Creative Education
Vol.06 No.13(2015), Article ID:58567,9 pages
10.4236/ce.2015.613146
Computers and Language Learning
Junia Rocha1, Alexsandro Soares2, Mauro Honorato3, Luciano Lima4, Nayara Costa4, Elvio Moreira5, Eduardo Costa4
1Department of Informatics, Federal Institute of Triangulo Mineiro, Patos de Minas, Brazil
2Department of Computer Science, Federal University of Uberlandia, Uberlandia, Brazil
3Department of Informatics, Federal Institute of Sao Paulo, Barretos, Brazil
4Department of Electrical Engineering, Federal University of Uberlandia, Uberlandia, Brazil
5Department of Education, Federal University of Uberlandia, Uberlandia, Brazil
Email: juniamagalhaes@iftm.edu.br, prof.asoares@gmail.com, maurojh@gmail.com, lucianovieiralimaster@gmail.com, asc.nayara@gmail.com, elvio.esm@hotmail.com, edu500ac@gmail.com
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 30 May 2015; accepted 2 August 2015; published 5 August 2015
ABSTRACT
This paper investigates how computers together with Internet technologies help people in the learning of languages. To achieve this goal, it analyses open source libraries that a teacher can use to build educational applications. The text contains a short discussion on how to build such tools, using methods of programming proposed by Richard Stallman and Paul Graham. It also shows that computers help to improve language skills in those children with low reading abilities. Finally, it provides an overview of linguistic and computational tools that a teacher can use to check a student’s grammar. Of course, in order to build a practical grammar checker, the reader must have a working knowledge of Lisp and Prolog. In few words, the reader will not only see the magic of programs that understand English grammar, but learn how one can reproduce it.
Keywords:
Rasch Model, Natural Language Processing, Automatic Grammar Checker

1. Introduction
When one hears about computer aided language learning, she thinks immediately in Artificial Intelligence, and machines that can talk, translate all English Wikipedia entries to Esperanto, perform automatic caption, and accept speech-to-text input. Everybody knows that such intelligent applications exist, and help millions of people in their dealings with a multi-language world. Therefore a large portion of the present paper concerns Artificial Intelligence and programming. However, the greatest help that computers bring to language learning is the possibility of publishing books.
While doing graduate studies in Cornell in the seventies, one of the authors of this work dedicated himself to space science and linguistics. His main concern at the time was learning Ancient Greek. As a space scientist, he had access to good computers to perform numerical calculations. However, electronic publishing did not exist at the time, and the powerful Cray computer available to engineers was of little use for reproducing Greek documents.
In 1984, Donald Knuth made TeX available (Knuth, 1984) . TeX allowed for the typeseting of Greek books. Therefore, students could learn to read Greek by typesetting their own edition of Plato’s Republic.
With the invention of eInk, publishing a book became even easier. Now students can carry around whole libraries in a device weighting less than 200 g. While reading a book, the student can touch a word whose meaning is unknown, and get its definition in 20 languages.
Another way that computers help language learning is to connect learners to native speakers through the Internet. For instance, the authors observe that children that are learning Chinese in the United States spontaneously contact people living in China.
Computer aided language learning has two kinds of tool. Typesetting, dictionary construction and connectivity do not require Artificial Intelligence. On the other hand, automatic caption, translation and speech-to-text input require a good deal of artificial intelligence.
Let us end this section with a short discussion on programming. Students of computer science learn their trade by trying to write programs from scratch. In summary, the students open a blank buffer in a text editor like emacs and start filling it with code. Stallman (2015) thinks that such an approach is wrong. In his opinion, the student should start with an open software application, and adapt it to her needs, fix bugs and extend its functionality. To make a long story short, if the computer scientist does not start with the accumulated work of linguists and teachers, she is doomed to failure.
There are many open source tools that a language teacher can use to build parsers. The easiest of these to install and use is the open source version of RASP (Briscoe, 2015) . In order to make this conversation easier, let us introduce Nia, a fictitious female character that performs natural language processing for a living. Nia downloads and expands the archive in her work space, and runs the Makefile script in the application home directory.
~/wrk/rasp3os$ make
Since Nia has a limited knowledge of shell commands, she asks for help from Bob and Alice, who work in the Cryptography Department, as anyone familiar with the world of Computer Science fictitious characters already knows. After a few minutes, there appears the Clozure Common Lisp together with the RASP system in Nia’s machine. Nia checks what comes ready to go.

