 Journal of Data Analysis and Information Processing, 2013, 1, 90-96 Published Online November 2013 (http://www.scirp.org/journal/jdaip) http://dx.doi.org/10.4236/jdaip.2013.14010 Open Access JDAIP Spatial Multidimensional Association Rules Mining in Forest Fire Data Imas Sukaesih Sitanggang Department of Computer Science, Bogor Agricultural University, Bogor, Indonesia Email: imas.sitanggang@ipb.ac.id Received September 20, 2013; revised October 25, 2013; accepted November 8, 2013 Copyright © 2013 Imas Sukaesih Sitanggang. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. ABSTRACT Hotspots (active fires) indicate spatial distribution of fires. A study on determining influence factors for hotspot occur- rence is essential so that fire events can be predicted based on characteristics of a certain area. This study discovers the possible influence factors on the occurrence of fire events using the association rule algorithm namely Apriori in the study area of Rokan Hilir Riau Province Indonesia. The Apriori algorithm was applied on a forest fire dataset which contained data on physical environment (land cover, river, road and city center), socio-economic (income source, popu- lation, and number of school), weather (precipitation, wind speed, and screen temperature), and peatlands. The experi- ment results revealed 324 multidimensional association rules indicating relationships between hotspots occurrence and other factors. The association among hotspots occurrence with other geographical objects was discovered for the mini- mum support of 10% and the minimum confidence of 80%. The results show that strong relations between hotspots occurrence and influence factors are found for the support about 12.42%, the confidence of 1, and the lift of 2.26. These factors are precipitation greater than or equal to 3 mm/day, wind speed in [1 m/s, 2 m/s), non peatland area, screen tem- perature in [297K, 298K), the number of school in 1 km2 less than or equal to 0.1, and the distance of each hotspot to the nearest road less than or equal to 2.5 km. Keywords: Data Mining; Spatial Association Rule; Hotspot Occurrence; Apriori Algorithm 1. Introduction Forest fires are considered to be a potential hazard that causes enormous physical, biological and environmental losses. Hotspots are image pixels that may represent fires. A study on the spatial relationships between the location of hotspots occurrence and specific geographical objects near the hotspots is essential. Therefore, the possible in- fluence factors for fires can be determined to predict the future hotspots occurrence. Spatial data mining is a growing research area in ana- lyzing large spatial data. It is a process to extract knowl- edge, spatial relationships, or the other interesting pat- terns not explicitly stored in spatial databases [1]. In a spatial data mining system, attributes of neighbors of an object may have a significant influence on the object itself. Therefore, the discovery process for spatial data is more complex than those for non-spatial data, because spatial data mining algorithms have to consider the neighbors of objects in order to extract useful knowledge [2]. In this study, a technique in data mining, namely asso- ciation rule mining, is applied to a case study. The pur- pose of the case study is to discover relations between hot- spots occurrence and the characteristics of neighboring objects of hotspots. Pre-processing steps for spatial data were performed to prepare a dataset as the input of well- known association rule algorithm, i.e. Apriori. The results are spatial association rules describing frequent co-oc- currences between variables in the spatial database. Some works related to mining spatial association rules are discussed in [3-6]. Moreover, Berardi, et al. [7] dis- covered spatial association rules from a particular kind of images, namely document images. This work studied six papers, published in the IEEE Transactions on Pattern Analysis and Machine