C. Y. YONG ET AL.
26
rectly measure tilt angle and linear distance based on
acceleration of gravity [6]. The main drawback of the
sensor is it unable to distinguish between acceleration
due to linear movement and acceleration due to gravity.
Problem can be solved by combining accelerometer with
gyroscope sensor.
2.2. Gyroscope
Gyroscope is mainly used to measure absolute rate of
rotation and relative angle by a single mathe matical inte-
gration. The performance is fast and accurate without
corrupted by linear acceleration or magnetic fields.
However, sometimes the integration may lead to errors
over time but it can be solved by combining with accel-
erometer.
2.3. Pattern Recognition
Pattern recognition consists of 6 stages: data collection,
pre-processing, feature extraction, training, classification
and cross validation [7-10].
Data are collected for training and training classifiers.
In order to achieve accurate result, data size should be
large enough to cover all relevant parameters. Training
and testing data should be differen t.
Pre-processing of signals aims to reduce noise and
normalize interests in a data set.
Feature extraction is a process to extract features that
characterize the region of interests. There are many types
of features such as histogram, shape information, texture
information, scale invariant feature transform and many
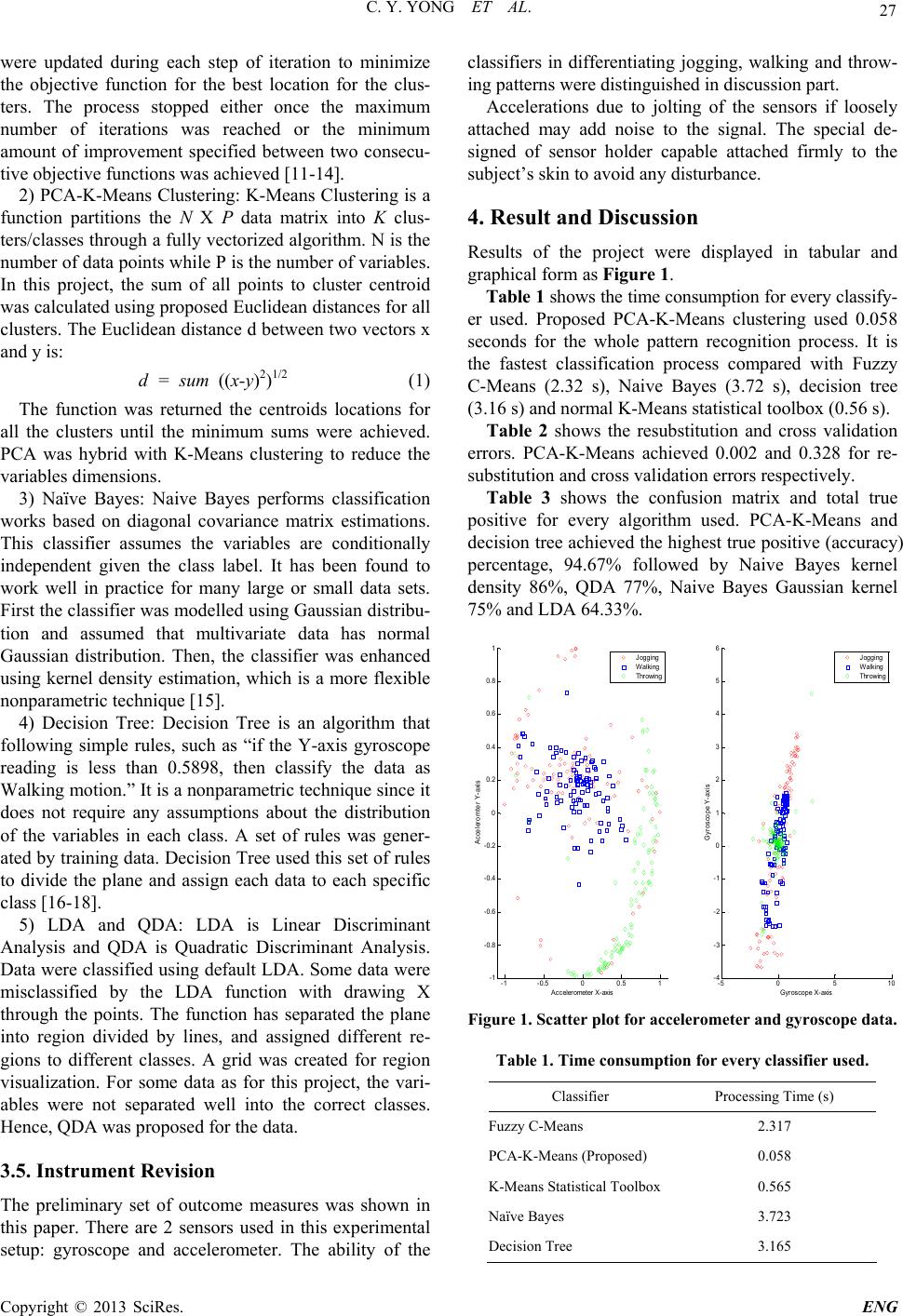
others. Principle Component Analysis (PCA) was used to
reduce the number of variables, from six to three; to re-
duce the complexity o f large data set.
