Open Journal of Genetics
Vol.05 No.02(2015), Article ID:57601,17 pages
10.4236/ojgen.2015.52008
Another Understanding of the Model of Genetic Code Theoretical Analysis
Petr Petrovich Gariaev
Institute of Quantum Genetics LLC, Moscow, Russia
Email: gariaev@mail.ru
Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 16 May 2015; accepted 27 June 2015; published 30 June 2015
ABSTRACT
At present the model of the genetic code (the code of protein biosynthesis) proposed almost 50 years ago by M. Nirenberg and F. Crick has undergone severe erosion. Tactically, it is true that triplicity and the synonymous degeneracy are unmistakable. But the Nirenberg-Crick postulate about unambiguous coding of amino acids, i.e., the strategy raises reasonable doubt. The reasons to doubt showed up very early: it turned out that the triplet UUU codes both phenylalanine and leucine, which was inconsistent with the declaration of the unambiguity of the DNA-RNA encoding of amino acids in proteins. On the other hand, the ambiguity automatically stems from the Wobble Hypothesis by F. Crick relating to the wobbling of the third nucleotide in codons, (random, undetermined behavior), which means the 3’-5’ codon-anticodon pair is not involved in the encoding, and represents a “steric crutch”. In fact, amino acids are coded not by triplet, but by doublet of nucleotides in a triplet, according to “Two-out-of-Three” rule by Ulf Lagerkvist. From this perspective, the codon families split into two classes: 32 codon-synonym triplets and 32 codon triplets with undetermined coding functions, that is inherent to one of the 32 codons UUU. These “undetermined” codons have called homonyms. They are ambiguous as they potentially and simultaneously encode two different amino acids, or amino acid and the stop function. However, the ambiguity is overcome in real protein biosynthesis. This is due to the sign orientations of ribosomes within mRNA contexts. This is the way the semantics of the codon-homonyms occur, as an exact analogy of the consciousness work in the human languages, abounding with homonyms. This turn in the understanding of the protein code, as actual text formation, leads to a strong idea of the genome as a quasi-intelligent biocomputer structure of living cells. Ignoring this leads to erroneous and dangerous works of genetic engineering, the most important results are Synthia bacteria with synthetic genome and GM foods. Protein biosynthesis is a key, but not the only basic information function of chromosomes. There are other, no less important, holographic and quantum non-loca- lity functions related to morphogenesis. In this plane, the work of the genome, as a quantum biocomputer, occurs on the wave level. Here the main function is regulatory quantum broadcasting of genetic-metabolic information on the intercellular, tissue and organism levels using a coherent photon DNA radiation and its nonlinear vibrational states (sound). DNA information presents itself in the form of dynamically polarized holograms as well as phantom DNA structures. In the interpretation of the quantum work of the genome almost everything is hypothetical. Nevertheless, we have created a laser technology, to some extent simulating “sign wave” states of the genome, and are able to transmit genetic and genetic-metabolic information. Manifestations of phantom DNA, which we managed to detect in 1984 but published only in 1991 [Gariaev et al., 1991], are particularly interesting. Now we can produce fDNK with our laser techniques and materialize it as a material structure in the PCR system [Gariaev et al., 2014 (a) Gariaev et al., 2014 (b)], as it was done earlier, but in their own way, by the team of Nobel Prize laureate, Professor Luc Montagnier [Montagnier et al., 2012]. However, back in 2007 and 2009 we demonstrated far-distance quantum transmission of genetic information for pancreas regeneration in rats [Gariaev et al., 2007; Gariaev, 2009]. These data are the basis of Linguistic Wave Genetics (LWG). The practical use of LWG principles is potentially large. So far, we have made precedents of regeneration of teeth, pancreas, and retina with full restoration of vision, cured cystic fibrosis and Down Syndrome, and returned mobility to the paralyzed. LWG provides a method to program stem cells. LWG makes it possible to, in an environmentally friendly way selectively destroy pathogenic bacteria and viruses, insect pests and weeds in agriculture. LWG lays the foundations for quantum computing instead of digital.
Keywords:
Genetic Code, Degeneracy, Homonymy, Linguistics, Holography, Quantum Non-Locality

1. The Background on the Creation of the Genetic Code Model
In recent years, the well-known and sagacious idea expressed a fair time ago by the famous Russian biologist A.G. Gurvich has gained lots of supporters. His idea stated that the hope that genes would explain the real functions of chromosomes was unrealistic, and, therefore, it is necessary to introduce a notion of the biological field, i.e. “the field of chromosome equivalent” to give an advanced understanding of the functions of the genetic apparatus [1] ―which is currently referred to as the epigenetics. At that time, more than 60 years ago, it was unclear how genes encode an organism’s structure and nowadays, indeed, this problem has not been solved either. They try to find a solution by applying so-called “epigenetic functions” of DNA, which notion is intended to explain the real additional functions of chromosomes, regardless of encoding of proteins, which would finally elucidate the most key points in the operation of the genetic apparatus. For this reason, in the genome they are seeking the super-codes (that’s why there is a prefix “epi-”) and regulatory factors, operating at the higher levels. Such searches are justified; however they are still in the opening stage. The present study is supposed, to some extent, to fill this gap. This gap is about understanding that the main, strategic and hidden aspects of chromosome operation, encoding of dynamic, and at the same time relatively constant, space-time structure of biosystems. The role of protein genes is, probably, secondary and the protein encoding mechanisms, within the bounds of Nirenberg-Crick’s model of genetic code, require considerable changes. It is only during the last 10 years the first signs of leaving the Procrustes bed of Nirenberg-Crick’s model came up. This comprises of the new information about quantum and linguistic levels of chromosome operation which will be described in this study on the general-theoretical grounds, and with due consideration of the latest experimental findings. To achieve this it’s necessary to revise the original protein-code model of Nirenberg-Crick, to develop it and transcend its operation to new levels, including quantum-linguistic ones, which are natural for the ribosomal protein-synthesizing apparatus and the whole genome. This concept in biology, genetics and medicine for a long time has been developing as a sort of scientific dissidence. It was named “Linguistic Wave Genetics” (LWG) and today it’s gradually coming to the front, though this research is principally of a private character, except for ours. The research done in this direction has great positive potential. However, like any other scientific achievements, the results of this research may be used against Humanity. They are specifically attractive as a cheap and powerful alternative to nuclear weapons, having a much higher efficiency. LWG might be used as a base for creation of the super genetic quantum weapons, which is absolutely unacceptable. Any normal and natural practical application of LWG principles in medicine is also suppressed, as it allows simply, inexpensively, quickly and efficiently regulate the main biochemical-biophysical-physiological processes in organisms, from viruses to humans. This is disadvantageous for some of the existing medical autocracy. LWG developments directly affect all fields of biology and medicine, including problem of aging. LWG aging treatment is based not on developing any super antioxidants or elixirs of immortality, which make no sense, but rather is based on the theory of management of genetic programs, which limit human life. Moreover, LWG principles facilitate the creation of new DNA- RNA-Protein texts and DNA holograms, which are able to reprogram genomes of zygotes and stem cells in a desired way. Both theoretical and experimental revision of the genetic code fundamentals based on LWG principles has a strategic and ideological character, since it is fundamental to understanding of the origin and essence of life. When the genetic protein code and its derivatives are interpreted incorrectly, and we see more and more evidence of this today, it becomes counterproductive and dangerous. We can already see the consequences of this, which led to creation and wide use of GM foods and bacteria (so-called “Synthia”) with an artificially synthesized genome. Synthia kill all living organisms in the Gulf of Mexico and even out of its area [http://one_vision.jofo.ru/224648.html]. The beginning of such a pan-genetic collapse on the Earth was, curiously enough, set by the Nobel model of the biosynthesis of proteins, perceived until recently as a dogma, and the only right one. It was and still is a great ideological mistake and, to the larger extent, it is a mistake of practical strategic application of this model “falsely” proclaimed for the humanity’s sake. Let’s review these mistakes in theoretical and experimental contexts.
2. Analysis of Causes of Inaccuracy of the Genetic Code Model
Let’s turn to the Nobel model of the genetic (protein) code, which in its foundation remained intact until now and which, with some small tactical additions, reflects the level of our outdated knowledge from the sixties of the last century. This is the model for which Marshall Nirenberg was awarded the Nobel Prize in 1968. I cite an important statement made by the authors, where the mistake in the proposed model of the genetic code is actually acknowledged, but ignored:
“Poly-U (Gariaev: polyuridylic RNA) mainly encodes phenylalanine. A protein which is synthesized from poly-U mRNA, comprises not only leucine but phenylalanine as well, of a ratio of one leucine molecule to ~20 - 30 phenylalanine molecules. In case there is no phenylalanine in the solution, poly-U uses leucine in the amount which equals the half of the usual amount of phenylalanine. Molecular explanation of this ambiguity does not exist”. This was received “only in the case” of the so-called cell-free protein biosynthesis system. Here, in order to decipher the genetic code, which determines which amino acids and in what sequences are included into the growing peptide chain, artificially synthesized RNA molecules were used as the code templates with the sought ciphers of amino acids. All amino acid ciphers (codes) in the form of the triplets of nucleotides (codons), as it looked like back then, were determined successfully. The only annoying exception, according to the above citation, was the UUU (uridine-uridine-uridine) codon, where the template for the codon was polyuridylic acid. The authors of the code model demonstrated an original approach to such a fundamental fact by saying that the “molecular nature of this phenomenon is unclear to them”. But the significance of the discovered phenomenon of phenylalanine and leucine coding ambiguity lies far beyond molecular interactions. After ignoring that discovered phenomenon, the authors, nonetheless, postulated an unambiguity thesis of amino acid coding (one codon equals one exactly selected amino acid (or stop-position)), which in a few decades led to the worst consequences in the form of so-called transgenic engineering with its GM foods, Synthia, and so on.
