Intelligent Information Management
Vol. 4 No. 4 (2012) , Article ID: 21406 , 7 pages DOI:10.4236/iim.2012.44017
Weighted Scatter-Difference-Based Two Dimensional Discriminant Analysis for Face Recognition
Laboratory of Conception and Systems, Faculty of Sciences, University of Mohamed V-AGDAL, Rabat, Morocco
Email: Hythem0101@hotmail.com, {jedra, zahid}@fsr.ac.ma
Received May 8, 2012; revised June 25, 2012; accepted July 5, 2012
Keywords: Feature Extraction; Face Recognition; LDA; PCA; 2DPCA; 2DLDA; WSD2DDA
ABSTRACT
Linear Discriminant Analysis (LDA) is a well-known scheme for feature extraction and dimension. It has been used widely in many applications involving high-dimensional data, such as face recognition, image retrieval, etc. An intrinsic limitation of classical LDA is the so-called singularity problem, that is, it fails when all scatter matrices are singular. A well-known approach to deal with the singularity problem is to apply an intermediate dimension reduction stage using Principal Component Analysis (PCA) before LDA. The algorithm, called PCA + LDA, is used widely in face recognition. However, PCA + LDA have high costs in time and space, due to the need for an eigen-decomposition involving the scatter matrices. Also, Two Dimensional Linear Discriminant Analysis (2DLDA) implicitly overcomes the singularity problem, while achieving efficiency. The difference between 2DLDA and classical LDA lies in the model for data representation. Classical LDA works with vectorized representation of data, while the 2DLDA algorithm works with data in matrix representation. To deal with the singularity problem we propose a new technique coined as the Weighted Scatter-Difference-Based Two Dimensional Discriminant Analysis (WSD2DDA). The algorithm is applied on face recognition and compared with PCA + LDA and 2DLDA. Experiments show that WSD2DDA achieve competitive recognition accuracy, while being much more efficient.
1. Introduction
Linear Discriminant Analysis [1-5] is a well-known method which projects the data onto a lower-dimensional vector space such that the ratio of between-class distance to the within-class distance is maximized, thus achieving maximum discrimination. All scatter matrices in question can be singular since the data is drawn from a very high-dimensional space, and in general, the dimension exceeds the number of data points. This is known as the under sampled or singularity problem [6].
In recent years, many approaches have been brought to bear on such high-dimensionality under sampled problems, including pseudo-inverse LDA, PCA + LDA, and regularized LDA. More details can be found in [6]. Among these LDA extensions is PCA + LDA which has received a lot of attention, especially for face recognition [3]. In this two-stage algorithm, an intermediate dimension reduction stage using PCA is applied before LDA. The common aspect of previous LDA extension is the computation of eigen-decomposition of certain large matrices, which is not only degrades the efficiency but also makes it hard to scale them into large datasets.
The objective of LDA is to find the optimal projection so that the ratio of the determinants of the between-class and within-class scatter matrix of the projected samples reaches its maximum. However, concatenating 2D matrices into a 1D vector leads to a very high-dimensional image vector, where it is difficult to evaluate the accurately of scatter matrices due to their large size and the relatively small number of training samples. Furthermore, the within-class scatter matrix is always singular, making the direct implementation of the LDA algorithm an intractable task. To overcome these problems, a new technique called 2-dimensional LDA (2DLDA) was recently proposed. This method directly computes the eigenvectors of the scatter matrices without conversion a matrix into a vector. Thus, PCA and LDA were developed into the 2-dimensional space these methods which are known as 2DPCA and 2DLDA [7-12].
The scatter matrices in 2DLDA are quite small compared to the scatter matrices in LDA. The size of a 2DLDA matrix is proportional to the width of the image. 2DLDA evaluates the scatter matrices more accurately and computes the corresponding eigenvectors more efficiently than LDA or PCA. However, the main drawback of 2DLDA is that, it needs more coefficients for image representation that the conventional PCA and LDA-based schemes. Tang et al. [13] have introduced a weighting scheme to estimate the within-class scatter matrix using a so called relevance weights. This technique was used in face recognition by Chougdali and all [14].
