M. G. ROSA ET AL.
OPEN ACCESS SN
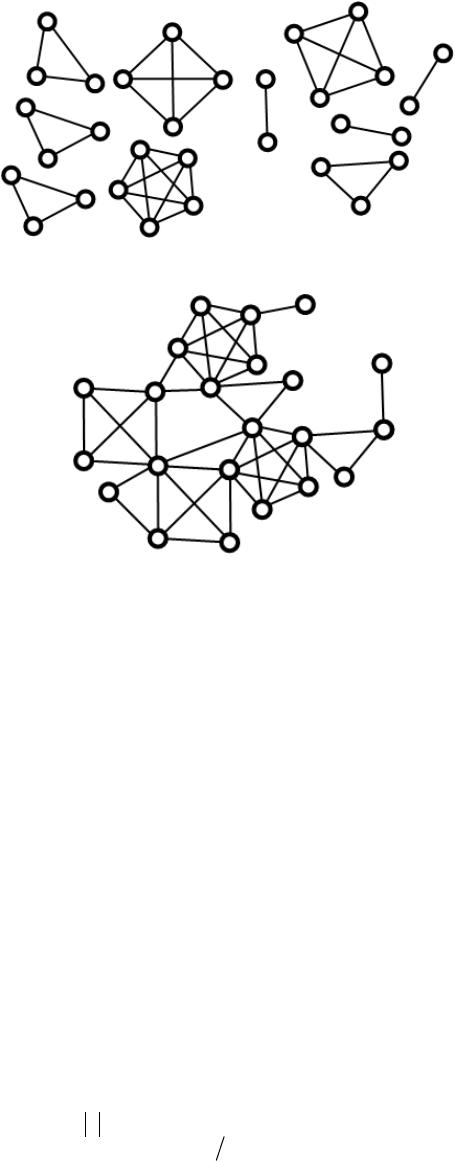
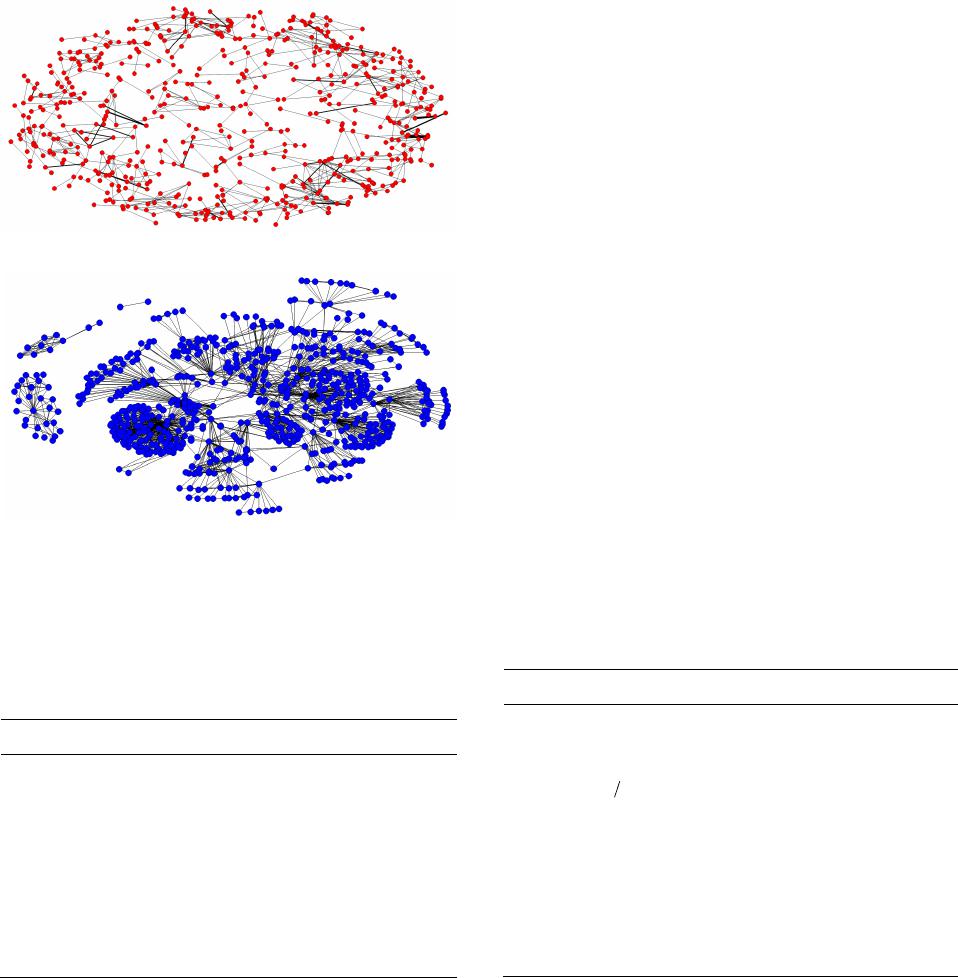
configuration of disconnected cliques. The results in
Table 2 show that the GP Network displays a higher
variance of density index score higher than the ME Net-
work. The theoretical maximum value for the variance of
density occur s when the network becomes a single clique,
i.e., all of the vertices are mutually connected. For the
ME Network, this maximum value is approximately
2200, and thus the value found herein (7.8784) corres-
ponds to only 0.4% of the maximum. In the case of the
GP Network, the maximum variance of the density is
1223, and the measured value (15.4440) is 1.3% of the
maximum. Comparatively, it can be stated that the GP
Network is more than threefold “densified” compared to
the ME Network. The variance of density index reflects
the coalescence of the authors that published alone but
also as coauthors (reduction of vertices without a reduc-
tion in the number of edges) in relation to the coales-
cence of pairs that published as coauthors (simultaneous
reduction of vertices and edges). To more precisely de-
termine what type of situation predominates in the net-
work, the superposition of edges and the vertex reduction
factor can be used.