It seems that, after learning Lisp, Nia will be able to build a simple grammar checker on top of RASP.
When dealing with languages, one needs a parser. Following Stallman philosophy, the parser should be open source and written in a language that facilitates contributions from the linguist. The computer languages that satisfy this last requisite are Lisp and Prolog.
The focal point of this introductory section is that one should not start a programming project on an empty buffer. The most effective approach to programming is to build code on top of existing tools, as recommended by Richard Stallman.
2. Lisp
A small team that wants to write an educational natural language application should rely on one of the libraries available on line. However, it is a good idea to build a small prototype, in order to learn programming, and understand how libraries work.
Lisp has two features that one cannot find in other languages, and makes it specially suitable for Artificial Intelligence. For one thing, Lisp has a strong mathematical foundation. Mathematics does not become obsolete. People use books written by Gauss 200 years ago, or by Archimedes, 2000 years ago, and they are considered state of the art. Although Lisp is the oldest computer language that is widely used, the very best works in Artificial Intelligence are coded in Lisp even today. After all, Lisp has remained unchanged for decades, while generations of mathematicians and physicists add code to complex applications.
The syntax of Lisp is extremely simple: Programs and data are represented by a list of elements between parentheses. When that list represents a program snippet, the first element is an operation, i.e., a command or a function call. When a list is data, it is prefixed by a quotation mark. Let us define a small vocabulary, and a few syntax rules.

The parameter wrds represents a list of words, where each word is associated with its grammatical class. For example, cat is a noun, therefore its dictionary entry is the sublist (cat n). The grammar is written in the so called Chomsky Normal Form. The rule (npdet n) means that a noun phrase is made of a determiner followed by a noun.
Representing the dictionary and the grammar as lists means that the computer would need to loop through all entries. Loops are both inefficient and hard to code. They should be used only when necessary. Dictionary lookup must be performed with a hash table.

The above snippet creates two hashtables, that use the lisp predicate #’equal for comparison. This predicate is able to check whether two lists are equal.
To test the program, the linguist needs a text editor and a lisp. The text editor must be emacs. One can find emacs and the sbcl Lisp on the Internet.
Since Nia has already installed the RASP library, she decided to use it. A Read Eval Print Loop prompt appears on the window. Below one can see how Nia tested the program.

It seems that everything is working fine. Now Nia will write a snippet that retrieves grammar rules, and use them to rewrite an input list. Of course, with such a small vocabulary in the hash table, the input sentence must be something like the cat chases the rat.

