Paper Menu >>
Journal Menu >>
 Engineering, 2 http://dx.doi.or g Copyright © 2 0 Emo t ABSTRA C The synthesis and so on. In Ti me D o ma i n synthesized s p p osed emotio n al expression . speech uttera n Keywords: E m 1. Introdu c The modern s of application could conduc t virtual agent speech synth e or children’s t thesizer coul d lost the use speech synth e form) from t e a totally natu r drawbacks e x with emotion s man commun munication i could not exp r al speech sy n synthesized s speech. Two majo r dominate the l tive synthesi s speech data acoustic corr e man speech r tion category a adapted [2] t o 013, 5, 73-77 g /10.4236/eng. 2 0 13 SciRes. t ional S 1 School 2 School o C T of emotional this wor k, an n Pitch Synchr o p eech with fo u n al speech sy n . The subject i n ces. m otional Spe e c tion s peech synthe s s. In the call- c t dialogues w i devices cou l e sis technique s t oys. In the m d even be use of their voi c e sizers could p e xt. However, r al way as a h u x isting is that t s . Emotion ex p ication, an ef f s virtually i m r ess or unders n thesis aims t s peech to pr o r approaches t o l iterature: for m s [1]. Forman t entirely base e lates of the s p ecordings. Ac a re derived fr o o create a sig n 2 013.510B015 P S peech Lin g of Electrical E n o f Electrical an d Email: l speech has wi emotional spe o nous OverLa p u r types of em n thesis system i ve test reach e e ch Synthesis; s is system ha s c enters, the sp e i th customers. l d read loud s , such as in t h m edicine field, d to speak fo c e. The majo r p roduce voice few machine s u man being. O t he machines c p ression is a v f ective human - m possible w i tand affection t o add huma n o duce more n o emotional s p m ant synthesi s t synthesis ge n d on rules s u p eech and doe s oustic profile s o m the literatu r n al. In 1989, P ublished Onlin e Synthe Mo d g He 1 , Hua H n gineering and I n d Computer En g l ing.he@scu.ed u Receive d de applicatio n ech synthesis p Add (TD-P S otion: angry, h achieves a go o e s high classi Prosodic Feat u s a wide varie t e ech synthesiz The intellige n to users usi n h e video gam e the speech sy n r sufferers w h r ity of mode r (acoustic wav s can “speak” i O ne of the maj o c ould not spe a v ital part in h u - to-human co m i thout speak e s. The emotio n n emotions in t n atural affecti v p eech synthe s and concaten n erates acous t u rrounding t h s not utilize h u s for each em o r e and manual Jenet Cahn [ 3 e October 2013 e sis Bas e d ificati o H uang 1 , Ma r n formation, Sic h g ineering, RMI T u .cn, margaret.l d November 20 n s in the field o system is pro p S OLA) wavef o h appy, sad an d o d performan c fication accu r u res; Time D o t y er n t n g e s n - h o r n e- in o r a k u - m - e rs n - t o v e s is a- t ic h e u - o - l y 3 ] imple m using a researc h [4]. De tic par a thesis i has an tenativ e er to g e ances a variety speech solve t h sodic s smalle r types o speech ramete r of spe e catenat chrono u In t h p ropos e TS-PS O 2. E m In this speech (http://www.sc i e d on P o n r garet Lech 2 h uan Universit y T University, M e ech@rmit.edu. a 12 o f human-co m p osed based o n o rm concatena d bore d . The e c e. The produ c r acy for diffe r o main Pitch S y m ented the s y a formant sy n h es have b ee n spite of the hi a meters provi d i s not widely unnatural, m e e synthesis [5 ] e nerate the sy n a re more nat u of emotions, database to b u h is problem, s s trategies into r number of s p o f emotion c o through mod i r s (like the fu n e ch contour), a ive approach e u s OverLap A h is work, an e m e d based on O LA concate n m otional Sp e work, a pro s synthesis