Journal of Mathematical Finance
Vol.05 No.04(2015), Article ID:61264,17 pages
10.4236/jmf.2015.54031
In Search of the Best Zero Coupon Yield Curve for Nairobi Securities Exchange: Interpolation Methods vs. Parametric Models
Lucy Muthoni
Institute of Mathematical Sciences (IMS), Strathmore University, Nairobi, Kenya

Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 18 September 2015; accepted 16 November 2015; published 19 November 2015
ABSTRACT
We seek to determine which yield curve construction method produces the best zero coupon yield curve (ZCYC) for Nairobi Securities Exchange (NSE). The ZCYC should be differentiable at all points and at the same time, should produce a continuous and positive forward curve at all knot points. A decreasing discount curve is also expected from the resulting ZCYC, as an indication of monotonicity. For the interpolation method, we will use an improvement of monotone preserving interpolation method on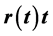 , while the Nelson and Siegel [1] model is the parametric model of choice. This is because compared to other interpolation methods, the improvement of monotone preserving interpolation method on
, while the Nelson and Siegel [1] model is the parametric model of choice. This is because compared to other interpolation methods, the improvement of monotone preserving interpolation method on 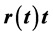 produces curves with the desirable trait of differentiability, while the Nelson-Siegel [1] model is shown to produce the best-fit results for Kenyan bond data. We compare the models’ performance in terms of accuracy in pricing back the fixed-income securities. For this study, we use bond data from Central Bank of Kenya (CBK). The better of the two methods will be used for the Kenyan securities market and, consequently, the East African Securities markets.
produces curves with the desirable trait of differentiability, while the Nelson-Siegel [1] model is shown to produce the best-fit results for Kenyan bond data. We compare the models’ performance in terms of accuracy in pricing back the fixed-income securities. For this study, we use bond data from Central Bank of Kenya (CBK). The better of the two methods will be used for the Kenyan securities market and, consequently, the East African Securities markets.
Keywords:
Interpolation Methods, Zero Coupon Yield Curves, Parametric Models, Nairobi Securities Exchange

1. Introduction
The objective of this paper is to establish the best yield curve model to be used in pricing of financial products at the Nairobi Securities Exchange. We compare two models so far established to be the best in their respective categories, as shown by Muthoni Onyango and Ongati [2] and Muthoni Onyango and Ongati [3] . Among the Parametric Models used in construction of yield curves, Nelson and Siegel [1] model was found to be superior by Muthoni, Onyango and Ongati [3] , while the improvement of monotone preserving interpolation on 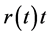 was found to be superior of the splines method studied by Muthoni, Onyango and Ongati [2] . This paper compares these two methods in terms of:
was found to be superior of the splines method studied by Muthoni, Onyango and Ongati [2] . This paper compares these two methods in terms of:
1) The accuracy of the yield curve using the set test statistics;
2) The smoothness of the curve;
3) The continuity and differentiability of the spot and forward curves;
4) Pricing back the fixed income securities;
5) The monotonicity of the yield curve, measured by the behavior of the discount curve.
2. Literature Survey
Many estimation methods for yield curves have appeared in literature over the years. Generally speaking, there are two distinct approaches to estimate the term structure of interest rates: the equilibrium model and the statistical techniques.
The first approach is formalized by defining state variables characterizing the state of the economy (relevant to the determination of the term structure) which are driven random processes and are related in some way to the prices of the bonds. It then uses no-arbitrage arguments to infer the dynamics of the term structure. Examples of this approach include: Vasicek [4] , Dothan [5] , Brennan and Schwartz [6] Cox, Ingersoll and Ross [7] , and Duffie and Kan [8] .
Unfortunately, in terms of the expedient assumptions about the nature of the random process driving the interest rates, the yield derived by those models have a specific functional form dependent only on a few parameters, and usually the observed yield curves exhibit more varied shapes than those justified by the equilibrium models.
In contrast to the equilibrium models, statistical techniques focusing on obtaining a continuing yield curve from cross-sectional coupon bond data based on curve fitting techniques are able to describe a richer variety of yield patterns in reality. The resulting term structure estimated from the statistical techniques can be directly put into the interest rate models such as the Hull [9] , and Heath [10] models, for pricing interest rate contingent claims. Since a coupon bond can be considered as a portfolio of discount bonds with maturities dates consistent with the coupon dates, the discount bond prices can thus be extracted from the actual coupon bond prices by statistical techniques.1 These techniques can be broadly divided into two categories: the splines (interpolation methods) and the parsimonious function forms (see Alper [11] ).
2.1. Splines/Interpolation Models
Interpolation is a method of constructing new data points within the range of a discrete set of known data points (called knot points). The simplest method for interpolating between two points is by connecting them through a straight line. Some variations of linear interpolation are capable of ensuring a strictly decreasing curve of discount factors. However, all the variations of linear interpolation imply discontinuities in the forward rate curve.
