 Journal of Computer and Communications, 2014, 2, 70-77 Published Online January 2014 (http://www.scirp.org/journal/jcc) http://dx.doi.org/10.4236/jcc.2014.22013 OPEN ACCESS JCC Low Resolution Face Recognition in Surveillance Systems Xiang Xu, Wanquan Liu, Ling Li Department of Computing, Curtin University, Perth, Australia. Email: xiang.xu1@postgrad.curtin.edu.au Received October 2013 ABSTRACT In surveillance systems, the captured facial images are often very small and different from the low-resolution images down-sampled from high-resolution facial images. They generally lead to low performance in face recog- nition. In this paper, we study specific scenarios of face recognition with surveillance cameras. Three important factors that influence face recognition performance are investigated: type of cameras, distance between the ob- ject and camera, and the resolution of the captured face images. Each factor is numerically investigated and analyzed in this paper. Based on these observations, a new approach is proposed for face recognition in real sur- veillance environment. For a raw video sequence captured by a surveillance camera, image pre-processing tech- niques are employed to remove the illumination variations for the enhancement of image quality. The face im- ages are further improved through a novel face image super-resolution method. The proposed approach is proven to significantly improve the performance of face recognition as demonstrated by experiments. KEYWORDS Face Recognition; Very Low Resolution; Surveillance Camera 1. Introduction Research in face recognition has been carried out for more than two decades, for its potentially wide applica- tions in commercial and law enforcement fields. Popular face recognition approaches can achieve very high rec- ognition performance in publicly released databases [1-6], where the resolution of the captured facial images is usually higher than 100 × 100. Some can even achieve similar high performance in a very low resolution [6], where the resolution of cropped faces is less than 10 × 10. However, most of these works have been conducted on databases where face images are captured in controlled environments with high definition cameras. The so-called “low-resolution” face images are derived from high-res- olution faces through down-sampling and/or smoothing methods. When face images are captured directly in a “real” low resolution, the high performance of current face recognition approaches is yet to be proven. Recently, face recognition research in real-life surveil- lance has become very popular. For high data transmission speed and easy data storage, surveillance cameras generally produce images in low resolution, and face images captured directly by surveillance cameras are usually very small. Besides, images taken by surveillance cameras are gener- ally with noises and corruptions, due to the uncontrolled circumstances and distances. [7] proposed a super-resolu- tion approach to increase the recognition performance for very low-resolution face images. They employ a minimum mean square error estimator to learn the relationship be- tween low and high resolution training pairs. A further dis- criminative constraint is added to the learning approach using the class label information. [8] proposed a matching algorithm through using Multidimensional Scaling (MDS). In their approach both the low and high resolution training pairs are projected into a kernel space. Transformation rela- tionship is then learned in the kernel space through iterative majorization algorithm, which is used to match the low- resolution test faces to the h igh-resolution gallery faces. Similarly, [9] proposed the Coupled Kernel Embedding approach, where they map the low and high resolution face images onto different kernel spaces and then transform them to a learned subspace for recognition. Only a small portion of existing research is specifically for real surveillance scenarios, where the captured face images are very different compared with images captured under controlled circumstances. Most of the existing re- searches are based on the down-sampled low-resolution face images captured by high definition cameras under controlled environments. Even the works on surveillance cameras [7-10] on the claimed low-resolution (lower