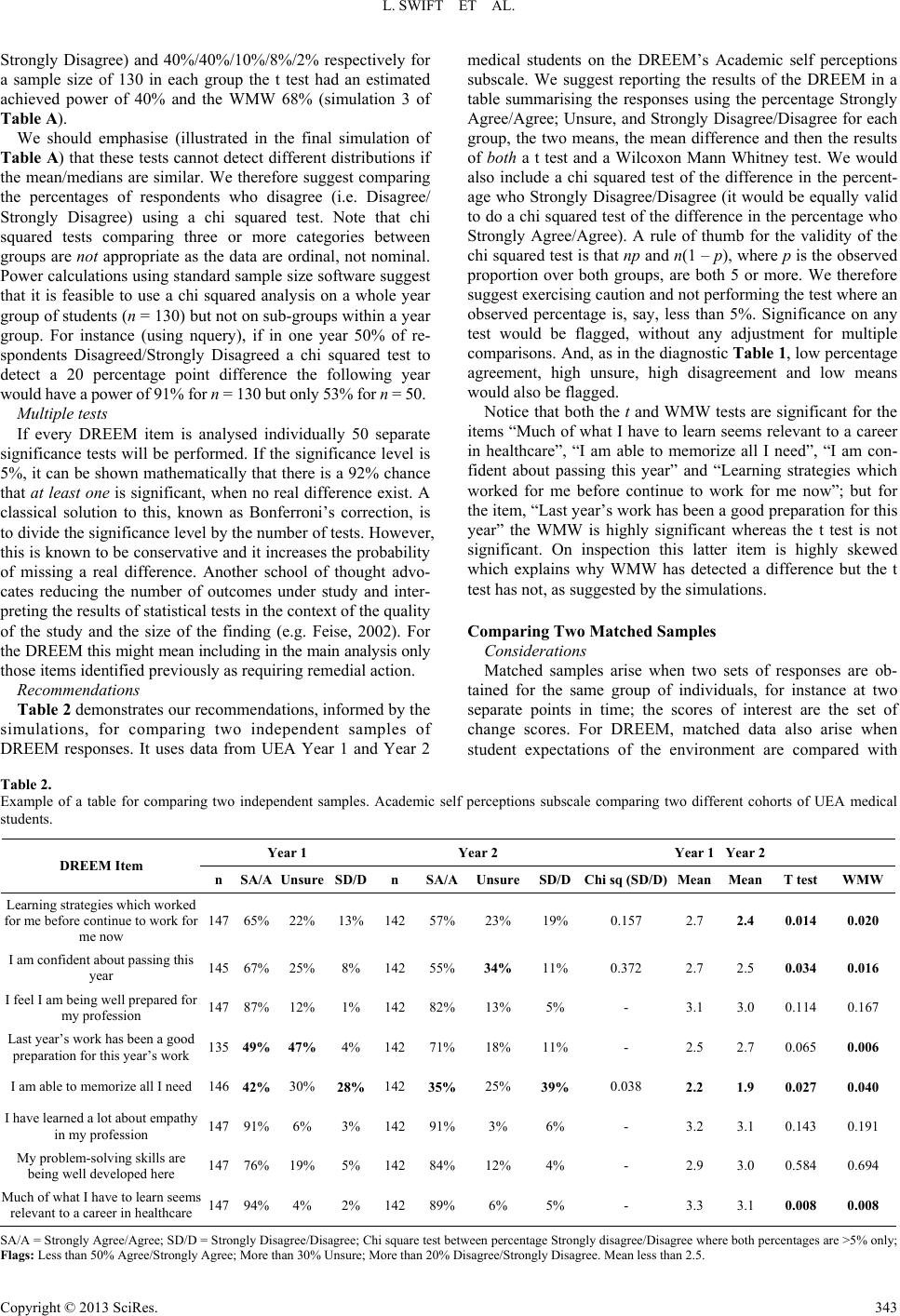
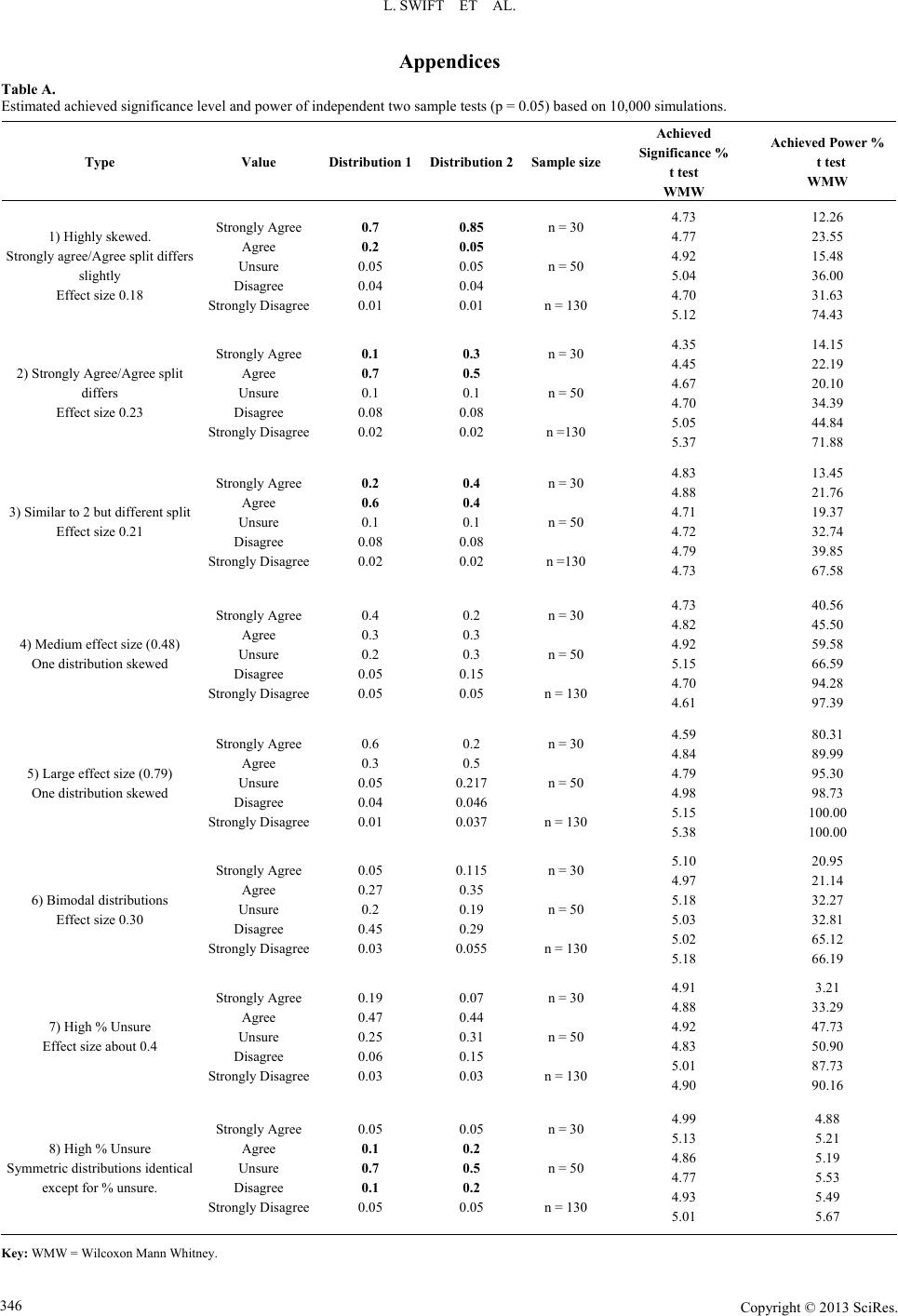
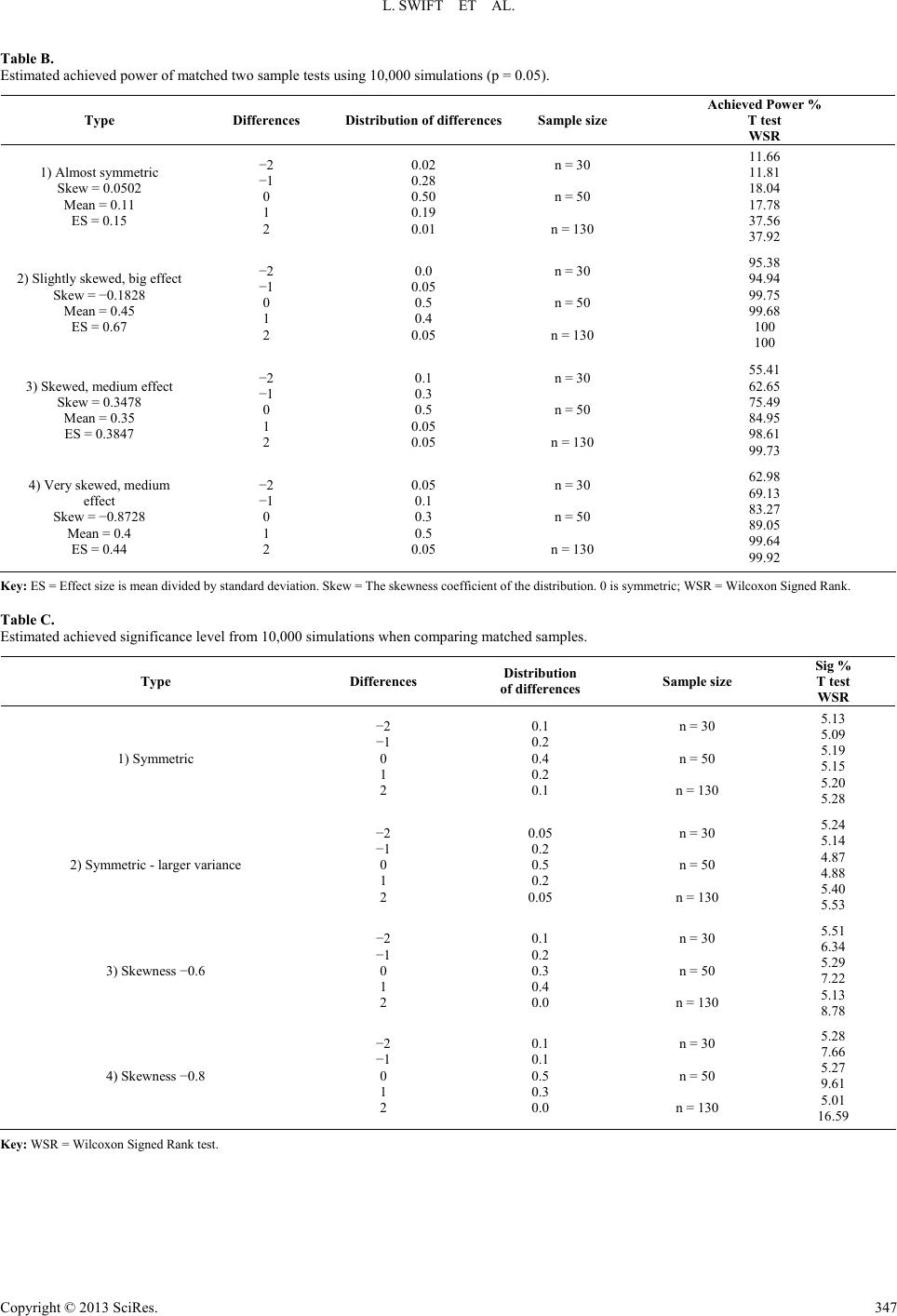
L. SWIFT ET AL.
scores to be used and combined as numbers so this question can
be put aside for the DREEM. Second, there is controversy as to
whether it is reasonable to treat Likert response scores as con-
tinuous numerical data, also known as interval data, which
opens up the possibility of using parametric methods. Jamieson
(2004) provoked considerable discussion by arguing that as
Likert scales are ordinal they should never be analysed using
parametric methods, because parametric methods make as-
sumptions such as the normality of the data. However, Carifio
(2007, 2008) makes the important distinction between a single
Likert item and a Likert scale, that is a collection of Likert
items, and supports the case that it is reasonable to treat a com-
bination of eight or more items as interval data; which would
apply in the case of the whole 50 item DREEM or its mul-
ti-item subscales. Third, Carifio (2008) also argues that single
items of a measurement scale should rarely be analysed alone
because they form part of a “structured and reasoned whole”.
However, the authors of DREEM call it a “diagnostic tool” and
the developers intended each item of the DREEM to be used
individually to diagnose problems in that area. As such, we
argue that it is valid to consider each item individually, as well
as looking at the five subscales and the full DREEM instrument.
