M. A. RAZEK
Open Access IIM
197
We apply dominant meaning words, along with a ma-
chine learning method to classify WebPages. The domi-
nant meaning definition is known as “the set of key-
words that best fit an intended meaning of a target word”
[7]. This technique sees a query as a target meaning plus
some words that fall within the range of that meaning. It
freezes up the target meaning, which is called a master
word, and adds or removes some slave words, which
clarify the target meaning.
2. Motivation
This research tackles to solve the Web mining content.
For the semi-structured data, all the works utilize the
HTML structures inside the WebPages and some utilized
the hyperlink structure between the WebPages for Web-
Page representation. As for the database view, in order to
have the better information management and querying on
the web, the mining always tries to infer the structure of
the web site to transform a web site to become a data-
base.
For HTML web pages, there are many research and
commercial systems available which use also image cap-
tions, e.g. Google image search: “Google analyzes the
text on the page adjacent to the image, the image caption
and dozens of other factors to determine the image con-
tent. Google also uses sophisticated algorithms to remove
duplicates and ensure that the highest quality images are
presented first in your results” [8], and [9]. In this sense,
this project is using dominant meaning technique [7] and
how it can be used to improve Web images searches.
How does it influence search results?
The dominant meaning definition is known as “the set
of keywords that best fit an intended meaning of a target
word” [7]. This technique sees a query as a target mean-
