Y. Ren, P. N. Suganthan
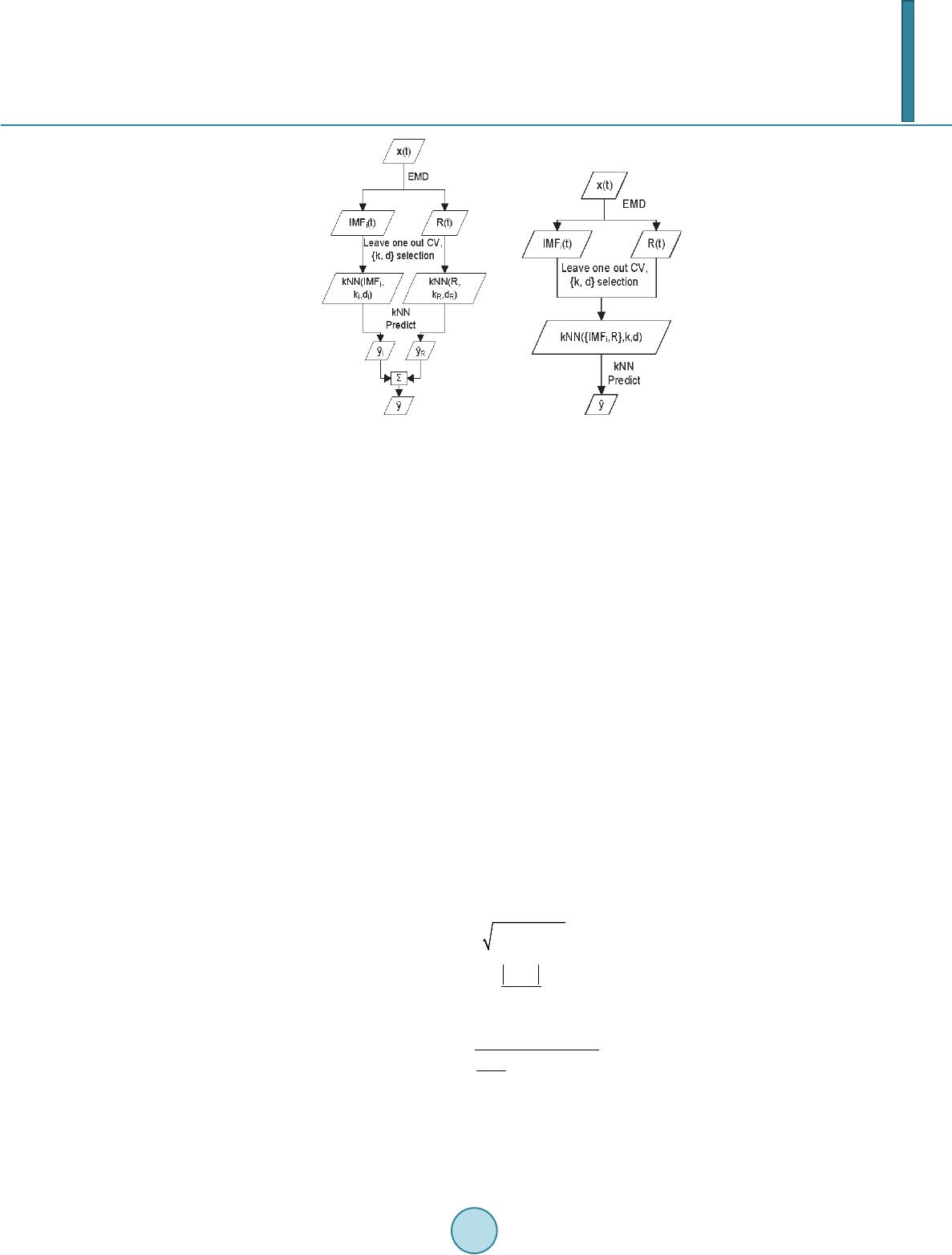
prediction. The second configuration has combined all IMFs and residue together to form a feature vector set for
computing the distance matrix and the prediction has followed the conventional kNN model. The two configura-
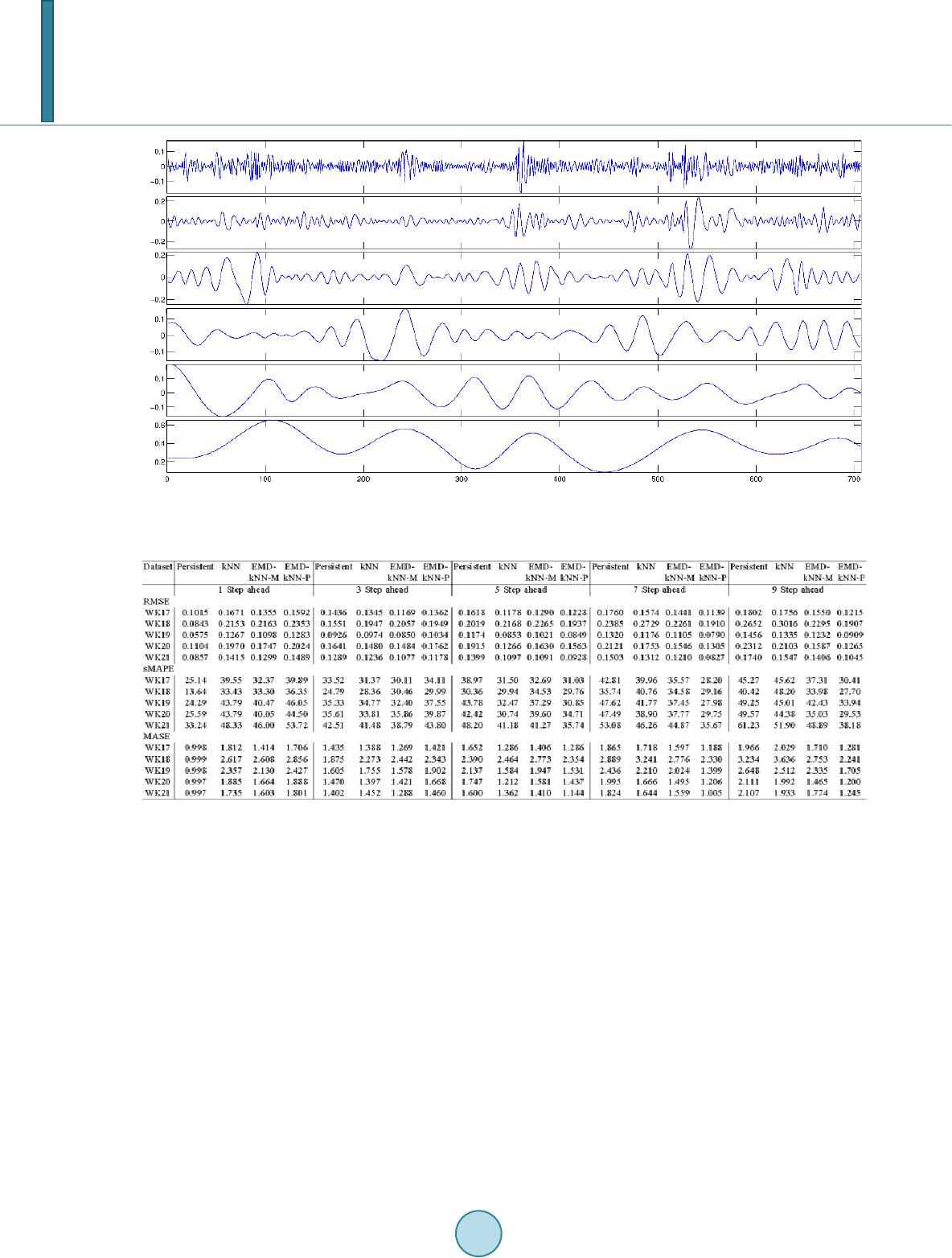