In order to produce continuous forward rates curves, researchers introduced cubic methods of interpolation. An example of cubic interpolation algorithm is the cubic Hermite spline. Under cubic Hermite splines, the derivative of the data of each knot point is assumed to be known, and the interpolation function is required to be differentiable. Often, these derivatives will not be known, and will have to be estimated. One method for estimating these derivatives, described by de Boor [12] [13] as the Bessel method involves estimating the derivative though the use of a three point difference formula.
Unfortunately, all the traditional cubic methods are incapable of ensuring strictly positive forward rates, which are synonymous with non-decreasing discount factors, as shown by Hagan and West [14] . Furthermore, some cubic methods have an inherent lack of locality in the sense that a local perturbation of curve input data will cause ringing and cause changes in the data far away from the perturbed data point as shown by Anderson [15] .
All variations of linear interpolations were seen to produce discontinuities in the forward rate curve, whilst all variations of cubic interpolations were seen to be incapable of ensuring strictly decreasing discount factors. Non-decreasing discount factors imply arbitrage opportunities, whilst discontinuous forward rates unacceptable from an economic perspective (unless the discontinuities occur on or around meetings of monetary authorities).
To counter this, a monotone convex interpolation method was developed, which it is claimed to be capable of ensuring a positive and (mostly) continuous forward rate curve Hagan and West [14] . This method proposed by Hagan and West [14] , was specifically designed to interpolate yield curve data, and involves fitting a set of quadratic polynomials to a discrete set of estimated instantaneous forward rates. The method is designed such that 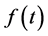 preserves the shape of the set of discrete forward rates. The monotone convex method was also seen to be capable of ensuring a strictly decreasing curve of discount factors. Unfortunately, the model depends heavily on an appropriate interpolation algorithm. In addition, it was discovered by du Preez [16] that there were specific conditions under which the interpolation function of the monotone convex interpolation would produce discontinuity of
preserves the shape of the set of discrete forward rates. The monotone convex method was also seen to be capable of ensuring a strictly decreasing curve of discount factors. Unfortunately, the model depends heavily on an appropriate interpolation algorithm. In addition, it was discovered by du Preez [16] that there were specific conditions under which the interpolation function of the monotone convex interpolation would produce discontinuity of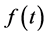 .
.
This led to the monotone preserving 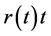 method of interpolation, introduced by Preez [16] . Essentially, this method involves applying cubic Hermite interpolation to the
method of interpolation, introduced by Preez [16] . Essentially, this method involves applying cubic Hermite interpolation to the 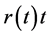 at the knot points i.e the values of
at the knot points i.e the values of 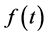 at the knot points, are estimated in manner which ensures positivity in
at the knot points, are estimated in manner which ensures positivity in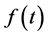 . Constructing an interpolating algorithm capable of preserving the monotonicity of the discount factors, was thus sufficient for ensuring positive forward rates.
. Constructing an interpolating algorithm capable of preserving the monotonicity of the discount factors, was thus sufficient for ensuring positive forward rates.
Monotone preserving 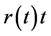 method is capable of ensuring a positive and continuous forward rate curve, and was designed to preserve the geometry of
method is capable of ensuring a positive and continuous forward rate curve, and was designed to preserve the geometry of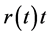 . Monotonicity in the discount factors implies monotonicity in the
. Monotonicity in the discount factors implies monotonicity in the 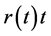 which is achieved by applying the work done in the field of shape preserving cubic interpolation, by authors such as de Boor [17] , Carlson and Fritsch [18] , Hyman [19] and Akima [20] . Apart from being an improvement of monotone convex method where it ensured positive forward rates, the monotone preserving
which is achieved by applying the work done in the field of shape preserving cubic interpolation, by authors such as de Boor [17] , Carlson and Fritsch [18] , Hyman [19] and Akima [20] . Apart from being an improvement of monotone convex method where it ensured positive forward rates, the monotone preserving  method was also capable of ensuring continuity of
method was also capable of ensuring continuity of .
.
In the study by du Preez [16] , they found that the monotone preserving  method to perfrom slightly better in terms of stability, and continuity of
method to perfrom slightly better in terms of stability, and continuity of , compared to monotone convex method. This suggests that when bootstrapping, the monotone preserving
, compared to monotone convex method. This suggests that when bootstrapping, the monotone preserving  method could be the ideal method of interpolation. Unfortunately, monotone preserving method had the undesirable characteristic of not being differentiable at the knot-points.
method could be the ideal method of interpolation. Unfortunately, monotone preserving method had the undesirable characteristic of not being differentiable at the knot-points.
Muthoni, Onyango and Ongati [2] introduced a new method of interpolation, which will be an improvement of monotone preserving  interpolation method suggested by du Preez [16] . They was done by removing the non-differentiability at the knot points in the aforementioned method, which is created by use of Hyman monotonicity constraint, which enforces monotonicity.
interpolation method suggested by du Preez [16] . They was done by removing the non-differentiability at the knot points in the aforementioned method, which is created by use of Hyman monotonicity constraint, which enforces monotonicity.