As a matter of fact, no experiments are required to prove that the unambiguous model of coding is false, look into conventional table and take into account that 3’-5’ codon-anti-codon pairs, in accordance with the F. Crick’s Wobble Hypothesis, do not participate in amino acid coding [2] . And hence, 64 codons, encoding 20 amino acids, automatically fractionize into two equal parts, namely 32 codons-synonyms and 32 codons with double coding. We’ll see, for instance, that triplet (codons) of UU family, encoding amino acids such as phenylalanine and leucine, encode them simultaneously, which contradicts the postulate on their unambiguity according to Nirenberg-Crick’s model. A term of “family” is used for the 1st and 2nd nucleotide codons (doublets), and reflects the fact that the 3rd nucleotide of codons does not participate in coding. Codon doublets are combined into families, which encode amino acids in either an unambiguous or ambiguous way. In this case UU family ambiguously encodes two different amino acids.
UUU―encodes phenylalanine;
UUC―encodes phenylalanine;
UUA―encodes leucine;
UUG―encodes leucine.
(U―uridine, С―cytosine, А―adenine, G―guanine,―nitrogen bases of mRNA, on which triplets are decoded into amino acids once it’s read by the ribosome).
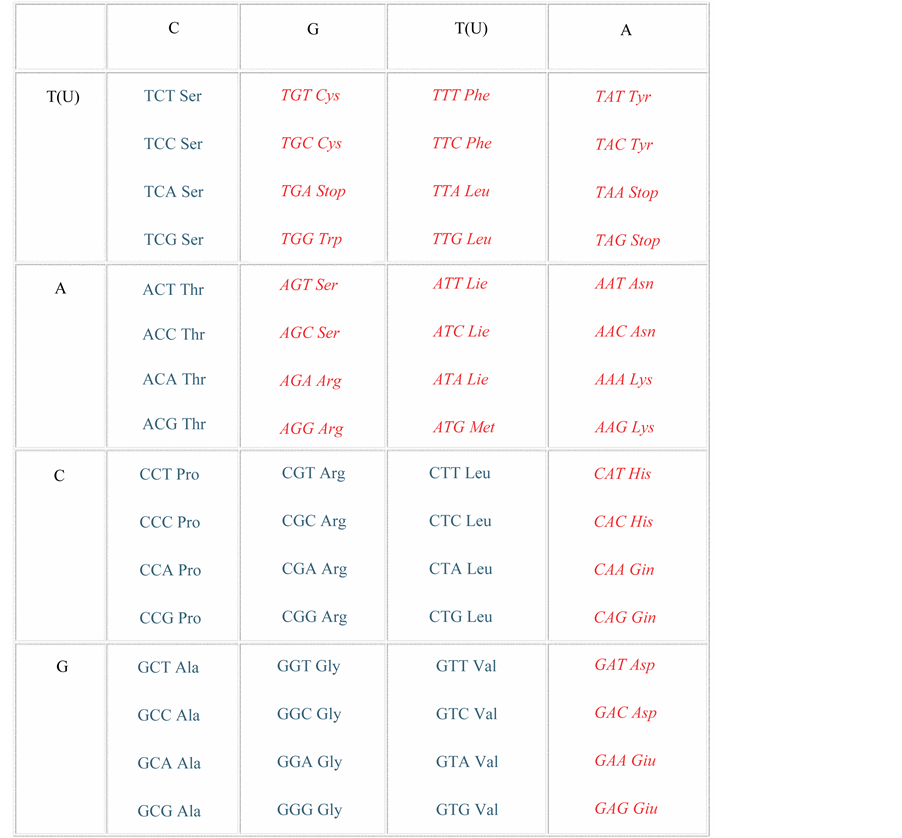
In other words, if one trusts the conventional table, poly-U RNA (equivalent of messenger RNA) in the cell- free protein synthesis system (and in the organism as well) shall code either phenylalanine or leucine only, which is not true as a matter of fact, as two different amino acids are encoded and incorporated into the growing peptide simultaneously. In other words, we get the case of homonymy, which should be somehow correctly handled by the genetic apparatus. If we do not have clear decision about the choice of one, and only one amino acid in vivo, this threatens the organism with metabolic abnormalities. The authors do not explain how in particular this, in its core, linguistic problem is resolved, thus contradicting themselves. All this is enough to prove that their code model is clearly contradictory. Now it’s time to remember the prominent statement by F. Crick, concerning the fact that the third nucleotides in codons do not participate in coding of the amino-acids, that make up proteins. The third nucleotide, as formulated by F. Crick, “wobbles”, i.e. it can become either of four possible ones [2] . If it’s so, then the authors’ postulate on unambiguity of amino acid coding by the protein genetic code becomes problematic. It is obvious even from a simple logical analysis of the table of genetic code―triplets automatically fractionize into two equal parts, where the first half encodes amino acids unambiguously and abundantly (synonymy), while the second half does it ambiguously. An important point to notice is that although the genetic code has certain regularities―in several cases it is the first two bases that encode one amino acid, the nature of the third being irrelevant―its structure otherwise makes no obvious sense [3] . Of course, it does not mean that the entire model is completely incorrect. Some of its statements are correct,―that it is a triplet code (triplets of nucleotides encode the protein amino acids), overlapping ((polycistronic) shift of the frame, reading the triplets, provide the codes of another proteins), and a synonymously degenerated code. Such code degeneration can be observed through the number of codons, which is 64, and the number of encoded amino acids, which is 20, i.e. 32 codons are synonyms, and this is confirmed by the existence of isoacceptor transfer RNA (tRNA). The synonymy means that the same amino acids can be encoded by several synonymous codons and can be correctly and unambiguously read by anticodons of a few isoacceptor tRNA’s. And what’s the function of the second, non-synonymous and incomprehensible remaining codons? The fathers of the code model had no answer to this question either. This pointed out that their understanding of the genome operation strategy is incomplete. It is here where one fundamental property of the code revealed itself, after being missed or misunderstood by Nirenberg and Crick, namely its 50% homonymy. It contradicts their canonized main provision of the model of code, namely its unambiguity. Of course, the code is unambiguous, but only after adding some functions and features of mRNA and ribosomes. But their experiment with poly-U RNA, seemingly, contradicts this canon. If a ribosome misreads a single UUU codon, that would be sufficient to demonstrate the code model’s failure, i.e. the code will work, and today it works, but not according to how Nirenberg and Crick saw the process and many geneticists still see it today. In case of UUU codon, the homonymy and ambiguity of half of the code is obvious. And there are 32 such codons-homonyms, including UUU. This contradiction in the above cited article [4] disempowers their model. Both Nirenberg and Crick missed the problem, or misunderstood it, misled others by saying that “molecular nature of this inconsistency is unclear to them”. Molecular nature has nothing to do with it. There is something fundamental in the phenomenon of homonymy of half the protein code, namely, the speech-likeness of the protein genes, but it is not metaphorical, as it is considered by majority, but real. Codon homonym mRNA may be precisely read by the correct anticodon of tRNA only when the mRNA protein synthesizing system understands the context, of which this homonym is a part, and this is the demonstration of the elementary consciousness-intelligence of genome-biocomputer. Thus, we’ve found evidence of the speech-likeness in DNA, RNA and Proteins, which incorporate the same quasi speech structures, but in different languages. Written genetic speech of the protein genes (and, perhaps, the genes of so-called small regulatory RNA or microRNA) is inconceivable without consciousness-intelligence, and this allows and even forces us to accept a strong idea about the presence of quasi-consciousness-intelligence of the genome as a small fractal dimension of consciousness-intelligence similar to the level of the cerebral cortex. Here is seen the “nerve” of the emerged problem, unrealized by the biologists and philosophers, regarding bilateral synonym- homonym degeneracy of the protein code. Theoretical and practical significance of such bilateral degeneracy of the protein code is extremely high. Let’s ask a natural question. How does the biosystem and its genetic apparatus handle the problem of homonymy with half the triplets, i.e. the problem of the accurate and unambiguous selection of amino acid (or stop-position) when theprotein-synthesizing apparatus encounters codon-homonyms? In this situation the price of mistake is tremendously high, resulting in either correct or incorrect synthesis of proteins, where some of those (enzymes) are especially vital. At the same time, it is well-known that biosynthesis of proteins is a very accurate process. Hence, the genetic apparatus “knows” a way-out of the dangerous ambiguities of codon-homonyms. The first one to understand this potential genetic homonym hazard (though he didn’t use this term) was a renowned molecular biologist Ulf Lagerkvist [5] . He reasonably assumed that the ribosome’s nucleotide reading “Two-out-of-Three” rule (the 1st and the 2nd, the 3rd “wobbles”) in codons during biosynthesis of proteins may result in biochemical disaster, unless ambiguous codons are read by the “tRNA- mRNA-ribosome system” correctly. The “Two-out-of-Three” rule automatically stems from the Crick’s Wobble hypothesis about the “wobbling” of the third nucleotide in codons, which means that the nucleotides of the 3’-5’ codon-anticodon pair do not participate in the encoding process. It also means that encoding is done by doublets (first two nucleotides of codons) instead of triplets. Back in 1978 Lagerkvist, in the mentioned publication, avoided to call and see ambiguous “dangerous” codons as homonyms. Furthermore, he unreasonably decided that such strange codons are uncommon in genome biochemistry, and that is why, they are not dangerous. It was and still is a huge mistake. Let’s take a look at the table of genetic code (Appendix), which marks and classifies homonym and synonym codons.
