X. F. LIU ET AL. 87
AI researchers typically use MDPs to formulate prob-
abilistic planning problems. An MDP is defined as a
four-tuple<S,A,T,C>, where S is a discrete set of states,
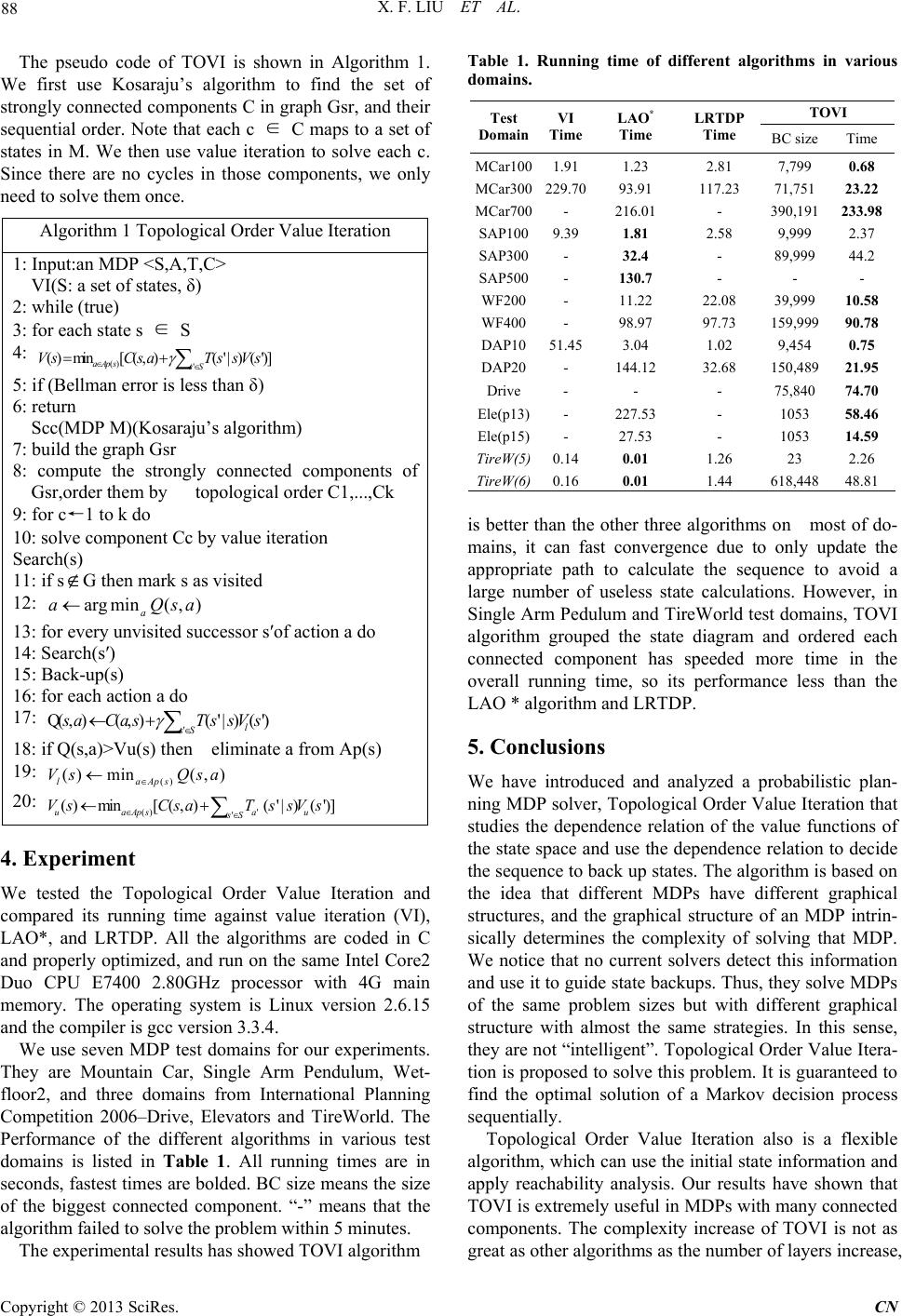
A is a finite set of all applicable actions, T is the transi-
tion matrix describing the domain dynamics, and C de-
notes the cost of action transitions. The agent executes its
actions in discrete time steps called stages. At each stage,
the system is at one distinct states ∈S. The agent can
pick any action a from a set of applicable action Ap(s)
⊆A, incurring a cost of C(s, a). The action takes the sys-
tem to a new state s′ stochastically, with probability Ta
(s′|s) .
