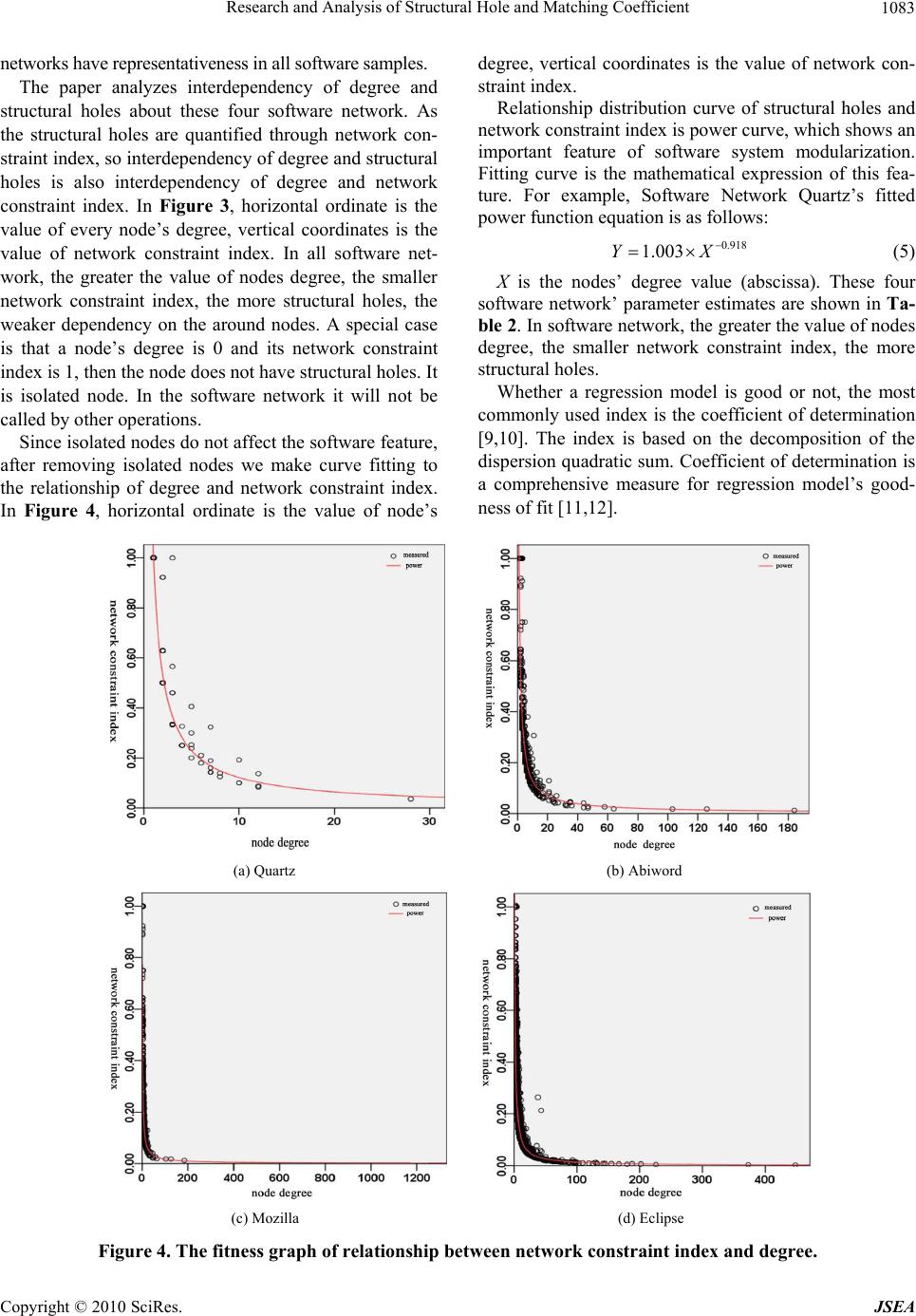
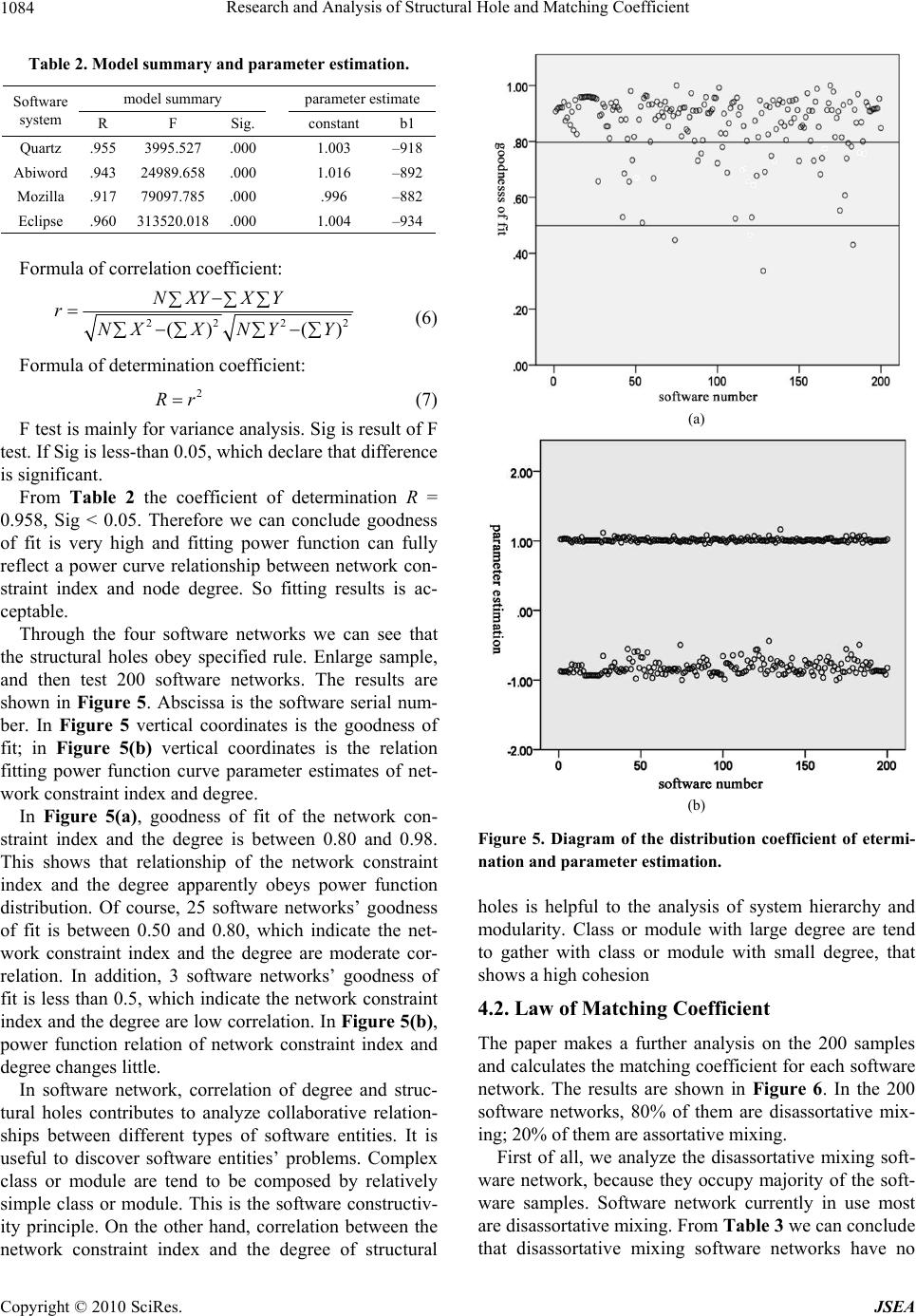
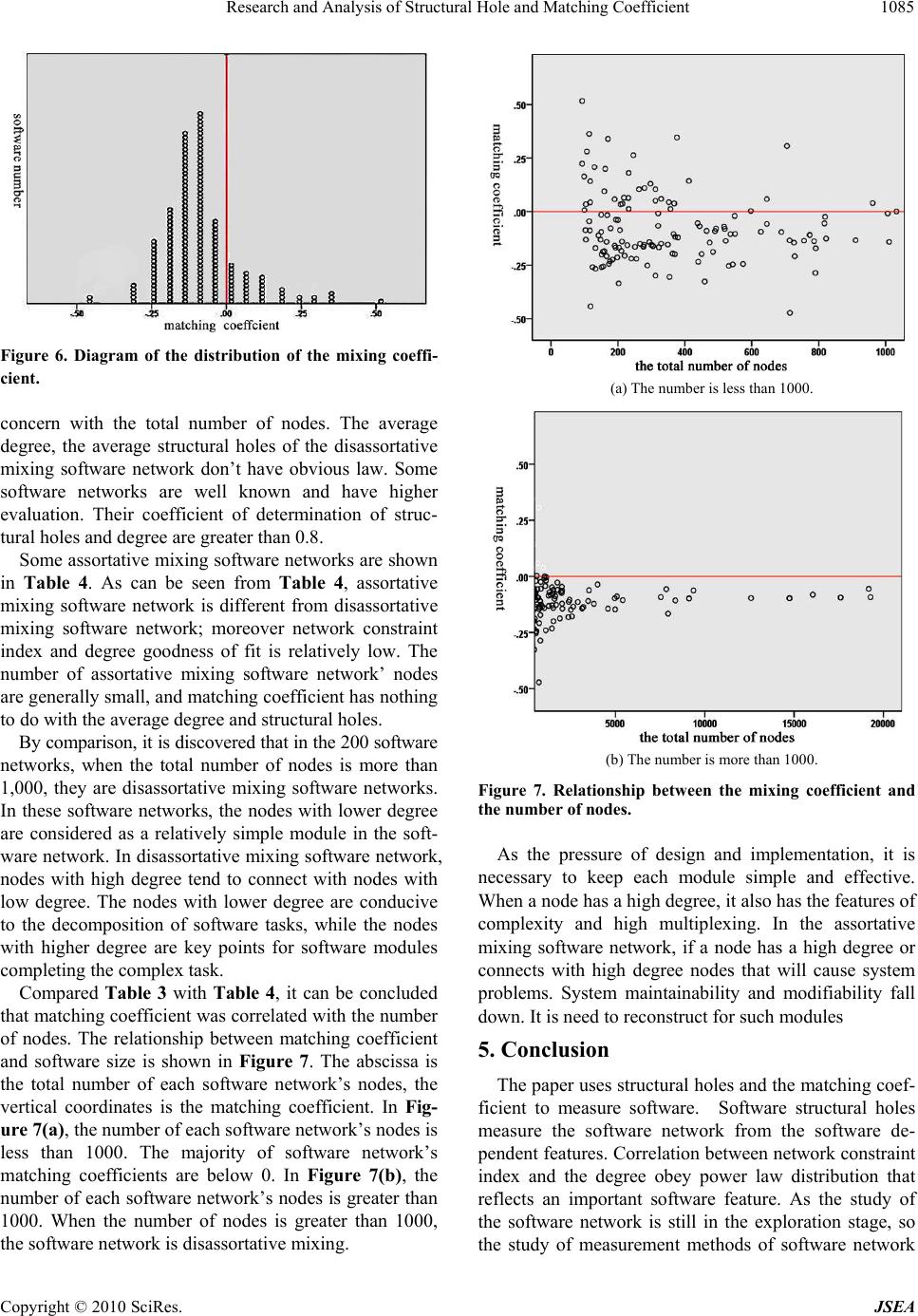
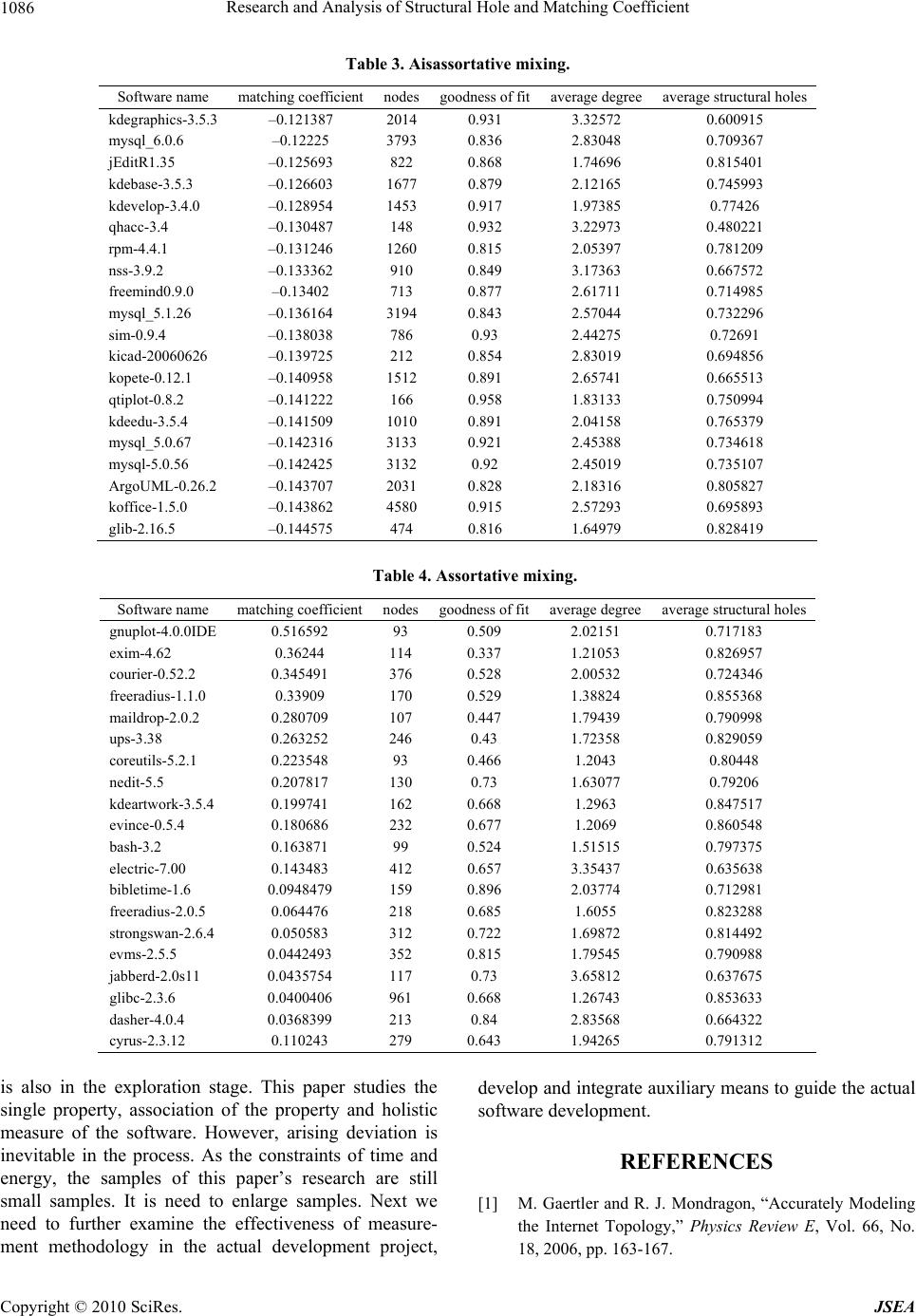
Research and Analysis of Structural Hole and Matching Coefficient 1081
Any node in the software network has direct contact
with other nodes. From the whole network view, it is
“no-hole” structure. This structure only exists in small-
scale software network and such groups are actually
closed, so the importance of each node in the networks is
basically equal. There are many nodes needed to be up-
dated. It is difficu lt to control them and update software.
