Theoretical Economics Letters
Vol.06 No.04(2016), Article ID:69165,20 pages
10.4236/tel.2016.64071
Heteroskedasticity-Consistent Covariance Matrix Estimators in Small Samples with High Leverage Points
Esra Şimşek1*, Mehmet Orhan2
1Department of Economics, Istanbul Bilgi University, Istanbul, Turkey
2Department of Economics, Fatih University, Istanbul, Turkey

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 26 April 2016; accepted 25 July 2016; published 28 July 2016
ABSTRACT
The aim of this paper is to demonstrate the impact of high leverage observations on the performances of prominent and popular Heteroskedasticity-Consistent Covariance Matrix Estimators (HCCMEs) with the help of computer simulation. Firstly, we figure out high leverage observations, then remove them and recalculate the HCCMEs without these observations in order to compare the HCCME performances with and without high leverage points. We identify high leverage observations with the Minimum Covariance Determinant (MCD). We select from among different covariates and disturbance term variances from the related literature in simulation runs in order to compare the percentage difference between the expected value of the HCCME and true covariance matrix as well as the symmetric loss function. Our results revealed that the elimination of high leverage (high MCD distance) observations had improved the HCCME performances considerably and under some settings substantially, depending on the degree of leverage. We hope our theoretical findings will be benefited for practical purposes in applications.
Keywords:
Heteroskedasticity-Consistent Covariance Matrix Estimator, HCCME, Robust Estimation, MCD, Monte Carlo, Simulation, Loss Functions

1. Introduction
An important assumption of the classical linear regression model is homoskedasticity, that is, the variances of the disturbance terms are the same. But many empirical studies have shown that this assumption is not often plausible and realistic. Although the method of least squares is still used under heteroskedasticity, the covariance matrix estimators of the OLS coefficient estimates are not unbiased any more. Therefore, inference based on heteroskedastic error terms maybe misleading. That is why White (1980) [1] has made use of earlier studies by Eicker (1967) [2] to introduce his asymptotically unbiased Heteroskedasticity-Consistent Covariance Estimator (HCCME) for the covariance matrix in his influential 1980 Econometrica paper. But this estimator is classified as biased in small samples (see [3] ).
Many efforts to diminish the bias of the HCCMEs have boiled down to six prominent estimators studied extensively in the literature. Hinkley (1977) [4] has made a degree of freedom arrangement to White’s estimator and multiplied all squared residuals by a coefficient. Horn et al. (1975) [5] have weighted the squared residuals by the vertical entries of the hat matrix. Similarly, the one-delete jackknife estimator popularized by Efron (1982) [6] used the squares of these entries as weights in an HCCME approximated to the original one-delete-jackknife estimator. The last two HMMCEs by Cribari-Neto (2004) [7] and Cribari-Neto et al. (2007) [8] are relatively new. These two estimators attempted to alleviate the bias due to high leverage observations in a more complicated way. The only exception to correcting for heteroskedasticity is Mishkin (1990) [9] who simulated on financial data. MacKinnon (2011) [10] includes a very proper review of HCCMEs. The idea of mitigating the negative impact of high leverage observations is common to almost all HCCMEs which bring the extra advantage of less bias but surprisingly White’s estimator is the most frequently used one by practitioners (see [11] ). The small-sample bias of White’s estimator inherited to all HCCMEs harms statistical inference based on all tests, especially the t-test that uses the standard error of the coefficient estimate. All hypothesis tests and confidence intervals constructed with these standard errors are misleading.
Almost all papers on HCCMEs mention the adverse effect of high leverage observations and appreciate the balance of covariates (To cite some, see [3] , [7] , [10] , [12] , and [13] ). The bias is lower if the design matrix is balanced and increases as there are more high leverage observations. The other point is the magnitude of the leverage that can be measured by the vertical entries of the hat matrix. As pointed out by Rousseeuw and Leroy (1987) [14] , many data sets suffer from high leverage observations. One way to cope with high leverage observations is to use the residuals by robust regression techniques (see [12] , [15] and [16] ).
