain functional criteria”.
Currently, services’ descriptions are published in registers (UDDI) to facilitate the discovery of published services. However, considering the number and the diversity of services, their discovery is a difficult task.
We distinguish three discovery approaches: syntactic, semantic and context based approaches. For each class we have two different architectures: centralized (services’ descriptions are localised in the same register) and distributed architectures (services’ descriptions are localised in different registers).
The principle of the syntactic-based approach is simple: The user sends a request composed of key words; these words will be compared with services’ descriptions. In spite of its simplicity and its facility of implementation, this approach presents some limitations [17]. Indeed, syntactic search does not make it possible, always, to have good results. Moreover, a software agent cannot examine textual descriptions intended for human use.
Others solutions were proposed for distributed architecture, as [18]. The main idea is to connect an arbitrary number of nodes (cloud or UDDI federation) to form in a virtual UDDI register, and each node contains a part of services’ descriptions. When a user sends a request to one of the nodes, the node transmits the request to its neighbours, and so on for the nodes receiving this request. The results of each node having received the request are then sent to the source node.
Another distributed system called AASDU system (Agent Approach for Service Discovery and Utilization) was proposed in [19]. AASDU is composed of:
1) A Graphical User Interface (GUI);
2) A Query Analyzer Agent (QAA);
3) A reference system of agents’ expertise fields, which reference agent according to their expertise;
4) The services module which allows services providers to publish descriptions, to start a negotiation agent allowing the selection of services and finally to invoke one of the selected services.
In the second discovery class (semantic approaches) authors focused on the semantic description of services. This development is increasingly significant since it seems to be able to approach certain insufficiencies of syntactic approaches.
For centralized architectures, we have:
• The OWL-S (Web Ontology Language) approach [20]: Among the ontologies proposed for the description of services we have the DAML-S ontology (DARPA Agent Markup Language for Services). This ontology is based on the DAML language ontology. DAML-S describes a service using three profiles:
1) ServiceProfile: defines the service;
2) ServiceModel: defines the operation of the service;
3) ServiceGrounding: defines how to reach the service.
• The IRS-II platform [21]: The main components of this architecture are:
1) The IRS-II Server contains services’ semantic descriptions.
2) The IRS-II Publisher has two functions. Firstly, it allows linking services to their respective semantic descriptions. Secondly, it automatically generates a program which wraps the Java code of the service, in order to invoke it.
3) The IRS-II Client invokes a service by sending a request.
For distributed architectures we have:
• The PSWSD Architecture (P2P-based Semantic Web Discovery Service) [22] is a service discovery architecture in a P2P network. In this architecture, providers publish services’ descriptions in various registers, distributed in a P2P network. A subscriber looking for a service can question any register of the network. When the register receives the request, it will direct it towards the register(s) which can satisfy this request. This information is sent to the matchmaker module which selects services descriptions having a semantic correspondence with the user request.
• The Speed-R system [23] aims to connect all private UDDI registers (each service provider has its own UDDI register) via the P2P network. In order to have semantics in services descriptions, authors associate to each register specific ontologies. Semantics are brought to services descriptions by making a mapping between services specifications and concepts of ontologies.
Finally, in the third class (context-based), a service context can group it localization (geographical restricttion), the cost, the service category, etc. The user context is composed of his localization, his preferences, etc. Several solutions were proposed:
• In the UDDI+ approach, the principal idea is to make extensions on UDDI register in order to take into account context information during the service discovery. The new UDDI server is called UDDI+ [24].
• The SOAP approach proposed in [25] integrates the context in the SOAP (Simple Object Access Protocol) communication protocol. The goal of this approach is to seek and select services according to a preset context integrated in SOAP.
• In CASD approach (Context Aware Discovery Service) [26], the semantic discovery module determines the services that have a semantic relationship with the user request using specific ontologies.
Table 1 represents a synthesis of the principal approaches previously presented.
