Environmental Sound Recognition Using Double-Level Energy Detection
22
tion (width of margin).
Many linearly inseparable problems in the real world
can be converted into linearly separable by mapping to
high-dimensional space with the SVM kernel function
[10]. At present, the most commonly used kernel func-
tions include linear kernel, polynomial kernel, RBF ker-
nel and sigmoid kernel. In the experiment of this paper,
we use the LIBSVM package which is designed by DR.
Lin Zhiren of Taiwan University.
5. Experiments
5.1. Experimental Setup
The sounds of the ecological environment which are used
in these experiments are the variety of birds singing.
There is a total of 12 kinds of birds singing here including
flour chicken, Zhu turtledove, Dong chicken, male thrush,
blackwater chicken, hair chicken, mother partridge,
mountain turtledove, water rails, white-eye, the mother
pheasant, mother bamboo chicken. There are 20 samples
of each kind of birds singing, of which 10 samples are
used for training and 10 samples for testing, so a total of
240 sound samples. These bird singings were recorded by
voice recorder in the outdoors, and the length of each
sound sample is more than two seco nds, the sampling rate
is 44100 Hz. In this work, the sign al to noise ratio (SNR)
of the sounds which is used to train the SVM models is
60 dB in the training step, which is done by adding the
noise at 60 dB SNR to the clear sound data. In the testing
step, we use the sounds with different SNRs. The ex-
tracted features include classic MFCC, TED_MFCC (use
the time-domain energy detection only), FED_MFCC
(use the frequency-domain energy detection only) and
DED_MFCC, and they are all 12-dimensional feature
vectors. The kernel function used in SVM is RBF kernel.
The PFA was set to .
8
10
5.2. Evaluation Results
In order to observe the noise immunity of the DED_
MFCC feature on the ecological environment sounds
classification, we use SVM to construct the classification
models based on MFCC, TED_MFCC, FED_MFCC and
DED_MFCC respectively. We use 30 frames of each
sample for training, and 256 frames of each sample for
testing. Here, the no ise we add to the clear bird singing is
the white Gaussian noise. The classification accuracy of
the test samples corresponding to the different SNRs is
shown in Table 1. The results of the experiments show
that, in the case of SNR 50 dB and above, the four kinds
of features do not have big difference. But with the
enhancement of the noise, the MFCC has a sharp decline
in the recognition rate. Compar ed to MFCC, TED_MFCC
has an improvement up to about 25%, while FED_MFCC
Table 1. classification results under the white Gaussian
noise.
Signal Noise Ratio (SNR)
feature 60 dB50 dB40 dB 30 dB 20 dB10 dB
MFCC 100.0090.8368.33 45.83 37.5024.17
TED_MFCC 100.00100.0091.67 78.33 67.5043.33
FED_MFCC100.00100.0091.67 85.83 71.6761.67
DED_MFCC 100.00100.0091.67 85.83 71.6761.67
and DED_MFCC up to about 35%. Therefore, it can be
seen from the experiments that FED_MFCC and DED_
MFCC show bett e r robust nes s i n a noisy environm ent .
In order to demonstrate DED_MFCC not only has a
higher recognition rate but also lower time complexity,
here we study the time complexity of the feature extrac-
tion of the test samples and classification. The time com-
plexity means t he running time o f the program, the u nit is
seconds(s). Due to using the same amount of training data,
the time complexity of training the model is the same. In
these experiments, the training step is the same, and we
use all of the 240 samples for testing and classification.