In this study, we suggest another approach to alleviate the negative effect of high leverage observations on HCCME performances. We suggest that detecting and removing high leverage points properly, improves the HCCME performances. Indeed, the detection of these points is not easy since a few such observations can act together and mask them. We use Minimum Covariance Determinant (MCD) to detect the observations with high distances that lie far away from the cluster of regressors. The MCD, developed by Rousseeuw and Van Driessen (1999) [17] , is shown to be free from masking effect and has the highest breakdown value possible as well as efficiency. We remove these observations from the data set in order to calculate the HCCMEs with and without the high leverage points and document better results. We coded the procedure explained in Rousseeuw and Van Driessen (1999) [17] to classify these points.
Our paper simply generates design matrices and error term variances from a variety of distributions first and tests the performances of the HCCMEs in estimating the true covariance matrix. And then the high leverage points in the data set are detected and removed. The HCCMEs are run one more time to compare performances. Our simulation runs document that the removal of high leverage observations increases the performance of HCCMEs substantially. Section 1 of the article is the brief introduction. Section 2 explains the model and HCCMEs. Section 3 explains how the robust method is applied. Section 4 includes the simulation setups and results. Finally, Section 5 concludes.
2. Heteroskedasticity-Consistent Covariance Matrix Estimators
We consider the linear model 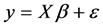 in which is
in which is 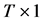 vector of dependent variable,
vector of dependent variable, 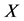 is matrix of regressors, and
is matrix of regressors, and 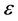 is
is 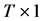 vector of disturbance terms. The disturbance terms are assumed to have flexible variances to let heteroskedasticity, i.e.
vector of disturbance terms. The disturbance terms are assumed to have flexible variances to let heteroskedasticity, i.e. 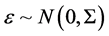 where
where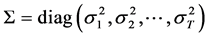 . Note that the disturbance terms are pairwise uncorrelated.
. Note that the disturbance terms are pairwise uncorrelated.
We define the covariance matrix belonging to the OLS coefficient estimator of 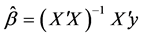 as
as
 . Here, the unique unknown is the
. Here, the unique unknown is the 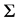 matrix whose diagonal
matrix whose diagonal
elements are the variances of the error terms. If the variances of the error terms are assumed to be equal, then 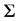 is estimated by the OLS as
is estimated by the OLS as 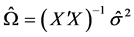 where
where 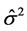 is the variance of the error terms estimated as
is the variance of the error terms estimated as
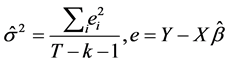 .
.
Several attempts to estimate 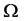 led to the HCCMEs we list with references as:
led to the HCCMEs we list with references as:
 , by White (1980) [1] ,
, by White (1980) [1] ,
 , by Hinkley (1977) [4] ,
, by Hinkley (1977) [4] ,
 , by Horn et al. (1975) [5] ,
, by Horn et al. (1975) [5] ,
 , by Efron (1982) [6] ,
, by Efron (1982) [6] ,
 , by Cribari-Neto (2004) [7] ,
, by Cribari-Neto (2004) [7] ,
 , by Cribari-Neto et al. (2007) [8] ,
, by Cribari-Neto et al. (2007) [8] ,
where H is the hat matrix, ,
, with
with  in HC4 and
in HC4 and
 in HC5. Indeed, HC3 resembles the one-delete jackknife estimator whose for-
in HC5. Indeed, HC3 resembles the one-delete jackknife estimator whose for-
mula is provided to MacKinnon and White (1985) [18] by an anonymous referee.
3. Robust Estimation
The model we introduced in the previous section can be estimated by OLS which still preserves its popularity due to its favorable statistical properties and ease of computation. But OLS is very sensitive to outliers and bad leverage points. One can change the OLS estimate of a coefficient even playing with one of the observations
arbitrarily which means that the breakdown value of OLS is . The main purpose of robust regression techniques
. The main purpose of robust regression techniques
is to protect the estimation against misguiding results due to outliers and bad leverage points. These outliers maybe coming from recording or measurement errors and if that is the case then one has to get rid of bad effects stemming from them. If there are not any such mistakes and these exceptional observations belong to the original data set, one must be careful in preserving them since they may explain some important facts about the data generating processes.
Many methods of robustness generated so far suffer from shortcomings, the most important of which is the weakness of detecting the outliers and bad leverage points. In many cases what we face is the coordinated action of such observations to group themselves where they are able to mask their deceiving behavior. Although, many robust techniques fail in such cases, what we use, namely the MCD, in this study is guaranteed to come over this handicap. The observations in any regression analysis can be classified into four (see [14] ):
1) Regular observations with internal X and well-fitting y.
2) Vertical outliers with internal X but non-fitting y.