3. The Table of Genetic Code
As we can see, they are represented according to Yin-Yang pattern. And this is not accidental. This ancient symbol-mandala symbolizes interpenetration of two opposite inceptions, their unity and struggle, and surprisingly conforms to the operation of the amino acid code of proteins. On the one hand, biosystems must be stable and self-identical in genetic and morphologic aspect, must maintain their structure and main functions during geologically long periods of time. However, on the other hand, the biosystems are capable of and they have to adapt to long-term changes of the environment. This is exactly the purpose of such protein genetic code division into synonyms and homonyms of triplets. Synonymy provides abundance and accuracy of encoding of amino acids, while homonymy provides proper flexibility and adaptability, which takes place in the biosynthesis of every new protein form of a trial or exploratory type. A bright example of this is the immune system, accumulating tremendous pools of trial immunoglobulin and through their selection, thus, providing protection of the organism from pathogenic microorganisms, viruses and pollution. The phenomenon of homonymy of half the genetic code, which was missed or ignored by the authors of the triplet protein code model, is the basis of these processes on the genetic level. The phenomenon of homonymy of genetic information during biosynthesis of proteins becomes extremely important in light of its theoretical and philosophical understanding for the following reason. Homonymy is a factor of meanings, precisely speaking, multiple meanings of human-made written text and oral speech. The same applies to genetic texts. Gene texts are not metaphorical but real, and may be, ciphered with some kind of Universal Esperanto―the language understood by the genome, but for the time being not understood by the Human consciousness. The main point in the genetic textual aspect is that ambiguity of codon-homonyms may disappear just like it happens when a person is reading usual texts with words-homo- nyms, for instance, band, spring, box, bank, etc. We see the exact correct semantics of these words, depending on the context, i.e. taking into consideration what the entire text is about. From the point of view of philosophy, more generic principles play their part here, the categories of the Part and the Whole. The Part cannot be understood and fully comprehended without the Whole. Applied to the gene texts and protein biosynthesis process it looks as follows: A ribosome reads mRNA, as a gene’s replica, where it meets codon-homonyms. A ribosome must correctly interpret each homonym, find its exact meaning and decode it as this or that amino acid, or as a stop-codon, a signal to stop protein biosynthesis. The linguistic model of DNA has an additional theoretical justification. Language of gene texts grammatical structure and lexicons in matches to Russian language [6] .
4. What Do We Get with a Different Understanding of the Genetic Code from above Stated Viewpoints?
The exact meanings of homonyms are determined when the ribosome-nanobiocomputer (with the rudiments of thought-consciousness) perceives the text of the entire mRNA (the context). This is the key hypothetical point of Linguistic Wave Genetics (LWG). The following is essentially important in this point of view. When we transcend the narrow bounds of our understanding of genetic processes as purely physical and chemical ones, and realize that they also have the quality of Thought-Consciousness, it is a leap to deeper levels of understanding of the genome as a Quantum Biocomputer, which reads and sees genes as real text-programs. Who or what has created these programs? This is quite a special problem. There was splendid research performed by V.I. Shcherbak [7] . To some extent, it is close to our research, because it proves not only quasi-intelligence of the genome, but from the points of view of physics-mathematics and philosophy, justifies the conscious-intelligent origin in creation of genetic information, which is critically and strategically important. V.I. Shcherbak, analyzing quantitative relationships of nucleonic composition of atomic nucleuses of encoded amino acids and codons of the genetic code, suggests that a system of arithmetic operation take place in biosynthesis of proteins, and this also is the demonstration of some aspects of genome quasi-intelligence. In the protein code V.I. Shcherbak found the system of genetic computation, the system using the null function. He says that it is significant, because the null is an entirely cognitive and ultimately abstract notion, giving birth to the co-ordinate consciousness with its quantitative measurements of the external environment. These measurements are then interpreted by the internal organism’s genetic computing consciousness. As a result, digits (together with letters) become an integral part of the genetic (protein) code. And therefore, according to V.I. Shcherbak, arithmetic control in linguistic (textual) genetics is real.
Some proof is provided by experimental research done by Eidelman, who employed fast re-association of “sticky-ends” of DNA fragments as a basic factor for artificial DNA-ing technology in vitro in a demonstration for the solution of the so-called “traveling salesman problem” [8] . However, it’s not the best example. Actually today, Eidelman’s DNA-computing is performed by people, deciding on the final choice out of billions potential “solutions”, where he simulated it by re-associating sticky-end DNA fragments [9] . Developing further his ideas, V.I. Shcherbak writes: “If that is the case, some cell organelles should work as biocomputers. Thereby, we have to discover the number systems with which they work”. Then he continues: “it seems that the genetic code is connected more closely to abstract notions of arithmetic than with notions of physics or chemistry. The Chromosomal continuum is itself a kind of a biocomputer, and at the same time it is not self-sufficient and it is incorporated into cellular and tissue computing using additional cell organelles. V.I. Shcherbak regards the binary logic of digital computing of the genome a determining factor of its operation. However, translation of digital DNA-RNA “comprehension” into analogue form is regarded by him as secondary or subordinate. If this is true, this is only partially true. A strategic set of genome functions is management of holographic and textual images. In a normal computer, all information is recorded in the form of combinatorics of alterations of one and zero. This is coding of information, its cipher, it represents ciphered wealth which is to be deciphered into words and images. The Chromosome Quantum Biocomputer works without such primitive ciphering, it uses the principle of holographic processing of information in form of ready images of the inner state of cells, tissues and organs, the state received from genome holograms is the means by which a organism achieves its inner self vision and its self regulation. Binary digital logic is not abolished completely. It is required, for example, when turning protein and RNA genes on and off, which is also important, especially for building protein phrases or texts. Moreover, V.I. Shcherbak’s research is fundamental and of ideological importance, for the first time ever it provides strict and unambiguous mathematical evidence of the protein code being a quasi-intelligent system and at the sametime a small display of the Universe’s semantic nature. The origin of protein code can be understood as a conscious act rather than a consequence of the Darwin evolution.
Let’s return to the analysis of the homonymy phenomenon of a part of the code. F. Crick tried to explain the strange non-conventional behavior of 3’-5’ codon-anticodon pair of nucleotides with the help of the “Wobble Hypothesis”, proposed by him [2] . It introduces an idea of intermittent ambiguous correspondence of codons to amino acids in the encoded proteins, and explains the possibility of non-conventional, random pairing of 5’ nucleotide of anticodon of tRNA with 3’ nucleotide of codon in mRNA during translation into protein. In other words, in the course of protein biosynthesis an opportunity of a weak correspondence of codon-anticodon nucleotides is realized, it means that non-conventional pairs of bases are generated (Guanine-Uridine, etc.). From the Wobble Hypothesis as well as the general model of the code, it automatically follows that in codons of a gene, only the first two nucleotides (doublets) encode sequences of amino acids in the protein chains. 3’-codon nucleotides do not participate in coding of amino acid sequences in proteins.
These 3’-nucleotides are rigidly determined by DNA molecule, but they allow accidental, random non-cano- nized pairing with 5’-nucleotides of anticodons in tRNA for transferring amino acids. And therefore these 5’- nucleotides of anticodons can beany of the four possible nucleotides. Accordingly, 3’-5’-codon-anticodon pairs do not carry any gene-sign character, and stand for the “steric crutches” filling the “empty spaces” in codon- anticodon pairs. A crutch―is a metaphor which emphasizes the mechanical role of 3’-5’ codon-anticodon pairs of nucleotides for sustaining the stability of the mRNA-tRNA complex. But this role has an additional second very important function: switching from reading of general meaning of codons by anti-codons from synonymy mode to homonymy and back. This leads to comprehension of exact meaning of codons homonyms and prevents potential mistakes in selection of amino acids and stop positions. If because of Crick’s random wobbling, we accept a “steric crutch-switch” idea, then, it becomes clear that the 3’-nucleotide on homonymous codons of mRNA (as well as on synonymous) do not participate in coding of amino acids for protein synthesis. At first sight, it is a certain gene-semantic abuse, and the triplet code model, seemingly, loses any logic and obvious meaning.