It is noticed that semantic approaches, are based on the same technique which consists on calculating the semantic correspondence level between the functional parameters of the services and those requested by the client.
However, one of the big problems of search systems is the definition of a correspondence function between the representation of the proposed service and the user request. This function must model the relevance of the search result to the user [27].
The search relevance is a complex concept. Closely related to user judgment, the relevance is paradoxically evaluated by technologies because the capacity to perceive similarities and analogies is one of the most fundamental aspects of human knowledge. Consequently, to be able to offer, to users, services corresponding to their requirements, a search solution must be based on a relevance model. This model will permit to calculate, for each request, the relevance of its information. Those that have the best relevance score will then be presented to the users in a descending order.
In the majority of the cases, the correspondence between what is offered and what is required is evaluated using a similarity measure to obtain useful information about their compatibilities.
3.4.2. The QSim Similarity Measure
The similarity is defined as “the degree of resemblance between two objects”. Indeed, any system having for goal to analyze or organize automatically a whole of data or knowledge must use, in a form or another, a similarity operator to establish the resemblances or the relations existing between the used data.
In general, a similarity measure is defined in a universe U which can be modelled using a quadruplet: (Ld, Ls, T, FS) [28]:
• Ld the representation language used to describe the data;
• Ls the representation language of the similarities;
• T a whole of knowledge about the studied universe;
• SF the similarity binary function: FS: Ld × Ld à Ls.
A similarity measure is a function which satisfies the following properties:
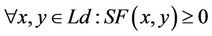 (1)
(1)
 (2)
(2)
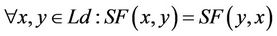 (3)
(3)
In the same way, a dissimilarity measure is defined as a function which checks the following properties:
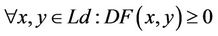 (4)
(4)
 (5)
(5)
 (6)
(6)
It is also possible to transform a similarity measure SF to a dissimilarity measure DF by using the following relation:
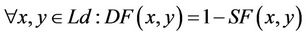 (7)
(7)
Several similarity measures were proposed in various applications fields like similarity for textual data [29,30], similarity for intrusion detection [31] and similarity for Web services discovery [14].
A basic similarity measure is useful to define the resemblance rate between objects (profiles) composed of a set of attributes. To evaluate the similarity between two profiles (for example service and user), we have to define a descriptive common form for all profiles. Each profile is described by m characteristics (X1, X2···Xm) and represented by a binary vector including the existence of each descriptor such as:
 (8)
(8)

Table 1. Synthesis of services discovery systems.
In [14], we have used the Jaccard Similarity Measure (JSM) to discover services in an e-commerce platform. The JSM state as follows:
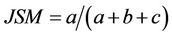 (9)
(9)
We note by:
• a: characteristics proposed by the service and required by the client;
• b: characteristics proposed by the service but not requested by the client;
• c: characteristics requested by the client but not proposed by the service.
The JSM match client profile with the set of services profiles by comparing the values of their parameters. The comparison result is a numerical value indicating the degree of similarity between the client needs and the services parameters.
The Quantitative Similarity Measure (QSim) is proposed in order to fill in the weaknesses of the JSM, detected in our previous work [14]. Among these weaknesses, we have noticed that JSM checks just the existence of a characteristic (we have a binary result: 1 if the parameter exists, 0 else).
Let us take the following example: let P be a group of objects profiles (individuals, documents, Web sites, Web services…). An object X is described by N characteristics: .
.
Each characteristic is either present or absent in each object. Each characteristic is represented by a binary value (0/1).
We consider two objects X and Y with the following properties:
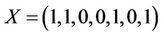
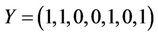
JSM allows to measure the similarity of these two objects and to turn over the value 1 because the same characteristics are present.
Let us consider now a quantitative parameter (we suppose that the first parameter is the room price). Let X be a user requesting a room price not exceeding 70 EUR and Y a hotel proposing rooms at 100 EUR.