2.2. Parsimonious Models
Parsimonious models specify parsimonious parameterizations of the discount function, spot rate or the implied forward rate. Moving from the cubic splines, Chambers [21] introduced the parsimonious function forms by considering an exponential polynomial to model the discount function. Nelson & Siegel [1] followed shortly thereafter by choosing an exponential function with four unknown parameters to model the forward rate of U.S Treasury bills. By considering the three components that make up this function, Nelson & Siegel [1] illustrated that it can be used to generate a variety of shapes for the forward rate curves and analytically solve for the spot rate. Moreover, the advantage of the classical Nelson-Siegel [1] model is that the three parameters may be interpreted as latent level, slope and curvatures factors. Diebold [22] , Modena [23] and Tam & Yu [24] employed the Nelson-Siegel [1] interpolant to examine bond pricing with a dynamic latent factor approach and concluded that it was satisfactory.
Svensson [25] increased the flexibility of the original Nelson and Siegel [1] model by adding two extra parameters (Svensson [25] model) which allowed for a second “hump” in the forward rate curve. Later, Bliss [26] introduced the Extended Nelson-Siegel [1] method, which introduced a new appropriating function with five parameters by extending the model developed by Nelson & Siegel [1] . Bliss suggested that a six-parameter model can produce better results for fitting the term structure with longer maturities.
The Nelson-Siegel [1] model class has linear and non-linear parameters depending on the values assumed fixed. Due to this, these models have multiple local minima making model estimation difficult. Previous studies have widely discussed the estimation of Nelson-Siegel [1] model class and they are: Bolder [27] , Maria et al. [28] , Gilli [29] , Rezende [30] , Rosadi [31] , among others.
Muthoni et al. [3] estimated the Kenyan government bonds (KGBs) term structure of interest rates based on the parsimonious functions specifications , i.e. the four parameters Nelson-Siegel [1] model, the five parameters Svensson [25] model and the six parameters Rezende [30] model, known as Nelson-Siegel-Svensson model. The reason they chose the Nelson-Siegel family is that these models have substantial flexibility required to match the changing shape of the yield curve, yet they only use a few parameters. As noted by Diebold [22] , they can be used to predict the future level, slope, and curvature factors for bond portfolio investments purposes. After comparing the Nelson-Siegel classes of models, Muthoni, Onyango and Ongati [3] found Nelson Siegel [1] to be the superior model.
3. Empirical Methodology
3.1. Model Selection
3.1.1. The Nelson-Siegel [1] Model
The Nelson-Siegel [1] model sets the instantaneous forward rate at maturity m given by the solution to a second order differential equation with unequal roots as follows:
 (1)
(1)
where . The model consists of four parameters:
. The model consists of four parameters:  and
and  m is the time to maturity of a given bond. Equation (1) consists of three parts: A constant, an exponential decay functional and Laguerre function.
m is the time to maturity of a given bond. Equation (1) consists of three parts: A constant, an exponential decay functional and Laguerre function.  is independent of m and as much,
is independent of m and as much,  is often interpreted as the level of long term interest rates. The exponential decay function approaches zero as m tends to infinity and
is often interpreted as the level of long term interest rates. The exponential decay function approaches zero as m tends to infinity and  as m tends to zero. The effect of
as m tends to zero. The effect of  is thus only felt at the short end of the curve. The Laguerre function on the other hand approaches zero as m tends to infinity, and as m tends to zero. The effect of
is thus only felt at the short end of the curve. The Laguerre function on the other hand approaches zero as m tends to infinity, and as m tends to zero. The effect of  is thus only felt in the middle section of the curve, which implies that
is thus only felt in the middle section of the curve, which implies that  adds a hump to the yield curve.
adds a hump to the yield curve.
The spot rate functions under the model of Nelson and Siegel [1] is as follows:
 . (2)
. (2)
From Equation (2) it follows that both the spot and forward rate function reduce to  as
as . Furthermore, we have
. Furthermore, we have . Thus, in the absence of arbitrage, we must have that
. Thus, in the absence of arbitrage, we must have that  and
and .
.
Suppose we observe n zero coupon bonds, expiring at times . Let
. Let  denote the prices of these bonds. Note that
denote the prices of these bonds. Note that  will imply the spot rate of interest corresponding to time
will imply the spot rate of interest corresponding to time  for
for . Let
. Let  denote these spot rates. If we assume that the values of
denote these spot rates. If we assume that the values of  are known, then the Nelson and Siegel [1] model reduces to a linear model, which can be solved using linear regression.
are known, then the Nelson and Siegel [1] model reduces to a linear model, which can be solved using linear regression.
Define:
 . (3)
. (3)
We would like to obtain a vector  satisfying
satisfying . By using ordinary least squares (OLS) estimation, we can solve
. By using ordinary least squares (OLS) estimation, we can solve  as follows:
as follows:
 (4)
(4)
Nelson and Siegel [1] suggested the following procedure for calibrating their model:
1) Identify a set of possible values for 
2) For each of these  estimate B
estimate B
3) For each of these  and their corresponding B’s, estimate
and their corresponding B’s, estimate
 (5)
(5)
4) The optimal  and
and  are those associated with the highest value of
are those associated with the highest value of .
