Z. X. YE, J. S. Chen
8
{ (1,0),(-1,0),(0,1),(0,-1)}
o
N
(see Figure 1). This means that each vertex has 4 nearest
neighboring vertices.
Prisoners’ dilemma game: The basic game we study in
this work is two person prisoners’ dilemma game (PDG)
which is defined in its classic form: This game is played
by two players. We assume that each player has only two
choices of strategies which may be identified as {, }
CD
.
Where C represents to cooperate and D represents defect.
At any run of dynamic games, if both players choose C,
they get a pay-off R each; if one player chooses D while
the other chooses C, the defector player gets the biggest
pay-off T, while the other gets S; if both players defect,
they get pay-off P. We can write the payoff in the matrix
form:
(, )(,)(,)(,)
(,)(, )(,)(,)
QCC QCDRRST
QDCQDDTSPP
Q
(1)
where the pay-off values must satisfy the inequalities
2.TRPS andRST
For more about PDG, readers may refer [3-5].
Stage games: In our class of supergames, some stage
games are played over discrete time At
each discrete time every player plays four 2-strategy 2-
person prisoners’ dilemma games simultaneously with
his neighbors. At the end of each game, player receives
payoff
if he plays strategy y while his
neighbor plays strategy
{0,1,2,}.i
i
(, )
ij j
Qyx
j
; so his total payoff from
playing strategy y is the sum of the payoffs received from
playing y against each of his neighbors. Then player i
may revise his strategy from y to z with probability
(|(,))
11
exp( ,)(,)
|| ||
11
exp( ,)
'||||
i
i
i
ij jijj
jN
i
ij j
jN
i
pz iy
Qzx Qyx
N
Qzx
N
x
(2)
where
and '
are normalization factors to make
(| (,))1
i
zA
pz iy
x (3)
The global updating rule is synchronous, i.e., all play-
ers change their strategies simultaneously at the same
time.
The dynamics of a supergame is characterized by a
stochastic process which is called strategy evolution
process (SEP). Technically, the SEP for a large super-
game is a Markov chain whose state at time t is denoted
by ,
{;
tti}
iVX. It takes value over
{, }
VV
t
CD
,
{; }
tti
iV
x is the realization of t
. Equivalently
he state of SEP at time y a probability
distribution t
we may model tt b
on V
. Suppose that the configuration
1t
x determs theategy of player i at time t with
ability (called local transition probability):
,1 ,1,
(| )(|:}
itititi tji
pxpxxj W
ine
prob
str
x (4)
Note that
,
,1,
|;)1
ti
iti tji
x
xjWfor alliV
(p x
(5)
Let be the global one-step transition prob-
)jW
()Py|x
abilities from x toy. Then for Synchronous updating
rule, the global transition probabilities of the SEP are
defined by
P
1,1,
() (|:
ttititj i
iV
pxx
x|x (6)
The global transition probabilities (6) defines a dis-
crete-time Markov process on the configuration space
V
. Given a measure 1t
on the configuration 1t
x
defines a probability msure 1
=
tt
(6) ea
P on t
x.
()( ))ddP
xx
11 1
( |
tttttt
d
xx (7)
We say that a measure
is stationary
va
or time in-
riant if
=
P. We are interested in existence and
uniquenessf the invariant measures under the above
mentioned condition, i.e., the ergodicity and reversibility
of the SEP. In certain cases there may exist multiple in-
variant measures. This phenomenon is called phase tran-
sition. The following result is well known.
Theorem 3.1: The invariant measures
o
for the time
ev
ous updating case, to find the invari-
an
3. Simulation Result of the Limiting
Ine report the simulation results for exam-
We consider the finite sub-lattice with
olution form a nonempty convex set.
Proof: see [6].
For the synchron
t measure analytically is quite difficult. So in this pa-
per we focus on the numerical simulation which shows
interesting behavior. The detail is given in the next sec-
tion.