Intelligence, in the January and February 1996 issues. The rules discovery is based on the processes of layout structure extraction (layout analysis) and logical structure extraction (document image under- standing). This work uses SPADA (Spatial Pattern Dis- covery Algorithm) [8] to generate association rules, for example [7]: is_a(A,running_head) on_top(A,B), is_a  I. S. SITANGGANG 91 (B,content), type_text(A), support: 90.9%; confidence: 90.9% This rule means that if a logical component (A) is a running head, then it is textual and it is on top of another layout component (B) which is a component of type content. This rule has a high support and a high confi- dence i.e. 90.9%. A case study by [9] determines the existing spatial re- lationships between the location of incidents and specific geographical objects near the center of Helsinki. This work performed the transformation of spatial data to the transaction format such that the classic association rules algorithms can be applied to the data. Each object in the transactional file is identified by only its unique ID, geo- graphical coordinates and the specification of object type (point, line, or polygon). The algorithm based on the Ap- riori algorithm was utilized to extract association rules from the transaction file. One of the rules is as follows: bars and restaurants incidents (1.7%; 40.0%). This rule states that an incident has occurred in a neighbourhood of 40% of all bars and restaurants within the Helsinki city center during the studied time period. Spatial association rules of land use were extracted in the study by [10] from the land use data of Yi city in Hubei Province in China. This work used the fuzzy con- cept lattice method to obtain land use spatial association rules, which can offer decision supports in land suitabil- ity evaluation, classification and grading and land use planning [10]. 2. Material and Methods 2.1. Study Area and Forest Fires Data The study area is Rokan Hilir district in Riau Province in Indonesia. Rokan Hilir spans an area of 8881.59 Km2 [11] or approximately 10% of Riau’s total land area. Rokan Hilir is located in the western part of the north Sumatera, the southern part of Bengkalis district and Rokan Hulu district, the eastern of Dumai and the northern part of the north Sumatera and Melaka strait. The district is divided into 13 subdistricts with the total of population is 552,400 based on Population Census 2010 of the Riau Province [12]. The data used in this study are as follows: 1) Spread and coordinates of MODIS hotspots 2008. The data are provided by Fire Information for Resource Management System (FIRMS), University of Maryland, NASA, Conservation International. 2) Digital maps for road, rivers, city centers, land cov- er, and the administrative border from National Coordi- nating Agency for Survey and Mapping (BAKOSUR- TANAL), Indonesia. 3) Socio-economic data from BPS-Statistics Indonesia including inhabitant’s income source, population density, and number of school per km2. 4) Weather data 2008 (in the NetCDF format) includ- ing screen temperature, precipitation, 10 m wind speed, and surface height. The data were collected from Mete- orological Climatological and Geophysical Agency (BMKG), Indonesia. 5) Digital maps for peatland depth and peatland types provided by the Wetland International. A MODIS hotspot/active fire is a vegetation fire, but sometimes it is a volcanic eruption or the flare from a gas well. It is detected using the MODIS (or Moderate Reso- lution Imaging Spectroradiometer) instrument, on board NASA’s Aqua and Terra satellites [13]. A MODIS hot- spot represents the center of a 1 km (approximately) pixel flagged as containing one or more actively burning hotspots/fires (Figure 1). In the study area, as many 517 MODIS hotspots were found in 2008. We create a buffer of each hotspot and then 513 points were randomly generated outside buffers as non-hotspot points. The radius of buffer is 0.90737 km as the result of Landsat TM image processing. The spatial data as influencing factors for hotspots occurrence are stored in layers in the spatial database. There are three types of spatial features in the layers i.e. point, line, and polygon. The spatial reference system UTM 47N and datum WGS84 were assigned to all layers in the spatial database. 