Applying Score Reliability Fusion to Bi-Model Emotional Speaker Recognition
4
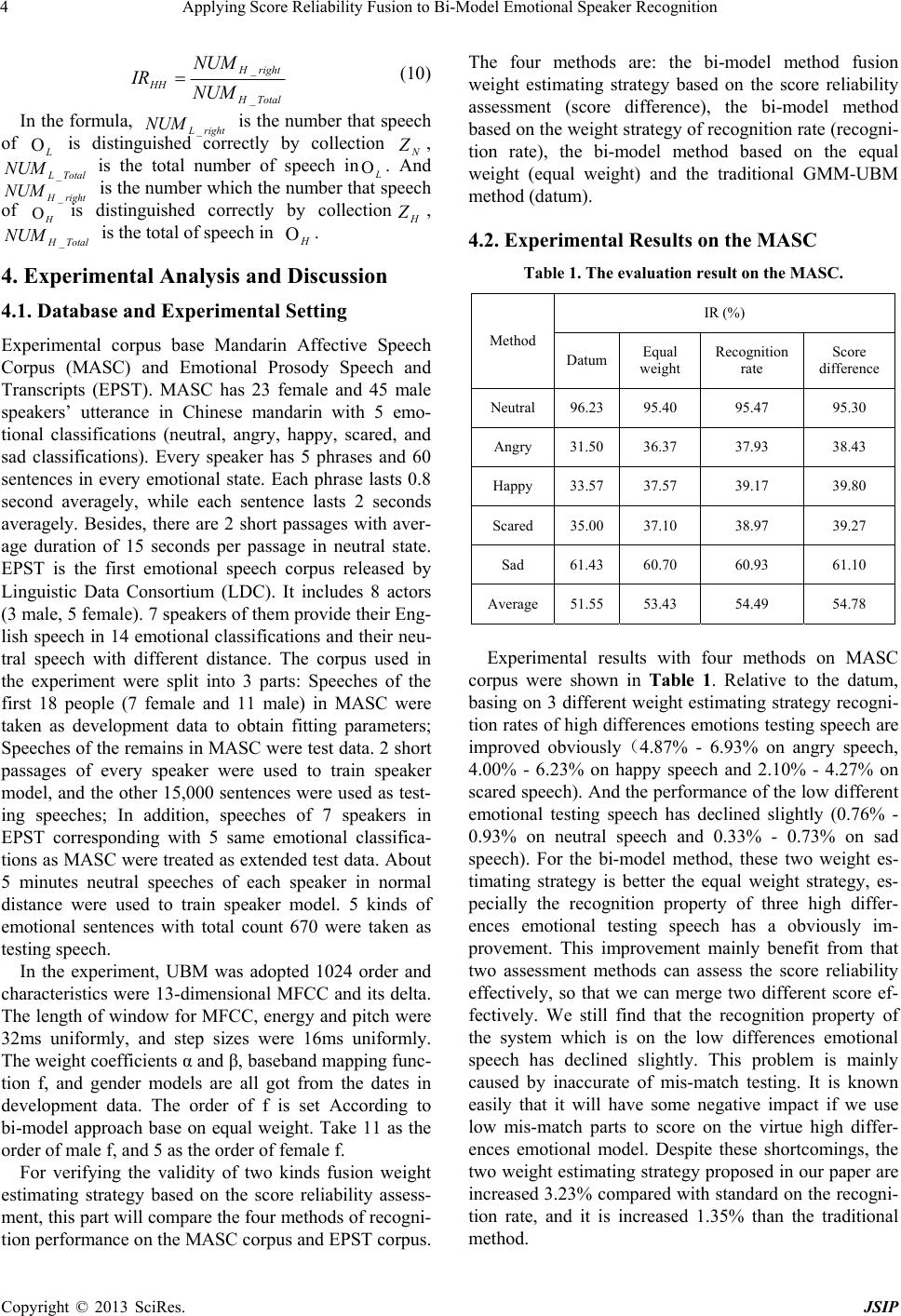
TotalH
rightH
HH NUM
NUM
IR
_
_
(10)
In the formula, rightL _ is the number that speech
of is distinguished correctly by collection N,
is the total number of speech inL
NUM
L
L
NUM _
Z
Total
. And
right_ is the number which the number that speech
of is distinguished correctly by collection,
is the total of speech in .