Even if with the JSM, used in [14], the degree of similarity between the two objects is of 100%, it is obvious that the two objects are not completely identical.
The profile should correctly represent the reality: each characteristic must be quantified.
In addition, the similarity depends, also, on the similarity of each characteristic (atomic similarity).
Our similarity measure is formalized as follows:
• Let P be a set of profiles (users, documents, services …). An object is described by m contextual characteristics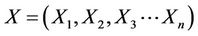 . In our context, let N be a set of services. Each service is composed of a set of concepts, and each concept is described by n characteristics.
. In our context, let N be a set of services. Each service is composed of a set of concepts, and each concept is described by n characteristics.
• Let 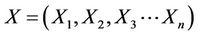 be a profile belonging to P and
be a profile belonging to P and 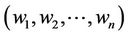 is a set of weights associated to each characteristic where:
is a set of weights associated to each characteristic where:
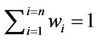 .
.
• We define a threshold in order to present only services that have a rate of similarity with the user profile higher than the threshold defined.
• QSim: P × P à[0,1] is defined as follows:
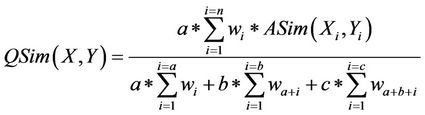 (10)
(10)
where:
• X and Y are two profiles belonging to P;
• a is the set of common characteristics of X and Y;
• b is the set of characteristics existing in X and not existing in Y;
• c is the set of characteristics existing in Y and not existing in X;
• ASim is the atomic similarity between each characteristic of X and Y.
• ASim is defined as follows: ASim: R+ × R+ à [0,1]
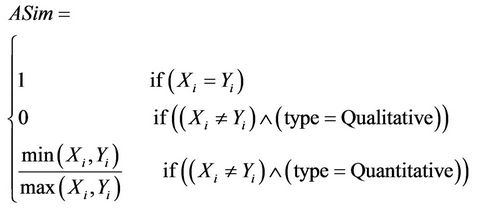 (11)
(11)
ASim checks properties of similarity measures [32].
The distance (dissimilarity) corresponding to QSim is defined as follows: Dist : P × P → [0,1]
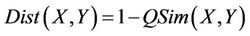 (12)
(12)
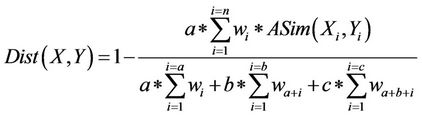 (13)
(13)
3.5. Google Maps for Discovered Services Localization
MLS systems make it possible to produce rich information based on users’ localization. Thus, MLS operators use online cartography solutions to provide mobile users with information about services or data localization.
Many Web Map Services (WMS) are proposed like Google Maps, Bing Maps, Mappy, Géoportail, OpenStreetMap, Yahoo Maps… etc. Basic functionalities are proposed by these services but certain additive functionalities will make the difference between these various solutions. After studying the advantages and disadvantages of these WMS, we chose Google Maps because it seems more interesting in term of functionalities and API suggested.
We represent discovered services (Figure 6) by a descriptive text summarizing the service and we associate a link allowing the user to start a service SMIL multimedia presentation, to have a detailed service’s description.
3.6. Services Adaptation
The multimedia services descriptions are a composition of different multimedia elements like video, image, text, audio…. These media are synchronized, via the SMIL standard, to have a composed and a coherente multimedia document, making the information richer than a simple multimedia object.
However, the SMIL document can be too complex so that a terminal having limited capacities cannot treat it and present it correctly. Facing this reality, it is necessary to find mechanisms giving access to information in a form corresponding to the client constraints.
Thus, we have integrated into the m-tourism platform an adaptation solution for heterogeneous environments called AdaMS for Adaptation Multimedia System [33]. The adaptation system allows clients to reach various multimedia descriptions according to their profiles. Various adaptation techniques were used to adapt services presentations to users’ environments, these techniques are presented in [33].
