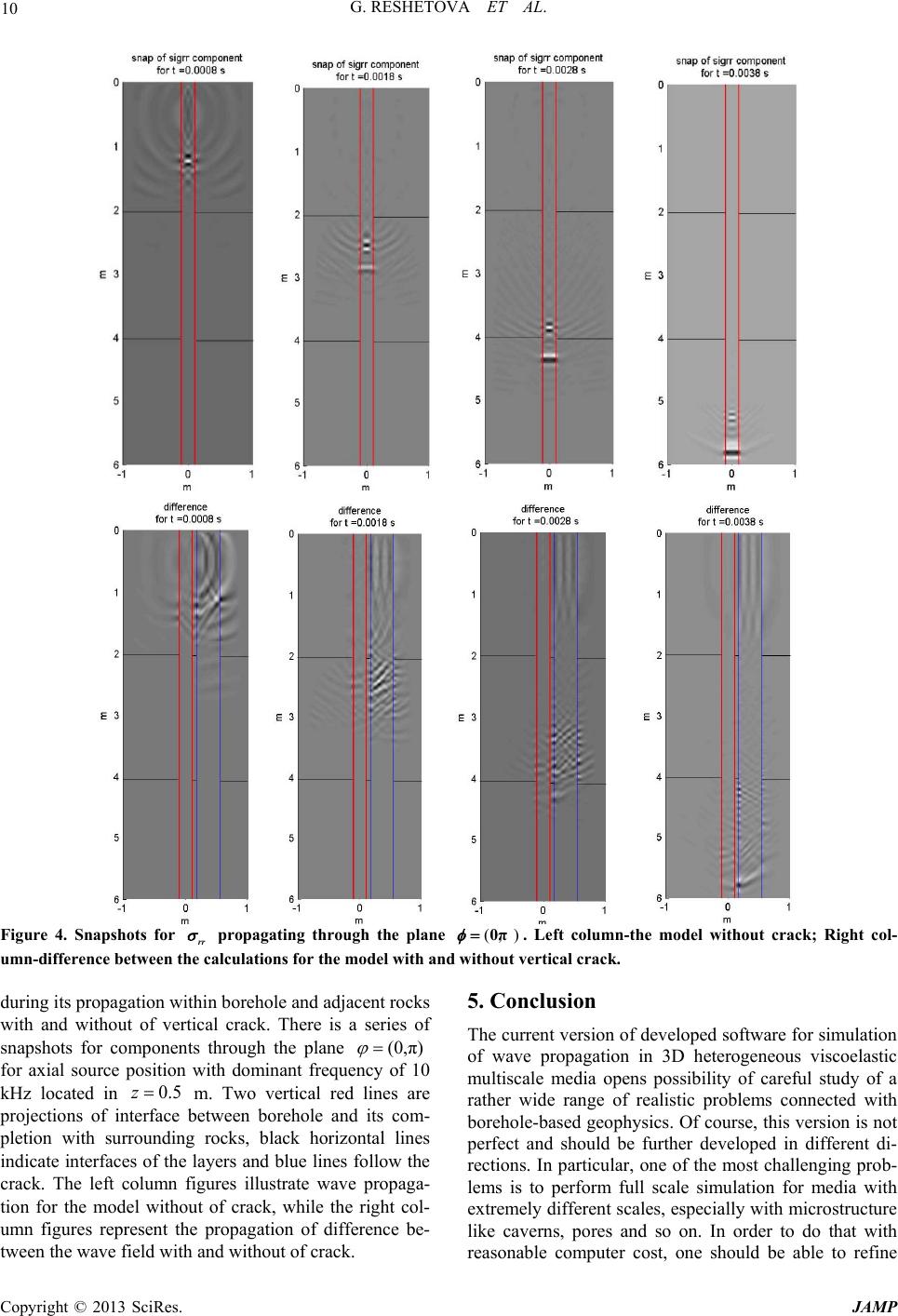
G. RESHETOVA ET AL.
Copyright © 2013 SciRes. JAMP
meters. Taking this into account we slice the total 3D
model into a number of disc-like subdomains Ω. Finite
difference scheme assumes communication between
neighboring processors requiring them to exchange func-
tion values on the interfaces between elementary discs.
It should be noted that DD on the base of this rather
simple geometry easily provides possibility to guarantee
uniform load of Processor Units involved in computa-
tions. Another advantage of the chosen DD is in ex-
tremely small portions of data PU should interchange at
each time step and, so, extremely small waiting period
before computation on the next time step would be done.
The MPI (Message Passing Interface) library is applied
for arranging the above-mentioned send/receive proce-
dures and special efforts are paid in order to minimize
idle time of Processor Units due to the data exchange. In
order to provide this we start computations for each sub-
domain from its interior widening them towards inter-
faces and use non-blocking functions Isend and Ireceive
in order to arrange data exchange between neighboring
PU.
Special attention was paid to analysis of effectiveness
and scalability of this approach. This analysis was per-
formed by the series of numerical experiments performed
on the cluster HKC-160 (Siberian Supercomputer Center,
Novosibirsk) made of 80 computation modules (hp Inte-
grity rx1620 with two PU Intel Itanium 2, each of 1.6
Ghz, 3 Mb cache, 4 Gb RAM) connected via 24-port
commutator InfiniBand (10 Gbot, Cluster Interconnect).
Peak performance of the cluster is about 1 Tflop/s.