H
NUM
H
H
NUM _
H
Z
Total H
4. Experimental Analysis and Discussion
4.1. Database and Experimental Setting
Experimental corpus base Mandarin Affective Speech
Corpus (MASC) and Emotional Prosody Speech and
Transcripts (EPST). MASC has 23 female and 45 male
speakers’ utterance in Chinese mandarin with 5 emo-
tional classifications (neutral, angry, happy, scared, and
sad classifications). Every speaker has 5 phrases and 60
sentences in every emotional state. Each phrase lasts 0.8
second averagely, while each sentence lasts 2 seconds
averagely. Besides, there are 2 short passages with aver-
age duration of 15 seconds per passage in neutral state.
EPST is the first emotional speech corpus released by
Linguistic Data Consortium (LDC). It includes 8 actors
(3 male, 5 female). 7 speakers of them provide their Eng-
lish speech in 14 emotional classifications and their neu-
tral speech with different distance. The corpus used in
the experiment were split into 3 parts: Speeches of the
first 18 people (7 female and 11 male) in MASC were
taken as development data to obtain fitting parameters;
Speeches of the remains in MASC were test data. 2 short
passages of every speaker were used to train speaker
model, and the other 15,000 sentences were used as test-
ing speeches; In addition, speeches of 7 speakers in
EPST corresponding with 5 same emotional classifica-
tions as MASC were treated as extended test data. About
5 minutes neutral speeches of each speaker in normal
distance were used to train speaker model. 5 kinds of
emotional sentences with total count 670 were taken as
testing speech.
In the experiment, UBM was adopted 1024 order and
characteristics were 13-dimensional MFCC and its delta.
The length of window for MFCC, energy and pitch were
32ms uniformly, and step sizes were 16ms uniformly.
The weight coefficients α and β, baseband mapping func-
tion f, and gender models are all got from the dates in
development data. The order of f is set According to
bi-model approach base on equal weight. Take 11 as the
order of male f, and 5 as the order of female f.
For verifying the validity of two kinds fusion weight
estimating strategy based on the score reliability assess-
ment, this part will compare the four methods of recogni-
tion performance on the MASC corpus and EPST corpus.
The four methods are: the bi-model method fusion
weight estimating strategy based on the score reliability
assessment (score difference), the bi-model method
based on the weight strategy of recognition rate (recogni-
tion rate), the bi-model method based on the equal
weight (equal weight) and the traditional GMM-UBM
method (datum).
4.2. Experimental Results on the MASC
Table 1. The evaluation result on the MASC.
IR (%)
Method
Datum Equal
weight
Recognition
rate
Score
difference
Neutral 96.23 95.40 95.47 95.30
Angry 31.50 36.37 37.93 38.43
Happy 33.57 37.57 39.17 39.80
Scared 35.00 37.10 38.97 39.27
Sad 61.43 60.70 60.93 61.10
Average 51.55 53.43 54.49 54.78
Experimental results with four methods on MASC
corpus were shown in Table 1. Relative to the datum,
basing on 3 different weight estimating strategy recogni-
tion rates of high differences emotions testing speech are
improved obviously(4.87% - 6.93% on angry speech,
4.00% - 6.23% on happy speech and 2.10% - 4.27% on
scared speech). And the performance of the low different
emotional testing speech has declined slightly (0.76% -
0.93% on neutral speech and 0.33% - 0.73% on sad
speech). For the bi-model method, these two weight es-
timating strategy is better the equal weight strategy, es-
pecially the recognition property of three high differ-
ences emotional testing speech has a obviously im-
provement. This improvement mainly benefit from that
two assessment methods can assess the score reliability
effectively, so that we can merge two different score ef-
fectively. We still find that the recognition property of
the system which is on the low differences emotional
speech has declined slightly. This problem is mainly
caused by inaccurate of mis-match testing. It is known
easily that it will have some negative impact if we use
low mis-match parts to score on the virtue high differ-
ences emotional model. Despite these shortcomings, the
two weight estimating strategy proposed in our paper are
increased 3.23% compared with standard on the recogni-
tion rate, and it is increased 1.35% than the traditional
method.
Copyright © 2013 SciRes. JSIP