3) Good leverage points with outlying X and well-fitting y.
4) Bad leverage points with outlying X and non-fitting y.
Good leverage points are very valuable to OLS since they pull the regression line to the target. On the other hand, bad leverage points and outliers are extremely harmful since they strongly pull the estimated regression line to the wrong direction. With this classification in hand, the robust method must be able to make diagnosis to classify each observation into the four categories above correctly. In this study we make use of MCD to detect the observations with high distances of the covariates.
More technically, the MCD initiated by Rousseeuw and Van Driessen (1999) [17] has the objective of finding h observations out of T, with lowest determinant of the covariance of regressors. The estimate for the center is the average of these h observations and the MCD estimate of spread is the covariance matrix. Indeed, the objective of MCD is to find h observations that forms a subset, say , of the T observations (here we pick just the regressors, we do not include the response variables in MCD calculations) in such a way that the average of these h
, of the T observations (here we pick just the regressors, we do not include the response variables in MCD calculations) in such a way that the average of these h
observations is L where ,
, is the
is the  observation of regressors. This is a statistic for the location of the regressors. The statistic for the covariance is S where
observation of regressors. This is a statistic for the location of the regressors. The statistic for the covariance is S where  The distance for
The distance for
the  observation,
observation,  , is defined on both location and covariance statistics,
, is defined on both location and covariance statistics,  The details can be found in Rousseeuw and Van Driessen (1999) [17] .
The details can be found in Rousseeuw and Van Driessen (1999) [17] .
We have coded a GAUSS procedure to return the observations with lowest MCD distances and included it in the Appendix. We flag the robust MCD distances that are greater than  critical values and remove them to improve the HCCME performances (see Zaman et al. (2001) [19] for a decent application similar to ours).
critical values and remove them to improve the HCCME performances (see Zaman et al. (2001) [19] for a decent application similar to ours).
4. Simulation Runs
The literature includes voluminous papers with different simulation designs to test the HCCME performances, almost all papers stated in the Introduction can be cited. The main shortcoming of these designs is their peculiarity to settings focused without generalizations. In order to cover the behaviors of different design matrices and error term variances we made use of patterns listed in Table 1. The distributions we included for the covariates and error term variances are selected to reflect progressive layers of leverage and error term variances. The simple regression model we use in simulation runs is:
 . (1)
. (1)
We have fixed  and used
and used  to account for the degree of heteroskedasticity. Note that λ returns 1 under homoskedasticity and becomes higher in case of more intensive heteroskedasticity. The simulation program is coded in GAUSS 7 and we set the Monte Carlo sample size to 10,000 replications.
to account for the degree of heteroskedasticity. Note that λ returns 1 under homoskedasticity and becomes higher in case of more intensive heteroskedasticity. The simulation program is coded in GAUSS 7 and we set the Monte Carlo sample size to 10,000 replications.
The program first generates the design matrix entries and then the error terms with variances listed in Table 1. Then dependent variable values are fixed according to the simple regression model. The MCD procedure code is run to detect the covariates with high leverages (i.e. with MCD distances larger than the critical  values). These detected observations are removed from the data set. We estimate
values). These detected observations are removed from the data set. We estimate  by HCCMEs with the original (full) sample and the sample without high leverages (short sample). Since the true covariances are different for full and short samples, we calculated the percentage differences to set the ground for comparisons. We calculated the quasi-t statistics which are quite common in such studies but did not report them since they are parallel to the percentage deviations. We also prepared the symmetric, entropy and quadratic losses but preferred just reporting the symmetric loss in order to save space because the losses are similar to each other and the percentage deviations as well.
by HCCMEs with the original (full) sample and the sample without high leverages (short sample). Since the true covariances are different for full and short samples, we calculated the percentage differences to set the ground for comparisons. We calculated the quasi-t statistics which are quite common in such studies but did not report them since they are parallel to the percentage deviations. We also prepared the symmetric, entropy and quadratic losses but preferred just reporting the symmetric loss in order to save space because the losses are similar to each other and the percentage deviations as well.
Tables 2-6 are prepared to display the percentage deviations of the estimators from the true values for the diagonal entries of . Cases 1 - 5 are corresponding to covariates following patterns explained in the first column
. Cases 1 - 5 are corresponding to covariates following patterns explained in the first column

Table 1. Covariates and error term variances.