2. Subspace LDA Method
The first method in this study is the Subspace LDA method [15-18]. Projecting the data to the eigenface space generalizes the data, whereas implementing LDA by projecting the data to the classification space discriminates the data. Thus, Subspace LDA approach indeed is a complementary approach to the eigenface method. Now we described the following steps which summarize the PCA process:
1) Let a face image I be a two dimensional (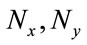 ) matrix, pixels is converted to the image vector
) matrix, pixels is converted to the image vector  of size (
of size (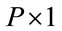 ) where P is of size (
) where P is of size (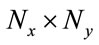 ), by adding each column one after the other we obtain the training set as:
), by adding each column one after the other we obtain the training set as: 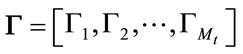 (1)
(1)
of image vectors and its size is (P × Mt) where Mt is the number of training images.
2) Calculate the mean face,  as the arithmetic average of the training image vector at each pixel point:
as the arithmetic average of the training image vector at each pixel point:
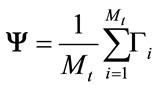 (2)
(2)
3) Find the mean subtracted image which is the difference of the training image from the mean image 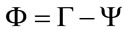 and we obtain the difference matrix:
and we obtain the difference matrix:
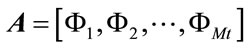 (3)
(3)
which is the matrix of all the mean subtracted training image vectors and its size is (P × Mt).
4) Calculate the covariance matrix to represent the scatter degree of all feature vectors related to the average vector. The covariance matrix X of the training image vectors of size (P × P) is defined by:
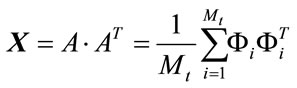 (4)
(4)
An important property of the eigenface method is its feasibility to obtain the eigenvectors of the covariance matrix. For a face image of size (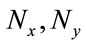 ) pixels, the covariance matrix is of size (P × P). This covariance matrix is very hard to work with due to its huge dimension causing computational complexity. On the other hand, the eigenface method calculates the eigenvectors of the
) pixels, the covariance matrix is of size (P × P). This covariance matrix is very hard to work with due to its huge dimension causing computational complexity. On the other hand, the eigenface method calculates the eigenvectors of the 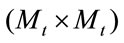 matrix, with Mt being the number of face images, and we can obtains (P × P) matrix using the eigenvectors of the (Mt × Mt) matrix.
matrix, with Mt being the number of face images, and we can obtains (P × P) matrix using the eigenvectors of the (Mt × Mt) matrix.
 (5)
(5)
we compute the eigenvectors and corresponding eigenvalues by:
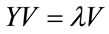 (6)
(6)
using (SVD) function, where V is the set of eigenvectors associates with its eigenvalue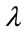 .
.
Also it can be easily observed that most of generalization power is contained in the first few eigenvectors. For example, 40% of the total eigenvectors share 85% - 90% of the total generalization power.
After this we find the eigenface by projection of matrix A into new eigenvector and normalized the eigenface.
5) Each mean subtracted image project into eigenspace using:
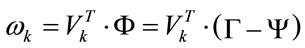 (7)
(7)
where k = 1, 2, ,
, .
.
Finally, we obtain weight Matrix:
 (8)
(8)
By performing all these calculations, the training images are projected into the eigenface space, that is a transformation from P-dimensional space into 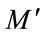 dimensional space. This PCA step, also referred as a feature extraction step is performed to reduce the dimension of the data. From this step on, each image is an (
dimensional space. This PCA step, also referred as a feature extraction step is performed to reduce the dimension of the data. From this step on, each image is an (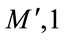 ) dimensional vector in the eigenface space. After the PCA, we describe the LDA process.
) dimensional vector in the eigenface space. After the PCA, we describe the LDA process.
With the projected data in hand, a new transformation is performed; the classification space projection by LDA. Instead of using the pixel values of the images (as done in pure LDA), the eigenface projections are used in Subspace LDA method.
Again, as in the case of pure LDA, a discriminatory power is defined as:
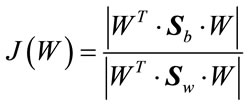 (9)
(9)
where 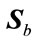 is the between-class and
is the between-class and 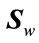 is the withinclass scatter matrix.
is the withinclass scatter matrix.