sys t rp.org/journal/ e P rosodi c y , Chengdu, Chi n e lbourne, Austr a a u m puter interact i n prosodic f ea t tive algorith m e xperiment res u c ed utterances r ent types of s y nchronous O v y nthesized em n thesis syste m n done using t h gh degree of c d ed in this te c applied, sinc e e chanical sou n ] joins recordi n n thetic speech u ral. Howeve r the system re u ild a selecti n s everal resear c unit selectio n p eech corpor a o uld be adde d i fying corresp o n damental fre q n d then apply i e s, such as th e dd) algorithm m otional spee c prosodic fea t n ative synthesi s e ech S y nth e s odic modific a t em is propos e e ng) c Feat u n a a lia i on, medicine, t ures modific a m . The system p u lts show that present clear e s ynthesized e m v erlap Ad d otional speec h m . After then , h e formant sy n c ontrol over t h c hnique, for m e the resultin g n d. In contras t n gs of a hum a . The generati n r , in order to quires a large n g units pool [ c hers incorpo r n [10,11]. In t h a is required. D d into the sy n o nding to aco u q uency, or the i ng the wavef o e PSOLA (Pi t [12]. c h synthesis s t ure modifica t s method. e sis S y stem a tion based e m e d. The block ENG u re industry a tion and p roduces the pro- e motion- m otional h firstly , several n thesizer h e acous- m ant syn- g speech, t , conca- a n spea k - n g utte r - produce r size of [ 6-9]. To r ate pro- h is way, D ifferent n thesized u stic pa- duration o rm con- t ch Syn- s ystem is t ion and m otional diagram  L. HE ET AL. Copyright © 2013 SciRes. ENG 74 is illustrated in Figure 1. In the experiment, the speech utterances, which are selected from emotional speech database with four dif- ferent types of emotion: angry, happy, sad and bored, are divided into a set of units. For the concatenative speech synthesis, there are various possible choices for the type of unit, the most popularly used types include words, syllables, phonemes, demi-syllables and diphones. The speech unit is the basic synthesis building block. It is known that when the length of unit goes longer, the ef- fect of context decreases and the quality of resulting synthesized speech increase. Considering the size of speech database, in this work, the chosen concatenative unit is word. For the segmented un its, the prosod ic an aly- sis is applied to calculate the pitch, energy and duration rules. The length of silence is also calculated to decide the pause assignment. The prosod ic feature templates for different types of emotion are then built up using the estimated parameters. In the next step, for the neutral input speech, the ut- terances are segmented into units (word ) firstly. Then the prosodic features are extracted for each unit, and mod- ified according to the prosodic feature templates which are built in the previous step, with the corresponding emotion type. At last, the time-domain pitch synchronous overlap add (TS-PSOLA) concatenative synthesis me- thod is used to smooth and modify unit boundary, and to produce the final synthesized emotional speech. 3. Speech Database The publicly available Berlin emotional speech (BES) database [13] is used in this work, for the purpose of comparison with other experiments. In the construction of the database, the text materials are carefully chosen to achieve natural emotion arousal. 