Open Journal of Statistics
Vol.04 No.10(2014), Article ID:51474,5 pages
10.4236/ojs.2014.410080
Estimation of Multivariate Sample Selection Models via a Parameter-Expanded Monte Carlo EM Algorithm
Phillip Li
Department of Economics, Office of the Comptroller of the Currency, Washington, DC, USA
Email: Phillip.Li@occ.treas.gov
Copyright © 2014 by Phillip Li.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 6 September 2014; revised 5 October 2014; accepted 2 November 2014
ABSTRACT
This paper develops a parameter-expanded Monte Carlo EM (PX-MCEM) algorithm to perform maximum likelihood estimation in a multivariate sample selection model. In contrast to the cur- rent methods of estimation, the proposed algorithm does not directly depend on the observed-da- ta likelihood, the evaluation of which requires intractable multivariate integrations over normal densities. Moreover, the algorithm is simple to implement and involves only quantities that are easy to simulate or have closed form expressions.
Keywords:
Multivariate Sample Selection, Heckman Correction, Incidental Truncation, Expectation Maximization

1. Introduction
Sample selection models, pioneered in [1] - [3] , are indispensable to researchers who use observational data for statistical inference. Among the many variants of these types of models, there is a growing interest in multiva- riate sample selection models. These are used to model a system of two or more seemingly unrelated equations, where the outcome variable for each equation may be non-randomly missing or censored according to its own stochastic selection variable. Applications range from modeling systems of demand equations [4] [5] to house- hold vehicle usage [6] - [8] . A common specification is to assume a correlated multivariate normal distribution underlying both the outcomes of interest and the latent variables in the system.
There are two dominant approaches in the current literature to estimate these models. One approach is to use maximum likelihood (ML) estimation. However, as noted in the literature, a major hurdle in evaluating the like- lihood is that it requires computations of multivariate integrals over normal densities, which do not generally have closed form solutions. [9] discusses the ML estimation of these models and proposes to use the popular Geweke, Hajivassiliou, and Keane (GHK) algorithm to approximate these integrals in a simulated ML frame- work. While this strategy works reasonably well, the GHK algorithm can be difficult to implement. Another popular approach is to use two-step estimation (see [10] for a survey). In general, there is a tradeoff in the statistical properties and the computational simplicity for these estimators. If efficiency and consistency are of pri- mary concern, then ML estimation should be preferred over two-step estimation.
The objective of this paper is to develop a simple ML estimation algorithm for a commonly used multivariate sample selection model. In particular, this paper develops a parameter-expanded Monte Carlo expectation maximization (PX-MCEM) algorithm that differs from [9] in a few important ways. First, the PX-MCEM algo- rithm does not use the observed-data likelihood directly, so it avoids the aforementioned integrations. Second, the proposed iterative algorithm does not require the evaluations of gradients or Hessians, which become increa- singly difficult to evaluate with more parameters and equations. Third, the algorithm is straightforward to implement. It only depends on quantities that are either easy to simulate or have closed form expressions. This last point is especially appealing when estimating the covariance matrix parameter since there are non-standard restrictions imposed onto it for identification.
This paper is organized as follows. The multivariate sample selection model (MSSM) is formulated in Section 2. Section 3 begins with a brief overview of the EM algorithm for the MSSM and continues with the develop- ment of the PX-MCEM algorithm. Methods to obtain the standard errors are discussed. Section 4 offers some concluding remarks.
2. Multivariate Sample Selection Model
The MSSM is
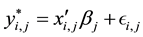 (1)
(1)
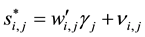 (2)
(2)
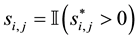 (3)
(3)
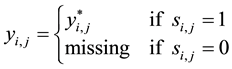 (4)
(4)
for observations , and equations
, and equations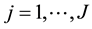 . In the previous expressions,
. In the previous expressions, 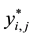 is the continuous outcome of interest for observation
is the continuous outcome of interest for observation 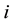 and equation
and equation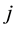 . Using similar indexing notation,
. Using similar indexing notation, 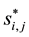 is the latent
is the latent
variable underlying the binary selection variable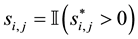 , where
, where 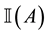 denotes an indicator function
denotes an indicator function
that equals 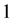 if event
if event 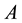 is true and 0 otherwise. Sample selection is incorporated by assuming that
is true and 0 otherwise. Sample selection is incorporated by assuming that 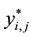 is
is
missing when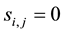 . Otherwise,
. Otherwise,  is observed and equal to
is observed and equal to . For later use, define
. For later use, define  and
and , where the prime symbol in
, where the prime symbol in ,
,  , and in the rest of this paper is used to denote matrix
, and in the rest of this paper is used to denote matrix
transpose.