The result is the average of 10 experiments, and it is
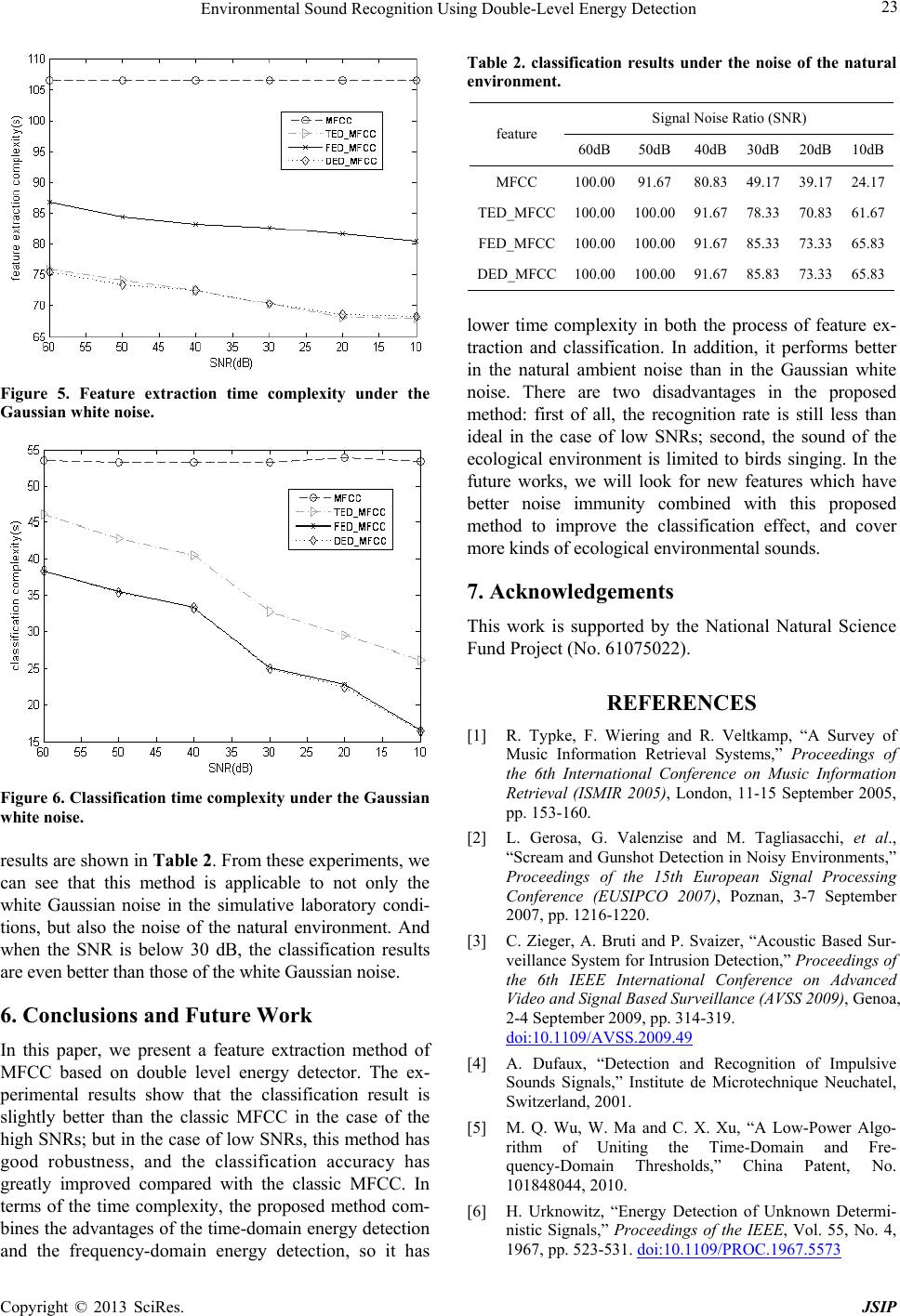
shown in Figure 5 and Figure 6. From Figure 5, we can
see that the time complexity of MFCC feature extraction
is higher than that of FED_MFCC, which is because
FED_MFCC does not have the pre-emphasis, while
MFCC needs it and MFCC extracts feature of all the
frames; TED_MFCC and DED_MFCC reduce the num-
ber of FFT, so their time complexity of feature extraction
is lower than that of FED_ MFCC. From Fi gure 6, we can
see that the time complexity of MFCC classification is
higher than that of the others, which is because MFCC
classifies all the frames, while the others only classify the
frames through the time-domain or frequency-domain
energy detection; the detected accuracy of the FED is
higher than that of the TED, that means the number of
frames detected by the FED is less than the number of
frames detected by the TED, so the classification time
complexity of FED_MFCC and DED_MFCC is lower
than that of TED_MFCC. From Figure 5 and Figure 6,
as SNR decreases, the number of the frames which are
detected is also reduced. So the time complexity of fea-
ture extraction and classification is reduced too. Therefore,
DED_MFCC has a lower time complexity of feature ex-
traction and classification with the advantages of the
TED_MFCC and the FED_MFCC.
In order to observe the performance of the method in
the natural ambient noise, we use the sound of brook
which was recorded in the outdoors instead of the white
Gaussian noise. That means the clear bird singings were
added with the sound of water with different SNRs. The
Copyright © 2013 SciRes. JSIP