.
The above method of calibration is known as the grid-search method. Alternatively, non-linear optimization techniques can be used to solve all four parameters simultaneously. However, such networks are very sensitive to starting values, implying a high probability of obtaining local optima. The estimated parameters obtained by using the grid search method behave erratically over time, and have large variances. The problems resulting from multi-colinearity depend on the time to maturity of the securities used to calibrate the model. Diebold [22] , attempted to address the multi-colinearity problem by fixing the value of  over time, which in some instances might not produce accurate results.
over time, which in some instances might not produce accurate results.
Due to the local-minima problem which makes model estimation difficult in the Nelson-Siegel [1] model and the inadequacy of the calibration methods used so far, we propose NLS estimation with L-BFGS-B method optimization approach. This optimization method is an extension of the limited memory BFGS method (LM-BFGS or L-BFGS) which uses simple boundaries model, according to Zhu et al. [32] .
Using L-BGFS-B algorithm, we can estimate the above five parameters: , embedded in the Nelson?Siegel [1] model, and hence calculate the price of the bond using the following nonlinear constrained optimization estimation procedure based the Gauss-Newton numerical method:
, embedded in the Nelson?Siegel [1] model, and hence calculate the price of the bond using the following nonlinear constrained optimization estimation procedure based the Gauss-Newton numerical method:
 (6)
(6)
where  is the price of bond i.
is the price of bond i.
3.1.2. Improvement of Monotone Convex Interpolation on 
We start with a mesh of data points  (we will think of the x-values as time points on the x axis) and the corresponding y values are define as
(we will think of the x-values as time points on the x axis) and the corresponding y values are define as  for a generic but unknown function
for a generic but unknown function . Cubic splines are generally defined by piece-wise cubic polynomial that passes through consecutive points:
. Cubic splines are generally defined by piece-wise cubic polynomial that passes through consecutive points:
 . (7)
. (7)
With  and
and  . We will use the following definitions:
. We will use the following definitions:
 (8)
(8)
 . (9)
. (9)
With  The coefficients
The coefficients  and
and  depends on the details of the method, and are related to the values of
depends on the details of the method, and are related to the values of  and its derivatives at the node points. In general
and its derivatives at the node points. In general
 and so on (10)
and so on (10)
where in the above equation, the prime denotes the derivative of the interpolating function  w.r.t. its argument t. Moreover given
w.r.t. its argument t. Moreover given  and
and , we can express
, we can express  and
and  as follows:
as follows:
 (11)
(11)
 . (12)
. (12)
We can use Equation (4) to compute the following derivative:
 . (13)
. (13)
We have:
 (14)
(14)
 (15)
(15)
 (16)
(16)
 . (17)
. (17)
Which depends on the matrix element . Here
. Here  is the Kronecker delta, which is equal to one if
is the Kronecker delta, which is equal to one if  and zero otherwise. Once the derivatives at the points, or equivalently the
and zero otherwise. Once the derivatives at the points, or equivalently the  coefficients, are specified, everything else is fixed. In particular we are interested in computing
coefficients, are specified, everything else is fixed. In particular we are interested in computing , then all the work will be in the calculation of the derivatives
, then all the work will be in the calculation of the derivatives  w.r.t.
w.r.t. .
.
This calculation is tricky if we use monotone preserving splines (or any other method which enforces monotonicity where the  s are non-differentiable functions of the
s are non-differentiable functions of the  s (which involve the min and max functions). And this is where the novelty of this paper comes in.
s (which involve the min and max functions). And this is where the novelty of this paper comes in.
Let us start by recalling the formulas for the ’s in the monotone preserving cubic spline method as defined in the Hagan-West [14] . First of all, at the boundaries, we have:
’s in the monotone preserving cubic spline method as defined in the Hagan-West [14] . First of all, at the boundaries, we have:
 (18)
(18)
For the internal data, if the curve is not a monotone at , i.e.
, i.e. , then the boundaries become:
, then the boundaries become:
 (19)
(19)
So that it will have a turning point there. Instead if the trend is a monotone at , i.e.
, i.e. , then one defines:
, then one defines:
 . (20)
. (20)
And:
 . (21)
. (21)
The former choice is made when the curve is increasing (positive slopes), the latter when decreasing (negative slopes). Equation (21) represents the monotonicity constraint introduced by Hyman and based on the Fritsch- Butland algorithm.
We can now move to the monotonicity constrain. What we need first is:
 (22)
(22)
 . (23)
. (23)
The final step consists of putting all the information together to compute . Suppose first that the trend is increasing, i.e.
. Suppose first that the trend is increasing, i.e. . Using Equation (23) we find:
. Using Equation (23) we find:
 (24)
(24)
 . (25)
. (25)
Let us now suppose that the trend is decreasing instead, i.e. . By Equation (23) we have:
. By Equation (23) we have:
 (26)
(26)
 . (27)
. (27)
It can be shown that for any i and j
 (28)
(28)
 . (29)
. (29)
This formula solves our problem of non-differentiability found in the monotone preserving convex on .