Table 2. HCCME performances at full and short samples, Case 1.
of Table 1. For each such covariate pattern the error term variances are generated from the second column of Table 1 (Cases a, b, c, and d) in which c0 = 0.1, c1 = 0.2, c3 = 0.3 and d0 = 0.285. L is the number of high leverage observations removed. The column heads are F for full sample and S for short sample (that is free from the high leverage observations). Since this paper has the specific purpose of HCCME performances in small samples we have used the sample sizes of T = 20, 30, 40, 50, 60, 80 and 100.
Table 2 displays the performances of the six HCCMEs for short and full samples. In this setting the covariates are intentionally generated from the uniform distribution to have no leverage point of the covariates. In Case a, homoskedasticity with error term variances set equal to 1, removing the occasional high leverage points or not does not make much difference. Full and short samples are having similar percentage errors. We generate different covariates each time we run the simulation and keep records of the covariates. One point that deserves attention is the huge percentage errors belonging to HC4 and HC5 when sample size is limited to 20. Furthermore, HC0 by White has the next greatest percentage difference as well as HC3, the top performers are HC2 followed by HC1. The other point to mention is that the estimators are sometimes biased downward and sometimes upward indicated by positive and negative differences.
We introduce heteroskedasticity in Case b. This time again the percentage differences for short samples do not perform better than the full sample estimates when sample size is large over 50 since the high leverage observations are limited. And if they exist the leverages indicated by MCD distances are very low. But short sample HCCMEs are slightly better when T < 50 and especially when T = 20.
For Case c, the short sample estimates are better than the full sample estimates, and the difference is even more significant when sample size gets lower. Note that the estimation performance becomes much better when the sample size increases. We note the superior performance of HC2 and the inferior performance of HC4 and HC5.
Table 3. HCCME performances at full and short samples, Case 2.
In Case d, the short sample estimates are better than the full sample estimates at almost all sample sizes. The performances are very unstable when T = 20. It is interesting to note that HC4 and HC5 that are claimed to be better than others and introduced more recently, are doing much worse than all others including White’s estimator with its bias proved in small samples.
In Case 2, we generated the covariates from standard normal distribution to have more leverages with higher MCD distances. Short sample estimates are having lower percentage differences than full sample especially when the sample size is small. All estimators perform better when the sample size increases to even 40. The percentage differences more than 10 shrink to less than 3 when T increases to 80. When heteroskedasticity is introduced in Case b, percentage differences at T = 20 and 30 are large, and they become mild soon after T = 50. The largest differences belong to HC4 and HC5 at T = 20, they are more than 2.5 times the true variances. Although the percentage differences get lower, there are surprises possible, for instance HC4 and HC5 have percentage differences larger than 20% even at T = 80. Similar comments are true for Cases c and d.
In Case 3, we generate covariates from t distribution with 3 degrees of freedom. Note that the density of this distribution has thick tails to let high leverage covariates. The short sample estimates are slightly better than the full sample ones with high leverage points. The performance of the estimators become better as the sample size increases and the difference becomes smaller in case of homoskedasticity for the intercept terms variance. Regarding the variance of the slope coefficient, the estimates without the high leverage observations are much better especially at small sample sizes of 20 and 30. This difference becomes lower as the sample size increases. This difference is preserved in Case b. The performance becomes much more apparent in Case c when sample size is 20 or 30. Note that the best performer is HC2 followed by HC3 regardless of the sample being large or small. The same is for Case d as well.
Table 4. HCCME performances at full and short samples, Case 3.
In Case 4, the covariates are generated from the lognormal distribution to amplify the number and degree of leverages. This time the differences in performances are drastic. HC4 and HC5 estimators are yielding estimates much higher than the true values, indeed, we have observed much larger numbers and preferred to report them as “>1000”, this means the estimated value is more than ten times the true value. More interestingly this sometimes happens at sample sizes of 80 and even 100. Note that HC2 comes up with reasonable estimates when the high leverage observations are removed and even HC2 as the best performer becomes failing as there are high leverage covariates. The situation becomes even worse when there is heteroskedasticity introduced in Cases c and d. The other point that deserves attention is the extra failure in the performance of HC4 and HC5. These findings suggest that one should refrain from using these estimators especially when there is high leverage and heteroskedasticity simultaneously.