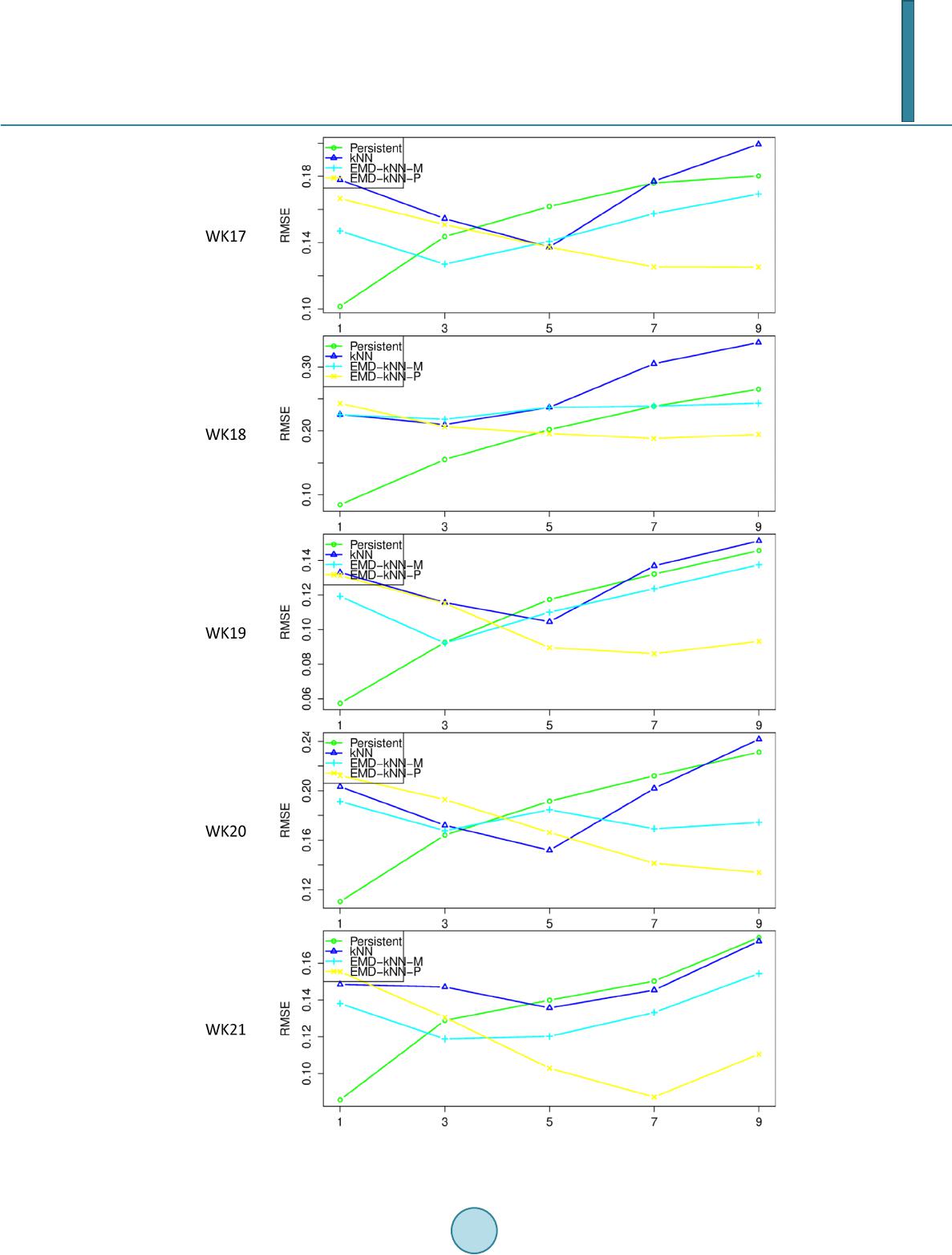
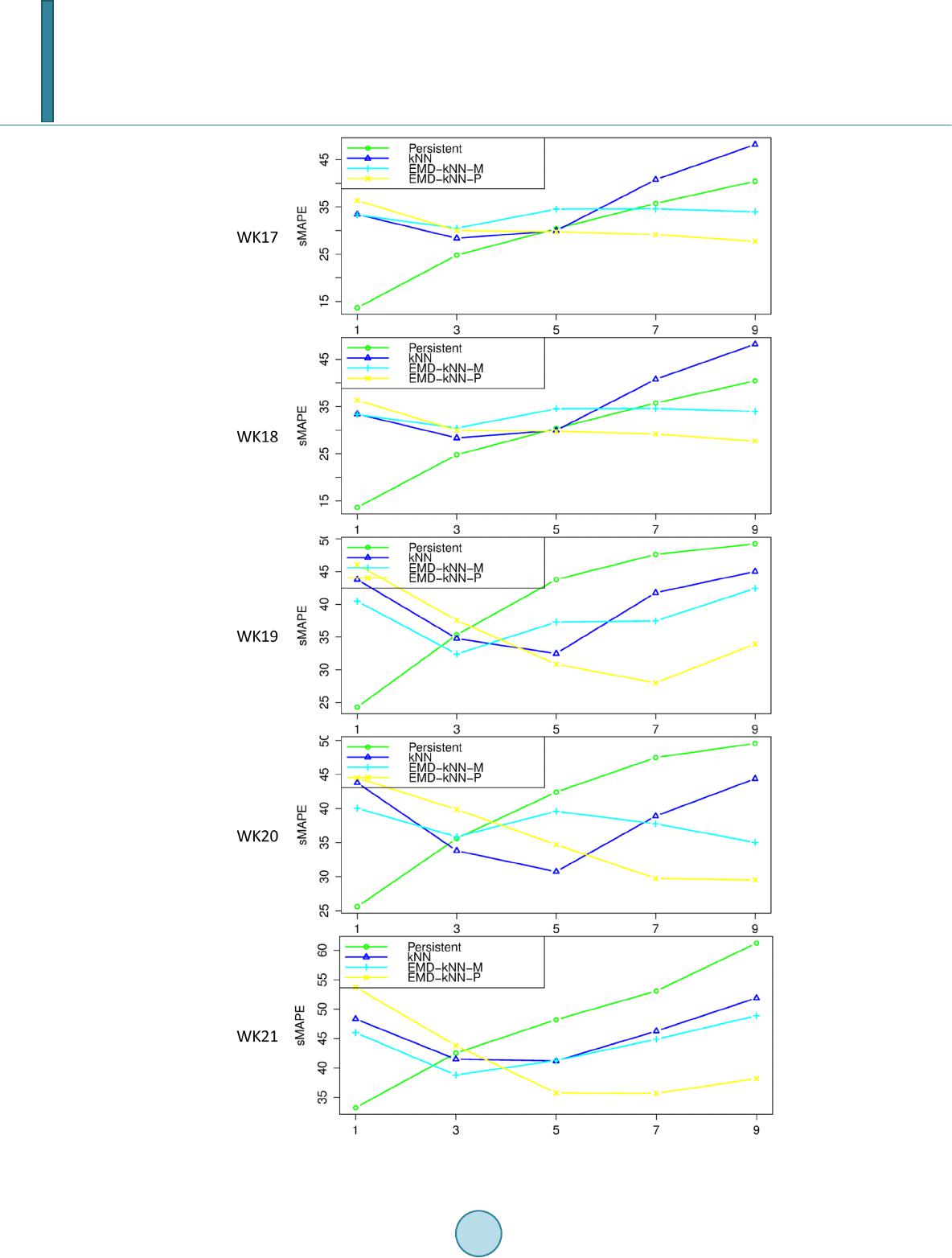
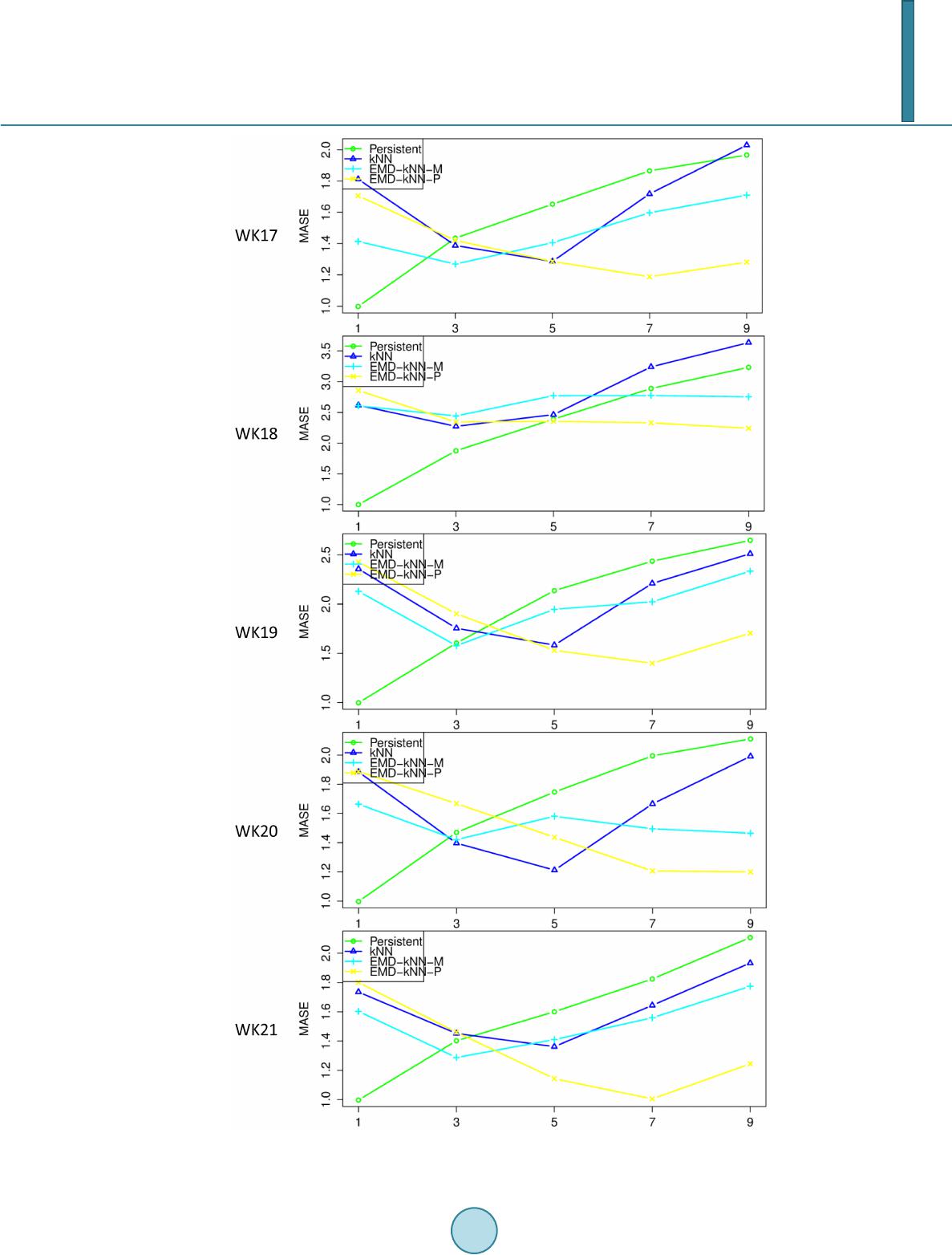
tions have been compared with the persistent model and the kNN model with a wind speed TS recorded in Sin-
gapore. The results have shown that the two configurations outperformed the persistent model and kNN for
longer term forecasting. The second configuration has outperformed the first configuration for 1 and 3 step-
ahead forecasting.
For future work, a possible improvement is on the feature vector selection. Some statistical methods can be
applied for the dimension selection instead of user-defined range followed by grid search based on cross valida-
tion performances. Another possible future work is to apply different weight scheme w to the distance matrix
creation stage. Instead of a uniform w, a linear or exponential decayed w can be used to weigh the distance. This
weighted distance may improve the selection of nearest neighbors.
Acknowledgements
The author Ren Ye would like to thank National Research Foundation (NRF) for providing the Clean Energy
Program (CEPO) research scholarship.
References
[1] Wu, Y.K. and Hong, J.S. (2007) A Literature Review of Wind Forecasting Technology in the World. IEEE Lausanne
Power Tech, Lausanne, 1-5 July 2007, 504-509.