2.2. Data Transformation Association rules mining requires a dataset in the trans- action format which contains transaction id and item sets. Several steps were performed to create the transaction dataset from the set of layers of influencing factors for hotspots occurrence. The tools utilized in data transfor- mation are PostgreSQL 9.1 (http://www.postgresql.org) to manage the spatial database, PostGIS 1.5 (http://www.postgis.org) to perform spatial operations, and Quantum GIS 1.7.2 (http://www.qgis.org) to analyze and to visualize spatial data. This work applied topological and distance relation- ships to relate spatial objects in two different layers. The topological operation ST_Within that is available in Post GIS defines whether a point feature is located inside a polygon feature. For example, for each hotspot and non- hotspot point, we determine whether the points are inside a land cover type in which land cover objects are repre- sented in polygon (Figure 2). The operation ST_Within was also used to relate the hotspot occurrence layer to other layers i.e. income source, precipitation, screen temperature, 10 m wind speed, peatland type and peat- land depth. Moreover, the distance function is used to calculate distance from a point (or line) to another point (or line). Open Access JDAIP 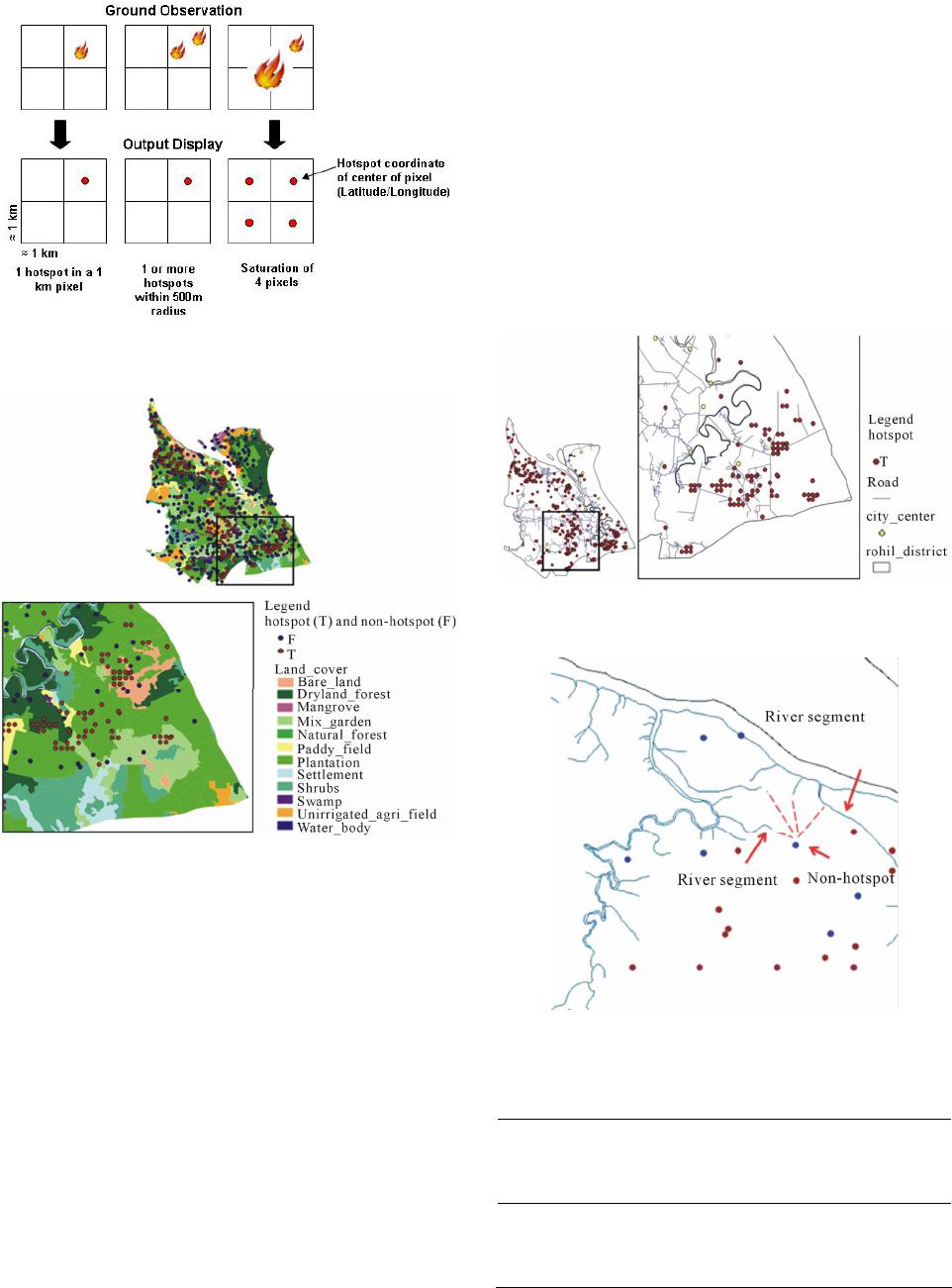 I. S. SITANGGANG 92 Figure 1. The MODIS hotspot represents the center of a 1 km (approximately) pixel [13]. Figure 2. Hotspot locations overlaid with the land cover la- yer. This work computed distance from hotspots and non- hotspots (point features) to the nearest river (line fea- tures), to the nearest road (line features), and to the near- est city centers (point features). For example, Figure 3 shows hotspot locations overlaid with road and city cen- ters. Figure 4 shows how distance from a hotspot to every river segment is calculated and the minimum value is considered as the distance from a hotspot to the nearest river. To perform this task, the spatial operation ST_ Distance in PostGIS 1.5 was applied to calculate distance of objects to the nearest river, road, and city center. Be- cause the Apriori algorithm requires categorical values in a dataset, the minimum distance were converted to cate- gorical values based on the classes provided in Table 1. Table 2 provides the number of spatial features in all layers in the forest fire database. The layers contain spa- tial objects that may influence hotspots occurrence. In order to discover associations between spatial objects and hotspots occurrence using the Apriori algorithm, each layer is related to the hotspot layer. Relating the hotspot layer to other layers using the spatial operation ST_Within and ST_Distance results several new layers. For example, Figure 5 shows the relations as the representation of layers. Each relation has the attribute the_geom which stores the geometry type of spatial features. The new layer (c) is obtained by apply- ing the spatial operation ST_Within to define whether points in the hotspot layer (a) are inside polygons in the land cover layer (b) or not. Figure 3. Hotspot locations overlaid with road and city cen- ters. Figure 4. Hotspot locations overlaid with the river layer. Table 1. Classes for distance from target objects to nearest city centers , ri vers, and roads. Class Distance target object to nearest city center (x) in km Distance target object to river (y) in km Distance target object to road (z) in km Low x ≤ 7 y ≤ 1.5 z ≤ 2.5 Medium 7 < x ≤ 14 1.5 < y ≤ 3 2.5 < z ≤ 5 High x > 14 y > 3 z > 5 Open Access JDAIP  I. S. SITANGGANG 93 Table 2. Layers in the database. Layer