Finally, in Case 5, we have the covariates from the ratio of two standard normals to let very large and very small values possible. The man goal is to have arbitrary number of high leverages with arbitrary degrees. This time we observe the failure of HC5 and HC4 again in Case a of homoskedasticity. All other HCCMEs have good performances especially when the sample size is greater than 30. When heteroskedasticity is introduced in Case b, the full sample estimates become much worse and the short sample HCCMEs are much better compared to them. Again HC2 is the best followed by HC1, HC3, and HC0. Both HC4 and HC5, but especially HC5, are too bad. The slope coefficient’s variance in Case d deserves the attention since almost all estimators fail very badly in full sample, this case is a proper example of the benefit from detecting and eliminating the high leverage points. Note that with this removal the full sample percentage differences that are greater than 1000 are tamed to deviations less than 20%.
The computer code run is ready to be sent in case one asks it from us for all settings. The initializations in the
Table 5. HCCME performances at full and short samples, Case 4.
program are modified to try different alternatives. The regressors and the variance patterns are available upon request to return the same simulation results as well.
Although the percentage differences give a very sound idea of the HCCME performances in full and short samples, we include the symmetric loss as well in Table 7. The symmetric loss can be formulated as
 due to Sun and Sun (2005) [20] and can be used to assess the performances.
due to Sun and Sun (2005) [20] and can be used to assess the performances.
Case 1, covariates generated from the Uniform distribution, does not have high leverage(s) or the high leverage observations are very limited. That is why the short and full sample losses are very close. Still, the overall picture reveals that the short sample symmetric losses are slightly lower. The difference between short and full samples becomes significant when the covariates are generated from the Normal Distribution in Case 2. We note that the symmetric losses of the full sample are substantially lower than the full sample for all patterns of heteroskedasticity. The differences are more when the sample sizes are low at T = 20 and 30. We skip Case 3 with similar results in order to save space and in Case 4, the difference becomes massive, especially at lower sample sizes. Indeed, these results are in line with the Tables including the percentage differences. The differences between HCCME performances reflected to the symmetric losses are drastic, sometimes more than 20 fold (HC0 in Case 4a, T = 20 and without loose bounds the same Case for HC5). Similar comments are applicable for Case 5 as well. The other point that deserves attention is the increase in symmetric losses of the short sample for HC4 (Table 8).
5. Concluding Remarks
The purpose of this paper is the improvement of the HCCMEs with the removal of the high leverage points and
Table 6. HCCME performances at full and short samples, Case 5.
this purpose is proven to be realized under the settings we used. Although there are exceptional cases where full sample performance is better than the short sample, in general the elimination of high leverage observations helps improve the HCCME performances.
The study at the same time compares the HCCME performances. According to this comparison, the HCCME by Horn et al. (1975) [5] is the best performer under almost all settings with and without the high leverage points. This estimator is followed by Hinkley’s (1977) [4] estimator. The improvement in HCCME by Cribari-Neto (2004) [7] and Cribari et al. (2007) [8] makes it a good competitor in the absence of high leverage observations. If the high leverage observations are not removed, both HC4 and HC5 are performing too badly. And Efron’s (1982) [6] jackknife estimator appears as sometimes the second and sometimes the third best performer depending on the setting. Regarding the underestimation and overestimation of the HCCMEs, the percentage differences we report for White’s HCCME are always negative which suggests that HC0 underestimates the true covariance matrix. The same is true for HC1 despite of a few exceptional occasions of 0 and positive figures whereas HC2 is negative for the majority of the cases. To the contrary, HC3, HC4, and HC5 are almost always positive. They overestimate the true covariance. Note that the removal of the high leverage points places HC4 and HC5 to the list of the top three performers.
The other contribution of the paper is the surprise faced in the performance of the two HCCMEs introduced recently, HC4 and HC5. We document that these two estimators are worst performers and the percentage differences of these estimators are dramatically high where HC4 is slightly better than HC5. This finding is in line with MacKinnon (2011) [10] .
Under homoskedasticity, OLS is the best performer and there is no need to make use of the HCCMEs. Also there is not a significant improvement of detecting and removing the high leverage points. For the remaining
Table 7. Symmetric losses of HCCMEs, Cases 1 and 2.
cases we scanned over several patterns of covariates and error term variances in the literature and came up with the five cases of covariates and four cases of error term variances displayed in Table 1. We made use of the loss functions for comparisons and reported the figures of the symmetric loss. The results based on loss functions are similar to the percentage differences.