This led us to our own investigations, using a series of simu-
lations to assess the performance of candidate statistical tests
for the Likert data generated by the DREEM. Our aim was that
these simulations would inform a set of recommendations for
the analysis and reporting of the DREEM for current and future
users of the DREEM. The investigations also have wider re-
percussions, in that they are applicable to Likert responses in
general.
Methodology
Information from the articles reviewed by Miles et al. (2012)
and unpublished student evaluation data from the Norwich
Medical School, University of East Anglia (UEA) was used to
identify typical distributions for the item responses. We then
ran a series of simulations in Stata v8 to assess the performance,
for data of this kind, of alternative tests suggested by the statis-
tical literature. A sample size of 30 was used to reflect the con-
ventional threshold at which a parametric test is applied to
non-normal samples and 50 and 130 to represent a subgroup of
a year group and a whole year group of students respectively.
The Distribution of Individual DREEM Responses
Data from UEA and research publications suggest that a
common distribution of responses for a single DREEM item is
50% - 70% Agreeing, 40% - 20% Strongly Agreeing with the
remaining small percentage spread between Strongly Disagree,
Disagree and Unsure resulting in a skewed distribution. Further,
as Till (2004) points out, a great number of items have bimodal
distributions, that is, a high percentage disagree and a high
percentage agree giving “mixed messages”. Another common
occurrence is to observe a very high percentage of Unsure an-
swers, with smaller percentages agreeing or disagreeing. Any
method of reporting and analysis must therefore be suitable for
all these types of distribution.
The Uses of the DREEM
Miles et al. (2012) identified three main uses of the DREEM
for evaluation purposes. First, it is used as a diagnostic tool;
that is to highlight elements of a course/curriculum which are
currently unsatisfactory and need remediation. Second, it can be
used to compare two or more completely separate groups of
students, for instance, males with females or one year group
with another. More generally this is known as the independent
samples case. Third, it is used to compare the same group of
students on different occasions; the matched case. This might
be, for instance, to compare a cohort’s experiences from one
academic year to another or alternatively to compare a group of
students’ scores with their “ideal” or “expected” score. We will
consider each of these in turn.
The DREEM as a Diagnostic Tool
Considerations
The developers suggest reporting mean scores across all par-
ticipants for each of the 50 items separately. If using the
DREEM for purely diagnostic purposes examination of these
means will indicate areas of strength and weakness. Individual
items with a mean score of ≥3.5 are particularly strong areas,
items with a mean score of ≤2.0 need particular attention, and
items with mean scores between 2 and 3 are areas of the educa-
tional environment that could be improved (McAleer and Roff,
2001).
Recommendations
It is certainly meaningful to use means rather than medians
because the median can only take one of the five possible
scores. However, for skewed or bimodal distributions, which
commonly occur in the DREEM, an item with an acceptable
central measure may still mask a high proportion of negative
responses, so this alone does not seem adequate. We therefore
suggest reporting a table of results which summarises the re-
sponses by merging the Agree/Strongly Agree, Disagree/
Strongly Disagree categories and reports the mean. Further we
propose using a series of warnings or “flags”, with thresholds
decided a priori to alert to items with a low percentage agree-
ment, a high percentage unsure and/or a high percentage dis-
agree as well as means below a particular level, say 2.0 as rec-
ommended by the developers or 2.5 if one wants to be stricter.
Given that many items give skewed responses the standard
deviation can mislead, so we do not recommend its inclusion.