Lisp has an extremely simple syntax: The first element of a list is the operation and the other elements are arguments. For instance, (rp s) picks the left hand side of a rule, (first s) produces the first element of s, and so on.
The nxt program repeatedly applies a function to the first element of a series until the series converges to a fixed value. Before proceeding to syntactical analysis, let us test the nxt program with a subject that is easier than natural language, something like mathematics.
The nr is the famous Newton algorithm that calculates the square root of a number. Before trying to understand it, Nia checks whether it works.
* (load "cyk.lisp")
T
* (nxt (nr 16) #'equal '(3))
(4.0 4.0000014 4.003333 4.1666665 3)
* (car '(a x b e))
a
* (cdr '(a x b e))
(x b e)
* (cons 'top '(a x b e))
(top a x b e)
It seems that it works. The series converges to the square root of 16. Function nxt finds the limit of a series by repeatedly applying a function that adds the next element of a series to the head of list s. Of course, Nia will not learn Lisp in a short paper. However, she can understand an amazing fact. One can represent almost everything with lists. Nia has seen that she can use lists to represent grammar, sentences, arithmetic series and syntactical trees. Besides this, one needs only four functions to process lists.
The car and the cdr, in the theory of algebraic data types, are called selectors. These two functions take a list apart: (car s) calculates the head of s, while (cdr s) calculates the tail, which is the remaining part of the list when its first element is removed. The (cons a s) is called constructor, and builds a list whose car is a and the cdr is s. The predicate (null s) checks whether a list is empty.
Function nxt keeps adding elements to the head of the list until an element converges to the same value as the previous one. Function fn calculates the next element of the series. Nia noticed that fn is passed as a parameter to nxt. This is necessary because this fn changes from one application to another.
Expression (nr n) builds a function that calculates the next approximation of the square root of n. Yes, Lisp functions can build other functions as easily as Python builds intergers. Lisp has two mechanisms that allow programs to build programs: closures and macros. There are two books that one can use to learn more about closures and macros. The first one was written by Paul Graham (Graham, 1993) . Nia prefers Paul Graham’s book, but the most popular one is Practical Common Lisp, by Peter Seibel (Seibel, 2005) .
Let us go back to English grammar. One can use nxt to build a series of syntactic trees that converge to the representation of a phrase.
~/wrk/rasp3os$ rlwrap bin/x86_64_darwin/ccl
Welcome to Clozure Common Lisp Version 1.8-r15286M
? (load "infix.cl")
#P"/Users/ufu/wrk/rasp3os/infix.cl"
? (load "cyk.lisp")
#P"/Users/ufu/wrk/rasp3os/cyk.lisp"
? (tree '(the cat chases the rat))
((PHRASE) (NP SV) (NP TVERB NP)
(DET N TVERB DET N)
(THE CAT CHASES THE RAT))
The function ky picks each pair of symbols and checks whether there is a grammar rule able to rewrite the pair. After reading the first and second chapter of Practical Common Lisp, the interested reader will have no problem in understanding this short program.
3. Recovering from Blind Alleys
The problem with the parser described in program cyk. lisp is that the choice of a grammar rule may lead the algorithm down a blind alley, where there is no way to backtrack from the mistake. What is worse, the deterministic cyk algorithm has no mechanism to choose a rule with high probability of success. In fact, it does not even deal with probability.
Most people implements the cyk algorithm with arrays. This paper shows a list based implementation, because one can easily add backtrack to stateless data structures such as lists. The interested reader can use the screamer library to build a backtracking version of the cyk. lisp parser.
The work that gave rise to this paper uses both probabilities and backtrack. The rule with greatest probability of success is chosen first. This point deserves a comment. Consider the following rule:
![]()
The probability of S is the product of the probability of the rule by the probabilities of the subtrees NP and SP. To overcome the problem of estimating the probabilities of NP and VP before the full expansion of the tree, one solution is to accept backtracking in case of failure. With backtracking, a rough estimation of the subtree probabilities is acceptable.
4. Assessment
The previous section states that the probability of a construction occurring is used to resolve ambiguities in the grammar formalism. The main contribution of the present paper is a method for calculating the probability of a student committing a given mistake. To unify the framework, one describes mistakes as grammar rules. For instance, there are grammar rules for the lack of agreement between the verb and its subject. Therefore, a set of rules accept a sentence like The cat chase mouses, and tags it as a mistake.
In order to estimate probabilities, the teacher needs to model the student, and assess his/her evolution. The method explained here is amply used to evaluate learning.
In any kind of measurement, there is a variable that one wants to evaluate. Variables like weight, temperature or height can be measured directly with scales, thermometers, measuring tapes, calipters, etc. Unobservable variables like skill and difficulty are not so easy to measure. One can describe such latent variables, but cannot compare them to a standard meter, since they lack physical dimensions. However, one needs to assess them to appraise student evolution.
In order to estimate the value of a latent variable, Rasch, Lord and Lazarsfeld developed independently a branch of statistics known as Measurement Theory. There is strong evidence found in Measurement Theory that leads educators to consider its superiority over classical test theory. Therefore, making it the preferred method for scoring high stake tests, like SAT.
4.1. Scales
Let us consider two students C and V. Suppose a teacher wants to discover the most common types of errors her students commit. In order to do this, one needs to compare the ability of the student in relation to a given grammatical rule.
The teacher’s best option would be to write a grammar for mistakes. Let us examine exactly what a grammar for mistakes is. A very commoner or among students of English as a Second Language is lack of agreement between subject and verb. For instance, the subject may be in the third person singular and the verb in the plural: She walk in beauty. One can write a grammar that accepts this kind of sentence, and use it to compare how often it appears in texts that two students C and V have written. Let us ignore those results where both C and V commit the same mistake or both of them avoid it.
At first glance, it may seem strange that the counter ignores when an instance of the error occurs with both students. To understand that such a procedure does not alter the distance between the two students, let us consider Table 1.
C committed this particular kind of mistake 5 times. V made the mistake 8 times. The difference is 3. If one ignores the cases where both C and V hit the mistake together, then the final count for C drops to 2, and for V is reduced to 5. The difference between them is still 3.
The probability of C committing a mistake r is given by
![]() and the probability of avoiding it can be calculated by
and the probability of avoiding it can be calculated by![]() . On the other hand, the probabilities of V committing and avoiding the mistake are given by
. On the other hand, the probabilities of V committing and avoiding the mistake are given by
![]() and
and
![]() respectively. Let
respectively. Let
![]() be the notation of how many times C stumbles upon a mistake and V avoids it. On the same token, let
be the notation of how many times C stumbles upon a mistake and V avoids it. On the same token, let
![]() denote the number of times that C makes a mistake and V stays away from it. The ratio between
denote the number of times that C makes a mistake and V stays away from it. The ratio between
![]() and
and
![]() is given below
is given below
![]()
4.2. Specific Objectivity
One can say that C is more prone to mistakes than V if the rate
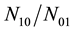 does not change with the kind of mistake. This property is called specific objectivity and when it holds, one has the equality below.
does not change with the kind of mistake. This property is called specific objectivity and when it holds, one has the equality below.