.
3.2. Liquidity-Weighted Function
In yield curve construction, errors are caused by two reasons: (a) curve fitting mistakes and (b) presence of liquidity premium. The errors due to curve fitting arise from the calculations and can be avoided. But the error due to the presence of liquidity premium is reflective of market conditions and one cannot ignore them. Since the reliability of the term structure estimation heavily depends on the precision of the market prices according to Subramanian [33] , liquid and illiquid securities are a heterogeneous class and including them both in the term structure estimation process poses problems. Illiquid bonds are traded at a premium to compensate for their undesirable attribute in terms of a low price. Assigning equal weights to both types of errors will give undue weight to the kind of error that creeps in due to curve fitting.
Subramanian [33] suggests a liquidity weighted objective function, which hypothesizes that a weighted error function (with weights based on liquidity) would lead to better estimation that equal weights to the squared errors of all securities. We therefore model the liquidity using a function with two factors: the volume of trade in a security and the number of trades in that security.
The weight of the  security
security  is given by:
is given by:
 (30)
(30)
 (31)
(31)
where  and
and  are the volume of trade and the number of trades in the
are the volume of trade and the number of trades in the  security respectively, while
security respectively, while  and
and  are the maximum number of trades among all the securities traded for the day respectively.
are the maximum number of trades among all the securities traded for the day respectively.
As given in the Equation (30) and Equation (31) above, it ensures that the weights of the relative liquid securities would not be significantly different from each other. For the illiquid securities, however the weights would fall quickly as liquidity decreased.
The final error-minimizing function, which should equal to zero, is given by:
 . (32)
. (32)
3.3. Test Statistics
In academic literature, there are two distinct approaches used to indicate the term structure fitting performance. One is the flexibility of the curve (accuracy), and the other focuses on smoothness of the yield curve. Although there are numerical methods proposed to estimate the term structure, any method developed has to grapple with deciding the extent of the above trade-off. Hence it becomes a crucial issue to investigate how to reach a compromise between the flexibility and smoothness.
Three simple summary statistics which can be calculated for the flexibility of the estimated yield curve are the coefficient of determination, root mean squared percentage error, and root mean squared error . These are calculated as shown in the next four subsections.
3.3.1. The Coefficient of Determination (R2)
 (33)
(33)
where  is the mean average price of all observed bonds,
is the mean average price of all observed bonds,  is the model price of a bond i, n the number of bonds traded and k is the number of parameters needed to be estimated.
is the model price of a bond i, n the number of bonds traded and k is the number of parameters needed to be estimated.
Roughly speaking, with the same analysis in regression, we associate a high value of  with a good fit of the term structure and associate a low
with a good fit of the term structure and associate a low  with a poor fit.
with a poor fit.
3.3.2. Root Mean Squared Error (RMSE)
Denoted as the RMSE, a low value for this measure is assumed to indicate that the model is flexible, on average, and is able to fit the yield curve.
 . (34)
. (34)
3.3.3. Root Mean Squared Percentage Error (RMSPE)
Denoted as the RMSPE, a low value for this measure is also assumed to indicate that the model is flexible, on average, and is able to fit the yield curve.
 . (35)
. (35)
3.3.4. Testing for Smoothness
To test the smoothness of the estimated yield curve, we use a modified statistic suggested by Adams and Deventer [34] to reach the maximum smoothness for forward rate curve, and denote the smoothness (Z) for the estimated yield curve as:
 . (36)
. (36)
Ideally, the value should equal to zero. The model with the least Z value is deemed to be the best.
4. Empirical Results
4.1. Data
In Kenya, nearly all bond transactions take place on the OTC market. The data used in this study was supplied by the Central Bank of Kenya. The sample period contains 417 weekly data from January 2005 to December 2012. Weekly prices (every Friday) for 108 Kenyan Government Bonds (KGBs) with original maturity dates ranged from 2 to 30 years are obtained.
4.2. Parameter Estimation
4.2.1. Nelson-Siegel [1] Model
Table 1 lists the summary statistics of estimated parameters for the Nelson-Siegel [1] model. It is seen that all estimated values for  and
and  are negative, which indicates that the yield curves generated by this model are all positively and upward sloping without a visible hump.
are negative, which indicates that the yield curves generated by this model are all positively and upward sloping without a visible hump.
4.2.2. The Spline Model
Table 2 lists the summary statistics of estimated parameters for the improved monotone preserving interpolation method on  Model.
Model.
4.3. Comparison of the Models
4.3.1. In terms of Accuracy
A direct comparison of the two models in Table 3 appears to favor the Nelson-Siegel [1] .
4.3.2. In Terms of Smoothness
In the academic literature, it has been observed that when comparing alternative methods of term structure fitting models, there is usually a trade-off between flexibility and smoothness. In Table 4, the spline seems to have the best fit in flexibility for fitting the term structure of KGB market. However, as shown in Table 4, the Nelson-Siegel [1] Model is superior to the spline, which shows that the Nelson-Siegel [1] results to a relatively smoother yield curve, compared to the other model.