Furthermore,  and
and  are column vectors of exogenous covariates, and
are column vectors of exogenous covariates, and  and
and  are conforming
are conforming
vectors of parameters. Define  and
and . For identification,
. For identification,  must
must
contain at least one exogenous covariate that does not overlap with  (refer to [11] for these exclusion res-
(refer to [11] for these exclusion res-
trictions). The unobserved errors  and
and  are jointly distributed as a
are jointly distributed as a
 -dimensional multivariate normal with a mean vector of zeros and an unknown covariance matrix of
-dimensional multivariate normal with a mean vector of zeros and an unknown covariance matrix of . Formally,
. Formally,  with
with
 . (5)
. (5)
The submatrix  is restricted to be in correlation form to identify the parameters corresponding to the latent variables [9] . The other elements of
is restricted to be in correlation form to identify the parameters corresponding to the latent variables [9] . The other elements of  are restricted such that the matrix is symmetric and positive definite.
are restricted such that the matrix is symmetric and positive definite.
The covariates and binary selection variables are always observed. Without loss of generality, assume that the outcomes for any observation  are only missing for the first
are only missing for the first  equations, where
equations, where . Define
. Define
 , and let
, and let  denote the observed data. The observed-data likelihood derived from (1) through (5) is denoted as
denote the observed data. The observed-data likelihood derived from (1) through (5) is denoted as . See [9] for an exact expression of this likelihood.
. See [9] for an exact expression of this likelihood.
3. Estimation
3.1. Overview of the EM Algorithm
The PX-MCEM algorithm is based on the EM algorithm of [12] . The basic idea behind the EM algorithm is to first augment  with a set of “missing data”
with a set of “missing data”  such that the observed-data likelihood is preserved when the missing data are integrated out of the complete-data likelihood. Formally, the missing data must satisfy
such that the observed-data likelihood is preserved when the missing data are integrated out of the complete-data likelihood. Formally, the missing data must satisfy
 , (6)
, (6)
where  is the complete-data likelihood to be defined later.
is the complete-data likelihood to be defined later.
The EM algorithm then proceeds iteratively between an expectation step (E-step) and a maximization step (M-step) as follows. In iteration  of the algorithm, compute in the E-step
of the algorithm, compute in the E-step
 , (7)
, (7)
where the expectation is taken with respect to the conditional predictive distribution for the missing data,
 , and in the M-step, find
, and in the M-step, find
 . (8)
. (8)
Denote the maximal values as ,
,  , and
, and , and continue on with the algorithm until convergence. The final maximal values are at least local maxima of the observed-data likelihood function.
, and continue on with the algorithm until convergence. The final maximal values are at least local maxima of the observed-data likelihood function.
For the MSSM,  consists of all the missing outcomes and latent variables. Specifically,
consists of all the missing outcomes and latent variables. Specifically,
 , where
, where . Furthermore, denote
. Furthermore, denote  as the vector
as the vector
of complete data,  as a block-diagonal matrix with the rows of covariates corresponding to the elements of
as a block-diagonal matrix with the rows of covariates corresponding to the elements of  on its block diagonals, and
on its block diagonals, and . The complete-data likelihood for the MSSM is given by
. The complete-data likelihood for the MSSM is given by
 (9)
(9)
with  which is a density function for a
which is a density function for a  -dimensional multivariate
-dimensional multivariate
normal with mean  and covariance
and covariance , and
, and
 . (10)
. (10)
Equation (10) is a degenerate density since conditioning on  in
in  determines
determines  from (3). Note that the observed-data likelihood from [9] is obtained when
from (3). Note that the observed-data likelihood from [9] is obtained when  is integrated out of (9), hence the condition in (6) holds.
is integrated out of (9), hence the condition in (6) holds.
3.2. PX-MCEM Algorithm
The standard EM algorithm using (7) and (8) is difficult to implement for the MSSM as the E-step and M-step are intractable. The PX-MCEM algorithm addresses this issue by modifying the E-step in two ways and leads to an M-step that can be evaluated with closed form quantities. Stated succinctly, the PX-MCEM algorithm is as follows.
