Combined Dictionary Learning in Facial Expression Recognition 89
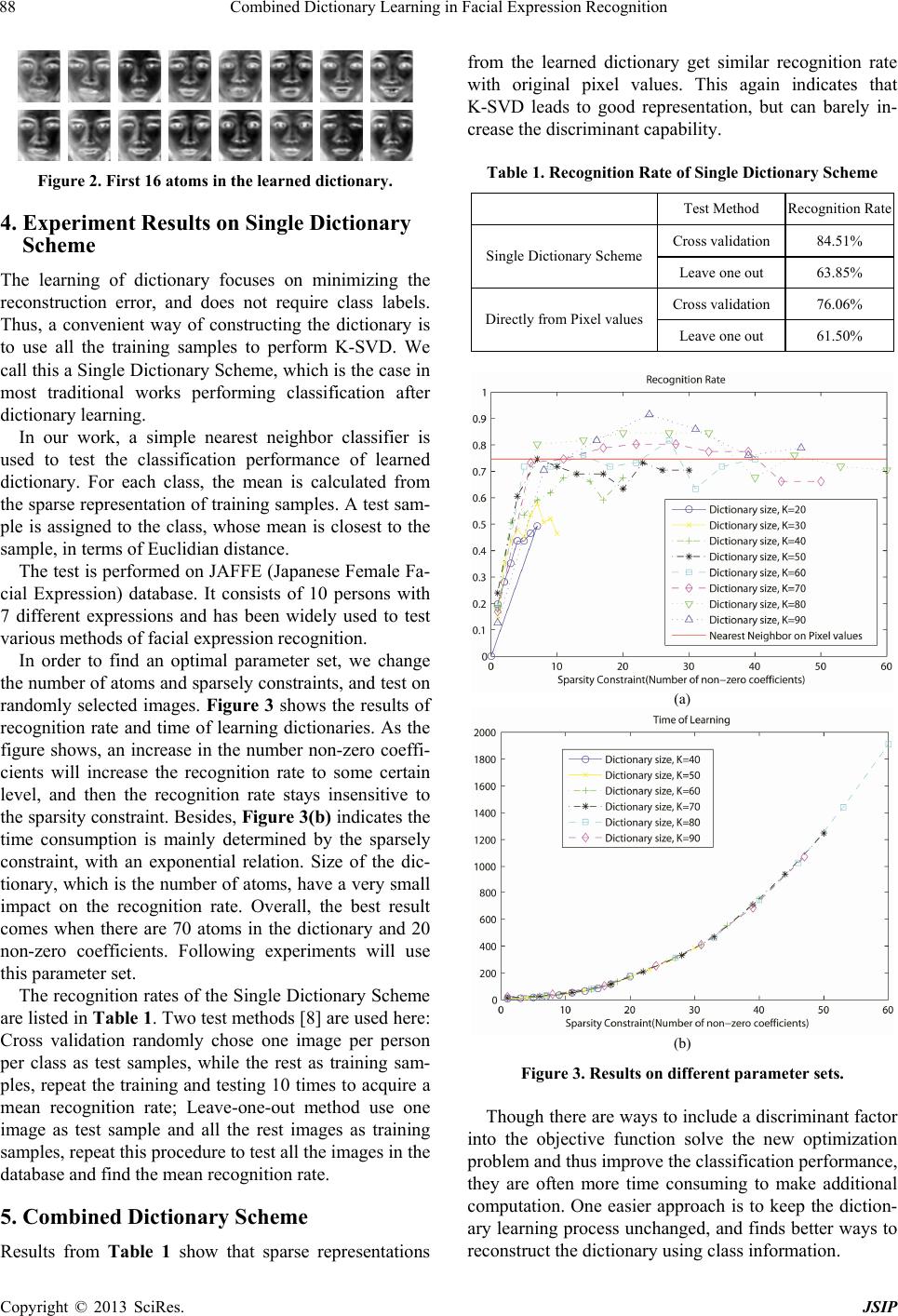
Figure 4. Combined Dictionary Scheme.