For c individuals having qi training images in the database, the within-class scatter matrix is computed as:
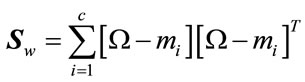 (10)
(10)
The size of  depends on the size of the eigenface space. If
depends on the size of the eigenface space. If 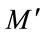 of the eigenface were used, then the size of
of the eigenface were used, then the size of 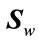 is (
is ( ).
).
The means of eigenface space class are defined as:
 (11)
(11)
where 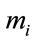 are the arithmetic average of the eigenface projected training image vector corresponding to the same individual, i = 1,2,
are the arithmetic average of the eigenface projected training image vector corresponding to the same individual, i = 1,2, ,c with size (
,c with size (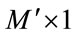 ).
).
Moreover, the mean face is calculated from the arithmetic average of the entire projected training image vector by:
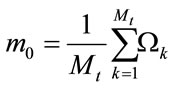 (12)
(12)
And the between-class scatter matrix is computed as:
 (13)
(13)
which represents the scatter of each projection classes mean 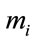 around the overall mean vector
around the overall mean vector 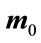 and its size is (
and its size is (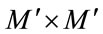 ).
).
The objective is to maximize J(W), to find an optimal projection W which maximizes between-class scatter and minimizes within-class scatter:
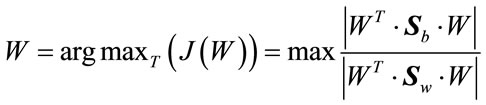 (14)
(14)
Then, W can be obtained by solving the generalized eigenvalue problem:
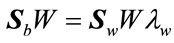 (15)
(15)
Next, the eigenface projections of the training image vectors are projected to the classification space by the dot product of optimum projection of W and weight vector:
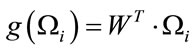 (16)
(16)
In the testing phase each test image should be mean centered, and projected into the same eigenspace as defined by:
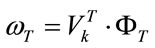 (17)
(17)
where 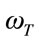 is the projection of a training image on each of the eigenvectors, k = 1, 2,
is the projection of a training image on each of the eigenvectors, k = 1, 2, ,
,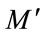 . Then we obtain the weight matrix as:
. Then we obtain the weight matrix as:
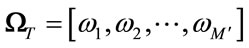 (18)
(18)
where 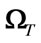 is the representation of the test image in the eigenface space and its size is (
is the representation of the test image in the eigenface space and its size is (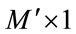 ).
).
After this, the eigenface projection of the test image vector (i.e. the weight matrix) is projected to the classification space in the same manner as:
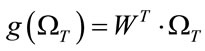 (19)
(19)
which is of size ((c – 1) × 1).
Finally, we compute the Euclidean distance 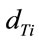 between the training and test classification space projection by:
between the training and test classification space projection by:
 (20)
(20)
which is scalar and calculated for i = 1, 2, ,
,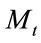 and returned the index, which refers to the smallest values of distance measure.
and returned the index, which refers to the smallest values of distance measure.
3. Two Dimensional Linear Discriminant Analysis (2DLDA)
Suppose there are c known pattern classes 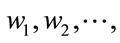
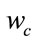 and N training samples
and N training samples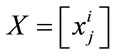 , I = 1, 2,
, I = 1, 2,  ,
, 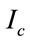 , j = 1, 2,
, j = 1, 2,  , c is a set of samples with (m × n) dimension.
, c is a set of samples with (m × n) dimension. 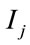 is the number of training samples of class j and satisfies
is the number of training samples of class j and satisfies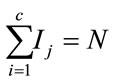 . The following steps summarize the process of 2DLDA:
. The following steps summarize the process of 2DLDA:
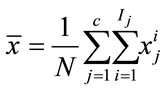 (21)
(21)
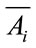 of the
of the 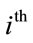 class by:
class by: 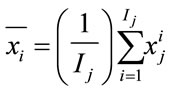 (22)
(22)
where i = 1, 2,  ,
, .
.