10 sentences (5 short and 5 long sentences) frequently used in everyday com- munication are selected. The speech utterances are pro- duced by ten actors (5 female and 5 male). A total of 248 emotional recordings are selected in this work, with four different types of emotion: angry, happy, sad and bored, to build up the emotion al prosodic feature templates. For the emotion “angry”, it is a short clipped speech, with one word or syllable being more strongly stressed. For the emotion “happy”, the voice tone is high pitched, speech is faster or louder than usual. Under “sad” emo- tional state, a person tends to speak slowly, and use a low Figure 1. Block diagram of emotional speech synth esis. voice tone. For the emotion “bored”, the voice tone is cold and dull. For each emotion, the number of record- ings is 62. The sampling frequency for the data is 16 kHz. In addition, 40 speech recordings under neutral state are used for testing. A neutral voice tone is even, relaxed, without marked stress on individual syllables. For each neutral speech, four synthesized utterances are produced with emotion type of angry, happy, sad and bored. 4. Prosodic Feature s Calculation In this work, three prosodic features are extracted: fun- damental frequency, energy and time duration. 4.1. Calculation of Fundamental Frequency As illustrated in Figure 2, the fundamental frequency F0 of vocal folds vibration is estimated simultaneously in the time domain using the autocorrelation method [13], and in the frequency domain using the cepstral method [13]. The average value of these two measurements pro- vides the final estimate of F0. The frequency domain cepstrum method of the F0 es- timation looks for a periodicity in the log spectrum of the signal; if the log amplitude spectrum contains many reg- ularly spaced harmonics, then the Fourier analysis of the spectrum is expected to show a peak corresponding to the spacing between the harmonics: i.e. the fundamental frequency. The time domain autocorrelation method, on the other hand, estimates the fundamental frequency directly from the waveform using the autocorrelation function which is expect to show peaks at delays corresponding to mul- tiples of the glottal wave period (1/F0). The autocorrela- tion is calculated as: )()()( 1 0 kjsjskR m kN jmm += −− = (1) where s is the speech signal. 4.2. Calculation of Energy Speech utterance is a non-stationary signal. However, it could be viewed as a stationary signal in a short-time roughly ranging between 16 ms and 32 ms. In the experiment, the short-time energy is calculated Figure 2. A flowchart of the fundamental frequency estima- tion method. Spectrum Log-Spectrum DFT of Log-SpectrumPeak Location Autocorrelation Peak Location F 0 Voiced Frame F0estimation in the time domain F0estimation in the frequency domain Averag i ng Spectrum Log-Spectrum DFT of Log-SpectrumPeak Location Autocorrelation Peak Location F 0 Voiced Frame F0estimation in the time domain F0estimation in the frequency domain Averag i ng  L. HE ET AL. Copyright © 2013 SciRes. ENG 75 for the speech frame with the length of 16 ms and 50% overlap. The short-time energy for a speech signal s[n] is calculated as: +−= −= n Lnm nmnwmsE ˆ 1 ˆ 2 ˆ]) ˆ [][( (2) where s[m] is the speech signal, ] ˆ [mnw − is th e applied window. rRn = ˆ, where R represents frame shift and r is the integer. 4.3. Calculation of Time Duration The time duration of each unit under different emotional states is calculated to obtain the prosodic characteristics of speech signals. Moreover, the duration of silence in each sentence is estimated, in order to get the pause assignment for each type of emotion. The duration of silence is calculated through speech endpoint detection method. The endpoint detection algo- rithm aims to iden tify the speech sign al from background noise. The short-time energy is calculated to detect voic- ed speech and short-time zero crossing rate is estimated to decide the voiceless speech. The length of silence is then calculated while removing the speech parts. Table 1 shows the average value of prosodic features for the units under five different types of emotion. 