As a simple way of reconstructing dictionary, the pro-
posed Combined Dictionary Scheme combine multiple
dictionaries into one. More specifically, learn dictionary
from the training samples of each single class, and com-
bine these dictionaries into a C times larger diction- ary,
as shown in Figure 4, where C is the number of classes.
Therefore, in order to keep the same dictionary size
and sparsity constraint with Single Dictionary Scheme,
the dictionaries need to be learned can have C times
smaller size and sparsity constraint. It has been discussed
from Figure 3 that the sparsity constraint (number of
non-zero coefficients) mainly determines the computa-
tion complexity in an exponential way. It can be ex-
pected that the Combined Dictionary Scheme will dra-
matically reduces the time of learning dictionaries. As in
the previous section, dictionary size of 70 and sparsity
constraint 20 are used, here for each of the 7 dictionaries,
the sizes are set to 10 and sparsity constraints are set to 3.
Once again, nearest neighbor is used to test perform-
ance. Table 2 and Table 3 compare the recognition rate
and time of computation with Single Dictionary Scheme
and an-other Gabor based algorith m in literature.
Table 2. Comparison of Recognition Rate.
Test Method Recognition Rate
Cross validation 84.51%
Single Dictionary Scheme Leave one out 63.85%
Cross validation 91.55%
Combined Dictionary
Scheme (Proposed) Leave one out 84.04%
Cross validation 83.09%
Gabor + Nearest Neighbor Leave one out -
Cross validation -
Gabor + PCA + FLD [1] Leave one out 93.90%
As shown in Table 2 and Table 3, the proposed
Combined Dictionary Scheme achieves better results
than the original Single Dictionary scheme. The
recognition rate is increased by 7 and 20 percentage,
respectively in the two test methods, while reducing the
computation complexity by approximately 3 times.
Table 3. Comparison of Computation Complexity.
Training Time* Testing Time*
Single Dictionary Scheme61.14 0.0382
Combined Dictionary
Scheme (Proposed) 16.99 0.0101
Gabor + PCA + FLD [1]99.06 1.26
*Training time refers to the average time of training 140 samples; Testing
time refers to average time of testing one sample; All times are in seconds,
acquire d from Matlab running on a desktop computer.
Though the recognition performance of dictionary
learning is not as good as Gabor+PCA+FLD [1], the av-
erage time of testing one image is more than 100 times
less. We should also note that the recog nition rate here is
based on nearest neighbor, it could be expected that the
performance would be better if more powerful classifica-
tion algorithms are used. If the same nearest neighbor
classifier is applied to Gabor feature, the recognition rate
is worse than that of dictionary learning. This indicates
that dictionary learning and sparse representation might
get more promising results in the future.
6. Conclusions
This paper investigates the application of K-SVD dic-
tionary learning in facial expression recognition. The
sparse representation of a facial image is regarded mainly
as a way of extracting features and at the same time with
low dimensions Sparse representation based on learned
dictionary directly from all training samples (Single Dic-
tionary Scheme) yields similar recognition performance
with original image pixel values. This demonstrates that
K-SVD focuses on minimizing reconstruction error, and
does not provide good discriminate capability.
In order to improve the classification performance, a
Combined Dictionary Scheme is proposed, so that the
class information can contribute to the dictionary con-
struction. First learn a separate dictionary for each class
using the corresponding samples in the training set. Then
combine them into a larger dictionary for the final train-
ing and classification. The proposed method gets better
classification performance than the traditional Single
Dictionary Scheme, in terms of both recognition rate and
computation complexity.
Though the current recognition rate is not as good as
classification systems using other features, it might be
due to the simple nearest neighbor classifier used for
testing. Also dictionary learning needs much less time to
compute than Gabor features. Since currently there are
few works applying dictionary learning to facial expres-
sion recognition, the performance would be further im-
proved in the future, if more powerful classification al-
gorithms are used.
Copyright © 2013 SciRes. JSIP