1. Initialize ,
,  ,
,  , and the number of Gibbs sampling draws
, and the number of Gibbs sampling draws .
.
At iteration :
:
2. Draw  sets of missing data, denoted by
sets of missing data, denoted by , from
, from  using Gibbs sampling.
using Gibbs sampling.
3. PX-MC E-step: Estimate  as
as
 . (11)
. (11)
4. PX-MC M-step: Maximize  with iterative generalized least squares (IGLS) to
with iterative generalized least squares (IGLS) to
obtain the maximizing parameters ,
,  , and
, and .
.
5. Reduction step: Apply reduction functions to ,
,  , and
, and  to obtain
to obtain ,
,  , and
, and .
.
6. Repeat Steps 2 through 5 until convergence. The converged values are the ML estimates ,
,  , and
, and .
.
Each step is described in more detail in the subsequent sections.
3.2.1. PX-MC E-Step
Following [13] , the first modification is to expand the parameter space of the complete-data likelihood function from  to
to . The expanded parameters play similar roles as the original parameters, however
. The expanded parameters play similar roles as the original parameters, however  is expanded into a standard covariance matrix without the correlation restrictions. The parameter-expanded complete-data likelihood function is
is expanded into a standard covariance matrix without the correlation restrictions. The parameter-expanded complete-data likelihood function is
 (12)
(12)
with , where
, where , and
, and  and
and 
are defined analogously to  and
and . The advantage of using (12) instead of (9) is that
. The advantage of using (12) instead of (9) is that  is easier to work with in the PX-MC M-step.
is easier to work with in the PX-MC M-step.
Second, instead of computing  analytically, it is approximated as (11) with Monte Carlo methods and Gibbs sampling. To draw from
analytically, it is approximated as (11) with Monte Carlo methods and Gibbs sampling. To draw from  , simply draw
, simply draw  and
and  from the conditional distribution
from the conditional distribution  for
for . From (9), we have that
. From (9), we have that
 , (13)
, (13)
where . For the missing outcomes, it is easy to see from (13) that
. For the missing outcomes, it is easy to see from (13) that
 (14)
(14)
for , where
, where  is equivalent to
is equivalent to  with
with  removed, and
removed, and  and
and  are respectively the conditional mean and variance of
are respectively the conditional mean and variance of  given all other elements in
given all other elements in  from
from
 .
.
Similarly, for the latent variables,
 (15)
(15)
for , where
, where  denotes a univariate normal distribution with mean
denotes a univariate normal distribution with mean  and variance
and variance  truncated to the region
truncated to the region . In (15),
. In (15),  is
is  with
with  removed,
removed,  is the interval
is the interval  if
if  and
and  otherwise, and
otherwise, and  and
and  are respectively the conditional mean and variance of
are respectively the conditional mean and variance of  given all other elements of
given all other elements of  from
from .
.
The Gibbs sampler recursively samples from the full conditional distributions in (14) and (15) in the usual way. After a sufficient burn-in period, the last  draws are used in (11).
draws are used in (11).
3.2.2. PX-MC M-Step and Reduction Step
By recognizing that (11) is proportional to the log-likelihood function of a seemingly unrelated regression model with  observations and
observations and  equations, the maximization can be performed with IGLS. IGLS utilizes the quantities
equations, the maximization can be performed with IGLS. IGLS utilizes the quantities
 (16)
(16)
and
 , (17)
, (17)
where  is equivalent to
is equivalent to  with
with  and
and . First evaluate (16) with
. First evaluate (16) with  removed, which amounts to estimating
removed, which amounts to estimating  equation by equation, and then evaluate (17) based on
equation by equation, and then evaluate (17) based on . Proceed by iterating (16)
. Proceed by iterating (16)
and (17) recursively until convergence. Denote the converged values as ,
,  , and
, and .
.
In the reduction step, set ,
, 
 , and
, and , where
, where  is a
is a  diagonal matrix with the first
diagonal matrix with the first  diagonals equal to 1 and the re-
diagonals equal to 1 and the re-
maining  diagonals equal to the square root of the last
diagonals equal to the square root of the last  diagonals of
diagonals of . The previous transformations are referred to as the reduction functions, and they are needed because (12) is used instead of (9) in the algorithm [13] .