than 32 × 32) surveillance face images are in fact on images  Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC down-sampled from the original images captured in a res- olution of 64 × 64. Face recognition based on true low- resolution (lower than 32 × 32) face images in uncontrolled surveillance scenarios remains an issue to be explored. In this paper, we systematically analyze the key issues for face recognition in surveillance scenario, where the captured face images are usually with uncontrolled illumi- nation, motion, poses and are generally taken in a far dis- tance. Moreover, the off-the-shelf commercial surveillance cameras come with low-quality sensors and can only cap- ture images in low resolutions. Through our analysis, we found out that three factors which impact significantly on face recognition perfor- mances, including the distance between the camera and the human subject, types of cameras including sensor sizes and quality, and the resolutions of captured face images. Three experiments are designed to show the impact of these fac- tors. We first demonstrate that the recognition perfor- mances on the low-resolution face images directly captured in real surveillance circumstances are much lower than those on the down-sampled low-resolution images from high-resolution images. It clearly indicates that the down- sampled face images are not able to represent the true low-resolution images. By changing the types of cameras and the values of distances and resolutions, we demonstrate that face image resolution plays a key role in face recogni- tion although the types of cameras and capturing distances are important factors. Based on these observations, we propose an approach for face recognition in real surveillance environment. In this paper we focus on the indoor surveillance environment, e.g., in a corridor where people’s motions are generally walking in a single direction in a relatively slow and steady pace. Our focus is hence on face recognition on surveillance captured face images with low resolutions, varied illumina- tion conditions, small pose variation, and slow motions. Due to the very low resolution of the captured face images, many face features are lost. Image pre-processing ideas are employed to remove illumination variations as much as possible. In order to accumulate more features, we fuse a video sequence into one frame in the frequency domain. Curvelet features are adopted in the fusion process. The image is further improved through image super-resolution methods in order to increase the image resolution. Experi- mental results demonstrate that the proposed approach is able to improve the face recognition performance. 2. Face Image Pre-Processing 2.1. Histogram Equalization for Illumination In real surveillance scenarios, directly captured low res- olution images are different from those which are cap- tured in controlled circumstances. Various factors influ- ence the performance of face recognition, such as motion blur, and illumination and noises in images. In this paper we will focus on the surveillance of an ordinary indoor environment, where a normal range of illumination con- dition and distortion are considered without motion blur. With a surveillance camera, video pictures are usually captured in low resolutions. The generic commercial surveillance cameras record pictures with resolutions varying from 400 to 800 pixels. For example the “SWANN DVR4-1300” commercial surveillance system used in CurtinFaces database [11] captures video se- quences with the resolution of 576 × 704. While working in the indoor circumstance, the camera system captures very small faces in a distance. In the “SWANN DVR4- 1300” commercial surveillance system, face resolutions are around 32 × 32 in the distance of approximately 2.5 meters, 16 × 16 in the distance of 5 meters and 8×8 in the distance of 10 meters respectively. In an indoor corridor with no obvious side lighting, the face images captured demonstrate quite obvious illumi- nation effects from the natural overhead lightings during a walking motion. A histogram equalization approach is adopted here for reducing illumination variations. There are generally two types of histogram equalization for image pre-processing [12]. One is the rank normalization where each pixel of the image