4.3.3. In Terms of the Spot Curves
In Figure 1, we see the spot curve generated by the Nelson and Siegel [1] model, which shows character-

Table 1. Results for estimated parameters for Nelson-Siegel [1] model.
Table 2. Results for estimated parameters for improved monotone preserving interpolation method on .
.
Table 3. Summary statistics for fitting performance in terms of accuracy.
Table 4. Summary Statistics for fitting performance in terms of smoothness.
ristics of normal curve.
In Figure 2, we see that the splines produce a curve which initially is increasing and then suddenly becomes flat after time 10, at a constant yield rate of 1.40%. This does not depict normal behavior of yield curves.
4.3.4. In Terms of Pricing Back the Securities
In Figure 3, we see the Nelson and Siegel model [1] prices back the securities but not with as much accuracy as the spline curve does, as shown in Figure 4.

Figure 1. Nelson and siegel [1] curve.

Figure 2. Splines curve.

Figure 3. Nelson and Siegel [1] .

Figure 4. Splines.

Figure 5. The Nelson-Siegel model [1] .
4.3.5. In terms of the Discount Curve
In Figure 5, we see that the Nelson and Siegel [1] model is able to produce a decreasing discount curve, which is a very important characteristic of a yield curve because it shows not only monotonicity, but is also sensible from an economic perspective. When we compare with Figure 6, we see that the discount curve is decreasing in the short to middle terms, with a little hitch at times 10 - 12, 16 - 28 and 29 - 31, after which it starts increasing. This curve lacks monotonicity and therefore does not make much economic sense.
5. Conclusion and Discussion of Results
The objective of this paper was to compare the performance of the improved monotone preserving interpolation method on  against the Nelson & Siegel [1] in terms of several performance yard sticks. These yard sticks were: 1) accuracy, 2) smoothness, 3) the non-negativity and continuity of forward and spot curves, 4) pricing back of securities and 5) the monotonicity of the discount curve.
against the Nelson & Siegel [1] in terms of several performance yard sticks. These yard sticks were: 1) accuracy, 2) smoothness, 3) the non-negativity and continuity of forward and spot curves, 4) pricing back of securities and 5) the monotonicity of the discount curve.

Figure 6. Splines discount curve.
In terms of accuracy, we see that the spline method does better than the parametric method in that it gives an accuracy of 97.37% compared to an accuracy of 96.54% by the Nelson-Siegel [1] model. We come to the same conclusion when we compare the two models using the test statistics of accuracy in that the spline does better than the parametric model.
However, when it comes to the test of smoothness, we see that Nelson-Siegel [1] model performs much better with a lower Z value of 4.9822 compared to the spline’s value of 10.7467. Smoothness of the curve is extremely important in that it points towards differentiability and continuity of the curve.
When we compare the spot and the forward curves, we see that Nelson-Siegel gives us better curves (normal curves) which reflect reality, compared to the resulting splines’ curve which increases with time initially, then abruptly becomes static at a given yield rate. This behavior is not realistic. We come to the same conclusion (that the parametric is better than the spline) when we compare the two in terms of pricing back the fixed income securities in that we see an almost perfect pricing back of the securities when we use the parametric model.
When we compare the two in terms of monotonicity, a very important concept in both Mathematical Finance and Economics, we see again that Nelson-Siegel [1] performs better than the spline. It results to a strictly decreasing discount curve, compared to the decreasing spline curve which starts increasing in the long term (after 25 years).
After considering all the factors at hand, we come to a conclusion that the parametric model (Nelson-Siegel [1] ) is the proper model to be used in NSE, and consequently, in the East African securities Markets.
Acknowledgements
I would like to acknowledge the academic guidance given to me by my supervisors, Prof. Silas Onyango, Prof. Omolo Ongati and an academic friend, Prof. Michael Ingleby. I would like to also thank the Institute of Mathematical Sciences, in particular its Dean, Prof. Vitalis P. Onyango-Otieno for making this possible. On the same breath, I would like to thank Strathmore University, and in particular, the Vice Chancellor, Prof. John Odhiambo for all the support accorded to me. Finally, I would like to make a special mention of my husband, Cosmas Kamuyu for being my best friend and making this publication possible through encouragement, emotional support and also financial support. Thank you.
Cite this paper
Lucy Muthoni, (2015) In Search of the Best Zero Coupon Yield Curve for Nairobi Securities Exchange: Interpolation Methods vs. Parametric Models. Journal of Mathematical Finance,05,360-376. doi: 10.4236/jmf.2015.54031
References
- 1. Nelson, C.R. and Siegel, A.F. (1987) Parsimonious Modelling of Yield Curves. Journal of Business, 60, 473-489.
http://dx.doi.org/10.1086/296409 - 2. Muthoni, L., Onyango, S. and Ongati, O. (2015) Construction of Nominal Yield Curve for Nairobi Securities Exchange: An Improvement on Monotone Preserving Interpolation Method on r(t)t. Journal of Mathematical Finance.