In order to let any interested reader repeat our results we intended to provide the covariates and the error term variances in the Appendix, but these vectors are so lengthy that we cannot present them in this paper, rather we can send it to the interest reader in case they ask from us.
The main shortcoming of comparing the HCCMEs with the help of the simulation is that the covariates and error term variances generated do not give full insight for a complete analysis. It should be borne in mind that simulation studies rely on certain types of X and  settings, therefore one cannot generalize the outcomes. Although we have selected several different patterns to produce covariates and error term variances to have a more detailed understanding of the comparisons, there may be other settings with different conclusions.
settings, therefore one cannot generalize the outcomes. Although we have selected several different patterns to produce covariates and error term variances to have a more detailed understanding of the comparisons, there may be other settings with different conclusions.
Although we have documented that the removal of high leverage points may substantially improve the HCCME performances, we do not suggest practitioners to apply the procedure directly. But rather, we do advise investigating these unusual observations first. There may be occasions where these particular observations indicate some unforeseen aspects of the reality. And if one deleted these observations without questioning the data generation process, these aspects can never come up to the surface for exploration.
Finally, the performances of the HCCMEs can be much better or worse according to settings of Xs and Σs. Although proof-type studies are better ways to make analysis, this area of study does not yet include such proof-types, and simulations give us a good idea about making the comparisons. This leaves the door open for further research.
Acknowledgements
We would like to thank TUBITAK (Scientific and Technical Research Council of Turkey) for its valuable support to this project (Reference Number: 110K439) as well as organizers and participants of the 13th International
Table 8. Symmetric losses of HCCMEs, Cases 4 and 5.
Conference on Econometrics, Operations Research and Statistics, especially Prof. James MacKinnon who has kindly commented his positive opinion on our paper presented.
Cite this paper
Esra Şimşek,Mehmet Orhan, (2016) Heteroskedasticity-Consistent Covariance Matrix Estimators in Small Samples with High Leverage Points. Theoretical Economics Letters,06,658-677. doi: 10.4236/tel.2016.64071
References
- 1. White, H. (1980) A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity. Econometrica, 48, 817-838.
http://dx.doi.org/10.2307/1912934 - 2. Eicker, F. (1967) Limit Theorems for Regressions with Unequal and Dependent Errors. Proceedings of Fifth Berkeley Symposium on Mathematical Statistics and Probability, Vol. 1, No. 1, 59-82.
- 3. Chesher, A. and Jewitt, I. (1987) The Bias of A Heteroskedasticity-Consistent Covariance Matrix Estimator. Econometrica, 55, 1217-1222.
http://dx.doi.org/10.2307/1911269 - 4. Hinkley, D.V. (1977) Jackknifing in Unbalanced Situations. Technometrics, 19, 285-292.
http://dx.doi.org/10.1080/00401706.1977.10489550 - 5. Horn, S.D., Horn, R.A. and Duncan, D.B. (1975) Estimating Heteroscedastic Variances in Linear Models. Journal of the American Statistical Association, 70, 380-385.
http://dx.doi.org/10.1080/01621459.1975.10479877 - 6. Efron, B. (1982) The Jackknife, the Bootstrap and other Resampling Plans. Society for Industrial and Applied Mathematics, Philadelphia, PA.
http://dx.doi.org/10.1137/1.9781611970319 - 7. Cribari-Neto, F. (2004) Asymptotic Inference under Heteroskedasticity of Unknown Form. Computational Statistics & Data Analysis, 45, 215-233.
http://dx.doi.org/10.1016/S0167-9473(02)00366-3 - 8. Cribari-Neto, F., Souza, T.C. and Vasconcellos, K.L.P. (2007) Inference under Heteroskedasticity and Leveraged Data. Communications in Statistics—Theory and Methods, 36, 1877-1888.
http://dx.doi.org/10.1080/03610920601126589 - 9. Mishkin, F.S. (1990) Does Correcting for Heteroscedasticity Help? Economics Letter, 34, 351-356.
http://dx.doi.org/10.1016/0165-1765(90)90144-P - 10. MacKinnon, J.G. (2011) Thirty Years of Heteroskedasticity-Robust Inference. Queen’s Economics Department Working Paper No. 1268.
- 11. Long, J.S. and Ervin, L.H. (2000) Using Heteroscedasticity Consistent Standard Errors in the Linear Regression Model. The American Statistician, 54, 217-224.
