C. Z. PIAO ET AL. 105
Here j is the level number of the tree and N is the
number of antennas of the transmitter and the receiver.
The nodes of the tree store the information of the partial
solutions in order to find the op timal solution. Th e squ are
of the Euclidean distance, namely , is cal-
culated by computing partial Euclidean distance (PED)
for each level j, i.e.
(13)
Obviously (14)
3.2. Depth-First SD
The Depth-First Sphere Decoding algorithms contain
forward and backward directions of searching the tree. It
is carried out as below:
1) Set a large number as optdist (distance of the opti-
mal solution);
2) Go forward to the first leaf of the tree;
3) Calculate the lowest distance of the nodes expanded
by the same node with the leaf to update the optdist;
4) Go back to the former level and try the next node; if
the end of nodes is reached, continue this step until there
is a node available; if no such node exists, go to step 7.
5) If the PED of the node is larger than optdist, then go
to step 4; else expand the node and go to step 6;
6) If the leaf is reached, go to step 3; else go to step 5.
7) Choose the solution whose PED is optist as the op-
timal solution.
3.3. Fixed K-Best SD
Compared with exhaustive search, K-Best SD uses
Breadth-First Search (BFS). BFS only allows forward
direction and the information of nodes at current level
will be kept before the nodes are expanded. K-Best algo-
rithm keeps only K nodes at each level. Let j be the level
number. The procedure of the algorithm is:
1. Let j = N;
2. Calculate the PEDs of all nodes at level j expanded
by the former level and choose smallest
ones, where is the number of nodes at level j;
3. Expand the chosen nodes, and ;
4. If , go to step 2; else go to step 5;
5. Choose the smallest PED as the optimal solution.
4. Dynamic K-Best Algorithm
The fixed K-Best SD may bring extra complexity because
for some cases the PEDs are more likely to be near the
ML solution while for other cases they are low. So a
method able to adjust the value of K according to how
likely it is for the partial solution to be identical to the
ML solution is proposed. It is called Dynamic K-Best
algorithm.
If the noise of the optimal solution is small, the PEDs
of the solutions keeps unchanged, the PED difference
between the optimal solution and the other solutions will
be larger. A method adjusting th e number K according to
the difference between the PEDs of the optimal solution
and the suboptimal solution is feasible.
For some cases where the differences are large, in oth-
er words, the partial solution is more likely to ap- proach
the ML solution, the value of K will be decreased in or-
der to reduce the number of visiting nodes. Similarly, for
other cases when the difference is small, the value of K
will be increased to ensure the accuracy. The mathe-
matical description of the algorithm is:
1. Give a set of thresholds [a, b, c] (a < b < c) to each
level;
2. Calculate the PEDs of the optimal and suboptimal
solutions and .
3. Let K = if [0, a];
else K = if (a, b];
else K = if (b, c];
else K = ;
go to step 3;
4. Keep K survivor nodes with the smallest K dis-
tances and expand them and ;
5. If , go to step 2;
else go to step 5;
6. Find the solution with the smallest distance as the
optimal solution .
5. Simulation Result
In this section, the BER performance and complexity of
the Dynamic K-Best SD, compared with the conventional
K-Best SD (K=16), are assessed. It is assumed that our
simulation is based on a 4×4 MIMO system with
16QAM or 64QAM through a flat Rayleigh fading
channel, and [,,,] is assigned [8,4,12, 16].
Figures 1 and 2 are drawn when 16QAM is applied.
Figure 1 shows the BER performance of the Dynamic
K-Best SD as well as the conventional K-Best SD. It is
obvious that in Figure 1 the interval between the two
curves is almost negligible. By selecting appropriate
threshold values of each level, the rates of BER increased
approximately are 8.94%, 8.06%, 6.44%, 9.09%, 8.96%
and 6.25% when SNR (dB) equals 0, 2, 4, 6, 8 and 10
respectively. All of the rates of BER increased by Dy-
namic K-Best SD are less than 10%, which means prac-
tically the deterioration of BER can be igno red.