The adaptation system allows:
• The management of contents heterogeneity: The platform adapts services descriptions so they can be used by terminals with limited capacities (according to clients profiles).
• The creation of services’ versions: For each requested description, the adaptation system create a new version according to the user profile.
• The management of users’ profiles: The adaptation system manages information about the preferences and the environment of the users. An approach was proposed in [34] to generate automaticly and to manage clients profiles.
3.7. SeNeCom: An E-Negotiation Module for the M-Tourism Platform
The negotiation of services in the web is a very important axis that has valuable effects in different domains. This process can be seen through several applications but the common point is the client’s satisfaction.

Figure 6. Presenting discovered services via a WMS.
Thus, we enriched our SDP with an e-negotiation stage. When a client (an m-tourist) is interested by a service he can start a negotiation process to reach a compromise or agreement to the satisfaction of both parties.
In other words, the negotiation process allows the system to find an agreement between the client and the services’ provider.
The e-negotiation process, implemented in SeNeCom (Services Negotiation Component) is based on an automaton to direct the negotiation between the two entities and the system [14].
This automatic negotiation should have the same logical rules as a human negotiation. Thus, when the negotiation is started, it is necessary to keep in mind the objectives of the provider. Every time SeNeCom make new propositions (concession), it is necessary to be sure that these propositions are in the objectives of the provider.
The negotiation automaton is composed of a set of states that determines the activities of the client and the server and an alphabet that represents the exchanged information.
4. QSim Evaluation
In order to prove the relevance of QSim, we compared the results given by our measure with the results given by JSM.
4.1. Test Environment
Let S be a set of ten services (SV1 to SV10) and U a set of five users (U1 to U5) with different requests.
The objective of the tests is to confront the two similarity measures (JSM and QSim) and to compare the obtained results with the distance of Manhattan.
This distance indicates the dissimilarity between the users’ needs and the proposed services. The dissimilarity is calculated with the following formula:
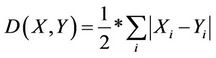 (14)
(14)
4.2. Test results
Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 represent the similarity degrees obtained between each user request and the various services, using QSim and JSM during the discovery process.
Figure 12 indicates the number of returned services for each request. In the bar chart we posted only services which have a similarity degree higher than 50%, i.e. that half of the user needs are satisfied by the service.
The first remark relates to the results obtained by JSM. We note, according to the histograms, that the similarity degree is always high even if there is not a big correspondence between the user request and the service.

Figure 7. Similarity results for U1 request.
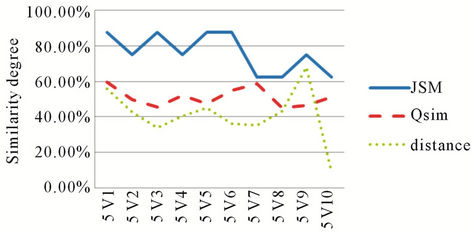
Figure 8. Similarity results for U2 request.
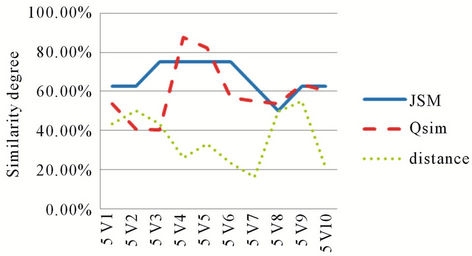
Figure 9. Similarity results for U3 request.
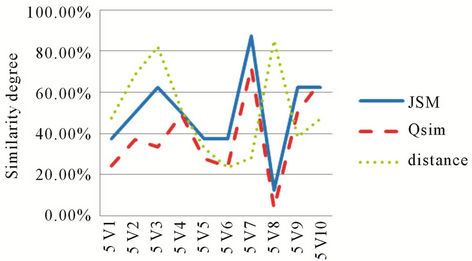
Figure 10. Similarity results for U4 request.