To confirm this, let’s cite the co-author of the triplet code model theory, Francis Crick, from his autobiographical book [3] : “An important point to notice is that although the genetic code has certain regularities―in several cases it is the first two bases that encode one amino acid, the nature of the third being irrelevant―its structure otherwise makes no obvious sense.” F. Crick observed synonymous degeneracy of the code, however he did not see the homonymous one. Although, his phrase “…its structure otherwise makes no obvious sense” tells us that F. Crick’s intellect of genius realized the limitations of his model and its ambiguity, which is related to the wobbling 5’-anticodon nucleotide. When mRNA is read codon-by-codon by the ribosome together with tRNA in accordance with the “Two-out-of-Three” rule, this complex of “Ribosome-mRNA-tRNA” must inevitably crack a typical linguistic meaningful problem of homonymy. Otherwise, the errors during biosynthesis of proteins become unavoidable.
In his memoirs F. Crick, seemingly, sees “no obvious sense” in his model, perhaps, implying unobvious homonymous meaning. But further down he writes: “… although the genetic code has certain regularities”. Why certain? Because they are relevant only for a half of codons, namely for codons-synonyms, grouped by the identical first two nucleotides (the third is any one), i.e. it’s relevant just for a half of all codon families, namely for CT, GT, TC, CC, AC, GC, CG, GG synonymous nucleotide doublet families. Each of them encodes one of twenty various amino acids or is the stop-codon. At the same time the 3’-nucleotide of codon paired with the 5’- nucleotide of anticodon does not participate in coding, in such a manner ensuring synonymy. However, and it’s very important, F. Crick says nothing specific about the second half of the doublet codon families, neither here nor in his Wobble Hypothesis. They are TT, AT, TA, CA, AA, GA, TG, AG families, where each of them encodes two different amino acids or amino acid and stop-function. Here already we can see the breach of the false-postulate by Crick and Nirenberg―the unambiguity of coding. And the role of 3’-5’-codon-anticodon pairs in these families weren’t commented by F. Crick. It appears that ambiguity of coding in these strange families confused F. Crick and prompted him to mention the absence of obvious meaning in his and Nirenberg’s model. He never says anywhere about what happens outside of these synonymous “certain cases”. And namely outside of those there is a strange “obscure family” of codons, which are TT, AT, TA, CA, AA, GA, TG, AG. Nothing can be found in F. Crick’s papers to this respect.
In this manner, F. Crick implicitly raised a question of coding within the “obscure family”―But how does it happen? And he didn’t give any answer to his question. Contemporary researchers principally do not address this question either. The answer is in the hypothesis of contextual references of genetic code (ribosomes as a quantum biocomputers) during the operation with obscure (homonymous) codon families, proposed just here and formerly in [10] [11] .
5. “Two-out-of-Three” Codons as a Sign of Genome Quasi-Intelligence
Let’s ask the following questions: Could “wobbling” be a synonym of randomness? Is “wobbling” random by itself? It appears that “wobbling” is pseudo-randomness. Let’s justify the fundamental importance of the pseudo- randomness of existence of this or that 5’-nucleotide in anticodons in situations of homonymy during synthesis of proteins by ribosomes. A pair of 3’-5’ codon-anticodon nucleotides in a situation of homonymy is, by all appearances “deliberate”, and not randomly put in, as an element of gene-sign character of the ribosome technique of mRNA “reading”. The cause is that the protein code is, among other things, a quasi-intelligent structure. It deals with mRNA texts, that is not metaphorical (that’s why the phrase Genetic Text is not in quotes), but real texts, with texts of thoughts and texts of meaningful commands. The captured “pseudo”-randomness is biologically necessary. It makes the code flexible, allowing biosystems to conduct adaptively-exploratory protein searches and synthesize trial proteins in the course of their natural selection, thus adapting to the changing environment. The Protein code is synonymously generous, rich and abundant. However, at the same time it via its homonymy grows into other meaningful areas of genetic coding at the textual level of mRNA and, possibly,
pre-mRNA.
So, we have two strategies of the protein code degeneracy, which are synonymous and homonymous. The first one ensures abundance of information about amino acid selection. And the second one helps to escape ambiguous situations during relevant selection, when an organism has to adapt to the environment by incorporating trial amino acids and, consequently, proteins. And this depends on the fundamental attribute of the genetic information―its objective textual and linguistic content, i.e. meanings. If organisms automatically followed Nirenberg-Crick’s model of genetic code, within its canonical framework, then life on the Earth would have been impossible, though, everything is relatively peaceful in this regard. Synthesis of proteins is an accurate enough process as it employs such practices which can be referred to linguistics and logic, i.e. consciousness. The ribosomal apparatus and the entire genome is a quasi-intelligent system, reading mRNA text triplet by triplet (locally, part by part) and at the same time reading it as a whole, namely continually and non-locally. In particular, such non-locality of reading, the contextual perception of the meaning whole Genetic Text eliminates the problem of codon homonymy. How does it happen?
Again, let’s go back to the half-forgotten and underappreciated article by Ulf Lagerkvist, but not for criticizing the triplet model of protein code over and over, as it has played its strong role in development of genetics and entire biology. We go back to the article with the aim to understand the protein code as a dualistic sign system, with its operation based on blind physics and chemistry on the one hand, and on the other hand andconcurrently using meaningful DNA and RNA text structures as quasi-intelligent functions of the genome. However, the triplet code is only one of many subsystems of coding and for creating the dynamic image of the future organism, maybe the lowest subsystem. Higher are other programs―holographic [12] .
Ulf Lagerkvist was the first to announce the inconsistency in the triplet model of protein code, but he didn’t understand its reason [7] . He tried to bring the model out of the dead-end but failed. He couldn’t raise any objection against the obvious and potentially dangerous fact that the “Two-out-of-Three” rule is similarly observed for the ribosome translation machine under in vivo conditions “with regularity which cannot be ignored”. Then Lagerkvist writes: “I would like to suggest that misreading by the “two out of three” method could pose a significant threat to the fidelity of protein synthesis in the cell”. Lagerkvist does not explain his thoughts about “inappropriate usage of the “Two-out-of-Three” method”, this is a question left without answer. And why “not in all” codon families? Not “in all”, but particularly in homonymous and not in synonymous. Lagerkvist didn’t understand that either. Although, he sees the contradiction in the model of the code, but leaves an illusion of removing it in a following way: “…those places in the code (Gariaev: in mRNA) where the “two out of three” method could lead to translational errors are exclusively occupied by low-probability codons. This organization of the code and the competition with tRNAs having anticodons able to read all three positions of the codon would effectively prevent the “two out of three” method from being used when it might compromise translational fidelity.”
This abstract is in contradiction with the actual situation, since 50% of codons are homonymous. But the author explains about only those codons “reading all 3 positions” of nucleotides in codons, i.e. synonyms, which is incomplete, as the other half of codons (homonyms) are left behind his analysis. The remaining half, the codon- homonyms cannot be assumed as rarely occurring. Evidently reading the UUU codon-homonym is able to bring a chaos into the protein synthesis. In short, the logical contradictions of the model, which are visible even to the naked eye, are simply disregarded by Lagerkvist as well as scientific community even today. Such disregard is encouraged by the fictitiously soothing and well-known fact that ribosomes practically make no mistakes during selection of amino acids. All this led to the temptation to consider triplet model of the genetic/protein code correct. Nonetheless, the prominent shortcomings of the conventional model of the code are too evident under objective analysis.
In order to overcome the homonymy dead-end, a simple but strategic idea is required: to get back to linguistics and obtain there, the notion of the context, which will eliminate this problem of the code. A homonym loses its ambiguity only within the context, i.e. a part becomes clear when it’s seen as a part of the whole. In this regard, the notion of the mRNA context (whole text) is by no means metaphoric. Gradually, retroactively molecular biologists and geneticists acknowledge using the idea of “the secondary genetic code” [13] . Let’s cite L.P. Ovchinnikov, one of the most outstanding molecular biologists: “An Initiator codon can be seen only within a certain context. If we ask a question concerning whether it is possible to write an amino acid sequence of the protein encoded in mRNA by having a sequence of nucleotides of this mRNA, table of genetic code and, moreover, knowing that mRNA translation is performed from 5’- to 3’-end, while the protein chain is generated from N-end to C-end, then we’ll have to give a negative answer to this question. To recognize a codon as the initiator, not only the codon itself is important but rather the context assigning initiator’s role to this codon. Initiation with eukaryotes occurs… mostly from the first AUG, but only in case when AUG is in the optimal context: there must be purine (A or G) just two nucleotides before it and there must be G immediately after it. If the first AUG in eukaryotic mRNA is beyond the optimal context, it’s then missed and initiation occurs with the next AUG. In the course of initiation of translation in eukaryotes, the mRNA sequence is scanned to locate an AUG codon in its optimal context.”