[2] Hill, D.C. , McMillan, D., Bel l, K.R.W. and Infield, D. (2012) Application of Auto-Regressive Models to U.K. Wind
Speed Data for Power System Impact Studies. IEEE Transactions on Sustainable Energy, 3, 134-141.
http://dx.doi.org/10.1109/TSTE.2011.2163324
[3] Damousis, I., Alexiadis, M., Theocharis, J. and Dokopoulos P., (2004) A Fuzzy Model for Wind Speed Prediction and
Power Generation in Wind Parks Using Spatial Correlation. IEEE Transactions on Energy Conversion, 19, 352-361.
http://dx.doi.org/10.1109/TEC.2003.821865
[4] Salcedo-Sanz, S., Ortiz -Garcia, E.G., Perez-Bellido, A.M., Portilla-Figueras, A. andPrieto, L. (2011) Short Term Wind
Speed Prediction Based on Evolutionary Support Vector Regression Algorithms. Expert Systems with Applications, 38,
4052-4057. http://dx.doi.org/10.1016/j.eswa.2010.09.067
[5] Shi, J., Guo, J. and Zheng, S. (2012) Evaluation of Hybrid Forecasting Approaches for Wind Speed and Power Genera-
tion Time Series. Renewable and Sustainable Energy Reviews, 16, 3471-3480.
http://dx.doi.org/10.1016/j.rser.2012.02.044
[6] Wang, Y., Niu, D. and Ma, X. (2010) Optimizing of SVM with Hybrid PSO and Genetic Algorithm in Power Load
Forecasting. Journal of Networks, 5, 1192-1200. http://dx.doi.org/10.4304/jnw.5.10.1192-1200
[7] Zeng, J. and Qiao, W. (2012) Short-Term Wind Power Prediction Using a Wavelet Support Vector Machine. IEEE
Transactions on Sustainable Energy, 3, 255-264. http://dx.doi.org/10.1109/TSTE.2011.2180029
[8] Guo, Z., Zhao, W., Lu, H. and Wa ng, J. (2012) Multi-Step Forecasting for Wind Speed Using a Modified EMD-Based
Artificial Neural Network Model. Renewable Energy, Elsevier, 37, 241-249.
http://dx.doi.org/10.1016/j.renene.2011.06.023
[9] Catalao, J., Pousinho, H. and Mendes, V. (2011) Hybrid Wavelet-PSO-ANFIS Approach for Short-Term Wind Power
Forecasting in Portugal. IEEE Transactions on Sustainable Energy, 2, 50-59.
[10] Huang, N., Shen, Z., Long, S., Wu, M., Shih, H. , Zheng, Q., Yen, N., Tung, C. and Liu, H. (1998) The Empirical Mode
Decomposition and Hilbert Spectrum for Nonlinear and Nonstationary Time Series Analysis. Proceedings of the Royal
Society London A, 454, 903-995. http://dx.doi.org/10.1098/rspa.1998.0193
[11] Ye, L. and Liu, P. (2011) Combined Model Based on EMD-SVM for Short-Term Wind Power Prediction. Proceedings
of the CSEE, 31, 102-108.
[12] Sun, C., Yuan, Y. andLi, Q. (2012) A New Method for Wind Speed Forecasting Based on Empirical Mode Decompo-
sition and Improved Persistence Approach. Conference on Power & Energy (IPEC2012), Ho ChiMinh City, 659-664.
[13] Hu, J., Wang, J. and Zeng, G. (2013) A Hybrid Forecasting Approach Applied to Wind Speed Time Series. Renewable
Energy, Elsevier, 60, 185-194. http://dx.doi.org/10.1016/j.renene.2013.05.012
[14] Lin, A.J. , Shang, P.J. , Fen g, G. C. and Zhong, B. (2012) Application of Empirical Mode Decomposition Combined with
K-Nearest Neighbors Approach in Financial Time Series Forecas ting. Fluctuation and Noise Letters, 11.
http://dx.doi.org/10.1142/S0219477512500186