Number of features Distance to nearest river (dist_river) 1030 points Distance to nearest road (dist_road) 1030 points Distance to nearest city center (dist_city) 1030 points Land cover (land_cover) 3058 polygons Income source (income_source) 117 polygons Population density (population) 117 polygons Number of school per km2 (school) 117 polygons Precipitation in mm/day (precipitation) 7 polygons Screen temperature in K (screen_temp) 7 polygons 10m wind speed in m/s (wind_speed) 7 polygons Peatland type (peatland_type) 58 polygons Peatland depth (peatland_depth) 68 polygons (a) (b) (c) Figure 5. A new layer (c) as the result of relating the hotspot layer (a) and the land cover layer (b). All new layers were integrated into a single layer by matching identifiers of objects in the hotspot layer and those in other layers. This step produced a relation that is considered as a transactional dataset for the Apriori algo- rithm. 2.3. Spatial Association Rules The basic idea of mining association rules from spatial databases is similar to those from non-spatial databases (transactional or relational databases). A spatial associa- tion rule has the form A B (s%, c%), where A and B are sets of spatial or non-spatial predicates, s% is the support of the rule, and c% is the confidence of the rule [1]. Spatial association rules differ with non-spatial asso- ciation rules because it may include spatial predicates such as distance information (for instance, close_to, and far_away), topological relations (for example, touch, overlap, and intersect), and spatial orientation (such as right_of, and east_of). An example of spatial association rule is as follows: x is a shopping centre x close to a bus station x close to a settlement area (0.5%, 75%). The rule says that 75% of shopping centers that are close to bus stations are also close to settlement areas, and 0.5% of the data belong to such a rule. 2.4. Apriori Algorithm The Apriori algorithm was introduced by [14] to discover frequent itemsets and association rules in a transactional dataset that have support and confidence greater than the user-specified minimum support (minsup) and minimum confidence (minconf) respectively. An association rule has the form X Y, where X and Y are a subset I, I is a set of items, and X Y = . The Apriori algorithm is as follows [14]: Lk is a set of large k-itemsets. This set contains k- itemsets that have minimum support. Ck is a set of can- didate k-itemsets. Itemsets in this set are potentially large itemsets. In the Apriori algorithm, the apriori-gen func- tion has the argument Lk1 i.e. the set of all large (k1)- itemsets. The output of this function is a superset of the set of all large k-itemsets [14]. 1) L1 = {large 1-itemsets}; 2) for (k = 2; Lk 1 ≠ ; k++) do begin 3) Ck = apriori-gen (Lk 1); //New candidates 4) forall transactions t D do begin 5) Ct = subset(Ck, t); //Candidates contained in t 6) forall candidates c Ct do 7) c.count ++; 8) end 9) Lk = {c Ck | c.count minsup} 10) end 11) Answer = kLk; Open Access JDAIP  I. S. SITANGGANG 94 There are three most widely-used measures for select- ing interesting rules i.e. support, confidence and lift. Support and confidence of the rule A B are defined as follows [1]: support BPAB (1) confidence | BPBA (2) support B is the percentage of transaction in a transactional dataset D that contain both A and B whereas confidence(AB) is the percentage of transactions in D containing A that also contain B [1]. Equation (2) is also stated as follows: support confidence upport B AB sA (3) In order to measure the correlation between A and B in the rule AB, the correlation measure Lift may be used which is computed as follows [1]: lift ,PA B AB PA PB (4) Based on the value of lift , B in Equation (4), the relation of occurrence of A and B is described as follows. If lift , B is greater than 1, then A and B are posi- tively correlated meaning that the occurrence of A im- plies the occurrence of B. If , lif t B is less than 1, then A and B are negatively correlated. A and B are inde- pendent if t , lif B is equal to 1. It means that there is no correlation between A and B [1]. 