- 3. Muthoni, L., Onyango, S. and Ongati, O. (2015) Extraction of Zero Coupon Yield Curve for Nairobi Securities Exchange: Finding the Best Parametric Model for East African Securities Markets. SIAM Journal on Financial Mathematics.
- 4. Vasiceck, O. (1977) An Equilibrium Characterization of the Term Structure. Journal of Financial Economies, 5, 177-188.
http://dx.doi.org/10.1016/0304-405X(77)90016-2 - 5. Dothan, L. (1978) On the Term Structure of Interest Rates. Journal of Financial Economies, 6, 59-69.
http://dx.doi.org/10.1016/0304-405X(78)90020-X - 6. Brennan, M.J. and Schwartz, E.S. (1979) A Continuous Time Approach to the Pricing of Bonds. Journal of Banking and Finance, 3, 133-156.
http://dx.doi.org/10.1016/0378-4266(79)90011-6 - 7. Cox, J.C., Ingersoll Jr., J.E. and Ross, S.A. (1985) A Theory of the Term Structure of Interest Rates. Econometrica, 53, 385-408.
- 8. Duffie, D. and Kan, R. (1996) A Yield Factor Model of Interest Rates. Mathematical Finance, 6, 379-406.
http://dx.doi.org/10.1111/j.1467-9965.1996.tb00123.x - 9. Hull, J. and White, A. (1990) Pricing Interest Rate Derivatives Securities. Review of Financial Studies, 3, 573-592.
http://dx.doi.org/10.1093/rfs/3.4.573 - 10. Heath, D., Jarrow, R. and Morton, A. (1992) Bond Pricing and the Term Structure of Interest Rates: A New Methodology for Contigent Claim Valuation. Econometrica, 60, 77-105.
http://dx.doi.org/10.2307/2951677 - 11. Alper, C.E., Akdemir, A. and Kazimov, K. (2004) Estimating the Term Structure of Government Securities in Turkey. Bogazaci University Research Papers: ISS/EC-2004-03.
http://dx.doi.org/10.2139/ssrn.578921 - 12. de Boor, C. (1977) Package for Calculating with B-Splines. SIAM Journal on Numerical Analysis, 14, 441-472.
http://dx.doi.org/10.1137/0714026 - 13. de Boor, C. (1978) A Practical Guide to Splines. Springer-Verlag, New York.
http://dx.doi.org/10.1007/978-1-4612-6333-3
Appendix 1: The L-BFGS-B Algorithm
A.1. Introduction
The problem addressed is to find a local minimizer of the non-smooth minimization problem.
 (A1)
(A1)
where  is continuous but not differentiable anywhere and n is large.
is continuous but not differentiable anywhere and n is large.  and
and  are respectively an upper limit and; lower limit parameters.
are respectively an upper limit and; lower limit parameters.  is NLS (Non Linear Schrödinger) function of residual functions of Nelson-Siegel [1] model class and x is a parameter of the Nelson-Siegel [1] model class.
is NLS (Non Linear Schrödinger) function of residual functions of Nelson-Siegel [1] model class and x is a parameter of the Nelson-Siegel [1] model class.
The L-BFGS-B algorithm by Zhu et al. [32] is a standard method for solving large instances of  when f is a
when f is a
smooth function, typically twice differentiable. The name BFGS stands for Broyden, Fletcher, and Goldfarb and Shanno, the originators of the BFGS quasi-Newton algorithm for unconstrained optimization discovered and published independently by them in 1970 [Broyden [35] , Fletcher [36] , Goldfarb [37] and Shanno [38] . This method requires storing and updating a matrix which approximates the inverse of the Hessian  and hence requires
and hence requires  operations per iteration.
operations per iteration.
According to Nocedal [39] , the L-BFGS variant where the L stands for “Limited-Memory” and also for “Large” problems, is based on BFGS but requires only  operations per iteration, and less memory. Instead of storing the
operations per iteration, and less memory. Instead of storing the  Hessian approximations, L-BFGS stores only m vectors of dimesion n, where m is a number much smaller than n. Finally, the last letter B in L-BFGS stands for bounds, meaning the lower and upper bounds
Hessian approximations, L-BFGS stores only m vectors of dimesion n, where m is a number much smaller than n. Finally, the last letter B in L-BFGS stands for bounds, meaning the lower and upper bounds  and
and . The L-BFGS-B algorithm is implemented in a FORTRAN software package, according to by Zhu et al. [32] . We discuss how to modify the algorithm for non-smooth functions.
. The L-BFGS-B algorithm is implemented in a FORTRAN software package, according to by Zhu et al. [32] . We discuss how to modify the algorithm for non-smooth functions.
A.1.1. BFGS
BFGS is standard tool for optimization of smooth functions. It is a line search method. The search direction is of type  where
where  approximation to the inverse Hessian of f.2 This
approximation to the inverse Hessian of f.2 This  step approximation is calculated via the BFGS formula.
step approximation is calculated via the BFGS formula.