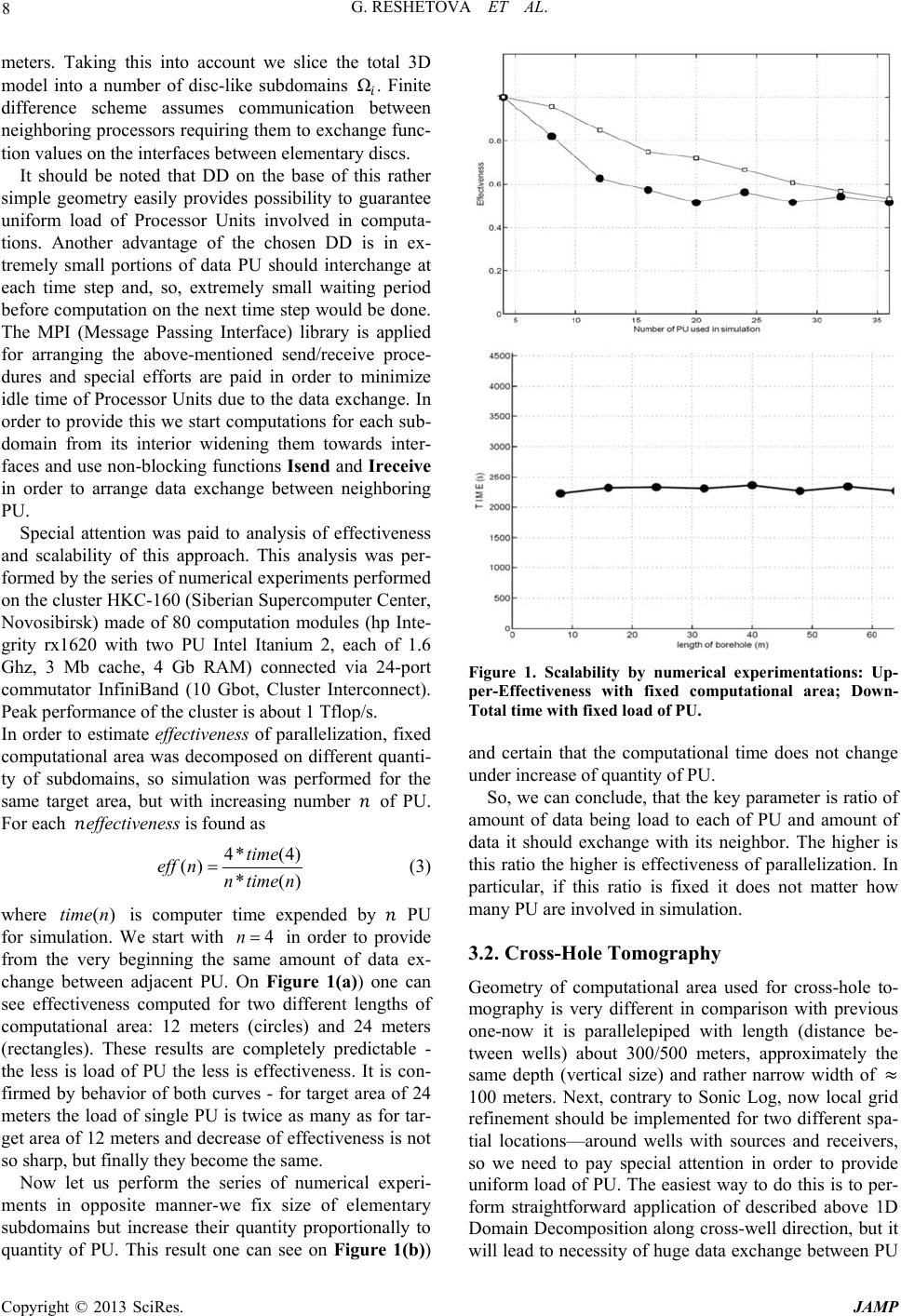
In order to estimate effectiveness of parallelization , fixed
computational area was decomposed on different quanti-
ty of subdomains, so simulation was performed for the
same target area, but with increasing number of PU.
For each effectivenes s is found as
4* (4)
() * ()
time
eff nntime n
=
(3)
where
is computer time expended by PU
for simulation. We start with
in order to provide
from the very beginning the same amount of data ex-
change between adjacent PU. On Figure 1(a)) one can
see effectiveness computed for two different lengths of
computational area: 12 meters (circles) and 24 meters
(rectangles). These results are completely predictable -
the less is load of PU the less is effectiveness. It is con-
firmed by behavior of both curves - for target area of 24
meters the load of single PU is twice as many as for tar-
get area of 12 meters and decrease of effectiveness is not
so sharp, but finally they become the same.
Now let us perform the series of numerical experi-
ments in opposite manner-we fix size of elementary
subdomains but increase their quantity proportionally to
quantity of PU. This result one can see on Figure 1(b))
Figure 1. Scalability by numerical experimentations: Up-
per-Effectiveness with fixed computational area; Down-
Total time with fixed load of PU.
and certain that the computational time does not change
under increase of quantity of PU.
So, we can conclude, that the key parameter is ratio of
amount of data being load to each of PU and amount of
data it should exchange with its neighbor. The higher is
this ratio the higher is effectiveness of parallelization. In
particular, if this ratio is fixed it does not matter how
many PU are involved in simulation.
3.2. Cross-Hole Tomography
Geometry of computational area used for cross-hole to-
mography is very different in comparison with previous
one-now it is parallelepiped with length (distance be-
tween wells) about 300/500 meters, approximately the
same depth (vertical size) and rather narrow width of ≈
100 meters. Next, contrary to Sonic Log, now local grid
refinement should be implemented for two different spa-
tial locations—around wells with sources and receivers,
so we need to pay special attention in order to provide
uniform load of PU. The easiest way to do this is to per-
form straightforward application of described above 1D
Domain Decomposition along cross-well direction, but it
will lead to necessity of huge data exchange between PU