is ranked and mapped to a new image between the values of 0 and 255. Another one is to pre-define a distribution of an image's pixels and re-map the image into the pre-defined model. Due to the similar feature on most part of face images, we adopt the second method in our approach. In detail, for a 32 × 32 grey scale face image x, the rank for each pixel is normalized to be ri,j (ri,j [1,1024]) and the number of pixels is 1024 and the grey scale im- age level is 256. A general mapping function for pixel xi,j is defined as: , , , 1024 0.5() () 1024 ij t ij ij x r pfx dxFx =−∞ −+ == = ∫ (1) where ti,j is the rank of pixel xi,j in the re-mapped space with distribution function f(x) and F(x) is the cumulative distribution function (CDF) for a given distribution f(x). In order to remove the illumination variation, we as- sume that the intensity distribution of face images mat- ches the standard normal distribution. The re-mapped face images can be derived from the inverse cumulative distribution function. For the pixel xi,j, the re-mapped rank ti,j is derived from: (2) where F−1 is the inverse cumulative distribution func- tion and 22 () /2 1 () ()2 tt x x Fxfx dxedx µσ σπ −− −∞ =−∞ = = ∫∫  Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC The grey scale face image after histogram equalization is derived through adjusting the pixel rank ti,jto the inter- val [0,255]. 2.2. Fusion of Video Sequence Surveillance cameras usually capture whatever happens in a fixed environment into a video sequence. A set of images belong to one person with minor differences in poses and expressions can be extracted from the video. Illumination differences could be minimized after histo- gram equalization as described in the last section. In or- der to enhance the spectral features for face recognition, image fusion method [13] is adopted here. Generally there are two ways for image fusion. One is fusion in the spatial domain and the other is fusion in the frequency domain. In this paper, we utilize the Curvelet coefficients to represent the face features [14,15]. For face recognition, Curvelet features have been proved to perform excellently in face feature represent- tation [16]. The proposed Curvelet based image fusion is represented in Figure 1 which indicates that several vi- deo frames can be fused into one image in order to derive rich features. It is expected to generate a face image which provides more features for face recognition. From [16] we can see that fine coefficients represent the char- acter of a human better. For a sequence of facial images, we first transfer them into Curvelet Coefficients. The smallest low-frequency components which are repre- sented by the coarse Curvelet coefficients and the biggest high-frequency components which are represented by the fine Curvelet coefficients are therefore kept in the pro- posed approach. For the image sequence I1, I2,…, In, their coefficients are represented as Ci{j}{l}(k1, k2) (I = 1, 2, …, n). The components of the first scale where j=1 represent the low-frequency parts of the face image and the compo- nents of other scales represent the high frequency parts. The minimum components between each Ci{j} {l} (k1, k2) (i = 1, 2, …, n) and the maximum components be- tween each Ci{j}{l} (k1, k2) (i = 1, 2, …, n; j ≠ 1) are kept for the fused Curvet coefficients C{j}{l}(k1, k2). After inverse Curvelet transformation, the fused face image can be derived as shown in Figure 1. 3. Super-Resolution Based Face Recognition In real surveillance video sequences, face images taken beyond certain distance always come with noticeable noises and corruptions. When the captured face images are below 32 × 32, corruptions are obvious. Directly ap- plying existing face recognition approaches on them generally will not achieve acceptable recognition per- formances. In order to enhance the face features, we propose a super-resolution based face recognition algo- rithm. Inspired by [17], we make use of the sparsity of signal representation to train low-resolution image patches pl through a dictionary Dl and transfer the trained relation- ship onto the corresponding high-resolution dictionary Dh to reconstruct the high-resolution patch ph. This dic- tionary is trained in the FRGC [18] face database inde- pendently with both the high-resolution