That is due principally to the fact that JSM tests only the existence of the requested attribute in the service, without taking into account its value. In this case, we have some examples: User 1 with Service 5 (an 87.5%
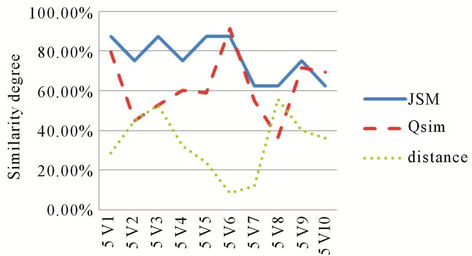
Figure 11. Similarity results for U5 request.
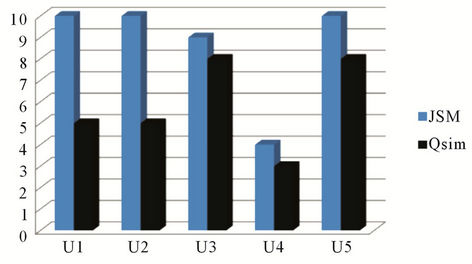
Figure 12. Number of discovered services satisfying at least 50% of the users’ needs.
similarity degree with only one common attribute), User 1 with Service 3 (an 87.5% similarity degree with two common attributes), User 2 with Service 1 (an 87.5% similarity degree with two common attributes), User 3 with Service 3 (an 75% similarity degree with one common attribute)...
Contrary to JSM curves, we note that the values represented by QSim curves are more realistic if we compare the set of services and the users’ requests.
We also note that the values given by the QSim are in inverse proportion to the values given by the distance measure and reflect the real degree of correspondence. Indeed, we notice that the more important the values given by our measurement are (high degree of similarity) and the more we have small values concerning the distance (low dissimilarity) thanks to the quantification of the services attributes by QSim.
As a result, we note that the number of discovered services (Figure 12) with the QSim is noticeably lower than the number of discovered services with JSM (with a threshold of similarity of 50%). Thus, we can say that our quantitative measure makes it possible to refine services search and to propose to users only services which really correspond to their needs.
5. Conclusion and Perspectives
In this paper, we have presented a new delivery platform, based on users’ localization, for m-tourism services. The m-tourism system is based on the SOA architecture.
Travel agencies, assuming the role of services provider, have to describe their services to facilitate the search process. Moreover, providers can describe their services with SMIL multimedia presentations, making the service description richer than a textual description.
On the client side, we propose a search engine based on a mathematical metric, to determine the correspondence degree between the client request and the service description. This correspondence is quantified using a quantitative similarity measure, which is more adapted to services discovery than the JSM used previously.
Moreover, in view of the importance of localization in services detection, we included the tourists’ localization as a new component of their profiles.
The perspectives of this work are manifold:
• It will be interesting to exploit a multi-agents system for a distributed UDDI architecture. The aim is to use number of agents, in various SLC, to refine the search result.
• We are also planning to integrate SMIL editor [35] to assist travel agencies to develop their SMIL services descriptions step by step, while insuring at every stage the validity of the current state of the multimedia document. The aim is to propose an easy-to-use temporal environment which can satisfy a wide range of users.
These are the research directions that will guide our future work.
REFERENCES
- C. Boonstra, G. Van Knippenbergh and S. Meijers, “Location Based Services on Mobile Internet,” White Paper Open Mobile Internet initiative OMI2, 2008. http://www.omi2.nl/wp-content/uploads/2008/12/omi-whitepaper-on-lbs-nov-2008.pdf
- D. Bartlett, “Software Blanking for OTDOA Positioning,” Proceedings of the 16th 3GPP TSG-RAN Meeting, Florida, 4-7 June 2002, pp. 1-7.
- S. Fischer and A. Kangas, “Time-of-Arrival Estimation for E-OTD Location in GERAN,” Proceedings of the 12th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications, San Diego, 30 September-3 October 2001, pp. 121-125.