As we see from this long, but extremely important citation, classical molecular biology, represented by RAS academician L.P. Ovchinnikov, in order to handle the problem of the genetic code model was forced to borrow this idea of context in homonymous codon situations. He borrowed this idea from the author of this article (however, without reference to him) and from linguistics, and was done, unfortunately in a metaphorical sense. And he introduces the second, no less important point, that there is a factor of remote influence by certain mRNA-blocks (cap, poly-А and UTR’s (Untranslated Regions)) on distant sites in mRNA where a ribosome integrates the first certain amino acid into a synthesized protein chain. This idea of “reading-scanning” an entire mRNA, i.e. mRNA context, was required. All these explanatory factors in general had been predicted by P.P. Gariaev before, including the mechanism of polynucleotide scanning via soliton excitations of RNA and DNA [10] . Another important aspect should be noted here, the reinterpretation of codons depending on the context, this doesn’t fit into the Procrustes’ bed of the canonized triplet model, and also the factor of ribosome reading mRNA frame shifts has been known for a long time.
It is obvious, that such mRNA frame shifts cannot be explained by physics and chemistry alone, or by remote contextual impacts leading the reinterpretation of codons. What’s required is the acknowledgment of other sign aspects of the genome, the transcendence of its logical operations as a quantum computer [14] and to its mathematical logic using ultimate, purely intellectual operations, which employ the abstract concept of the null [15] , are now significantly new ways of understanding biology and genetics. It’s indicative [13] : “...that reading of mRNA within a single cistron is not always continuous. Originally it was assumed that nucleotide sequence in mRNA is always read continuously from the initiator codon to the stop codon. However, it turned out that in the course of translation of Phage T4 Gene 60 mRNA a considerably long sequence can be bypassed. In such a case a ribosome makes kind of a 50 nucleotide jump along mRNA from one GGA glycine codon located before UAG stop codon to another GGA glycine codon. The mechanism of this phenomenon is not absolutely clear yet. And this is one of numerous examples of genome operation, lying beyond the existing canons and dogmas. Sure enough, such ribosome “jumps” should stem from the real, not metaphorical, reading and understanding of mRNA meaning (one should know from and where to jump). This leaves no chance for allegory or metaphor here anymore. All these deviations from the canons of the triplet model L.P. Ovchinnikov called “the secondary genetic code” [13] .
What type of code is this? On what principles is it based? It must be that key mechanisms are used by genomes as linguistic potentials of DNA and RNA molecules, which are, in fact, the real intellectual structures and/or components of bio-holographic programs. Only in this context, we are able to understand the real meanings and implications of the exceptions from the “general” laws of translation of genetic information from mRNA texts. Active and vital desire to find different codes in DNA has already led geneticists to assume that there are dozens of codes in the genome. Eduard Trifonov writes about this in a funny and biting manner as a pandemonium of the Second Genetic Codes: [http://trv-science.ru/2012/01/17/stolpotvorenie-vtorykh-geneticheskikh-kodov/]. This is a declaration of the confusion about the difficulties of chromosomal coding, as even the first genetic code discussed here is not yet fully understood. Let’s make an intermediate summary about discovery of these new fundamental phenomena within the framework of the first Nirenberg-Crick’s model of genetic code, the phenomena stated (but not yet understood) by official science:
a) distantness contextual influence by differently remote mRNA sequences on the exact comprehension of codons, read by a ribosome, and on their recoding,
b) non-local scanning of long mRNA sequences,
c) meaningful mRNA reading frame shifts,
d) long-distance ribosome “jumps” along mRNA,
e) recoding of codons.
6. “Genome Thinking” Methods
Let’s try to understand what happens within contextual situations, including homonymous ones, with coding doublets, while keeping in mind Lagerkvist’s “Two-out-of-Three” rule, which stems from Crick’s idea (hypothesis) on wobbling of the 3’-nucleotides in codons. Acknowledging the thesis of genome’s quasi-intelligence, we should interpret genetic homonymies in the same way as done in linguistics. Namely, the informational content of the homonym becomes clear only after reading and comprehension of the whole text (or sufficiently large part of it), i.e. the context, regardless whether it’s a human or genetic text. For example we cannot understand the meaning of such homonyms as “band” and “spring” without knowing the whole phrase or sentence. Similarly the ribosomal translation quasi-intelligent system has to read and comprehend the whole mRNA text or its larger part to make an accurate decision to choose this or that meaning (code) of codons-homonyms, or such as to make the decision about ribosome “jumping” on a strictly defined distance along mRNA chain. This applies to the situation when triplets are re-coded. Here the notion of context probably has a bigger reference, going beyond linguistic framework. For example, in case of amino acid starvation or heat shock situations, the biosystem considers critical ecological-biochemical emergencies as “contextual”, requiring immediate or time-con- suming evolutionary adaptations with subsequent injection of new contextually selected amino acids and subsequently the synthesis of new trial proteins. In general, geneticists and molecular biologists’ attitude to the synthesis of proteins can and must considerably change. This process can no longer be seen as purely physical-chemical interactions of DNA, RNA, enzymes, ribosome proteins, amino acids and the other metabolites. We have numerous examples of multi-dimensional intelligence of the whole organism as well as its parts―tis- sues, cells and the whole genome.
Historically, linguistic terminology in relation to the protein code has been applied for a long time and everywhere. Namely, from the moment in early 60s of the last century, when F. Crick and M. Nirenberg started calling DNA molecule a text. It was a brilliant anticipation; however F. Crick and the majority of others, using this term until now, understand the textual aspect of DNA, RNA and proteins as a metaphor, borrowing or leasing the intellectual origin from linguistics. Let the classical geneticist assume for a moment that these terms, applied to the chromosomal apparatus, are not metaphoric. Then logic will strongly suggest that the protein synthesis system and genome have a minor consciousness and intelligence or their equivalent in the form of biocomputing [14] [16] , acknowledging that Consciousness of Nature combines real physical-chemical and quantum acts in one super-sophisticated metabolic network of protein synthesis.
Although the idea of genome computing in vivo is nothing more than a model, and this model is considerably more developed than just seeing protein biosynthesis merely as chemistry-physics and biochemistry. Genomes are intelligent, in their own scale, and within their own limits. This ideology traces its origin back to Aristotle with his entelechy postulate [http://www.bibliotekar.ru/brokgauz-efron-ch/166.htm] and to Driesch [http://vikent.ru/author/2259/] [17] . To this turn, namely a return to a new level of the “causa finales” formula, classical genetics is not yet ready. This restrains biologist thinking, and this is quite counterproductive. It is stagnation, and we all see its results: conventional genetics and medicine cannot and will not be able to defeat cancer, tuberculosis, AIDS, aging, etc, with the old theoretical base. However there is a way out. It lies with the serious consideration of new, biosemiotic or epigenetic models of the genome, which are the subject of this study. And a lot has been done in this direction. The Biosemiotic aspect of genetics was magnificently represented by Sedov’s and Chebanov’s works, as well as some foreign researchers [http://www.zanoza.lv/blog/gordon/430]. They see not merely the textual aspect of the genome but its aesthetical aspect too: “In many regions of DNA they found refrains, which are “tunes with variations”, rhythmical and meaningful iterations, resembling homonyms, poetical rhymes and musical themes”.
DNA-protein musical phenomena deserve special attention. In the Western world production and marketing of such DNA- and protein “music” has reached a mass scale. Nucleotides and amino acids in DNA and protein sequences are designated with the notes according to specific algorithms. As a result they obtain, not a bunch of chaotic sounds but something harmonious and music-like. Attempts are made to use these sounds for therapeutic purposes. Any existing search engine in the Internet will provide a list of links for “DNA music” or “Protein music”. Businessmen disregard genetic science and irresponsibly exploit for profit the incomplete understanding of the wave, musical and sign functions of genetic structures. Listening to such “music” created without due control and foreknowing of possible after-effects in quite dangerous, as this may introduce hardly known wave information vectors into our metabolic “DNA-protein reactor”.
Some intelligence of the genome can be observed within the natural mutation process (the random field), where chaotic, stochastic processes supposedly predominate, though, the notion of chaos, as an absolute randomness is thing of the past. Prior the discovery of DNA, a chaotic mutation process allegedly formed the basis of the evolution, and “the ambiguous variability of characteristics of organisms”, were according to Darwin the “raw material” of evolution. It’s worth remembering that at the end of his life Darwin realized and admitted that seeing random variability as a basis of evolution is a fiction. If the protein code contains and employs strictly intellectual structures such as text, reading, recognition, determination, mathematical logic, etc., then it looks natural to admit, at least in its hypothetic form: both genome and protein code had been created with thought- consciousness, and the genome is intelligent.