and low-resolu- tion pairs. The high-resolution patch ph is reconstructed through adopting the same coefficients in the low-reso- lution training relationship, where a low-resolution patch pl is represented by a low-resolution dictionary Dl with the relationship of α. A high-resolution face image can be derived by combining all the high-resolution patches together. The low-resolution sparse representation is formulated as: (3) where α is the sparse representation coefficient s inl1 norm. This spar se representation relationsh ip is mapped to the high dimension space. The h igh-resolution imag e patch is derived from: (4) After combing the two high-resolution patches, the hallucinated face i ma g e y c an be der ived. Meanwhile, we adopt the idea of [19] to enhance the same low-resolution face image into a high-resolution one. This process utilizes the Eigen -subspace features of human faces, which has been pr oved to have a good and stable performance in face feature representation [2]. For a s et of training data (FRGC [18] in this paper), the cova- riance of zero mean face images L is: C = L × LT. A zero mean low-resolution face image x can be represented by the Eigenvectors Eas: (5) where w is the weight of Eigen faces and m is the mean face. Equation (5) can be rewritten as: (6 ) where V is the Eigenvectors of covariance matrix and . The hig-resolution face y can be derived from: (7) where H is the corre sponding h igh-resolution training data of L and mh is the high-resolution mea n face. After obtaining two high-resolution faces from the same low-resolution one, a decision is made for each pixel based on the low-resolution face image. For exam- 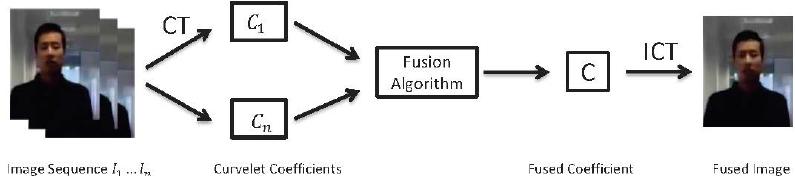 Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC Figure 1. Image Fusion Process Diagram. ple, for a 16 × 16 face image, we first enhance it into two high-resolution images using the methods described above. Both th es e high-resolution face images are then combined into one i mag e w ith a pixel by pixel deci- sion-making. For each pixel xi,j in the low-resolution im- age, the correspond ing pixels in high-resolution is a 4 × 4 block. For a 16 × 16 low-resolution face, the reare 256 blocks in the high-resolution image. A ssume th e blocks from the two different enhanced face images are b1and b2 respectively. In order to decide which block is to be kept, we down-sample both the 4 × 4 blocks into one pixel and keep the one which produces the pixel value closer to the value of the original low-resolution pixel xi, j . The final enhanced block image is: , 12 arg min() . .(1) ij Down bx stb bb λλ − =×+− × ( 8) where λ equals to 0 or 1. After combing the 256 blocks together, the final en- hanced face image is obtained which will be used for recognition. 4. Experiments and Results In this paper, the experiments are performed on four da- tabases: FRGC [18], AR [20], ScFace [10] and Curtin Faces [11]. FRGC and ARdatabases are captured with high definition cameras. Low-resolution images are down-sampled and smoothed from high-resolution ones. ScFace and Curtin Faces data bases contain face images from both high definition cameras and surveillance cam- eras. All the face images are cropped and aligned before being used. The high definition cameras used inAR, ScFace and Curtin Faces databases are SONY3CCDs, CanonEOS10D and PanasonicLumix respectively. The surveillance cameras used in ScFace database are: Bosch LTC0495/51, ShannyWTC-8342, ShannyMTC-L1438, JSJCC-915D and VFD400-12B. The surveillance camera used in Curtin Faces database is SWANNDVR4-1300 . In real world, the reare generally two reason s for a captured face image to be very small. One is that the dis- tance between the camera and the person is too lar ge and the other is that the camera sensor is limited. Although the focal length of a camera can always be changed, when the distance between a camera and an object is too far away, the captured images become very small. For simplicity, we assume that all cameras in our experiments have fixed fo cal length. In our experiments, the resolutions of face images are the originally captured sizes unless specified otherwise. None of the images are down-sampled from high resolu- tion images. For simplicity, we divide face image resolu- tions in to f iv e levels: 128 × 