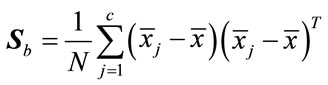 (23)
(23)
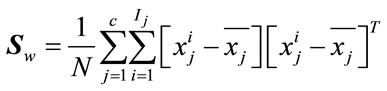 (24)
(24)
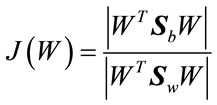 (25)
(25)
It can be proven that the eigenvector corresponding to the maximum eigenvalue of  is the optimal projection vectors which maximizes J(W). Generally, as it is not enough to have only one optimal projection vector, we usually look for d projection axes, say (
is the optimal projection vectors which maximizes J(W). Generally, as it is not enough to have only one optimal projection vector, we usually look for d projection axes, say (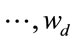
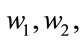 ), which are the eigenvectors corresponding to the first largest eigenvalues of
), which are the eigenvectors corresponding to the first largest eigenvalues of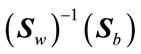 . In 2DLDA, once these projection vectors are computed, each training image
. In 2DLDA, once these projection vectors are computed, each training image 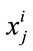 is then projected onto W to obtain the feature matrix
is then projected onto W to obtain the feature matrix  (m × d) of the training image
(m × d) of the training image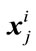 . So, during training, for each training image
. So, during training, for each training image 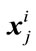 a corresponding feature matrix of size m × d is constructed and sorted for matching at the time of recognition.
a corresponding feature matrix of size m × d is constructed and sorted for matching at the time of recognition.
 (26)
(26)
 and
and 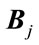 defined by:
defined by: 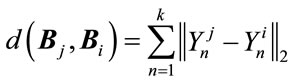 (27)
(27)
If 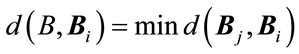 and
and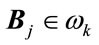 , where
, where 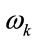 identify the class and B is a test sample, then the resulting decision is
identify the class and B is a test sample, then the resulting decision is .
.
4. Weighted Scatter Tow Dimension Difference Discriminant Analysis
The maximum scatter difference (MSD) discriminant criterion attracts a lot of research with regard to the components of this ratio. Recently, for the emphasis on the within-class scatter matrix, WMSD include the studies of [7,19]. Furthermore, these studies have demonstrated that MSD classifiers based on the discriminant criterion have been quite effective on face-recognition tasks. Since, the MSD utilizes the generalized scatter difference rather than the generalized Rayleigh quotient as a class separability measure; it also avoids the singularity problem when addressing the small-sample size problem that troubles the Fisher discriminant criterion. We introduce the weighted scatter matrices and thus define a weighted scatter-difference-based discriminant analysis criterion as follows:
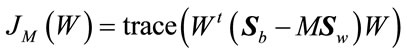 (28)
(28)
where,
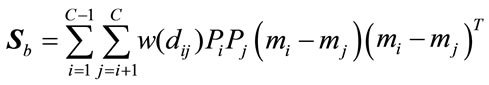 (29)
(29)
with 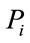 and
and 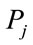 are the class priors and
are the class priors and 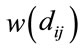 is the Euclidean distance between the means of class i and class j. The weighting function
is the Euclidean distance between the means of class i and class j. The weighting function 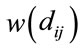 is generally a monotonically decreasing function:
is generally a monotonically decreasing function:
 (30)
(30)
where ri’s 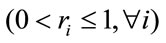 are the relevance based weights defined by
are the relevance based weights defined by
 (31)
(31)