In addition, the cost of maintaining this high redundancy
network is high.
Only the central node has direct link with every other
node in the network. The other nodes do not connect
with every node directly. From the whole view of the
network, the phenomenon of no direct contact or rela-
tionship breaking off is structural holes. There are no
direct connections among the rest nodes, which is
whole-hole structure.
2) The algorithm of structural holes
In the aspects of structural holes measurement, struc-
tural constraint algorithm and betweenness centrality
algorithm have been used. Structural constraint algorithm
uses closeness among nodes as measure targets, depend-
ence among nodes as the evaluation criteria. It can de-
termine the degree of software network structural holes.
At the same time if nodes across more structural holes,
they have less redundant connections, can access more
non-redundant in formation and are used more frequently.
Betweenness centrality algorithm largely determines the
centering level of the nodes. Therefore, the paper uses
structural constraint algorithm to compute structural
holes.
Definition 2.1 Network Constraint index: This index
describes direct or indirect closeness between a node and
other nodes. If the network Constraint index is higher,
the network is closer and the structural holes are fewer.
The concrete calculating steps is as follows [4]:
()
ij ji
ij ik ki
k
dd
pdd
(1)
ij
is the ratio of the shortest path length between
node i and node j to the sum of the shortest path length
about all the neighboring nodes of node i. is the
shortest pat h length bet ween node i and node j. ij
d
2
,,
(
ijijik kj
kk ikj
cp pp
)
ij
c
(2)
ij is the binding level between node i and node j.
When node j is the only adjacent node of node i, ij
gets maximal value 1.When node j is indirectly con-
nected with node i through other nodes, ij gets mini-
mum value.Node k is the adjacent node of node i.
cc
c
2
ij
p
By formula (2) and formula (3) we can calculate net-
work constraint index of node i.
i
j
C
(3)
Structural holes are used to describe a node in de-
pendence on other nodes. Few structural holes show
strong dependence on other nodes. Network constraint
index is the quantization of structural ho les. By calculat-
ing the network constraint index of structural holes, we
can understand the degree of structural holes in the soft-
ware network.
3. Matching Coefficient
In 2002, Newman put forward another important statis-
tical parameter used to mark the network, which is as-
sortativity. Assortativity is represented by r. It is chang-
ing between –1 and 1 that means nodes are prior to es-
tablish side connection with similar nodes in the network
[5,6]. When r is greater than zero, nodes are prior to con-
nect with similar nodes. Such network is called assorta-
tive mixing. When r is less than zero, nodes are prior to
connect with dissimilar nodes. Such network is called
disassortative m i xi ng.
Definition 3.1 assortative coefficient: Incidence rela-
tion between nodes in the network can be described by
assortative coefficient [7,8]:
11
1221
1
[()]
2
11
()[ ()
22
iii i
ii
ii ii
ii
EjkE jk
rEjkEjk
2
2
]
(4)
i and i are the degree of the i side’s two vertices.
E is the number of sides in the network.
j k
If assortative coefficient is greater than 0, the network
is assortative mixing; if assortative coefficient is less
than 0, the network is disassortative mixing; if assorta-
tive coefficient is equal to 0, the network is randomized.
Assortative coefficient reflects the connectivity of net-
work nodes. In the assortative mixing network, nodes of
a high degree tend to connect with nodes of a high de-
gree. In the disassortative mixing network, nodes of a
high degree tend to connect with nodes of a low degree.
In Figure 2, it is a network composed by 10 nodes. In
Figure 2(a), 0.372881r
1r
. Node 1’s degree is 5,
which is a high degree node and connect with nodes (de-
gree is 2 or 1). Such network is disassortative mixing. In
Figure 2(b),
. Degrees of all nodes are similar, that
is assortative mixing.
4. The Law and Analysis of Metrics in the
Network Software
4.1. Correlation Analysis of Degree and
Structural Holes
Degree is used to describe the connected complexity of a
C
opyright © 2010 SciRes. JSEA