128, 64 × 64, 32 × 32, 16 × 16 and 8 × 8. The face images are directly cropped from the surveillance images, and if the cropped images are not exactly the desir ed sizes, they are sligh tly changed through Cubic interpolation to the nearest resolution level. Four experiments are conducted. Experiment 1 compares recognition performances between two different types of low resolution image. One type is directly captured with large distance between the camera and the person. Another type is from down-sampling from high-resolu- tion images. Results from Experiment 1 demonstrate that the recognition performances for the directly captured images are much low er than the low-resolution images. In Experiment 2 the distance between the camera and the perso n is fixed. It compares the recognition performances between different types of cameras, resulting in different resolutions in the captured images. In Experiment 3: the image resolution is fixed. Recognition performances are compared on face images from various sources, whereas the types of camera and capturing distances vary. The recognition performance of our proposed approach on surveillance fac e images is demonstrated in Experiment4. 4.1. Down-Sampling vs Captured Low Resolution Lots of work has be en done on low -resolution face rec- ognition. Howev er, mo s t of the existing works are on low-resolution face images down-sampled from high- resolution images. In real life, most low-resolutions are due to the large distances between the cameras and the face. It is hence worthwhile to evaluate whether the down-sampled images provide a good representation of the true low-resolutio n ima ges . Here we compare the recognition difference between the down-sampled im- ages and images captured by cameras in a far distance. Face recognition is first performed on imag es from the popular AR database. Fig ure 2(a) shows the recog ni tion 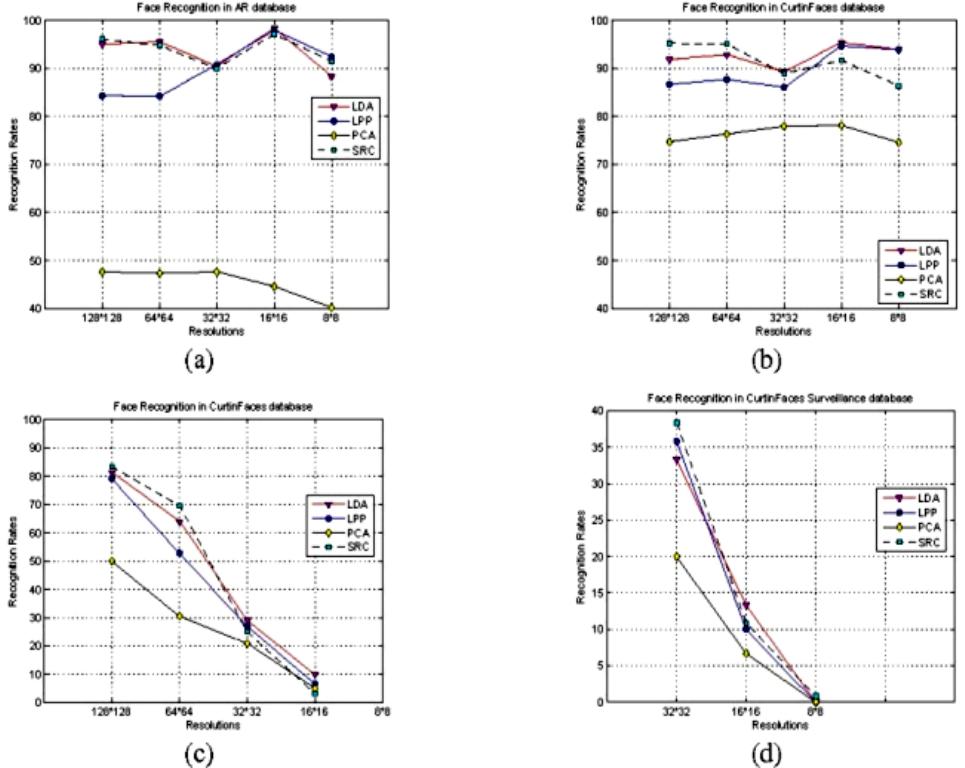 Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC rates in ter ms of different down-sampled resolutions on AR database. In this experiment, we randomly select 13out the 26 images per person for training and the other 13 for testing. This procedure is repeated 10 times to obtain the averag e r ecognition rate. Similarly, face rec- ognition resu lts on the Curtin Faces High Definition da- tabase are shown in Figure 2(b). H ere, only 25 images are selected per pe rson from the available 92 images among which images with large pose and illumination variations are excluded. 12 images out of the 25 are ran- domly selected for training and the other 13 are for test- ing. It can be seen from these two figures that when low- resolution face images are down-sampled from high- resolution ones, their recognition rates do not redu ced much. Even very low-resolution (8 × 8) faces can still achieve a satisfactory recognition rate (around 90%). However, when i ma g e resolution drop s due to the in- creased distances, recognition rates decrease very sharply, as shown in Figure 2(c). In this figure, face images are captured using the same High Definition camera as in b. Ins tead of down-sampling images to low-resolution, im- ages in this figure are captured from various distances in the same environment. The resolutions of the captured face images are approximately in the resolution levels of 128 × 128, 64 × 64, 32 × 32, and 16 × 16 in the distances of 2.5 meters, 5meters, 10meters and 20meters respec- tively. In clear contrary to the various resolutions from down-sampling, decreasing of resolutions due to the in- creased distance from camera caused the recognition rates drop ver y sharply as shown in Figure 2(c). It can be concluded that the down-sampled face images are not good representations of captured low-resolution images for face recognition. Face recognition perfo r- mance with directly captured images in distances through High Definition cameras is ver y low. To further demonstrate the difference between down- sampling and distance sampling, databases captured through surveillance cameras are adopted. Figu re 2(d) and Table 1 show the face recognition rates in Curtin Faces Surveillance Camera database and ScFace database Figure 2. Down-sampling vs distance sampling.  Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC Table 1. Face recognition performance in scface database. LDA LPP PCA SRC Camera 1 3.08 4.62 13.85 13.85 Camera 2 5.38 4.62 18.46 14.62 Camera 3 3.85 4.62 16.42 10.00 Camera 4 1.54 7.69 20.77 12.31 Camera 5 3.08 6.15 12.31 3.08 respectively. The face images of the mare captured with different surveillance cameras in far distances. It can be seen that reg ard les s of different recognition approaches, the recognition rates are also very lo w when images are captured in distances instead of down-sampled from high-resolution images through surveillance cameras. 4.2. High Definition Cameras vs Surveillance Camera It has been shown in Fig ure 2(c) that ev en images cap- tured from a high definition camera are unable to warrant a good recognition performance. In this experiment we evaluate the performance of surveillance ca me r a in in- door surveillance scenarios. The Curtin Faces Surv data- base contains video sequen ces from a surveillance cam- era which captures human faces in the sa me environment as the high definition camera used above. The surveil- lance camera is a commercial video surveillance camera with the ima g e resolution of 704 × 576. The o r igin al res- olutions of the croppe d face images from the surveillance camera are approximately 32 × 32, 16 × 16 and 8 × 8 taken in the distances of 2.5meters, 5meters and 10 me- ters respectively. Face recognition performance by the popular LD A, LPP, PCA an d SRC methods are shown in Figure 2(d). The recognition rates can be observed to be similar to those of the high definition cameras with dif- ferent distances (Figure 2(c)). However, when the dis- tances are fixed, e.g., in 5meters, the differences of cam- eras and resolutions lead to huge differences in reco gn i- tion rates. In this distance the SRC recognition rate for high definition camera is around 70% with the resolution 64 × 64, while the SRC recognition rate for surveillance camera is around only 11% with the resolution16 × 16. 4.3. Cameras, Distance and Resolution This experiment aims to exp lore the influences of the types of cameras, distances and resolutions for surveil- ance face recognition. From Experiment 1, we can see- that when the same camera is used, images taken in dif- ferent distances result in totally different recognition performance. As shown in Experiment 2, when the dis- tance is fixed, images taken by different cameras have large differences in the recognition performance. What would a fixed resolution lead to? We select two different resolutions in this experiment. Figure 3(a) shows the recognition performance for images with the resolution of 16 × 16. Images with this resolution are captu r ed by the high definition camera at the distance of 20 meters and by the surveillance camera only from 5 meters away. Figure 3(b) shows th e performance in the resolution of 32 × 32 , where HD camera is at a distan ce of 10 meters and surveillance camera is at a distance of 5 meters. We can see from both figures that despite the differences in camera types and shooting distances, f ace images with same resolutions result in similar recognition perfo r- mances. 4.4. Face Recognition by Super Resolution In this experiment, the proposed face recognition method is applied and tested. Here, we carry out the experiment on the surveillance camera. Figure 4(a) demonstrates the recognition performance comparison between the cap- tured faces in the distance of 5 meters by the surveillance camera and the enhanced images by the propose d ap- proach. In this setting, the original face resolution is 16 × 16 and the enh an ced face resolu tion is 64 × 64. Figure 4(b) sh ow s the rec ognition performance comparison be- tween the captur ed faces in the distance of 10 meters by the HD camera and the enhanced faces by the proposed approach. As shown in Figure 4, the face recognition rates are greatly improved after the images are processed using the proposed method, no matter which recognition method is used. 5. Conclusion Avoid Traditional face recognition approaches can hard- ly achieve satisfactory performance on low-resolution images, esp. on those directly captured by surveillance cameras. Till now little work has been done specifically on face recognition based on surveillance cameras. In this paper, we analyze the factors which impact on face recognition performances