Stochastic processes in operation of chromosomal DNA are optimized, and perhaps, there is a compromise between stochastic processes and determinism. The random nature of genomic mutation has been well studied for a long time. Such DNA mutations are mainly detrimental if they affect the Protein and RNA-coding chromosome regions (euchromatin), or they are neutral, in case of allegedly “non-coding” chromosome DNA (heterochromatin) mutation. Surprisingly, mutations become beneficial, if the cell controls the semantic aspect, and contribute to intelligent, non-Darwinian evolution [18] . Such mutations, specially selected and implemented by the biosystem itself, can hardly be called random. These mutations do not necessarily provide the raw material for long-term evolution, alternatively they can be quickly engaged within a single life cycle of the biosystem. These combinatorics are set by the organism on purpose. It is clear from the results of the immune genetic research; where amino acid sequences of antibodies, referred to as Wu-Kabat sequences (diagrams), are consciously, thoughtfully and preventively selected by B-lymphocytes [14] . Wu-Kabat amino acid sequence diversity is the result of hyper-variability of V(D)J genes of antigen-binding regions of immunoglobulin antibodies. This hyper-variability is, as one would assume, purposefully (consciously) and preliminarily set by the genome to “recognize” antigens at the molecular level. First of all, a cell and its genome scan an antigen in some myste- rious way, then it determines a set of V(D)J genes’ recombination for the directed selection of encoded amino acids involved in immunoglobulin antigen-binding sequences. V(D)J genes’ behavior contradicts to neo-Dar- winian dogma, that the whole of a genes variability in the germ line is pre-existent even before the selection takes place. But keep in mind, that there is no exact and instantaneous “decision” on selection of amino acids (no full determinism) during operation of V(D)J genes, however, there is no absolute stochastic process either, because mutations are controlled (set) by an organism itself. In other words, there are both direct and inverse relationships between the trial sets of mutations and of the antigen-binding structure in immunoglobulin. Randomness and regularity are in balance here.
The Protein-genetic code was created by Intelligence. Let’s follow Spinoza and Nalimov and consider the Universe being the reason for itself (“causa sui”) as well as being linguistic, i.e. intelligent [19] [20] . Then immune competent cells and their genome purposely and intelligently use randomness, creating relevant genetic texts featuring certain semantics, resulting in an adequate immune response.
Naturally, such genome intelligence operates within the given and limited bounds of immune problems, and its scope is incomparable to the intelligence of the Human brain. Thus, this demonstrates the general concept of biosystem fractality, including gene-cell-tissue-organ and organism intelligences. We see some non-linear, fractal iteration of the same phenomenon of intelligence, consciousness and mentality on different scale, depending on the considered level of biosystem organization. The levels are organism, organ, tissue, cell and genome. Intelligence, consciousness and mentality can be seen as a biosystem’s way to reflect with its environment for the purposes of self-regulation in order to ensure its integrity, survival and evolution. The means of speech (brain/cerebral cortex) and quasi-speech (genome) intellect are ways to actualize this.
One would be inspired by pantheism and think that genetic apparatus along with all organisms is the result of the actions of the Creator. And therefore, everything in a organisms is intelligent. And we could leave it there. But it’s extreme, because then we havean answer to Everything, but Nothing in detail. It’s a universal “black box”. Any question may be asked for an input, with the same allegedly right generic answer provided as an output. This is incorrect. Real research is required on chromosome operation, based on Linguistic Wave Genetics (LWG). There have been promising results already, which are briefly presented at www.wavegenetics.org. For example, regeneration of the eye’s retina has been performed, the sense of vision has been recovered, and from now on it’s feasible to regenerate injured spinal cord and cerebrum to their full functionality. All those achievements have the same core―the programming of the stem cells’ genome based on completely different understandings of the operation of the genetic apparatus. There are prospects to go far beyond medicine: launching of quantum biocomputers, operating via quasi-intelligence of chromosomes; creation of the biointernet; development of the deep space communication, etc. All these achievements and opportunities are possible due to not only the linguistic aspect of genetic information but its quantum, wave dimension. Such attributes are inherent to the chromosomal apparatus of biosystems as a sort of capability to operate as wave equivalents (phantoms) of
7. New Types of Nucleic Acid Memory―New Strategies of Genetic Coding
7.1. DNA and RNA Phantoms
The DNA phantom formation phenomenon was discovered by P. P. Gariaev in 1984 at the Institute of Physical and Technical Problems of the Academy of Sciences of the USSR [7] [12] . This phenomenon is about a trace left by DNA after it has been mechanically moved to another location. The trace is left in the original location of the physical DNA. The method of correlating laser spectroscopy allows its detection by registering light diffusion not only from DNA molecules but from DNA traces as well, so-called DNA phantoms. These DNA traces- phantoms reveal resistance to attempts to “blow them away” with the pure nitrogen, they disappear but come back again after 5 - 7 minutes. They ‘live” for about 40 days. After 40 days they can no longer be registered by the equipment. Using this same method, in 1990, the team of R. Pecora from Stanford University discovered the same phenomenon in solutions of short restriction fragments of DNA. Diffusion of light of such DNA preparations is different from what would be expected in classical terms of physics and mathematics. This distinction was noted but not explained by the authors and was then named “The Mimicking Dust Effect” [22] . During those experiments a solution of DNA restriction fragments only, without any impurities, when scanned by the laser beam, demonstrated a strange behavior as if it contained some foreign dust-like particles.
This dust mimicking confused the authors, who failed to find any reasonable explanation of such abnormality. Perhaps, the same explanation as we had in our case would suit them too. During the Brownian movements of DNA fragments in water, they leave traces-phantoms, which provide this additional abnormal contribution to the light diffusion.
Something similar is typical to molecules of RNA. A team from the Max Planck Institute, under the direction of the Nobel Prizewinner M. Eigen and other researchers, found that the enzyme Qb-replicase (RNA-dependent RNA-polymerase phage Qb) is able to synthesize RNA molecules in the form of short sections of 100-300 nucleotides (so-called 6S RNA) without an RNA template [23] . From the perspective of the molecular biology, as well as physics, this is principally impossible. The strict control of RNA impurities showed their total absence. Importantly, abnormal synthesis of RNA does not start immediately as it would do when usual RNA templatesare used, but after an 8 hour lag period. Perhaps, in this situation RNA phantoms are functioning in a similar way to so-called DNA phantoms. This template-free phantom 6S RNA synthesis has not yet been explained.
What is the Natural and biological role of such DNA and RNA phantoms? First attempts to explain this have already been made based on the principles of holography [24] . To consider these phenomena as an accidental side effect is not reasonable. There is also direct experimental proof for powerful regulatory function of DNA phantoms. When a native DNA preparation in a spectrometer is denatured by exposure to heat (~90 degrees centigrade) to induce its special dynamic behavior―and then, gradually cooled down to 20 degrees centigrade and then removed, then DNA phantoms induce another preparation of identical native DNA located in the same cooled-down spectrometer, to behave as if this preparation has also undergone denaturization [12] . It is difficult to work with naturally generated DNA phantoms due to their polymorphism and little predictability.
We have developed the technologies for laser generation of DNA phantoms and accompanying secondary radiation using a special helium-neon laser which scans DNA preparations [11] [24] . The secondary radiation was named Modulated Broadband Electromagnetic Radiation(MBER). MBER-DNA-phantoms were found to conduct transmission of active morphogenetic information over long distances. In Moscow (2000), Toronto (2001) and Nizhni Novgorod (2007) this phenomenon allowed us to successfully perform remote regeneration of rat’s pancreas after artificial alloxan toxin induced diabetes [25] [26] . That was certified by an independent group of researchers [27] .
In 2010 generation and remote transmission of DNA phantoms were performed by the team of Noble Prize winner Luc Montagnier, however, they used their own method [28] . Luc Montagnier et al., read some electromagnetic information from a short fragment of DNA (102 nucleotide pairs) and transmitted it to the pure water, in which later they performed the reaction of replication and amplification with PCR of the original short fragments of DNA using nucleoside triphosphates, without a material template of DNA. Comparative to Qb-repli- case RNA template-free RNA Synthesis, this was DNA template-free PCR synthesis of DNA based on its electromagnetic phantom. Luc Montagnier et al. did not provide any details of their method of detection of materialized DNA phantoms, and, as far as we know, no one has repeated their experiments. We have made available the methodology of our technology for obtaining MBER-DNA-phantoms and their application to template-free PCR synthesis of DNA [29] . The nature of DNA phantoms, discovered by L. Montagnier’s team is still not completely known from the point of view of physics. The MBER-DNA phantoms, that we produce, can be interpreted from the perspectives of holography [14] . Perhaps, DNA and RNA phantoms are a type of an epigenetic quantum derivative of chromosomes, a la Gurvich’s Theory of the Biological Field; this may be the main repository of the genetic information. The biological (genetic) activity of MBER-DNA-phantoms have been demonstrated by us and by other independent researchers [26] [30] . Noteworthy M. Pitkanen’s idea that genetic code and DNA phantoms can be interpreted from the standpoint of geometric topology dynamics as a manifestation of the cosmic computing [31] .
7.2. Non-Linear Dynamics of DNA, Ribosomes and Collagen
In 1984 at the Institute of Physical and Technical Problems of the Academy of Sciences of the USSR, applying laser correlation spectroscopy, P. Gariaev discovered a phenomenon of recurrent memory of DNA, ribosomes (50S sub-particles of E. coli bacteria) and collagen [7] [12] . In vitro preparations of DNA, ribosomes and collagen with strict periodicity produced isomorphic vibration spectra in the form of temporal autocorrelation functions. In fact, those preparations radiated a sound field with iterating spectral content, alternating with non- iterating. Such a behavior within non-linear vibration systems was called “Fermi-Pasta-Ulam Recurrence” (FPU) in the names of the physicists, who discovered this phenomenon in 1956 [32] . This is of fundamental importance and is regarded as a memory of a non-linear systems initial mode(s) of excitation and is of soliton type- (non-dissipative solitary wave which is neither preceded nor followed by another such disturbance). FPU recurrence can be observed in long-distance power transmission lines, in nerve impulses, in electromagnetic generators, in vibration dynamics of DNA, ribosomes, and collagen as well as in many other wave processes.
