R. SHARMA, V. P. PYARA 465
will not be maximum, hence denoising will not be the
best. Maximum PSNR value for shehnai sound is at level
5 with db10 wavelet, dafli at level 5 with dmey and flute
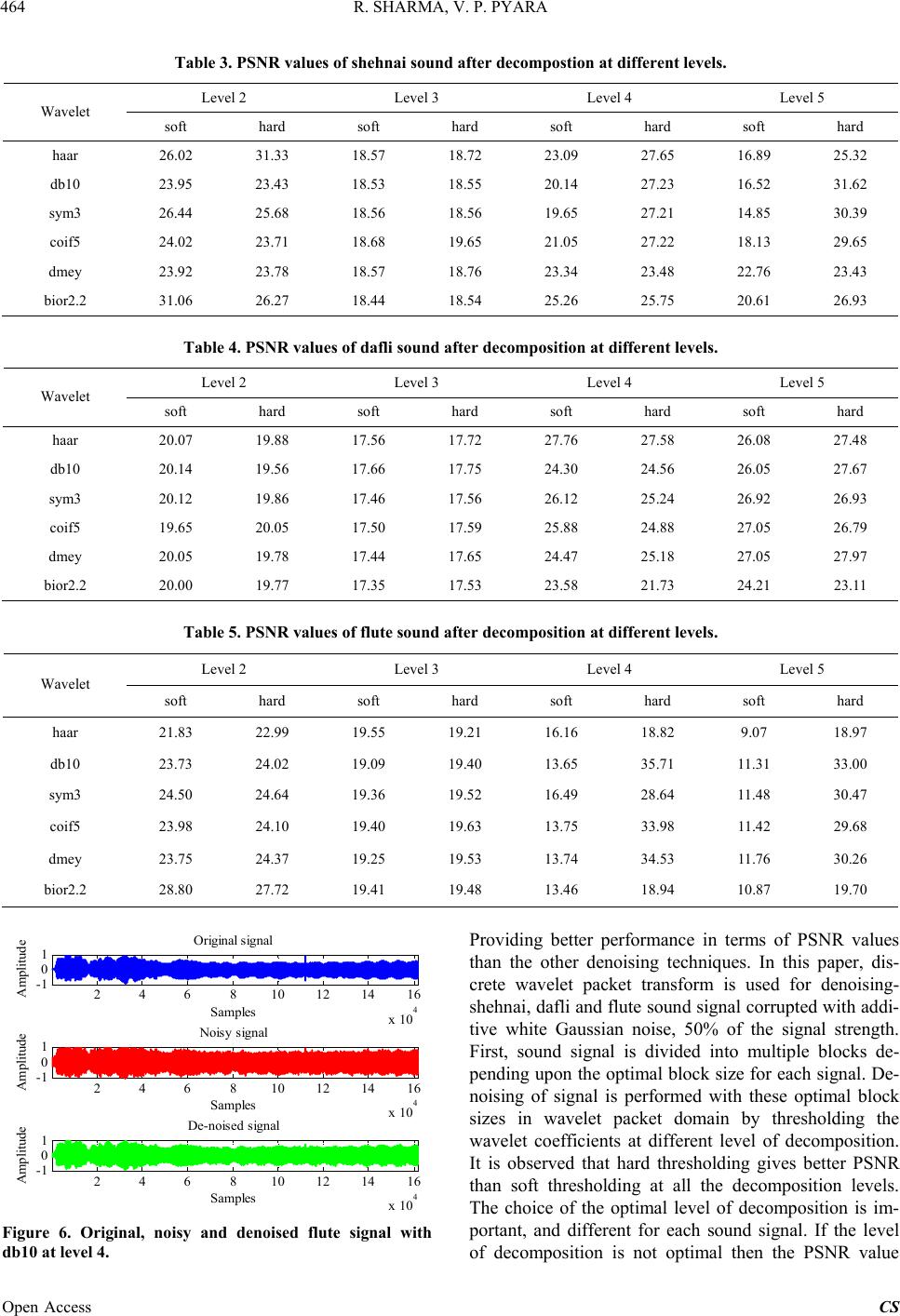
at level 4 with db10 respectively. When each block is
denoised, all the blocks are concatenated to form the fi-
nal denoised signal. It is also observed that when modi-
fied threshold with is used, the PSNR values are in-
creased. Higher thresholds remove the noise well but
some parts of the original signal are also removed be-
cause it is not possible to remove the noise without af-
fecting the original signal.
