A. M. SHAFFIE, G. A. ELKOBROSY
1314
Chinese characters, every one of them has its own char-
acteristics. In the Arabic character set, one of the main
features is dots. Up to 3 dots can exist for Arabic charac-
ters, and hence no one criteria can be used to apply for all
of these character sets. Some techniques for these styles
are applied for Arabic characters by Cowell et al. [4]
using “thinning” and “feature extraction”, however, that
technique was slow and cannot be modified to another
character sets easily. One of the main problems of the
techniques used by OCR systems is that the character is
wrongly identified, so th e features can be tested by bu ild-
ing a confusion matrix Cowell [5] to determine whether
this technique is good fo r this character set or it will lead
to a problem in the recognition phase. And it has been
derived a way to resolve this conflict Cowell [6]. The
proposed work here gets its importance from its scale and
rotation invariant and of course because its calculations
are minimum while its accuracy is very good and can be
tuned by doing more calculations to get more accuracy.
2. An Overview of the Proposed System
The paper’s approach in recognition makes use of five
phases as outlined below:
Read input image.
Line and characters segmentation.
Normalize character to a standard size, 100 × 100
pixel resolutio n has been used in the implem ent at i on.
Extract the character signature.
Compare the character signature with the signature
templates of the character set.
2.1. Text Image and Text Line Segmentation
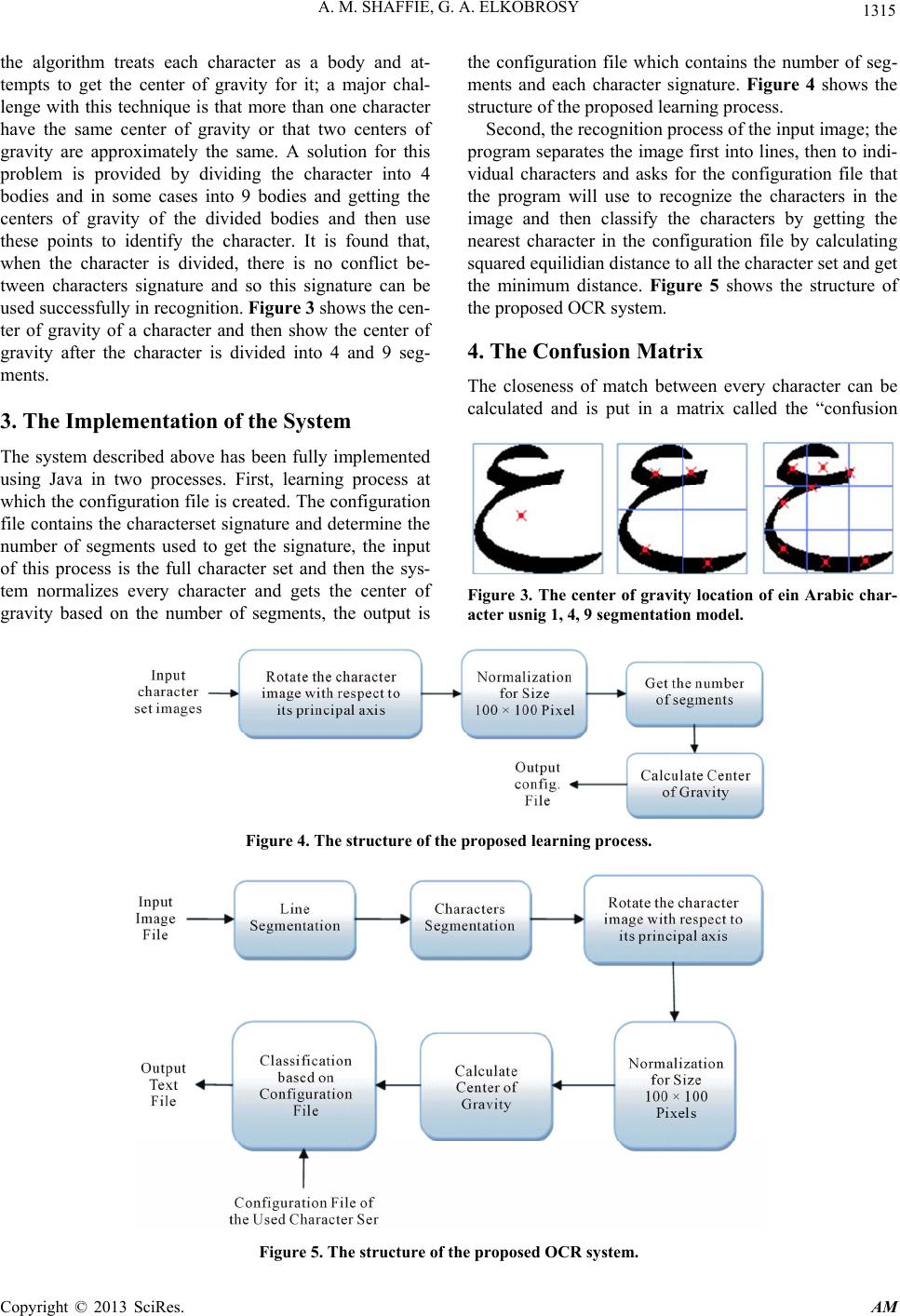
The segmentation of the image is done at two levels.