- 12. Lima, M.C., Souza, T.C., Cribari-Neto, F. and Fernandes, G.B. (2010) Heteroscedasticity-Robust Inference in Linear Regressions. Communications in Statistics-Simulation and Computation, 39, 194-206.
http://dx.doi.org/10.1080/03610910903402572 - 13. Chesher, A. (1989) Hájek Inequalities, Measures of Leverage and the Size of Heteroskedasticity Robust Wald Tests. Econometrica, 57, 971-977.
http://dx.doi.org/10.2307/1913779 - 14. Rousseeuw, P.J. and Leroy, A.M. (1987) Robust Regression and Outlier Detection. Wiley Series in Probability and Mathematical Statistics, John Wiley, New York.
http://dx.doi.org/10.1002/0471725382 - 15. Furno, M. (1996) Small Sample Behavior of a Robust Heteroskedasticity Consistent Covariance Matrix Estimator. Journal of Statistical Computation and Simulation, 54, 115-128.
http://dx.doi.org/10.1080/00949659608811723 - 16. Furno, M. (1997) A Robust Heteroscedasticity Consistent Covariance Matrix Estimator. Statistics, 30, 201-219.
http://dx.doi.org/10.1080/02331889708802610 - 17. Rousseeuw, P.J. and Van Driessen, K. (1999) A Fast Algorithm for the Minimum Covariance Determinant Estimator. Technometrics, 41, 212-223.
http://dx.doi.org/10.1080/00401706.1999.10485670 - 18. MacKinnon, J.G. and White, H. (1985) Some Heteroskedasticity Consistent Covariance Matrix Estimators with Improved Finite Sample Properties. Journal of Econometrics, 29, 305-325.
http://dx.doi.org/10.1016/0304-4076(85)90158-7 - 19. Zaman, A., Rousseeuw, P.J. and Orhan, M. (2001) Econometric Applications of High-Breakdown Robust Regression Techniques. Economics Letters, 71, 1-8.
http://dx.doi.org/10.1016/S0165-1765(00)00404-3 - 20. Sun, D. and Sun, X. (2005) Estimation of Multivariate Normal Covariance and Precision Matrices in a Star-Shape Model with Missing Data. Annals of the Institute of Statistical Mathematics, 57, 455-484.
http://dx.doi.org/10.1007/BF02509235
Appendix
/* ************ MCD PROCEDURE STARTS HERE *********** */
proc (1) = mymcd(mcdmat,hperc,chicri);
/* mcdmat includes the covariates X, with dimension nXk, k is the number of independent variables, */
local olddet, newdet, Tproc, kproc, Xproc, Xshort, Lnew, Snew, dists, sortedmat, newcov, outmat, boolvec, Hproc;
/* chicrit is the Chi-square critical value */
/* initializations */
Tproc=rows(mcdmat); kproc=cols(mcdmat);
Hproc=floor(Tproc*hperc+,1); /* number of trimmed observations */
Dists=mcdmat[,,1]; /* just to initiate, starting value not important */
Xshort=mcdmat[1:Hproc,,]; Lnew=(meanc(Xshort))';
newdet=det((Xshort-Lnew)'*(Xshort-Lnew));
olddet=2*newdet;
xproc=mcdmat;
mcdmat=(seqa(1,1,Tproc))~mcdmat;
sortedmat=mcdmat~dists; /* for initialization only */
do while olddet>newdet;
olddet=newdet;
Xshort=sortedmat[1:Hproc,2:(1+kproc)];
Lnew=(meanc(Xshort))'; /* L denoting the location */
Snew=(1/Hproc)*((Xshort-Lnew)'*(Xshort-Lnew));
/* S denoting the scatter */
dists=sqrt(diag((Xproc-Lnew)*inv(Snew)*(Xproc-Lnew)'));
sortedmat=sortc((mcdmat~dists),(kproc+2));
/* Xs rows are sorted according to the distances */
if rank(snew)==kproc;
newdet=det(snew);
else; newdet=olddet;
endif;
endo;
outmat= sortc(sortedmat,1); /* obs with inital sorts and distances */
boolvec=(outmat[,,cols(outmat)]),
outmat=outmat~boolvec;
retp(outmat);
endp;
/* This outmat includes the index of obs~X~distances~booleans */
/* ************ MCD PROCEDURE ENDS HERE *********** */
NOTES

*Corresponding author.