We designed an electromagnetic generator with a spectrum of radiation in which FPU recurrence took place. With this we successfully achieved remote transmission of morphogenetic information from Xenopus laevis embryos to preparations of the early gastrula ectoderm of Xenopus laevis with subsequent morphogenesis of the set of neural and mesodermal derivatives―premordia of the nerve tube, muscles, and intestine [7] [10] . In fact, this was the first remote electromagnetic programming of totipotent cells of early gastrula ectoderm and one of the testimonies for the existence of genetic information in a form of a physical field, as it was predicted by A.G. Gurvich in 20 s - 40 s of the last century. FPU recurrence at the level of chromosomal DNA can be considered as one of the forms of recurrent wave epigenetic memory, which is used by biosystems to regenerate organs and tissues―human liver, crab’s claws, cephalopods’ tentacles, planarians’ body, plant regeneration, etc.
7.3. MicroRNA (miRNA). Potential Role
A rather large class of so-called miRNA exist [http://en.wikipedia.org/wiki/MicroRNA], they are 21 - 22 nucleotides long. On their own such short polyribonucleotides are hardly capable of bearing any information. But nevertheless, the importance of miRNA is still extremely high, and can exert both a positive and negative influence on gene expression, depending on how miRNA-mRNA pairing affects the secondary structure of mRNA, and thus, also directly and indirectly control binding of other regulatory factors. Some miRNA can regulate activities of non-coding RNA. MicroRNAs can, probably, also function without pairing with nucleic acids targets, for example, through competition with other RNA for protein binding. Micro RNAs are a large set of the structural elements whose functions are often well-known and significant, but the strategic mechanism of regulation of miRNAs themselves is not understood. Despite having tiny dimensions, miRNAs perform important regulatory work, such as repression of mRNA translation without its destabilization. Today new experimental data on the powerful regulatory functions of miRNA are increasing rapidly. This becomes a problem for researchers, because it’s not clear, how, what or by whom miRNAs are regulated, as essentially they perform quasi-intelligent work of regulating metabolism in biosystems. This is a part of the great theoretical problem about, how small components regulate countless tactical variants of metabolism. In this respect, miRNAs are not an exception.
Similar to the problem of the regulation of the miRNA itself, is the meaning of accurate transposition of mobile genetic elements, accurate and distant tRNA translocation to relevant codons, antigen-antibody recognition, recognition of binding sites by restriction enzymes, finding binding sites on cell membranes by viral receptors, and p53 protein targeting of its multiple operational sites, etc. We can give countless examples of quasi-intelli- gent organizing interactions within the space of the intracellular liquid-crystal matrix. This is of molecular scale. However, the same can be seen on the level of herd behavior, in examples of bees interacting while building their combs, ants creating their nests, termites creating their hills, etc. Is this a manifestation of some sort of “collective unconsciousness” or higher organizing intelligent principle? We don’t know. Perhaps, a simple explanation of such phenomenon lies within the principles of Linguistic Wave Genetics. By assuming that a phrase of genetic text is not a metaphor, we automatically have to accept an idea of the grammar of such texts, not necessarily similar to those of human’s languages, which are, according to N.Khomskiy, universal
[http://www.textfighter.org/raznoe/Linguist/homsk/homskii_n_aspekty_teorii_sintaksisa_lingvistiki.php]. The grammar of genetic texts being like ‘Universal Esperanto’ have their own specific features, distinguishing them from natural languages but related to them [28] . We can assume that miRNAs represent a complex system of genetic text punctuation and generation of other signs-symbols, which set new arenas of meaning, depending on how textual targets of DNA and RNA are affected by miRNAs. It is reasonable, if we consider the genome as a quantum biocomputer, performing elementary acts of Consciousness-Intelligence and Speech (texts) [21] .
7.4. Can the Existence of the Homonymous Strategy of Degeneracy of the Triplet Protein Code Be Proved Experimentally?
The Main idea of this research is that the classical model of the protein synthesis (genetic code) contains a strategic mistake of misunderstanding of the double synonymous-homonymous degeneracy of the protein triplet code. Detailed evidence of codon-by-codon mRNA collinearity and corresponding amino acids and stop-posi- tions in the composition of the resultant proteins, encoded by them, is not surprisingly absent in the scientific literature. If detailed evidence were available, this could have brought clarity on the role of non-synonymous codons (homonyms). The only known case is the one of codon and amino acid replacement in the haemoglobin (HbS) protein in sickle-cell anemia, though numerous works on codon replacement have been done, comparative analysis of collinearity has not been performed, according to existing scientific literature.
With a certain degree of confidence we could predict that the same codon-homonyms for different proteins, or even within mRNA of large proteins, would (to a certain percentage) encode different amino acids or stop-posi- tions, depending on the context of mRNA. This would be one of the theoretical arguments for ambiguous degeneracy of the protein code. Although, the ambiguity of homonymous coding was shown experimentally by the authors of the protein code model from the very beginning as they demonstrated that UUU codon ciphers both phenylalanine and leucine simultaneously, which is contrary to their dogma of unambiguous encoding of protein amino acids. Further evidence has been introduced recently, that UGA codon may simultaneously encode selenocysteine and cysteine in one species of amoebae, and as a homonym it ciphers the stop position in animal cells [33] . The number of such publications will inevitably keep on growing.
Homonymy of half of the codons can be proved indirectly, without costly experiments, following the stated below logic. Short mRNA with small context sizes will code not a single but a few peptides, as with the shortening of mRNA, its context ambiguity will be growing as well, for example, for a word like “band”. Without the context this homonym-word will have several potential meanings. If you add letters “ha” and have “ha… band” ―the context is too short, the meaning will not be revealed, the ambiguity will remain, but if you have “hair band” the ambiguity of meaning disappears, leaving us with unambiguity―it becomes clear which band we are talking about.
The results of the research of [34] , the authors achieved biosynthesis of additional peptide fractions, using two seven-codon RNA templates. That is, two short artificial mRNA-sequences with unclear biological functions (contexts) were used. They predetermined the biosynthesis of more than two peptides, which is unusual. The increased broadening of the mass spectra obtained of the synthesized in vitro peptides demonstrated this, which proved the synthesis of additional, “unplanned” peptides with variable amino acid composition. Besides that, additional peaks, showing deviations by mass, were found in mass spectra. This also confirms synthesis of “unplanned” peptides. This also demonstrates the key point―a context dependent syntheses of multiple peptides. Similar deviations by mass were not observed in control spectrum of the pure peptide with known biological function. This method could be a key to proving the homonymous strategy of the degeneracy of the protein (genetic) code.
Another strategy to prove other epigenetic functions of the genome, was hinted by research of Lolle et al. [35] . This research caused a great disturbance in genetics, since its findings questioned the seemingly indisputable laws of G. Mendel. The discussion on this subject has been going over a decade. The point the authors is that “Arabidopsis thaliana” plants, homozygous for the recessive mutant gene HOT HEAD5 (HTH), can inherit allele-specific information, which is absent in the genome of their parents, but had been present in previous generations. This demonstrated, an earlier unknown process, which occurs with all polymorphisms of the considered DNA sequences, and, hence, appears to be a generic mechanism for extra genomic inheritance.” The authors postulate that “these genetic phenomena of restoration are the result of a template directed mechanism using a cryptic-store of sequence templates, “RNA Cache Hypothesis” (“hidden RNA”). Note, that this “hidden RNA” has not been found yet.
From the Linquistic Wave Genetics viewpoint this phenomenon has two explanations. The first one is that the locus of the mutant gene including the gene itself, is surrounded by DNA sequences of variable nucleotide composition. These sequences provide different contexts for mRNA, including those sequences that change the meaning of the homonym-triplet despite of nucleotide stability of this homonym-triplet within the mRNA sequence of the coding doublet. Accordingly, the protein product of this gene will include another amino acid (or trigger stop position) compared to the initial mutant. This will be another protein that may lead a return of the plant phenotype to its ancestral form. Unfortunately, the authors did not give codon-by-codon breakdown of the HOTHEAD gene and, it is unknown whether the mutated codon represents synonym or homonym. Comparative sequencing of the protein products of the mutant and the ancestral gene have not been performed, which could significantly help in determining the role of homonyms in the code. Another explanation of phenotype reversion of A.thaliana is that the ancestral gene is present in the form of phantom DNA or RNA, and is materialized by the replication system of the plant, as it happens in vitro [29] [36] [37] . And what’s important―DNA phantoms are stable in time and space and can be consistently reproduced (materialized) with the PCR system (unpublished data).