in surveillance scenario. Expe- riments indicate that other than camera types and captur- ing distances, image resolution is the major factor af- fecting the performance of face recognition in surveil- lance circumstance. Specifically we can conclude that the higher resolution the images, the better performance face recognition achieves. According to the special conditions of a surveillance system, we proposed a super-resolution based face rec- ognition approach. Experiments demonstrate that our approach outperforms traditional face recognition ap- proaches significantly. Although the proposed approach performs well for very low resolution face recognition in surveillance sys- tem, more practical surveillance conditions need to be- considered, such as motion blur, extremely low resolu- 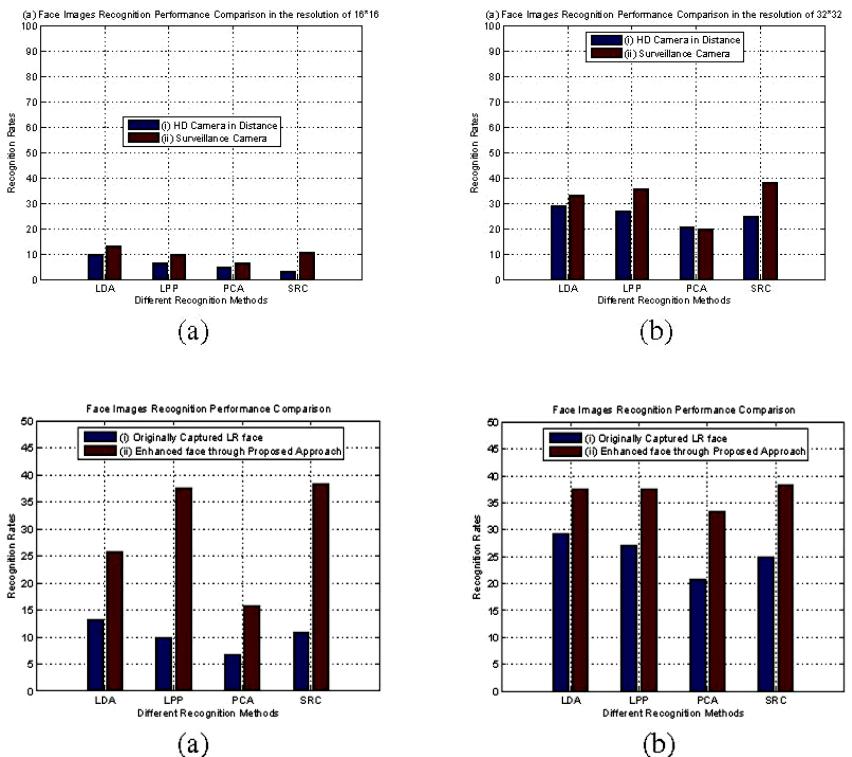 Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC Figure 3. Recongnition comparision with the same resolution. Figure 4. Recognition performance comparision between originally captured face images and proposed approach. tion (less than 10 × 10) and face recognition in outdoor conditions and from very far distances. They will be our future work. REFERENCES [1] W. Zhao, et al., “Face Recognition: A Literature Survey,” ACM Computing Surveys, Vol. 35, 2003, pp. 399-458. [2] M. A. Turk and A. P. Pentland, “Face Recognition Using Eigenfaces,” IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 1991, pp. 586- 591. [3] P. N. Belhumeur, J. P. Hespanha and D. J. Kriegman, “Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection,” IEEE Transactions on Pat- tern Analysis and Machine Intelligence, Vol. 19, 1997, pp. 711-720. [4] X. He and P. Niyogi, “Locality Preserving Projections,” Advances in Neural Information Processing Systems, Vol. 16, 2004, pp. 153-160. [5] A. S. Georghiades, P. N. Belhumeur and D. J. Kriegman, “From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose,” IEEE Transactions on Pattern Analysis and Machine Intelli- gence, Vol. 23, 2001, pp. 643-660. [6] J. Wright, et al., “Robust Face Recognition via Sparse Representation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 31, 2009, pp. 210-227. [7] W. W. W. Zou and P. C. Yuen, “Very Low Resolution Face Recognition Problem,” IEEE Transactions on Image Processing, Vol. 21, 2012, pp. 327-340. [8] S. Biswas, K. W. Bowyer and P. J. Flynn, “Multidimen- sional Scaling for Matching Low-Resolution Face Im- ages,” IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, Vol. 34, 2012, pp. 2019-2030. [9] C.-X. Ren, D.-Q. Dai and H. Yan, “Coupled Kernel Em- bedding for Low-Resolution Face Image Recognition,” IEEE Transactions on Image Processing, Vol. 21, 2012, pp. 3770-3783. [10] M. Grgic, K. Delac and S. Grgic, “SCface—Surveillance Cameras Face Database,” Multimedia Tools and Applica- tions, Vol. 51, 2011, pp. 863-879. [11] B. Y. L. Li, et al., “Using Kinect for Face Recognition Low Resolution Face Recognition in Surveillance Systems OPEN ACCESS JCC under Varying Poses, Expressions, Illumination and Di s- guise,” IEEE Workshop on Applications of Computer Vi- sion (WACV), 2013, pp. 186-192. [12] V. Štruc, J. Žibert and N. Pavešić, “Histogram Remap- ping as a Preprocessing Step for Robust Face Recogni- tion,” Image, Vol. 7, 2009, p. 9. [13] H. B. Mitchell, “Image Fusion: Theories, Techniques and Applications,” 2010. [14] E. Candes, et al., “Fast Discrete Curvelet Transforms,” Multiscale Modeling Simulation, 2006. [15] E. J. Candès and D. J. Donoho, “Curvelet: A Surprising Effective Non-Adaptive Representation for Objects with Edges,” Department of Statistics, 1999. [16] T. Mandal, Q. M. J. Wu and Y. Yuan, “Curvelet Based Face Recognition via Dimension Reduction,” Signal Processing, Vol. 89, 2009, pp. 2345-2353. [17] J. Yang, et al., “Image Super-Resolution via Sparse Re- presentation,” IEEE Transactions on Image Processing, Vol. 19, 2010, pp. 2861-2873. [18] P. J. Phillips, et al., “Preliminary Face Recognition Grand Challenge Results,” 7th International Conference on Au- tomatic Face and Gesture Recognition, 2006, pp. 15-24. [19] X. Wang and X. Tang, “Hallucinating Face by Eigen- transformation,” IEEE Transactions on Systems, Man, and Cybernetics, Vol. 35, 2005, pp. 425-434. [20] A. M. Martinez and R. Benavente, “The {AR} Face Da- tabase,” CVC Technical Report, 1998.
|