2.5. Multiple Dimensional Association Rule Mining In multiple dimensional association rule mining, associa- tion rules are discovered from a dataset which contains more than one attribute (called as a dimension). For ex- ample, in single dimension mining, we can generate a rule: buys (X, “pc tablet”) buys (X, “earphones”), whereas in a multidimensional mining, we can generate a rule: Occupation (X,” IT staff”) and Salary (X, “10-20K”) buys (X, “smartphone”). In this rule, occupation, salary and buys are dimen- sions that may have different types such as boolean, cate- gorical and numerical. Srikant and Agrawal [15] introduced an approach to map the quantitative association rules problem to the boolean association rules problem. The quantitative val- ues are partitioned into intervals and then the pair < at- tribute, interval > is mapped to a boolean attribute [15]. For example, the attribute Age can be partitioned into two intervals: 20 - 29 and 30 - 39. The categorical attrib- ute correspond to <attribute, value>. For example, the attribute Married that has two values: yes and no, is re- placed to the pair < Married: Yes > and < Married: No>. Figure 6 shows an example of a dataset before and af- ter mapping to boolean association rules problem. We can apply the algorithms for mining single dimension association rule to the new dataset (Figure 6(b)). 3. Result and Discussion Pre-processing steps on the spatial forest fires data result a dataset consisting of 490 records. Variables in the dataset are hotspots occurrence, distance to nearest river (dist_river), distance to nearest road (dist_road), distance to nearest city, center (dist_city), land cover (land_cover), income source (income_source), population density (popu- lation), number of school per km2 (school), precipitation in mm/day (precipitation), screen temperature in k (screen _temp), 10m wind speed in m/s (wind_speed), peatland type (peatland_type), and peatland depth (peatland_ depth). The Apriori algorithm which is available in the statistical computing tool R (http://www.r-project.org/) was executed on the dataset and it generated 2981 asso- ciation rules. The purpose of this study is to find possible factors that strongly influence hotspots occurrence. Therefore for further analysis, we only study association rules that include hotspots occurrence. There are 324 rules or about 10.87% containing hotspots occurrence generated from the dataset with the minimum support of 10% and the minimum confidence of 80%. For the support value greater than or equal to 25%, weather variables and socio-economic variables occur with hotspots in the study area. The support of 25% means that 123 transactions out of 490 transactions sup- port the association rules. The weather variables included in the rules are precipitation 3 mm/day and screen temperature = [297˚K, 298˚K) whereas the socio-eco- nomic variables appeared in the rules are population den- sity ≤ 50 and number of school in 1 km2 ≤ 0.1. The physical environmental factors including dist_city = (7 km, 14 km], dist_river ≤ 1.5 km, dist_road ≤ 2.5 km, and land_cover = Plantation occur together with hot (a) (b) Figure 6. A dataset before (a) and after (b) mapping to boo- lean association rules problem (Srikant and Agrawal, 1996). Open Access JDAIP  I. S. SITANGGANG 95 spots in the rules that have the support less than 25%. Moreover, hotspots appear in non-peatland and in the area where inhabitant’s income source is plantation. Several rules extracted from the forest fire transaction dataset are as follows: 1) {hotspot_occurrence = Yes} => {precipitation 3 mm/day} (44.49%, 100%, 1.03) 2) {hotspot_occurrence = Yes} => {school ≤ 0.1} (36.94%, 83.03%, 1.00) 3) {population ≤ 50, hotspot_occurrence = Yes} => {screen_temp = [297K,298K]] (25.31%, 80%, 1.05) 4) {income_source = Plantation, hotspot_occurrence = Yes} => {population ≤ 50} (18.57%, 85.85%, 1.27) 5) {dist_city = (7 km, 14 km), hotspot_occurrence = Yes) => {precipitation 3 mm/day} (20.20%, 100%, 1.03) 6) {peatland_type = non_peatland, hotspot_occurrence = Yes} => {wind_speed = [1 m/s, 2 m/s)} (13.27%, 83.33%, 1.20) For each rule, the first number between brackets repre- sents the support, the second is the confidence of the rule, and the third is the lift of the rule. The rule 1 is the strongest rule among all rules generated from the forest fires dataset. This rule has the support of 44.49%, the confidence of 100%, and the lift of 1.03. It means that 44.49% of the transactions contain at least the factor hotspot_occurrence = Yes and precipitation 3 mm/day and all transactions that contains hotspot_occurrence = Yes also contain precipitation 3 mm/day. The lift of rule 1 is greater than 1 meaning that hotspot_occurrence = Yes and precipitation 3 mm/day are positively corre- lated. This rule means that there is a high probability that the hotspots occurred in the area which has precipitation is greater than or equal to 3 mm/day. The rule 2 states that about 36.94% of the transactions in the dataset that contain hotspot_occurrence = Yes also contain school ≤ 0.1. This means hotspots are probably occurred in less populated regions in which the number of school in the area of 1 km2 is less than or equal to 0.1. Rules 3 and 4 show the associations between hotspots occurrence and two socio-economic factors i.e. population ≤ 50 and in- come_source = Plantation as well as the weather factor i.e. screen_temp = [297K, 298K). According to the rule 5, hotspots occur in locations in which the precipitation is greater than or equal to 3 mm/ day. The distance between the locations to nearest city centers is greater than 7 km and less than 14 km. As many 99 transactions out of 490 transactions (20.20%) support this association. The rule 6 means that hotspots were found in non-peatlands with the range of 10 m wind speed is [1 m/s, 2 m/s). Figure 7 shows the scatter plot for 324 association rules containing the item hotspot_occurrence = Yes. Ea- ch point in the plot represents a rule. Support and lift are Figure 7. Scatter plot for 324 association rules containing the item hotspot_occurrence = Yes. used for the x-axis and y-axis respectively while the color of the points is used to indicate the confidence level of the rules. The rule in the bottom right in Figure 7 has the high- est support i.e. 44.4898%. There are 24 rules in the top left corner with the highest lift of 2.258065 and the high- est confidence of 1. In the average, these rules are sup- ported by 12.4149667% of records in the dataset. In ad- dition to hotspots occurrence, the rules include other factors that are considered as influencing factors for fire events. These factors are precipitation greater than or equal to 3 mm/day, wind speed in [1 m/s, 2 m/s), non peatland area, screen temperature in [297K, 298K), the number of school in 1 km2 less than or equal to 0.1, and the distance of each hotspot to the nearest road less than or equal to 2.5 km. 4. Summary and Future Work This paper discusses the application of the association rule algorithm to discover strong relationships among hotspots occurrence and other geographical objects for forest fires. Pre-processing steps were conducted on the spatial forest fire dataset in order to prepare a task rele- vant dataset for the Apriori algorithm. Two types of spa- tial relationships namely topological and metric were applied to relate a spatial feature to other spatial features. Our analysis with the minimum support of 25% and the minimum confidence of 80% shows strong relations among hotspot occurrence, weather variables, and socio- economic. Hotspots mostly occur in less-populated areas with population density being less than or equal to 50 and number of schools per km2 being less than or equal to 0.1. The precipitation when the hotspots occur is greater than or