Odds is the ratio of the probability of an event occurring to the probability of it not occurring. One can rewrite this equality in order to obtain the odds of C committing the mistake r

4.3. Origin
The next step is to choose the origin for the measurement scales that one intends to introduce. Let us consider a

Table 1. VS agreement, where 1 represents a mistake.
student o whose tendency to make mistakes matches the easiness of anitem o. In this case, the student will stumble upon the mistake in half of the trials, and the error will fail to defeat the student for the other half. This student is said to be at the origin of the inability scale, and the item is at the origin of the easiness scale. Since the student commits the mistake half of the times, the probability of failure is . Let us compare C with the student of the origin.
. Let us compare C with the student of the origin.

Since
 is 0.5 one has that
is 0.5 one has that . Therefore
. Therefore

Let’s take the logarithm from both sides of this equation



If one defines


The equation becomes:

Notice that
 does not depend on the grammar rule r and
does not depend on the grammar rule r and
 does not depend on the student c. This finding is the greatest contribution made by Georg Rasch to the Measurement Theory
(Wright & Mok, 2004)
.
does not depend on the student c. This finding is the greatest contribution made by Georg Rasch to the Measurement Theory
(Wright & Mok, 2004)
.
The definition of the logarithm yields the following expression for the odds of committing a given mistake:




One often refers to parameters
 and
and
 as an individual’s inability and an item easiness respectively.
as an individual’s inability and an item easiness respectively.
4.4. Calibration
In the previous section, the reader saw that probability depends on parameters like easiness and inability. Calibration is thus the process of determining these parameters. To meet this goal, an iterative algorithm must force raw data onto the logistic curve.
The first step of the iteration calculates row and column averages to estimate initial easiness and inability vectors for the data matrix Xn.

The next step is to adjust the easiness vector by subtracting the average from each element. The function probability calculates the odds, and stores its value in a two dimensional array.

In order to update the inability and easiness vectors,one must calculate the residual between the current andthe previous probability matrix.

Now, one needs to calculate the variance of the probability matrix.

After summing up the residual and variance for each of the two dimensional arrays along each row, one is ready to update the easiness and inability vectors. These steps must be repeated until the sum of the squares of the residuals becomes sufficiently small.

The calibration algorithm produces Table 2 containing the probabilities of each student committing a given mistake.
5. Conclusion
The authors are convinced that natural language processing has reached a stage that makes building of automatic grammar checking possible. Another interesting application of these new technologies is the construction of models that facilitate the planning of grammar drilling. The abstract of the present paper was written by a
Table 2. Probabilities.
person with limited knowledge of English, and corrected by natural language processing tools. The reader will find the original text below.
This paper investigates how computers and communication can help people in learning languages. The authors will present both tools developed by themselves and by third parties. The text contains a short discussion on how to build such tools, using methods of programming proposed by Richard Stallman and Paul Graham. A longitudinal survey that the authors performed along three decades shows how computers improved the language learning environment. This article will provides enough information about linguistic and libraries for the reader building a program able to check of English prose composition. Of course, in order to build a practical grammar checker, the reader must have a working knowledge of Lisp and Prolog. In fewer words, this article intends not only to show the magic of programs that understand English grammar, but reveal how one can reproduce the effects.
Cite this paper
JuniaRocha,AlexsandroSoares,MauroHonorato,LucianoLima,NayaraCosta,ElvioMoreira,EduardoCosta, (2015) Computers and Language Learning. Creative Education,06,1456-1465. doi: 10.4236/ce.2015.613146
References
- 1. Briscoe, T., Buttery, P., Carroll, J., Medlock, B., Watson, R. Andersen, O., & Parish, T. (2015). RASP, a Robust Parsing System for English. Cambridge: iLexIR.
http://users.sussex.ac.uk/~johnca/rasp/ - 2. Graham, P. (1993). On LISP: Advanced Techniques for Common LISP. Upper Saddle River, NJ: Prentice Hall.
- 3. Knuth, D. E. (1984). The TEXbook. New York: Addison-Wesley Professional.
- 4. Seibel, P. (2005). Practical Common Lisp. New York: Apress.
http://dx.doi.org/10.1007/978-1-4302-0017-8 - 5. Stallman, R. (2015). The Best Way to Learn Programming.
https://www.youtube.com/watch?v=dvwkaHBrDyI - 6. Wright, B. D., & Mok, M. M. C. (2004). An Overview of the Family of Rasch Measurement Models in Introduction to Rasch Measurement (pp. 1-24). Maple Grove: JAM Press.