The horizon of an MDP is the number of stages for
which costs are accumulated. There are a set of sink goal
states G⊆S, reaching which terminates the execution. To
solve the MDP we need to find an optimal policy (S→A),
a probabilistic execution plan that reaches a goal state
with the minimum expected cost. Any optimal policy
must satisfy the following system of Bellman equations,
the value function of a policy π is defined as:
'
()(,())('| )('),[0,1]
sS
Vs CssTssVs
*
(1)
and the optimal value function is defined as:
*
() '
()min[(, )('| )(')],[0,1]
aAs sS
VsCsa TssVs
(2)
2.2. Dynamic Programming
Most optimal MDP algorithms are based on dynamic
programming. Its usefulness was first proved by a simple
yet powerful algorithm named value iteration [10].Value
iteration first initializes the value function arbitrarily. Its
basic idea is to iteratively update the value functions of
every state until they converge. And in each iterm, the
value function is updated according to Equation 2. We
call one such update a Bellman backup. The Bellman
residual of a state s is defined to be the difference be-
tween the value functions of s in two consecutive itera-
tions. The Bellman error is defined to be the maximum
Bellman residual of the state space. When this Bellman
error is less than some threshold value, we conclude that
the value functions have converged sufficiently.
The main drawback of the value functions algorithm is
that, and in each iterm, the value functions of every state
are updated, which is highly unnecessary. Firstly, some
states are backed up before their successor states, and
often this type of backup is fruitless. Secondly, different
states converge with different rates. When only a few
states are not converged, we may only need to back up a
subset of the state space in the next iteration.
3. Topological Order Value Iteration
We have studied the sequence of state backups according
to an MDP’s graphical structure, which is the intrinsic
property of an MDP and potentially decides the com-
plexity of solving it [11]. Our first observation is that
states and their value functions are causally related. If in
an MDP M, one state s′ is a successor state of s after ap-
plying action a, then V (s) is dependent on V (s′). For this
reason, we want to back up s′ ahead of s. The causal rela-
tion is transitive.
Topological Order Value Iteration solves an MDP
problem by using the problem’s graphical structure
wisely. Given an MDP, TOVI first builds a directed rea-
chability graph Gsr, where G has one vertex per state s
∈ S. A directed edge from vertex s1 to s2 exists if there
is an action such that Ta (s2|s1) > 0. TOVI then finds all
the strongly connected components of Gsr, and the topo-
logical order of the components. Then, it solves every
connected component individually, by value iteration,
according to their topological order. Figure 1 shows the
graphical representation of one simple MDP that has 7
states and 12 actions. In the figure, successors of prob-
abilistic actions are connected by an arc. For simplicity
reason, transition probabilities Ta and costs C(s, a) are
omitted. Using TOVI, we can divide the MDP into two
connected components C1 and C2. Based on the remain-
ing actions, C1 and C2 can be subdivided into three and
two smaller components respectively. By decomposing
an MDP into smaller components, TOVI’s convergence
can be much faster than VI.
We use Kosaraju’s algorithm of detecting the topo-
logical order of strongly connected components in a di-
rected graph [12]. Note that Bonet and Geffner used Tar-
jan’s algorithm in detection of strongly connected com-
ponents in a directed graph in their solver [5], but they do
not use the topological order of these components to sys-
tematically back up each component of an MDP. Kosa-
raju’s algorithm is simple to implement and its time
complexity is only linear in the number of states, so
when the state space is large, the overhead in ordering
the state backup sequence is acceptable. Our experimen-
tal results also demonstrate that the overhead is well
compensated by the computational gain.
Figu re 1. A simplified MDP and its set of strongly conne cted
components.
Copyright © 2013 SciRes. CN