The superposition of edges determines the proportion
of coauthor pairs in common; i.e., it is an index that
measures relationships, represented by the edges in the
network. The superposition of approximately 10% in the
ME Network indicates that few pairs of authors pub-
lished together more than once, unlike the GP Network,
where 52% of the pairs have more than one publication
together. This index, therefore, shows that there is more
scientific production by pairs of authors in the GP Net-
work than in the ME Network.
The vertex reduction factor, in turn, is directly related
to the author/vertex ratio in Ta bl e 1 . This index indicates
the percentage of authors with more than one publication.
The values obtained for the ME and GP networks indi-
cate that the researchers in the GP network display higher
individual productivity.
The values of the component reduction factor for the
two networks do not differ. Although the ME Network
has 160 components compared to only 08 for the GP
Network , the percentage difference is approximately
12%. However, almost all of the coauthorship groups
shared at least one vertex in common (link) in the GP
Network (99.4%), while a value of 87.4% was observed
in the ME Network.
6. Final Considerations
The clique approach in coauthorship networks allows the
social data to be analyzed in a way that is well suited for
the network topological structure. Network analysis us-
ing cohesion indices already allows new interpretations.
For example, considering the index that measures edge
superposition together with the vertex reduction factor
allowing us to clarify h ow the juxtaposition an d superpo-
sition processes create the network. Thus, we observed
that superposition predominated in the GP Network
compared to the ME Network. This effect also occurred
with the vertex reduction factor, but to a lesser extent.
These aspects result in a greater “densification” of the
GP Network, mostly due to the large number of pairs of
authors who have written more than one study together.
These results are consistent with the fact that the GP
Network comprises researchers connected through the
same research institution, while the ME Network in-
cludes researchers who may have stronger ties within
their own groups, but this collaboration is not shown
through their publication in jou rn a ls of the field .
The initial research us ing cohes ion indices showed that
other indices could potentially be added, and the dynam-
ics of network growth could be evaluated. Another aspect
that we emphasize is the applicability of the clique ap-
proach to other social networks with a similar structure,
such as actor-movie networks.
Finally, it is important to comment that th is work is an
ongoing research and initially it was published in the
proceedings of the 1st Brazilian Workshop on Social
Network Analysis and Mi ning [13].
REFERENCES
[1] J. L. Gross and J. Yellen, “Graph Theory and Its Applica-
tions. Discret Mathematics and Its Applications,” CRC
Press, Boca Raton, 2003.
[2] J. S. Katz and B. R. Martin, “What Is Research Collabo-
ration?” Research Policy, Vol. 26, N o . 1 , 1997, pp. 1-18.
http://dx.doi.org/10.1016/S0048-7333(96)00917-1
[3] S. A. d. S. Vanz and I. R. C. Stump, “Scientific Collabo-
ration: A Theoretical-Conceptual Review,” Perspectivas
em Ciência da Informação, Vol. 15, No. 2, 2010, pp. 42-
55. http://dx.doi.org/10.1590/S1413-99362010000200004
[4] M. E. J. Newman, “The Structure of Scientific Collabora-
tion Networks,” Proceedings of the National Academy of
Sciences, Vol. 98, No. 2, 2001, pp. 404-409.
http://dx.doi.org/10.1073/pnas.98.2.404
[5] M. E. J. Newman, “Scientific Collaboration Networks. I.
Network Construction and Fundamental Results,” Physi-
cal Review E, Vol. 64, No. 1, 2001, Article ID: 016131.
[6] M. E. J. Newman, “Scientific Collaboration Networks. II.
Shortest Paths, Weighted Networks, and Cen trality,” Phy-
sical Review E , Vol. 64, No. 1, 2001, Article I D: 016132.
[7] M. F. Maia and S. E. Caregnato, “Co-Authorship as an
Indicator of Scientific Collaboration Network,” Perspec-
tivas em Ciência da Informação, Vol. 13, No. 2, 2008, pp.
18-31.
[8] C. M. Mello, J. M. Crubellate and L. Rossoni, “Coauthor
Networks between Brazilian Graduate Administration
Program Faculty (Strictu Sensu): Structural and Dynamic
Aspects of Relationships,” Perspectivas em Ciência da
Informação, Vol. 15, No. 2, 2009, pp. 42-55.