ing plus some words that fall within the range of that
meaning. It freezes the target meaning, which is called a
master word, and adds or removes some slave words,
which clarify the target meaning.
For example, suppose that the query is “Java”. Figure
1 shows the results of the word “Java”. As shown, the
most results are representing some images for the three
well-known meanings of java: Java (computer program
language), Java (coffee), and Java (Island).
The idea of this research is to clarify the target mean-
ing with some slave words. Accordingly, if we need to
look for java (computer program language), we need to
add some slaves of java such as, computer, program, and
language.
Figure 2 shows the results of Java with its slaves. This
result, as we see, is more close to java language pro-
gram.
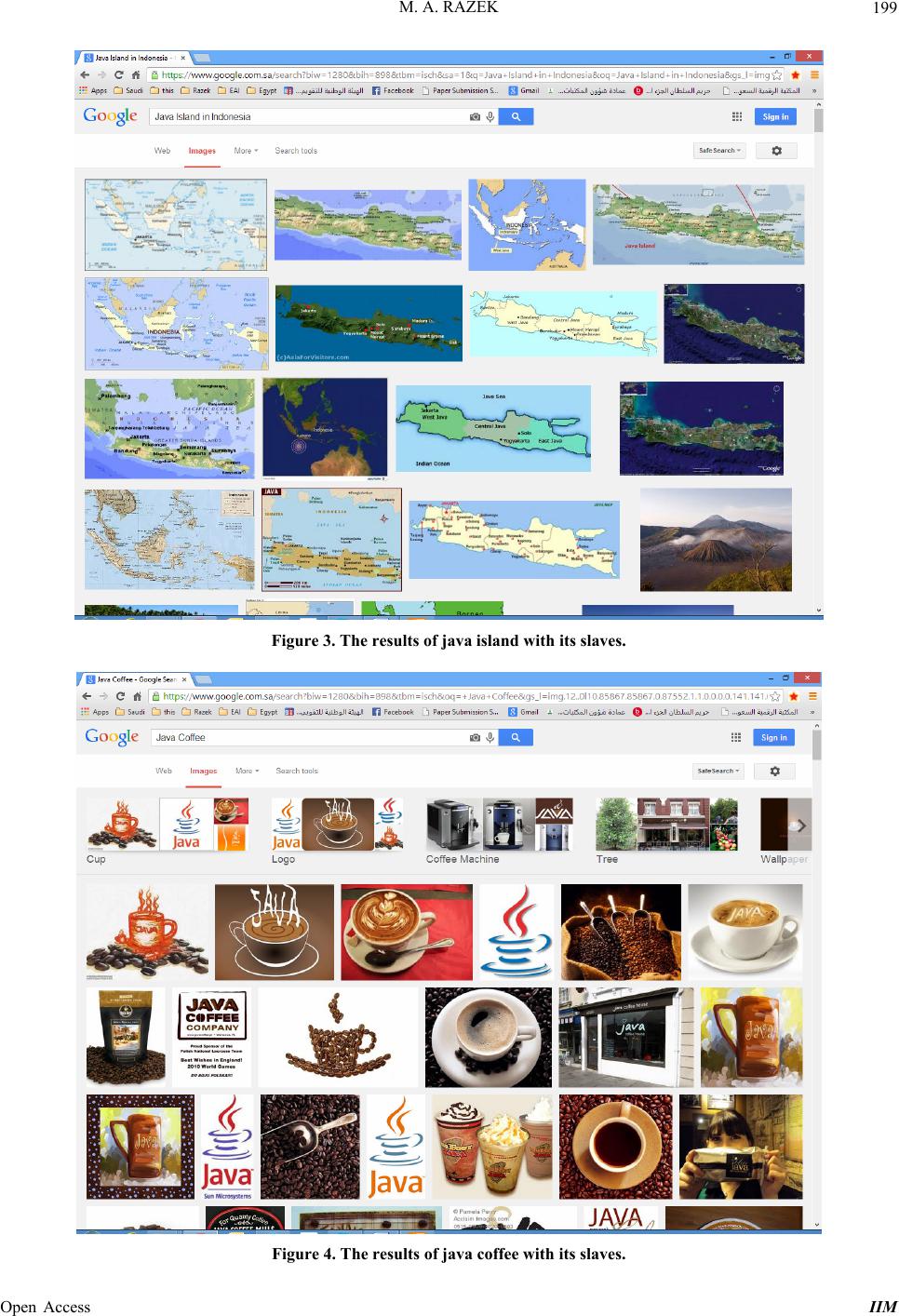
Figure 3 shows the results of Java Island with its
slaves. It’s clear that the results are more close to Java
Island in Indonesia, and th ere is no images related to ja va
language program.
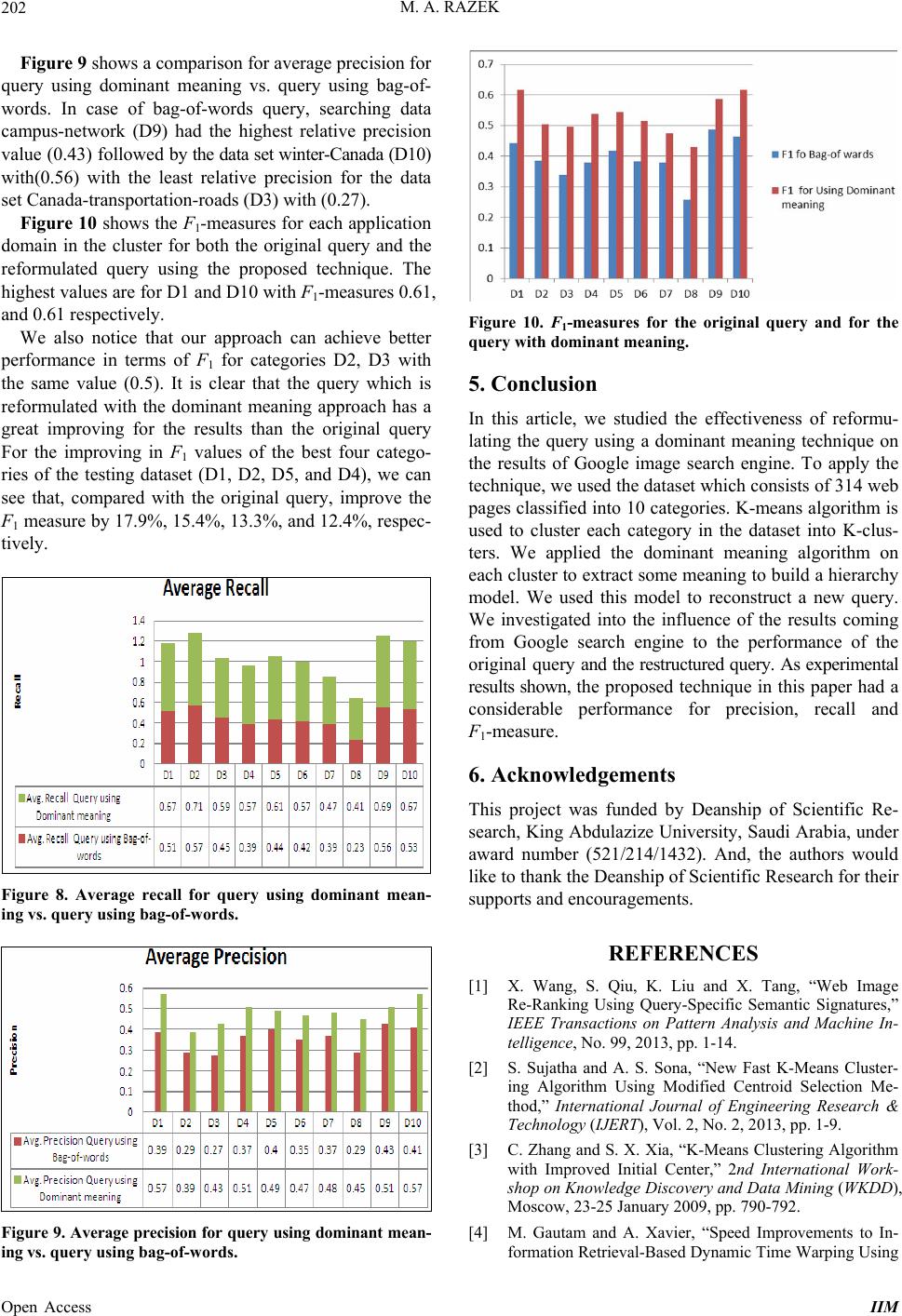
On the other hand, Figure 4 presents the results of
Java Coffee with its slaves. It’s clear that the results do
not include neither images for Java language program or
Java Island. Therefore, we use the learner’s context of
interest and domain knowledge to individualize the con-
text of this target word. We do that by looking for key-
wor ds in the use r profile (the learner’s context of interest)
to help in specifying the intending meaning. Because the
target meaning is “computer program language”, we look
for slave words in the user profile that best fit this spe-
cific meaning—words such as “computer”, “program”,