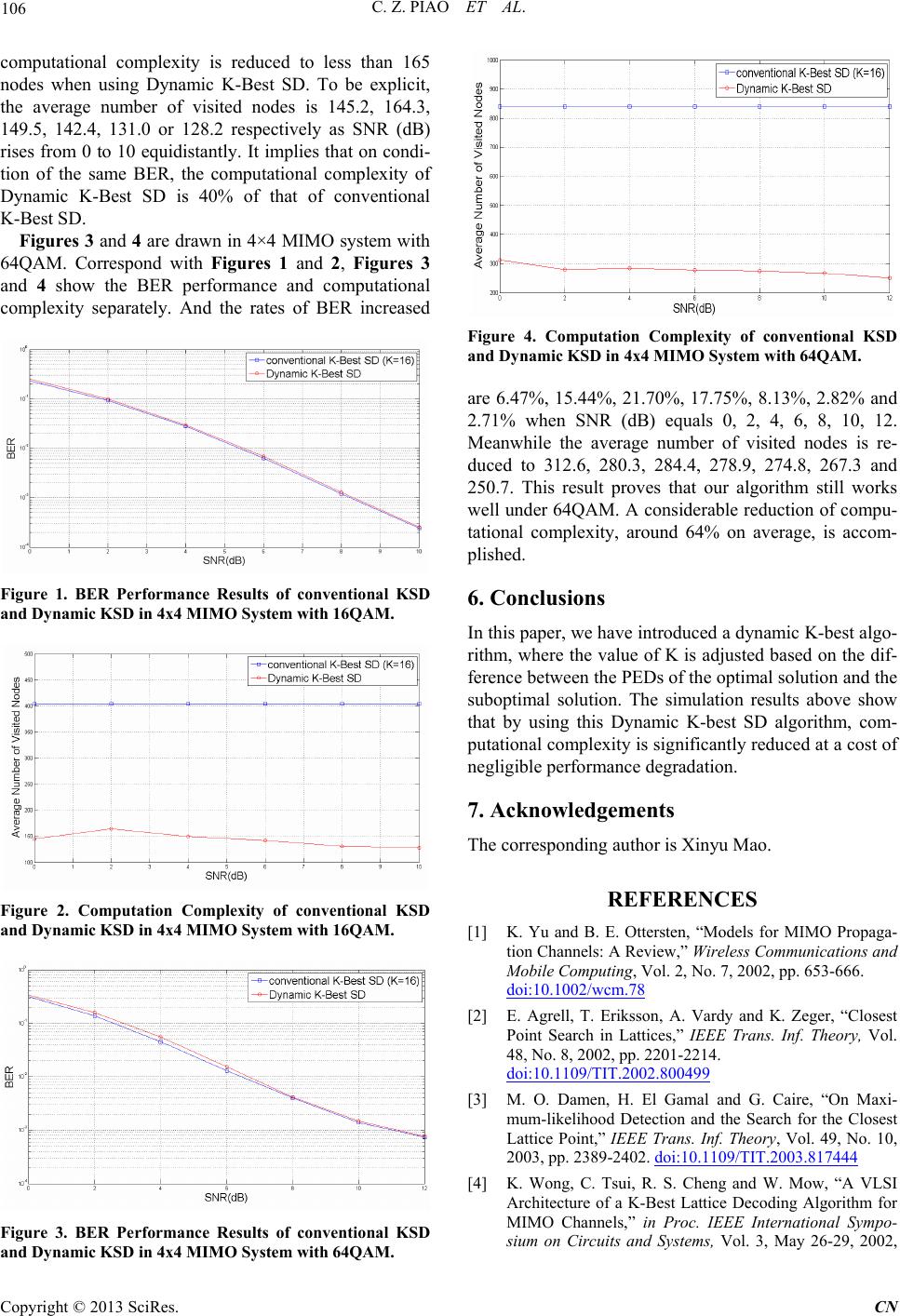
The computational complexity is characterized by the
average number of nodes visited in searching tree in this
paper. In Figure 2, it is concluded that compared with
404 nodes when using the conventional K-best SD, the
Copyright © 2013 SciRes. CN