REFERENCES
[1] M. Lang, H. Guo, J. E. Odegard, C. S. Burrus and R. O.
Wells, “Noise Reduction Using an Undecimated Discrete
Wavelet Transform,” IEEE Signal Processing Letters,
Vol. 3, No. 1, 1996, pp. 10-12.
[2] J. Yang, Y. Wang, W. Xu and Q. Dai, “Image and Video
Denoising Using Adaptive Dual Tree Discrete Wavelet
Packets,” IEEE Transaction on Circuit and Systems for
Video Technology, Vol. 19, No. 5, 2009, pp. 642-655.
[3] B. J. Shankar and K. Duariswamy, “Wavelet Based Block
Matching Process: An efficient Audio Denoising Tech-
nique,” European Journal of Scientific Research, Vol. 48,
No. 1, 2010, p. 16.
[4] R. Sharma and V. P. Pyara, “A Novel Approach to Syn-
thesize Sounds of Some Indian Musical Instruments Us-
ing DWT,” International Journal of Computer Applica-
tions, Vol. 45, No. 13, 2012, pp. 19-22.
[5] R. Sharma and V. P. Pyara, “A Comparative Analysis of
Mean Square Error Adaptive Filter Algorithms for Gen-
eration of Modified Scaling and Wavelet Function,” In-
ternational Journal of Engineering Science and Technol-
ogy, Vol. 4, No. 4, 2012, pp. 1396-1401.
[6] J. Yu and D. C. Liu, “Thresholding Based Wavelet Packet
Methods for Doppler Ultrasound Signal Denoising,” IF-
MBE Proceedings Springer Verlag Berlin Heidelberg, Vol.
19, No. 9, 2008, pp. 408-412.
[7] T. Mourad, S. Lotfi and C. Adnen, “Spectral Entropy
Employment in Speech Enhancement Based on Wavelet
Packet,” International Journal of Computer and Informa-
tion Engineering, Vol. 1, No. 7, 2007, pp. 404-411.
[8] N. S. Nehe and R. S. Holambe, “DWT and LPC Based
Feature Extraction Methods for Isolated Word Recogni-
tion,” EURASIP Journal of Audio, Speech and Music Pro-
cessing, Vol. 7, No. 1, 2012, pp. 1-7.
http://dx.doi.org/10.1186/1687-4722-2012-7
[9] D. Kwon, M. Vannucci, J. J. Song, J. Jeong and R. M.
Pfeiffer, “A Novel Wavelet Based Thresholding Method
for the Pre-Processing of Mass Spectrometry Data That
Accounts for Heterogeneous Noise,” Proteomics, Vol. 8,
No. 15, 2008, pp. 3019-3029.
[10] Y. Ren, M. T. Johnson and J. Tao, “Perceptually Moti-
vated Wavelet Packet Transform for Bio-Acoustic Signal
Enhancement,” Journal of Acoustic Society of America,
Vol. 124, No. 1, 2008, pp. 316-327.
[11] K. Ramchandran and M. Vetterli, “Best Wavelet Packet
Bases in a Rate-distortion Sense,” IEEE Transaction on
Image Processing, Vol. 2, No. 2, 1993, pp. 160-175.
[12] D. L. Donoho and I. M. Johnstone, “Adapting to Un-
known Smoothness via Wavelet Shrinkage,” Journal of
the American Statistical Association, Vol. 90, No. 432,
1995, pp. 1200-1224.
[13] S. G. Chang, B. Yu and M. Vetterli, “Adaptive Wavelet
Thresholding for Image Denoising and Compression,”
IEEE Transaction on Image Processing, Vol. 9, No. 9,
2000, pp. 1532-1546.
[14] J. Berger, R. R. Coifman and J. G Maxim, “Removing
Noise from Music Using Local Trigonometric Bases and
Wavelet Packets,” Journal of The Audio Engineering So-
ciety, Vol. 42, No. 10, 1994, pp. 808-818.
[15] M. T. Johnson, X. Yuan and Y. Ren, “Speech Signal En-
hancement through Adaptive Wavelet Thresholding,” Speech
Communication, Vol. 49, No. 2, 2007, pp. 123-133.
Open Access CS