- D. K. Elliott and C. J. Hegarty, “Understanding GPS: Principles and Applications,” 2nd Edition, Artech House Publisher, Boston, 2005.
- C. Steinfield, “The Development of Location Based Services in Mobile Commerce,” In: B. Preissl, H. Bouwman and C. Steinfield, Eds., E-Life after the Dot Com Bust, Springer Verlag, Berlin, 2004, pp. 177-198.
- N. Boulos, “Analyse, Définition et Conception d’une Solution de Sécurité de la Voix,” DEA Thesis, SAINTJOSEPH University, Beyrouth, 2003.
- J. Borkowski, J. Niemela and J. Lempiainen, “Performance of Cell ID+RTT Hybrid Positioning Method for UMTS Radio Networks,” Proceedings of the 5th European Wireless Conference Mobile and Wireless Systems beyond 3G, Barcelona, 24-27 February 2004, pp. 24-27.
- G. Klyne, F. Reynolds, C. Woodrow, H. Ohto, J. Hjelm, M. H. Butler and L. Tran, “Composite Capability/Preference Profiles (CC/PP): Structure and Vocabularies 1.0,” World Wide Web Consortium (W3C) Recommendation, 2004. http://www.w3.org/TR/CCPP-structvocab/
- C. L. Velasco, M. Villanova, J. Gensel and H. Martin, “Services Web Adaptés aux Utilisateurs Nomades,” Proceedings of the 2nd French-Speaking Conference on Mobility and Ubiquity Computing, Grenoble, 31 May-3 June 2005, pp. 133-136.
- World Wide Web Consortium. http://www.w3.org
- D. Bulterman, “Synchronized Multimedia Integration Language (SMIL2.0),” W3C Recommendation, 2001. http://www.w3.org/TR/SMIL2
- M. Handley, H. Schulzrinne, E. Schooler and J. Rosenberg, “SIP: Session Initiation Protocol,” IETF Request for Comments RFC 2543, 1999. http://www.ietf.org/rfc/rfc2543.txt
- M. Handley and V. Jacobson, “SDP: Session Description Protocol,” IETF Request for Comments RFC 2327, 1998. http://www.ietf.org/rfc/rfc2327.txt
- F. M. Bouyakoub and A. Belkhir, “A Similarity Measure for the Negotiation in Web Services,” Multimedia Tools and Applications, Vol. 50, No. 2, 2009, pp. 279-312. doi:10.1007/s11042-009-0383-8
- L. Maesano, C. Bernard and X. Le Galles, “Services Web Avec J2EE et. NET: Conception et Implémentation,” Eyrolles, Eyrolles, 2003.
- D. Booth, H. Haas, F. McCabe, E. Newcomer, M. Champion, C. Ferris and D. Orchard, “Web Services Architecture,” W3C Web Services Architecture Working Group note, 2004. http://www.w3.org/TR/ws-arch/
- M. Chelbabi, “Découverte de Services Web Sémantiques: Une Approche Basée sur le Contexte,” Master Thesis, CERIST, Algiers, 2006.
- P. Rompothong and T. Senivongse, “A Query Federation of UDDI Registries,” Proceedings of the 1st International Symposium on Information and Communication Technologies, (ISICT 03), 24-26 September, Dublin, 2003, pp. 561-566.
- P. Palathingal and S. Chandra, “Agent Approach for Service Discovery and Utilization,” Proceedings of the 37th Annual Hawaii International Conference on System Science HICSS-37, Hawaii, 5-8 January 2004, pp. 1-9.
- D. Martin, M. Burstein, J. Hobbs, O. Lassila, D. McDermott, S. McIlraith, et al., “Owl-S: Semantic Mark-Up for Web Services,” W3C Member Submission, 2004. http://www.w3.org/Submission/OWL-S/
- E. Motta, J. Domingue, L. Cabral and M. Gaspari, “Irs-II: A Framework and Infrastructure for Semantic Web Services,” Proceedings of the Second International Semantic Web Conference (ISWC 2003), Florida, 20-23 October 2003, pp. 306-318.