Behavior
this section w
ining the limiting behavior of dynamic supergames de-
scribed in the previous section. For convenience, we set
the following payoff matrix
(1,1
) (8,0)
(0, 8)(5, 5)
Q
40 40
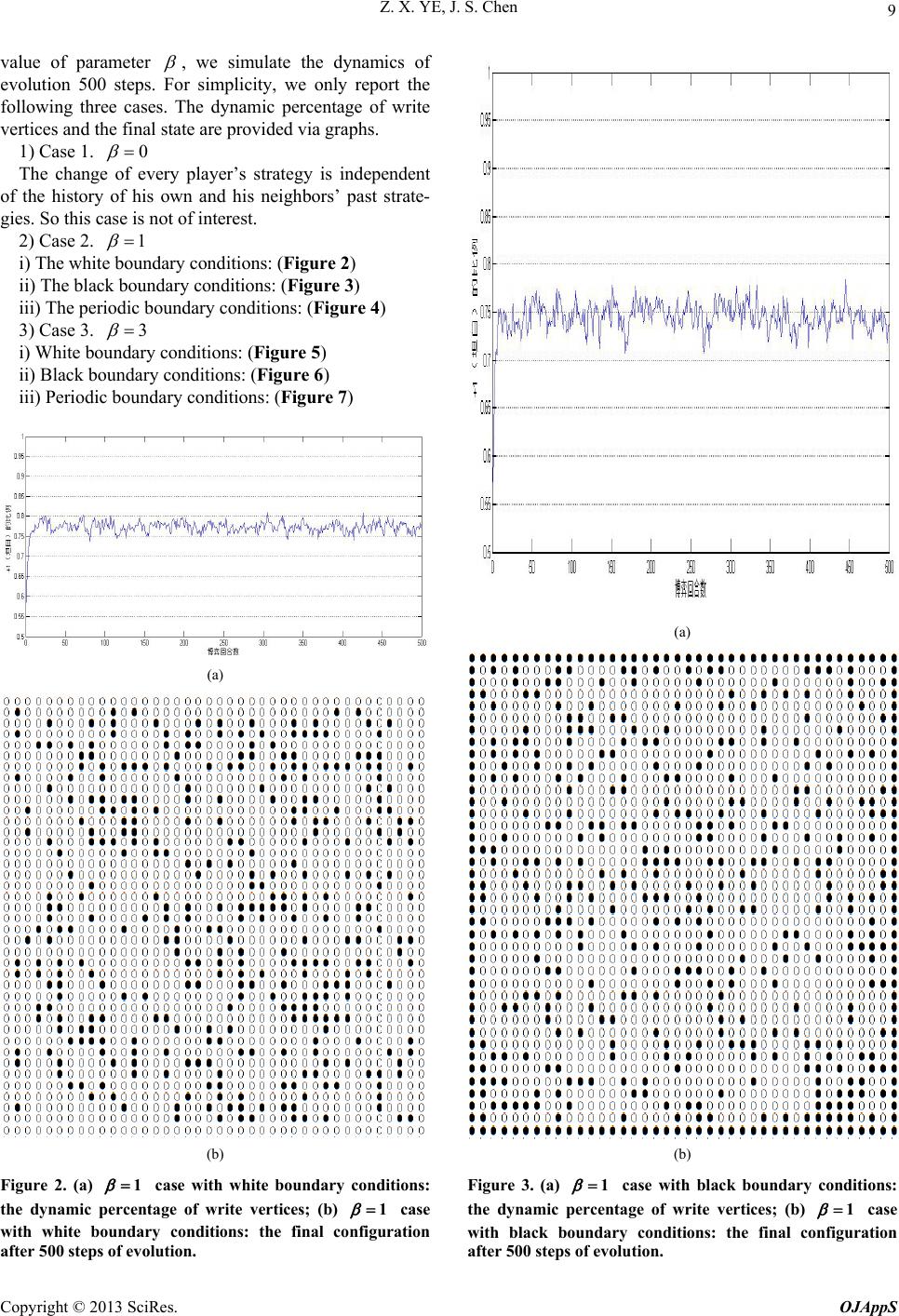
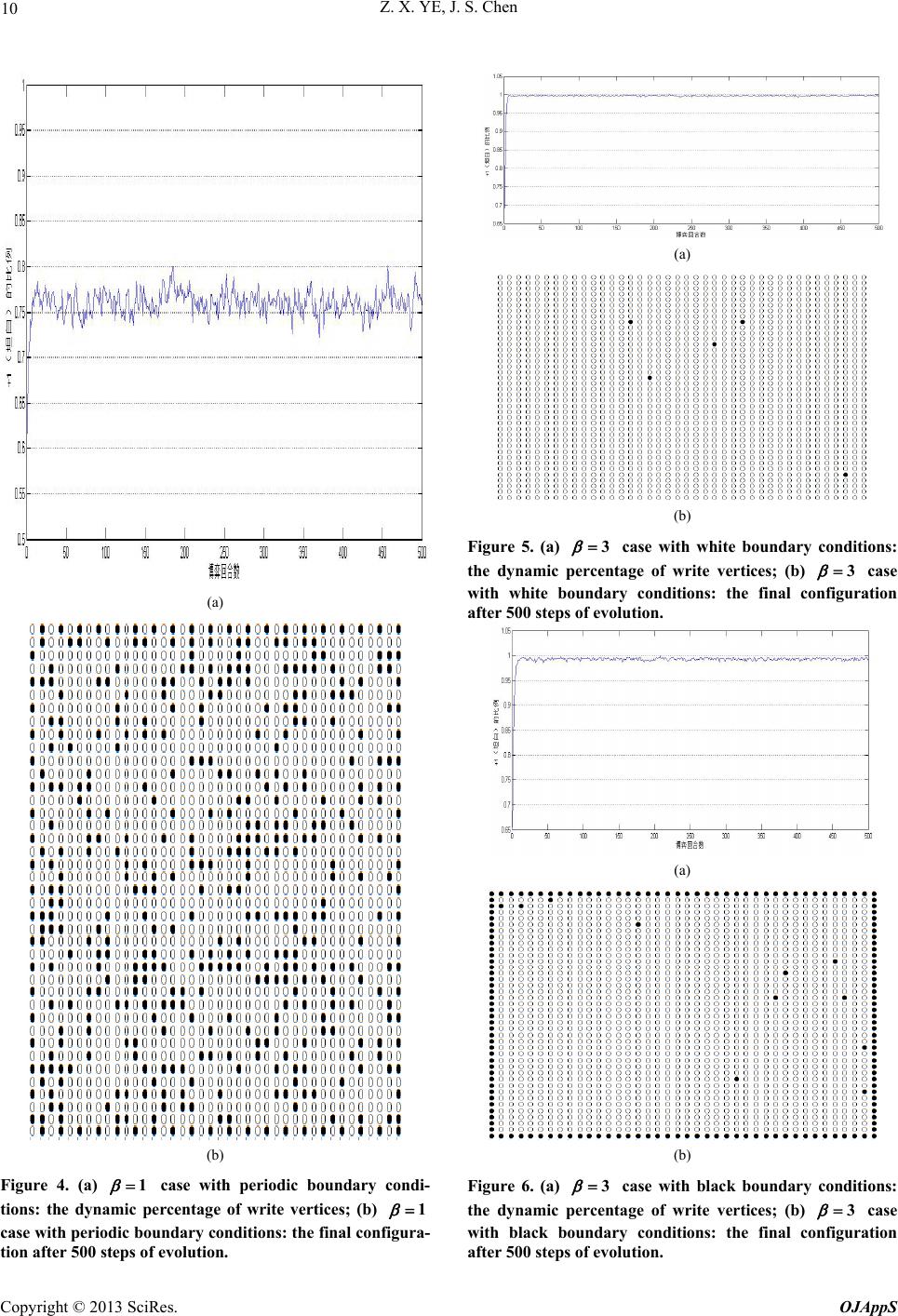
verti-
ce The los and 3 different boundary conditions. cal and
global transition probabilities are given by (2) and (6),
respectively. We use white color to represent D strategy
state, and black color the C strategy state. For different
which is called configuration space of the SEP at time t.
Copyright © 2013 SciRes. OJAppS