. The previous transformations are referred to as the reduction functions, and they are needed because (12) is used instead of (9) in the algorithm [13] .
3.3. Standard Errors
The observed information matrix is
 , (18)
, (18)
where , and
, and  is a column vector denoting the unique elements in
is a column vector denoting the unique elements in . Evaluate (18) at the ML estimates, and take the expectation and variance with respect to
. Evaluate (18) at the ML estimates, and take the expectation and variance with respect to . These moments are
. These moments are
estimated by taking additional draws from the Gibbs sampler and constructing their Monte Carlo analogs. The standard errors are the square roots of the diagonals of the inverse estimated quantity in (18).
4. Concluding Remarks
A new and simple ML estimation algorithm is developed for multivariate sample selection models. Roughly speaking, the implementation of this algorithm only involves iteratively drawing sets of missing data from well- known distributions and using IGLS on the complete data, both of which are inexpensive to perform. By using parameter expansion and Monte Carlo methods, the algorithm only depends on quantities with closed form expressions, even when estimating the covariance matrix parameter with correlation restrictions. This algorithm is readily extendable to other types of selection models, including extensions to various types of outcome and selection variables with an underlying normal structure, and modifications to time-series or panel data.
Acknowledgements
I would like to thank the referee, Alicia Lloro, Andrew Chang, Jonathan Cook, and Sibel Sirakaya for their helpful comments.
References
- Heckman, J. (1974) Shadow Prices, Market Wages, and Labor Supply. Econometrica, 42, 679-694. http://dx.doi.org/10.2307/1913937
- Heckman, J. (1976) The Common Structure of Statistical Models of Truncation, Sample Selection and Limited Dependent Variables and a Simple Estimator for Such Models. Annals of Economic and Social Measurement, 5, 475-492.
- Heckman, J. (1979) Sample Selection Bias as a Specification Error. Econometrica, 47, 153-161. http://dx.doi.org/10.2307/1912352
- Su, S.J. and Yen, S.T. (2000) A Censored System of Cigarette and Alcohol Consumption. Applied Economics, 32, 729-737. http://dx.doi.org/10.1080/000368400322354
- Yen, S.T., Kan, K. and Su, S.J. (2002) Household Demand for Fats and Oils: Two-Step Estimation of a Censored Demand System. Applied Economics, 34, 1799-1806. http://dx.doi.org/10.1080/00036840210125008
- Hao, A.F. (2008) A Discrete-Continuous Model of Households’ Vehicle Choice and Usage, with an Application to the Effects of Residential Density. Transportation Research Part B: Methodological, 42, 736-758. http://dx.doi.org/10.1016/j.trb.2008.01.004
- Li, P. (2011) Estimation of Sample Selection Models with Two Selection Mechanisms. Computational Statistics & Data Analysis, 55, 1099-1108. http://dx.doi.org/10.1016/j.csda.2010.09.006
- Li, P. and Rahman, M.A. (2011) Bayesian Analysis of Multivariate Sample Selection Models Using Gaussian Copulas. Advances in Econometrics, 27, 269-288. http://dx.doi.org/10.1108/S0731-9053(2011)000027A013
- Yen, S.T. (2005) A Multivariate Sample-Selection Model: Estimating Cigarette and Alcohol Demands with Zero Observations. American Journal of Agricultural Economics, 87, 453-466. http://dx.doi.org/10.1111/j.1467-8276.2005.00734.x
- Tauchmann, H. (2010) Consistency of Heckman-Type Two-Step Estimators for the Multivariate Sample-Selection Model. Applied Economics, 42, 3895-3902. http://dx.doi.org/10.1080/00036840802360179
- Puhani, P.A. (2000) The Heckman Correction for Sample Selection and Its Critique. Journal of Economic Surveys, 14, 53-68. http://dx.doi.org/10.1111/1467-6419.00104
- Dempster, A.P., Laird, N.M. and Rubin, D.B. (1977) Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, 39, 1-38. http://dx.doi.org/10.2307/2984875
- Liu, C., Rubin, D.B. and Wu, Y.N. (1998) Parameter Expansion to Accelerate EM: The PX-EM Algorithm. Biometrika, 85, 755-770. http://dx.doi.org/10.1093/biomet/85.4.755