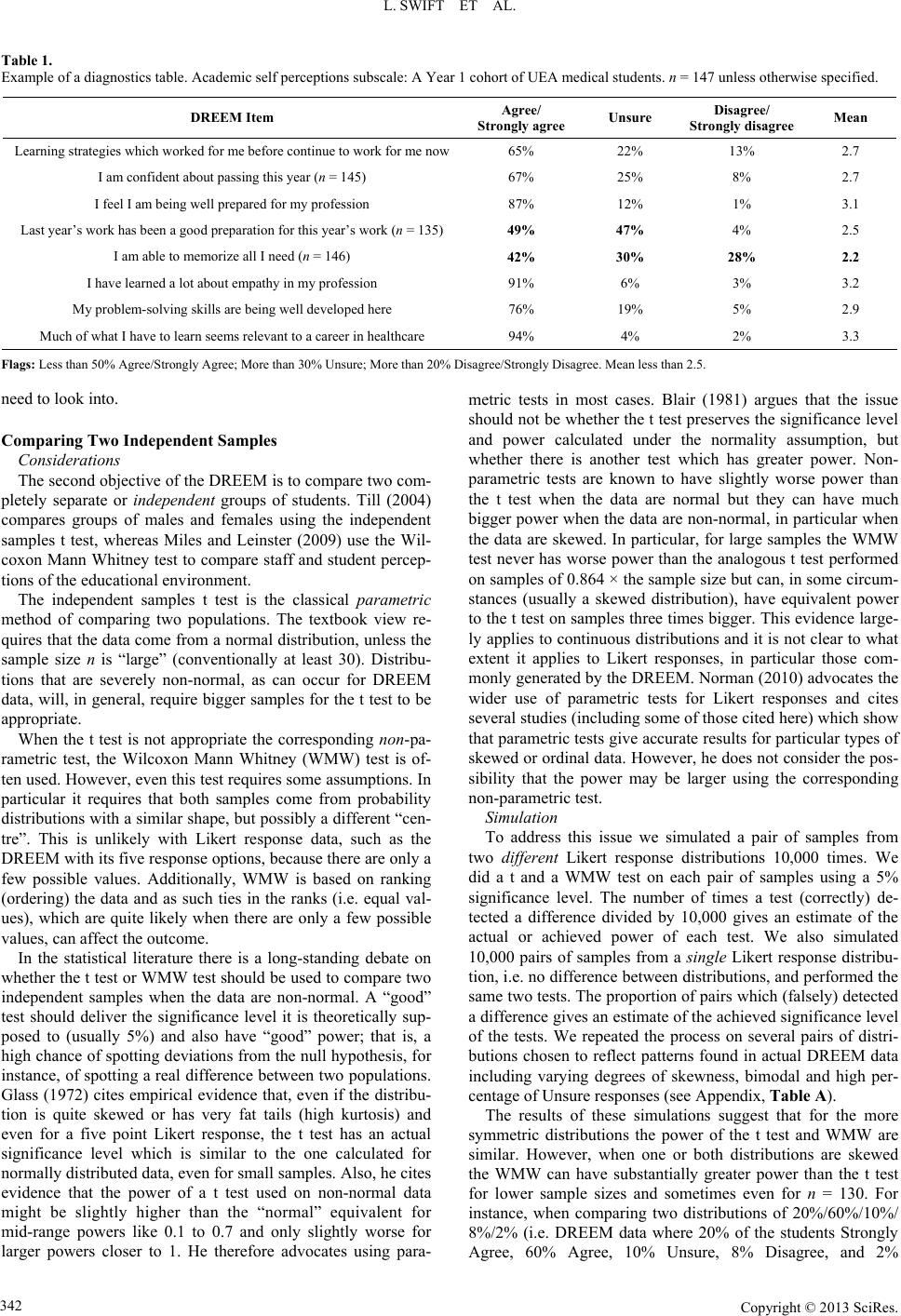
An example for one of the DREEM’s five subscales using
data from Year 1 UEA medical students can be seen in Table 1.
We have flagged in bold those items where less than 50% of
students Agree/Strongly Agree, more than 30% are Unsure and
more than 20% Disagree/Strongly Disagree. Notice that flags
occur on the items “Last year’s work has been a good prepara-
tion for this year’s work” and “I am able to memorize all I
need”. Whilst the item “Last year’s work has been a good
preparation for this year’s work” has a low but acceptable mean
of 2.5 the “flag” system draws attention to the fact that less than
50% of respondents agree and nearly all the others are unsure
suggesting that this is an item that needs attention from the
teaching team. However, in this case we would not necessarily
expect first year students to feel that the work they had done
last year (for instance A levels, an Access to Medicine course
or employment) was a good preparation for their first year of
medical school and there is no cause for concern. This illus-
trates the importance of interpreting the DREEM scores ac-
cording to their unique situational context at each educational
institution. In contrast, the flag for the item “I am able to mem-
orize all I need” suggests that there may be a concern about
workload or learning strategies that the teaching team might
Copyright © 2013 SciRes. 341