Classifiers are trained by training data set. There are
two types of classifier: supervised and unsupervised
learning. Classifiers used in this study are Fuzzy, pro-
posed PCA-K-Means, C-Means, Naive Bayes and deci-
sion tree. Classifier should not just memorize class labels
of testing data. This gives 100% accuracy on training
data, but may not work on other unseen data. Hence,
novel testing data is used to test the performance of
trained classifier that able to generalize to novel data.
Cross validation aims to provide more thorough and
accurate evaluation for the classification process. The
large samples data are divided into a few subsets. The
first subset is left out for testing and the rest are used for
training. The process is repeated for each of the subset in
turn. Average accuracies is achieved from all the runs
and this is called N-fold cross validation.
3. Materials and Methods
3.1. Study Sample
Five healthy volunteers were selected inside university
campus for taking part in this study. Their ages are
around 20 years old with normal limbs movement and
significant mobility in everyday routine independent of
any walking aid.
3.2. Experimental Setup
For this study, experimental setup was done using a wire-
less 3-axis accelerometer. This device employs a YEI
3-Space Sensor breakout board for the tri-axial gyro-
scope, accelerometer, and compass sensors in conjunc-
tion with advanced processing and on-board quaternion-
based Kalman filtering algorithms to determine orienta-
tion relative to an absolute reference in real-time in an
enclosure measuring 60 mm × 35 mm × 15 mm. The
device was connected to a laptop using a standard USB
2.0 host system wireless asynchronous serial transmis-
sion.
The subjects wore a wearable sensor on above right
arm which employed of 3 sensors (gyroscope, acceler-
ometer and compass) inside the package. These sensors
were attached firmly on subjects’ skin with a special de-
signed holder.
3.3. Data Collection and Management
In the initial phase of the trial study, experiment was
conducted for three activities, there are jogging, walking
and throwing. Subjects were asked to perform a normal
walking with speed 3.7 ft/s and jogging with speed 6.5
ft/s on a treadmill with regular motor. Throwing was
performed by throwing a paper roll 1.50 m apart. These
activities were performed in a supervised and comfort-
able environment with presence of researcher for time-
stamping the start and end time of activities period.
Subjects were encouraged to perform the jogging, walk-
ing and throwing activities at their own pace and conven-
ience. The whole experiment setup place was ensuring a
relaxing and natural mood for the sake of subjects for
reflective of real world conditions.
The data were transmitted from sensors to the laptop
for further processin g .
3.4. Data Analysis
Data were collected through transmission of a mini wire-
less dongle from the sensors. They were pre-processing
for noise elimination and then ex tracted for classification
as below:
1) Fuzzy C-Means Clustering: This clustering is an it-
erative process. The parameters required for this cluster-
ing are numbers of cluster/class, exponent for the matrix
partition, maximum number of iteration and minimum of
improvement. First, an initial fuzzy partition matrix was
generated and the initial fuzzy cluster centers were cal-
culated. The cluster centers and the membership function
Copyright © 2013 SciRes. ENG