 (A2)
(A2)
where  and
and . BFGS exhibits super-linear convergence on generic problems but it requires
. BFGS exhibits super-linear convergence on generic problems but it requires  operations per iteration, according to Wright et al. [40] .
operations per iteration, according to Wright et al. [40] .
In the case of non-smooth functions, BFGS typically succeeds in finding a local minimizer, as indicated by Overton et al. [41] . However, this requires some attention to the line search conditions. This conditions are known as the Armijo and weak Wolfe line search conditions and they are a set of inequalities used for computation of an appropriate step length that reduces the objective function” sufficiently”
A.1.2. L-BFGS
L-BFGS stands for Limited-memory BFGS. This algorithm approximates BFGS using only a limited amount of computer memory to update an approximation to the inverse of the Hessian of f. Instead of storing a dense  matrix, L-BFGS keeps a record of the last m is a small number that is chosen in advance. For this reason the first m iterations of BFGS and L-BFGS produce exactly the same search directions if the initial approximation of
matrix, L-BFGS keeps a record of the last m is a small number that is chosen in advance. For this reason the first m iterations of BFGS and L-BFGS produce exactly the same search directions if the initial approximation of  is set to the identity matrix.
is set to the identity matrix.
Due to this construction, the L-BFGS algorithm is less computationally intensive and requires only  operations per iteration. So it is much better suited for problems where the number of dimensions n is large.
operations per iteration. So it is much better suited for problems where the number of dimensions n is large.
A.1.3. L-BFGS-B
Finally L-BFGS-B is an extension of L-BFGS. The B stands for the inclusion of Boundaries. L-BFGS-B requires two extra steps on top of L-BFGS. First, there is a step called gradient projection that reduces the dimensionality of the problem. Depending on the problem, the gradient projection could potentially save a lot of iterations by eliminating those variables that are on their bounds at the optimum reducing the initial dimensionality of the problem and the number of iterations and running time. After this, gradient projection comes to second step of subspace minimization. During the subspace minimization phase, an approximate quadratic model of (A1) is solved iteratively in a similar way that the original L-BFGS algorithm is solved. The only difference is that the step length is restricted as much as necessary in order to remain within the lu-box defined by Equation (A1).
A.1.4. Gradient Projection
The L-BFGS-B algorithm was designed for the case when n is large and f is smooth. Its first step is the gradient projection similar to the one outlined in Conn, Gould, and Toint [42] and Toraldo, Jorge and Gerardo [43] , which is used to determine an active set corresponding to those variables that are on either their lower or upper bounds. The active set is defined at point is:
 (A3)
(A3)
Working with this active set is more efficient in large scale problems. A pure line search algorithm would have to choose to step length short enough to remain within the box defined by  and
and . So if at the optimum, a large number
. So if at the optimum, a large number  of variables are either on the lower or upper bound, as many as
of variables are either on the lower or upper bound, as many as  of iterations might be needed. Gradient projection tries to reduce this number of iterations. In the best case, only one iteration is needed instead of
of iterations might be needed. Gradient projection tries to reduce this number of iterations. In the best case, only one iteration is needed instead of .
.
Gradient projections works on the linear part of the approximation model:
 (A4)
(A4)
where  is a L-BFGS-B approximation to the Hessian
is a L-BFGS-B approximation to the Hessian  stored in the implicit way defined by L-BFGS.
stored in the implicit way defined by L-BFGS.
In this first stage of the algorithm a piece-wise linear path starts at the current point  in the direction
in the direction . Whenever this direction encounters one of the constraints the path runs corners in order to remain feasible. The path is nothing but feasible piece-wise projection of the negative gradient direction on the constraint box determined by the values l and u. At the end of this stage, the value of x that minimizes
. Whenever this direction encounters one of the constraints the path runs corners in order to remain feasible. The path is nothing but feasible piece-wise projection of the negative gradient direction on the constraint box determined by the values l and u. At the end of this stage, the value of x that minimizes  restricted to this piece-wise gradient path is known as the “Cauchy point”
restricted to this piece-wise gradient path is known as the “Cauchy point” .
.
From this description of the estimation and optimization, following steps can be summarized:
・ Find the residual function (r) of each model.
・ Find NLS estimation, i.e.  of each model.
of each model.
・ Find the  matrix value for
matrix value for , p is the number of parameters estimated in each model.
, p is the number of parameters estimated in each model.
・ Find the initial value of parameter vector with rank , p is the number of parameters estimated in each model.
, p is the number of parameters estimated in each model.
・ Find gradient from step 2 with every parameter in models. e.g. .
.
・ Substitute the initial value of the parameter (step 3) to gradient of step 5 with result. e.g. .
.
・ Find the value of 
Then we find the value of  so it will obtain of
so it will obtain of  and
and .
.
NOTES
1Once the discount function, 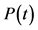 , is defined, the spot interest rate (the pure discount bond yield) can be computed by:
, is defined, the spot interest rate (the pure discount bond yield) can be computed by: .
.
2When it is exactly the inverse Hessian this method is known as Newton method. Newton’s method has quadratic convergence but requires the explicit calculation of the Hessian at every step.