5. TS-PSOLA Method Time Domain Pitch Synchronous Overlap Add is a po- pularly used concatenative synthesis method. The basic contribution of TD-PSOLA technique is to modify the pitch directly on the speech waveform. There are three steps for TD-PSOLA: pitch synchronization analysis, pitch synchronization modification and pitch synchroni- zation synthesis. Pitch synchronization analysis is the core of TD- PSOLA method, it finishes two tasks: fundamental fre- quency detection and pitch mark. Let xm(n) denotes the windowed short time signal: n)x(n)-()(mmm thnx = (2) where tm is the mark point of pitch, hm is the window sequence. Pitch synchronization modification adapts the pitch mark by changing the duration (insert or delete the se- quence with the length of pitch duration) and tone (in- crease or decrease the fundamental frequency). The pitch synchronization synthesis adds the new se- quence signal produced in the previous step. In this work, the Least-Square Overlap-Added Scheme method is used to get the synthesized signal: = qq qq th thna nn)-( n)-()(x )(x q 2 qqq (3) Table 1. Average prosodic feature values of units under five emotional states. Prosodic featuresEmotion types Neutral AngryHappySad Bored Pitch (Hz) 149 251 203 126 169 Time duration (s)0.24 0.16 0.18 0.260.25 Energy (db) 56.4 73.2 64.8 52.149.3 where q t is the new pitch mark, q h is the synthesized window sequence, q a is the weight to compensate the energy loss when modifying the pitch value. 6. Experiments and Results Figure 3 illustrates an example of the emotional speech synthesis applying the proposed method in this work. Figure 3 shows the waveforms of the utterance “Das schwarze Stück Papier befindet sich da oben neben dem Holzstück” produced under neutral and four types of emotional states: angry, happy, sad and bored. Figure 3 also shows the waveforms of the synthesized emotional speech under four different types of emotional states based on the prosodic feat u re modificati on algori t hm. In order to evaluate the performance of proposed emo- tional speech synthesis system, a subjective test is made. Six participators listened the synthesized emotional speech utterances, and selected which type of emotion they are. The subjective test results (confusion matrix) are listed in Table 2. 7. Conclusions and Discussion In this work, a prosodic feature modification method combined with PSOLA algorithm is proposed in order to add the emotional color to a neutral speech. Figure 3 shows the waveforms of the natural and synthesized speech signals under four different types of emotion. It is seen that the waveforms of the synthesized speech are distinguished among different types of emotion, and they are similar to the waveforms of natural speech pro- nounced by human beings. The subjective test as illu- strated in Table 2 indicates that the synthesized speech signals contain clear emotion colors, it is easy to classify emotion types from the synthesized utterances by human being. For the synthesized speech, the emotion “angry” is easiest to classify. This is because the natural emotion “angry” contains strong emotional arousal, resulting in distinguished prosodic characteristics. The emotion “bored” obtaines the lowest subjective classification ac- curacy, this is probably because the acoustic characteris- tics of emotion “bored” is not clear, this kind of emotion is mainly expressed through the linguistic information. One of the shortcomings of this work is that the emo- tional speech data size is limited. In order to meet the 