equal to 3 mm/day and the interval for screen temperature is [297˚K, 298˚K). The association among hotspots occurrence and phy- sical environmental factors was discovered for the sup- port greater than 10% and less than 25%, and the mini- Open Access JDAIP  I. S. SITANGGANG Open Access JDAIP 96 mum confidence of 80%. Hotspots were found not far from rivers and roads where the distance of the hotspots to the nearest river and road was less than or equal to 1.5 km and 2.5 km, respectively. Areas where hotspots found are covered by plantation and thus inhabitant’s income source is plantation. In future work, we intend to investigate how negative association rules algorithms may be applied on the forest fire dataset to discover strong relations between geo- graphical objects and locations where hotspots are not probably occurred. REFERENCES [1] J. Han and M. Kamber, “Data Mining: Concepts and Techniques,” 2nd Edition, Morgan Kaufmann, 2006. [2] M. Ester, H. Kriegel, and J. Sander, “Spatial Data Mining: A Database Approach,” Proceedings of the Symposium on Large Spatial Databases, Berlin, 15-18 July 1997, pp. 47- 66. http://dx.doi.org/10.1007/3-540-63238-7_24 [3] K. Koperski and J. Han, “Discovery of Spatial Associa- tion Rules in Geographic Information Databases,” Pro- ceedings of the 4th International Symposium on Advances in Spatial Databases, Springer-Verlag, London, 1995, pp. 47-66. http://dx.doi.org/10.1007/3-540-60159-7_4 [4] A. Appice, M. Ceci, A. Lanza, F. A. Lisi and D. Malerba, “Discovery of Spatial Association Rules in Geo-Refer- enced Census Data: A Relational Mining Approach,” In- telligent Data Analysis, Vol. 7, No. 6, 2003, pp. 541-566. [5] L. Wang, K. Xieb, T. Chena and X. Mab, “Efficient Dis- covery of Multilevel Spatial Association Rules Using Par- titions,” Journal of Information and Software Technology, Vol. 47, No. 13, 2005, pp. 829-840. http://dx.doi.org/10.1016/j.infsof.2004.03.007 [6] J. Mennis and J. W. Liu, “Mining Association Rules in Spatio-Temporal Data: An Analysis of Urban Socioeco- nomic and Land Cover Change,” Transactions in GIS, Vol. 9, No. 1, 2005, pp. 5-17. http://dx.doi.org/10.1111/j.1467-9671.2005.00202.x [7] M. Berardi, M. Ceci and D. Malerba, “Mining Spatial Association Rules from Document Layout Structures,” Proceedings of the 3rd Workshop on Document Layout Interpretation and its Application, Edinburgh, 2 August 2003, pp. 9-13. [8] D. Malerba and F. A. Lisi, “Discovering Associations between Spatial Objects: An ILP Application,” Proceed- ings of the 11th International Conference on Inductive Logic Programming, Springer-Verlag, London, 2001, pp. 156-163. [9] V. Karasová, J. M. Krisp and K. Virrantaus, “Application of Spatial Association Rules for Improvement of a Risk Model for Fire and Rescue Services,” Proceedings on the 10th Scandinavian Research Conference on Geographi- cal Information Science (ScanGIS), Stockholm, 13-15 June 2005, pp. 183-194. [10] J. Niu, Y. Zhang, W. Feng and L. Ren, “Spatial Associa- tion Rules Mining for Land Use Based on Fuzzy Concept Lattice,” Proceedings of the 19th International Confer- ence on Geoinformatics, Shanghai, 24-26 June 2011, pp. 1-6. [11] P. K. R. Hilir, “Gambaran Umum Kabupaten,” 2010. http://www.rohilkab.go.id/?tampil=link&act=profil&id=4 [12] B. P. S. K. R. Hilir, “Hasil Sensus Penduduk 2010, Ka- bupaten Rokan Hilir, Data Agregat per Kabupaten/Kota,” 2010. http://sp2010.bps.go.id/files/ebook/1409.pdf [13] Fire Information for Resource Management System (FIRMS), “Frequently Asked Questions,” 2013. https://earthdata.nasa.gov/data/near-real-time-data/faq/fir ms [14] R. Agrawal and R. Srikant, “Fast Algorithms for Mining Association Rules,” Proceedings of 20th International Conference on Very Large Data Bases, VLDB, 1994, pp. 487-499. [15] R. Srikant and R. Agrawal, “Mining Quantitative Asso- ciation Rules in Large Relational Tables,” Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, 4-6 June 1996, pp. 1-12. http://dx.doi.org/10.1145/233269.233311
|