“awt”, “application”, and “swing”.
The main question now is how to specify the core
cluster of a query. To overcome this question, we must
give answers for the following three questions: How can
we construct a dominant meaning for image search? How
can the system decide which intended meaning for the
image requested? And how can it select words that must
be added to the original query?
The following subsections give an answer for each of
them in detail.
3. Methodology
This section presents the methodology to clus ter the data
collected from the Web, and also shows how to use this
clusters for forming the model of the dominant mean-
ing.
Figure 5 presents the architecture of our approach to
improve the results of Google image search engine. This
project follows some instructs to create and then improve
the query results of image search.
Firstly, we collect a specific datasets related to some
application domain.
Using K-means algorithm to cluster the dataset into
K-clusters. Each collection is divided into K-classes.
Each cluster is related to one meaning and contains
some words to identify his meaning called slave
words.
Using dominant meaning algorithm is to classify
slave words under its master words to identify the
meaning coming from the cluster. This technique ge-
nerates a hierarchy model for the dominant meaning
of each cluster.
The query is reconstructed based what is appropriate
slave words to be added the query can be very impor-
tant.
Send the original and the new qu ery independently, to
search Google Image Search Engine.
Choose the top-1000 items coming from the results
for both queries.
Compare the precision and recall of the results for
both que ri e s.