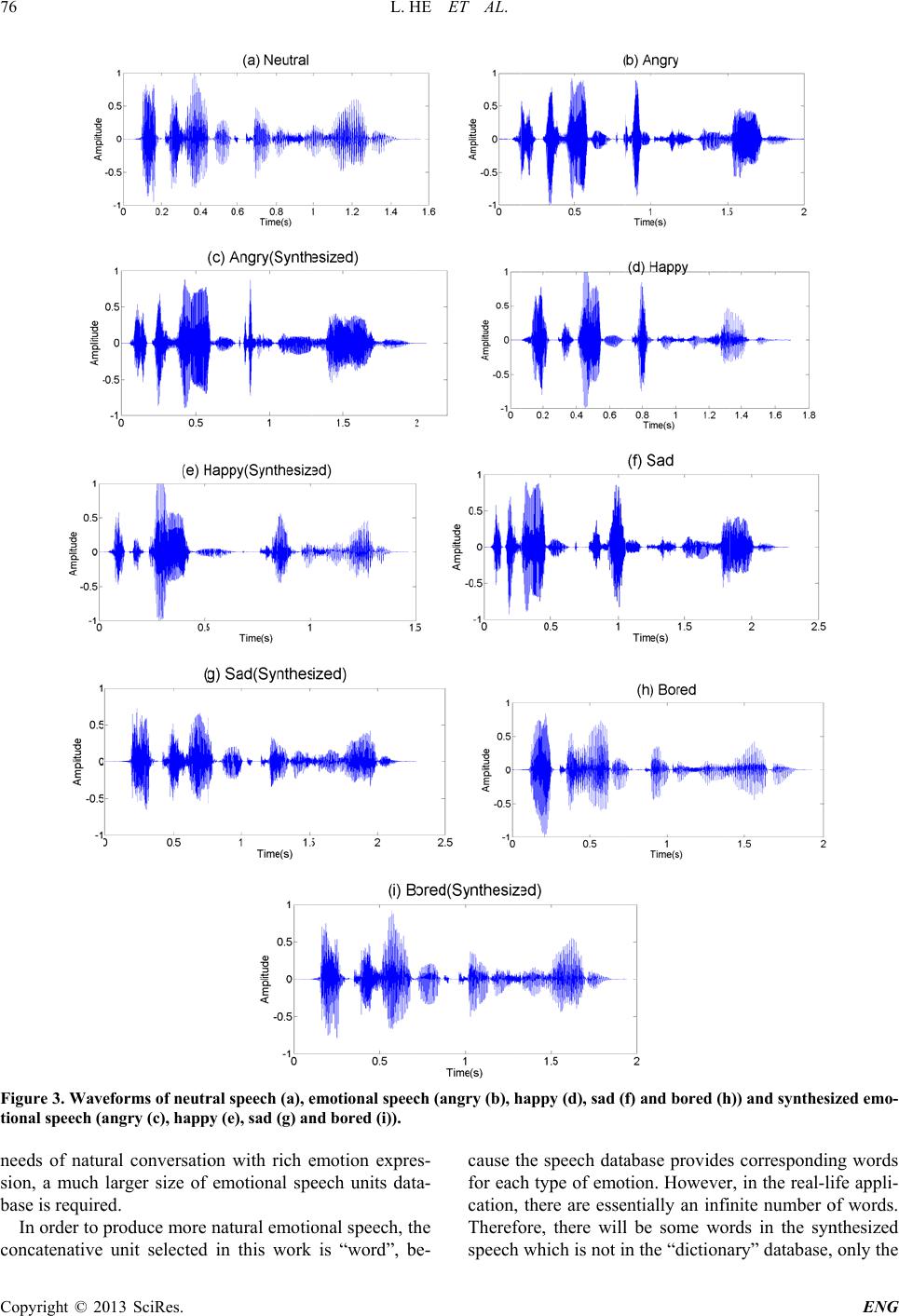 Copyright © 2 0 76 Figure 3. Wav e tional speech ( a needs of nat u sion, a much b ase is requir e In order to p concatenative 0 13 SciRes. e forms of neut r a ngry (c), hap p u ral conversati o larger size o f e d. p roduce more unit selected r al speech (a), e p y (e), sad (g) a n o n with rich e f emotional sp e natural emoti o in this work L. H e motional spee c n d bored (i)). e motion expr e e ech units dat o nal speech, t h is “word”, b H E ET AL. c h (angry (b), h e s- a- h e e- cause t h for eac h cation, Theref o speech h appy (d), sad ( f h e speech dat a h type of emo t there are ess e o re, there wil l which is not i n f ) and bored ( h a base provide s t ion. Howeve r e ntially an infi l be some wo r n the “diction a h )) and synthes i s correspondi n r , in the real-l i nite number o r ds in the sy n a ry” database, ENG i zed emo- n g words i fe appli- o f words. n thesize d only the  L. HE ET AL. Copyright © 2013 SciRes. ENG 77 Table 2. Subjective test re sults. Synthesized emotion type s Classified emotion types Angry Happy Sad bored Angry 90.3% 8.1% 1.6% 0% Happy 8.1% 87.1% 3.2% 1.6% Sad 6.5% 6.5% 80.5% 6.5% Bored 3.2% 8.1% 11.3% 77.4% optimized word could be found through unit selection algorithm, resulting lower quality of the final speech. One of the solutions is to choose shorter length of unit type, like syllables, phonemes and so on. In this way, a smaller size of data set will be required. REFERENCES [1] R. Cowie, E. Douglas-Cowie, N. Tsapatsoulis, G. Votsis, S. Kollias, W. Fellenz and J. G. Taylor, “Emotion Recog- nition in Human-Computer Interaction,” Signal Proces- sing Magazine, IEEE, Vol. 18, No. 1, 2001, pp. 32-80. http://dx.doi.org/10.1109/79.911197 [2] M. Schröder, R. Cowie and E. Cowie, “Emotional Speech Synthesis: A Review,” Eurospeech-2001, 2001. [3] J. E. Cahn, “The Generation of Affect in Synthesized Speech,” Journal of the American Voice I/O Society, Vol. 9, 1990, pp. 1-19. [4] F. Burkhardt and F. Sendlmeier, “Verification of Acous- tical Correlates of Emotional Speech Using Formant- Synthesis,” ISCA Workshop on Speech & Emotion, Northern Ireland, 2000, pp. 151-156. [5] M. Bulut, S. Narayan and A. Syrdal, “Expressive Speech Synthesis Using a Concatenative Synthesizer,” Proceed- ings of ICSLP, 2002, pp. 1265-1268. [6] E. Eide , “Pre se rva t i on, Ide n tif i cat i on, an d Use of E mo ti on in a Textto-Speech System,” Proceedings of IEEE Work- shop on Speech Synthesis, 2002, pp. 127-130. [7] A. W. Black and N. Cambpbell, “Optimising Selection of Uni ts fro m Sp eech Database for Concatenative Synthes is, ” Proceedings of EUROSPEECH-95, 1995, pp. 581-584. [8] J. Pitrelli, R. Bakis, E. Eide, R. Fernandez, W. Hamza and M. Picheny, “The IBM Expressive Text-to-Speech Syn- thesis System for American English,” IEEE Transactions on Speech Audio Process, Vol. 14, No. 4, 2006, pp. 1099- 1108. http://dx.doi.org/10.1109/TASL.2006.876123 [9] W. Hamza, R. Bakis, E. Eide, M. Picheny and J. Pitrelli, “The IBM Expressive Speech Synthesis System,” Pro- ceedings of ICSLP, 2004. [10] G. Hofer, K. Richmond and R. Clark, “Informed Blend- ing of Databases for Emotional Speech Synthesis,” Pro- ceedings of Interspeech, 2005, pp. 501-504. [11] M. Schroder, “Speech and Emotion Research: An Over- view of Research Frameworks and a Dimensional Ap- proach to Emotional Speech Synthesis,” Ph.D. Thesis, Saarland University, Saarland, 2004. [12] L. R. Rabiner and R. W. Schafer, “Digital Processing of Speech Signals,” Prentice-Hall, Inc., Englewood Cliffs, 1978. [13] F. Burkhardt, A. Paeschke, M. Rolfes, et al., “A Database of German Emotional Speech,” Proceedings of Inters- peech, 2005. |