- L. Vu, M. Hauswirth and K. Aberer, “Towards p2p-Based semantic Web Service Discovery with QOS Support,” Proceedings of the International Workshop on Business Process Management (BPM 2005), Nancy, 6-7 September 2005, pp. 18-31.
- K. Verma, R. Mulye, Z. Zhong, K. Sivashanmugam and A. Sheth, “Speed-R: Semantic p2p Environment for Diverse Web Service Registries,” W3C Technical Report, 2004. http://webster.cs.uga.edu/~mulye/SemEnt/Speed-R.html
- S. Pokraev, J. Koolwaaij and M. Wibbels, “Extending UDDI with Context-Aware Features Based on Semantic Service Descriptions,” Proceedings of the International Conference on Web Services (ICWS '03), Nevada, 23-26 June 2003, pp. 184-190.
- M. Keidl and A. Kemper, “Toward Context/Aware Adaptable Web Services,” Proceedings of the 13th World Wide Web Conference (W3C), New York, 19-21 May 2004, pp. 55-65.
- S. Kouadri-Mostéfaoui and G. Kouadri-Mostéfaoui, “Towards a Contextualization of Service Discovery and Composition for Pervasive Environments,” Proceedings of the AAMAS workshop on Web Services and Agent-Based Computing (WSABE’2003), Melbourne, 14-18 July 2003.
- M. F. Bruandet and J. P. Chevallet, “Utilisation et Construction de Base de Connaissances Pour la Recherche d’Information,” In: M. H. Stefanini and E. Gaussier, Eds., Assistance Intelligente à la Recherche d’Information, Hermès Sciences Edition, 2003, pp. 85-118.
- G. Bisson, “La Similarité: Une Notion Symbolique/Num- érique,”Apprentissage Symbolique-Numérique (Tome 2) Editions CEPADUES, 2000, pp. 169-201.
- M. Rajman, “Similarités Pour Données Textuelles,” Proceedings of the 4th Journées Internationales d’Analyse Statistique des Données textuelles JADT-98, Nice, 19-21 February 1998, pp. 545-556.
- M. M. Richter, “Classification and Learning of Similarity Measures,” In O. Opitz, B. Lausen and R. Klar, Eds., Studies in Classification, Data Analysis and Knowledge Organization, Springer Verlag, Berlin, 1992.
- A. Belkhirat, A. Bouras and A. Belkhir, “A New Similarity Measure for the Anomaly Intrusion Detection,” Proceedings of the 3rd International Conference on Network and System Security (NSS2009), Queensland, 19-21 October 2009, pp. 431-436.
- A. Belkhirat and A. Belkhir, “A New Similarity Measure for the Profiles Management,” Proceedings of the 10th International Conference on Computer Modelling and Simulation UKSIM '11, Cambridge, 30 March-1 April 2011, pp. 255-259.
- F. M. Bouyakoub and A. Belkhir, “AdaMS: An Adaptation Multimedia System for Heterogeneous Environments,” Proceedings of the 2nd IFIP International Conference on New Technologies, Mobility and Security (NTMS 2008), Tangier, 5-7 November 2008, pp. 42-46.
- F. M. Bouyakoub and A. Belkhir, “Automatic Generation of User’s Profiles for Location-Based Adaptation of Multimedia Documents,” Proceedings of the 1st IEEE International Workshop on Generation C Wireless Networks (GenCWiNets'08), Texas, 7-9 December 2008, pp. 400- 405.
- S. Bouyakoub and A. Belkhir, “SMIL BUILDER: An Incremental Authoring Tool for SMIL Documents,” ACM Transactions on Multimedia Computing, Communications, and Applications, Vol. 7, No. 1, 2011, pp. 1-30. doi:10.1145/1870121.1870123