8. Conclusions
During 50 years of its existence, the canonized dogmatization of F. Crick-M. Nirenberg’s triplet model of protein genetic code, came into contradiction with new experimental facts and new theoretical analysis of genome operation. The main drawback of the previous code model is in misunderstanding and denial of the ambiguous synonymous-homonymous degeneracy of the code, the real linguistic aspect, i.e. quasi-intelligence. In practical terms, this led to “genetic engineering”―disastrous manipulations with chromosome DNA texts. Now we have products that are of a danger to Humanity―GM foods, and Synthia with an artificial genome. Another limitation of outdated genetics and molecular biology is that even the correct interpretation of the triplet protein code is just the tip of the iceberg. There are other levels of “extra genomic coding”, called epigenetics, however, these also remain in the Procrustean bed of the old and incorrect model of the protein code, looking for new regulatory mechanisms of the same, not quite understood, protein synthesizing apparatus.
Now we must look beyond, toward other arenas of genome operation. The future lies in the strategic, wave- level of understanding of chromosomes as quantum biocomputers with quasi-intelligent functions of operation with text-holographic structures of DNA, RNA and Proteins [21] . The future herein is in studying phantom functions of DNA and RNA. The future of genetics is in exploring quantum non-locality principles of DNA operation, revealing themselves as FPU, holographic and phantom types of DNA memory, these are main directives of the biosystems genesis and their regenerative abilities. It’s time to more intensely study these particular, new, reflective functions of the genome. This is transcendence to completely new level of evolution for Humanity.
References
- Gurvich, A.G. (1944) The Theory of the Biological Field. 28.
- Crick, F.H.C. (1966) Codon-Anticodon Pairing. The Wobble Hypothesis, 19, 548-555.
- Crick, F.H.C. (1989) What Mad Pursuit. A Personal View of Scientific Discovery. Basic Books, Inc. Publishers., New York.
- Nirenberg, M. and Krik, F. (1964) T. LXXXII, Nauk. Physics of Our Days. http://ufn.ru/ufn64/ufn64_1/Russian/r641c.pdf
- Lagerkvist, U. (1978) “Two out of Three”: An Alternative Method for Codon Reading. Proceedings of the National Academy of Sciences of the United States of America, 75, 1759-1762. http://dx.doi.org/10.1073/pnas.75.4.1759
- Grinevich, G.S. (2001) Beginnings of Genetic Linguistics. M. Ed. Chronicle. Monograph, 320C.
- Gariaev, P.P., et al. (1991) Hologrphic Associative Memory of Biological Systems, Proceedings SPIE―The International Society for Optical Engineering. Optical Memory and Neural Networks, 1621, 280-291.
- Adleman, L.M. (1994) Molecular Computation of Solutions to Combinatorial Problems. The First DNA Computing Paper. Describes a Solution for the Directed Hamiltonian Path Problem. Science, 266, 1021-1024. http://dx.doi.org/10.1126/science.7973651
- Gariaev, P.P., Macedonian, S.N. and Leonova, E.A. (1997) Biocomputer on Genetic Molecules as Reality. Information Technology, 5, 42-46.
- Garyaev, P.P. (1997) Wave Genetic Code. Izdattsentr, Moscow, 107c.
- Garyaev, P.P. (2009) Linguistics Wave Genome. Theory and Practice. Kiev. Monograph. 216 p.
- Garyaev, P.P. (1994) Wave Gene. Russian Academy of Sciences, Moscow, 279 p.
- Ovchinnikov, L.P. (1998) What and How Is Encoded in the mRNA. Moscow State University, Soro-Sovski Educational Journal, No. 4, 10-18. http://bio.fizteh.ru/student/files/biology/bioarticles/f_4ai2
- Kabat, E.A., et al. (1977) Sequence of Immunoglobulin Chains. US Department of Health, Education and Welfare.
- Shcherbak, V.I. (2003) Arithmetic inside the Universal Genetic Code. BioSystems, 70, 187-209. http://dx.doi.org/10.1016/S0303-2647(03)00066-2
- Garyaev, P.P., et al. (2007) Theoretical Models of Wave Genetics and Reproduction Wave Immunity in the Experiment. New Medical Technologies, New Medical Equipment, No. 11, 26-70.
- Prangishvili, I.V., Garyaev, P.P., et al. (2000) Radiated Emission Spectroscopy Localized Photons: Exit to Quantum Nonlocal Bioinformatic Processes. Sensors and Systems, 9, 2-13.
- Steele, E., Lindley, R. and Blanden, R. (2002) What If Lamarck Rights? Immunogenetics and Evolution. M., Mir, 237 p.
- Nalimov, V.V. (1989) The Spontaneity of Consciousness. Probabilistic Theory of Meaning and the Meaning Architectonics-Leach of. M. Prometheus, 287 p.
- Spinoza, B. (1677) Ethics.
- Gariaev, P.P., Birshtein, B.I., Iarochenko, A.M., Marcer, P.J., Tertishny, G.G., Leonova, K.A. and Kaempf, U. (2001) The DNA-Wave Biocomputer. In: Dubois, D.M., Ed., “CASYS”―International Journal of Computing Anticipatory Systems, CHAOS, Liege, Belgium, 290-310.
- Allison, S.A., Sorlie, S.S. and Pecora, R. (1990) Brownian Dynamics Simulations of Wormlike Chains: Dynamics Light Scattering from 2311 Base Pair DNA Fragments. Macromolecules, 23, 1110-1111.
- Biebricher, C.K., Eigen, M. and Luce, R. (1981) Product Analysis of RNA Generated de Novo by Qb Replicase. Journal of Molecular Biology, 148, 369-390. http://dx.doi.org/10.1016/0022-2836(81)90182-0
- Gariaev, P. and Pitkanen, M. (2011) Model for the Findings about Hologram Generating Properties of DNA. DNA Decipher Journal, 1, 47-72. http://scireprints.lu.lv/160/
- Gariaev, P.P., Tertyshniy, G.G. and Tovmash, A.V. (2007) Experimental Studies of in Vitro-Sky Holographic Display and Transfer of DNA Complexed Sinformatsiey Her Environment. New Medical Technology, 9, 42-53.
- Garyaev, P.P., Kokaya, A.A., Mukhina, I.V., Leonova-Garyaeva, E.A. and Kokaya, N.G. (2007) Effect of Electromagnetic Radiation Modulated by Biostructures on the Course of Alloxan-Induced Diabetes Mellitus in Rats. Bulletin of Experimental Biology and Medicine, 143, 197-199. http://dx.doi.org/10.1007/s10517-007-0049-3
- Ostrovsky, Y., Tertyshniy, G.G. and Eventov, V.L. (2014) MANAGEMENT Normalization of Functioning of the Cells of the Organism. http://hologrammatrix.com/index.php/8-stati/2-up-r-avl-e-nie-n-o-r-m-a-l-i-z-a-ts-i-ej-f-un-kts-ioni-r-ov-a-niya-k-l-e-t-ok-o-rg-a-n-i-z-ma
- Montagnier, L., Lavallee, C. and Aissa, J. (2012) Remote Transmission of Electromagnetic Signals inducing Nanostructures Amplifiable into a Specific DNA Sequence. US Patent No. WO 2012 142565 A2.
- Gariaev, P.P., et al. (2014) Materialization of DNA Fragment in Water through Modulated Electromagnetic Irradiation. Preliminary Report. DNA Decipher Journal, 4, 1-2.
- Gariaev P.P., Kokaya, A.A., Mukhina, I.V., Leonova-Garyaeva, E.A. and Kokaya, N.G. (2007) Effect of Electromagnetic Radiation Modulated by Biostructures on the Course of Alloxan-Induced Diabetes Mellitus in Rats. Experimental Biology and Medicine Bulletin, 143, 155-158.
- Pitkanen, M. (2010) The Notion of Wave-Genome and DNA as Topological Quantum Computer. http://tgd.wippiespace.com/public_html/pdfpool/gari.pdf
- Fermi, E., Pasta, J. and Ulam, S. (1955) Studies of Nonlinear Problems. Physics Report.
- Turanov, A.A., Lobanov, A.V., Fomenko, D.E., Morrison, H.G., Sogin, M.L., Klobutcher, L.A., et al. (2009) Genetic Code Supports Targeted Insertion of Two Amino Acids by One Codon. Science, 323, 259-261. http://dx.doi.org/10.1126/science.1164748
- Garvin A.M., Kenneth, C.P. and Larry, H. (2000) MALDI-TOF Based Mutation Detection Using Tagged in Vitro Synthesized Peptides. Nature Biotechnology, 18, 95-97. http://dx.doi.org/10.1038/72013
- Lolle, S.J., Victor, J.L., Young, J.M. and Pruitt, R.E. (2005) Genome-Wide Non-Mendelian Inheritance of Extra-Genomic Information in Arabidopsis. Nature, 434, 1-4.
- Garyaev, P.P., et al. (2014) Method of Producing PCR Product of DNA Using Wave Replicas of DNA (Genes) and the Device for Its Implementation. 2014/06578. 8 September 2014.
- Gariaev, P.P., et al. (2014) Materialization of DNA Fragment and, Wave Genetics in Theory & Practice. DNA Decipher Journal, 4, 1-56.
Appendix: The Table of the Genetic Code