First, the text in the image is split into lin es of text using
the horizontal projection technique (i.e. location of hori-
zontal lines of zero density of pixels, given the line of
text from the horizontal projection technique, indicates
the beginning of a segment and the subsequent location
of another zero density line of pixels indicates the end of
a segment, thus an entire segment is located). Second,
each line of text is split into characters using vertical
projection technique (i.e. location of vertical lines of zero
density of pixels, given the line of character from the
vertical projection technique, indicates the beginning of a
segment and the subsequent location of another zero
density line pixels ind icates the end of a segment, thus an
entire segment is located) [7]. Figure 1 illustrates the
text image to text lines segmentation and the text line to
individ ual charact e r segmentati o n.
2.2. Normalization of the Fragmented
Characters
One of the important stages in the process is to insure
that the input character has the same dimensions and the
same orientation as the characters used to create the sig-
nature or the configuration file, so the procedure start by
unified the orientation of the characters by using the
character principle axis, so the normalization started by
getting the principle axis of the character and rotate the
character image to make the principle axis vertical, and
then trimming the white p arts of the character image then
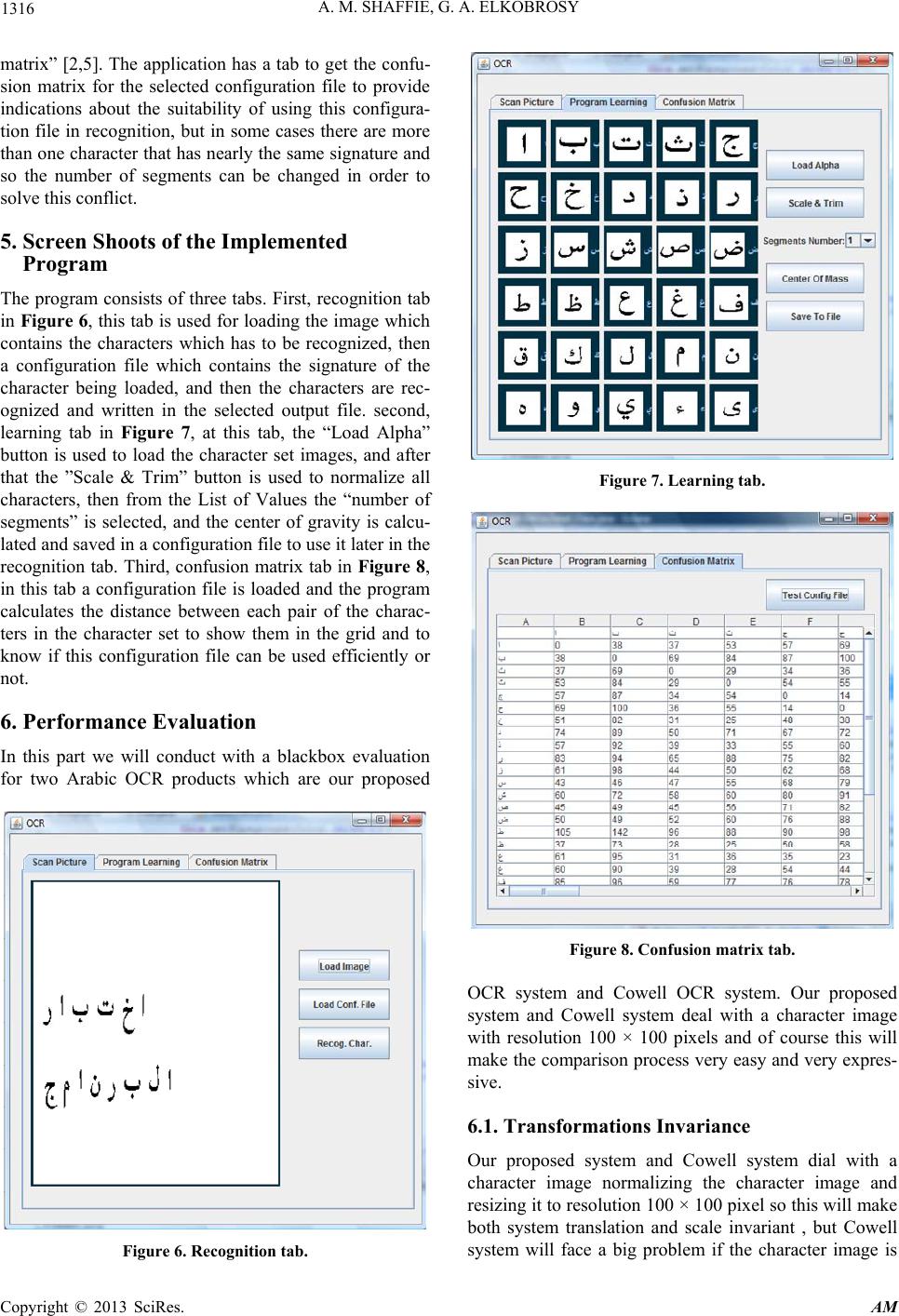
it is scaled to 100 × 100 pixels. Figure 2 shows the case
of Arabic character alef and mim. The figure on the right
shows the scanned character as scanned and the figure on
the left shows the character after it expanded so that it
has the size required and therefore touches each side on
the 100 × 100 square as shown [2 ].
2.3. Get the Center of Gravity
The signature of each character is produced by getting
the center of gravity of the normalized character as if the
character is a uniform body and the center of gravity co-
ordinate XG, YG is calculated using the following for-
mula
XG = thegma xi/n
YG = thegma yi/n
where:
n is the num ber of pixels.
x, y is the coordinate of the black pixels in the image
of the character.
This approach is applied to the Arabic characters as
Figure 1. Image and line text segmentation.
Figure 2. Normalized characters and other original form.
Copyright © 2013 SciRes. AM