which are based on the reciprocals of the smallest weights given by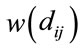 .To obtain an alternative set of based weights that assume to capture extra classes, we propose to pick the first largest
.To obtain an alternative set of based weights that assume to capture extra classes, we propose to pick the first largest 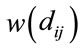 values so that Equation (31) is complement
values so that Equation (31) is complement
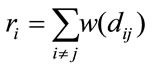 (32)
(32)
The proposed weight given by (32) relatively performed better than those given by (31) in this study. The weights proposed by (32) could be considered as an extension to the concept of weights to estimate a withinclass scatter matrix. Thus by introducing a so-called relevance weights, a weighted within-class scatter matrix 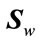 can be defined by replacing the conventional withinclass scatter matrix with:
can be defined by replacing the conventional withinclass scatter matrix with:
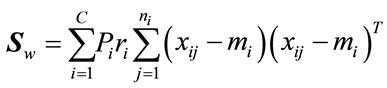 (33)
(33)
To obtain a better result we use the best eigenvector corresponding to the maximum eigenvalue given by:
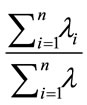 (34)
(34)
Using the weighted scatter matrices  and
and 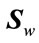 and consequently the criterion in (28) the resulting algorithm is referred to as Weighted Scatter difference 2DDA (WSD-2DDA). Thus, the criterion is:
and consequently the criterion in (28) the resulting algorithm is referred to as Weighted Scatter difference 2DDA (WSD-2DDA). Thus, the criterion is:
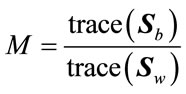 (35)
(35)
5. Experiment and Result
5.1. The Experiments on the ORL Face Base
For showing the effect of WSD2DDA, we use ORL database [20]. This base contains images from 40 individuals, each providing 40 different images. For some subjects, the images were taken at different times. The facial expressions (open or closed eyes, smiling or none smiling) and facial details (glasses or no glasses) also vary. The images were taken with a tolerance for some titling and rotation of the face of up to 20 degrees. Moreover, there is also some variation in the scale of up to about 10 percent. All images are grayscale and normalized to a resolution of 112 × 92 pixels. Examples of images are shown in (Figure 1).
Here we use between 3 to 9 images sample per class for training, and the remaining images for the test and we take three cases with different input and find the mean of this three cases. Table 1 show the comparisons result on recognition accuracy. We can see from this table that the result of testing WSD2DDA is better than the results of other methods.

Figure 1. Examples of ORL database.
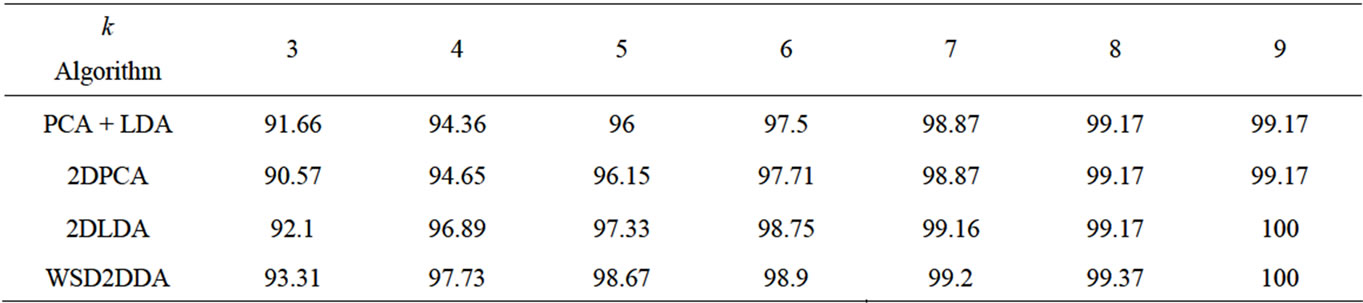
Table 1. Comparison result of recognition accuracy on ORL database.
For the comparison of cup time(s) for feature extraction of ORL databases, it can be seen from Table 2, 2DLDA, 2DPCA and WSD2DDA takes little time than PCA + LDA, because the size of the covariance matrix in 2DLDA is (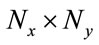 ) and the size of covariance matrix in PCA + LDA is (P × P) where P is size (
) and the size of covariance matrix in PCA + LDA is (P × P) where P is size (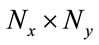 ). So, the covariance matrix in 2DLDA and 2DPCA is smallest and the computational cost is low.
). So, the covariance matrix in 2DLDA and 2DPCA is smallest and the computational cost is low.
5.2. Experiment on the Yale B Database
The next experiment is performed using the Yale face database [21], which contains 165 images of 15 individuals (each person has 11 different images) under various facial expressions and lighting conditions. Each image is manually cropped and resized 92 × 112 pixel in this experiment. We use a number of training images between 3 to 10 and the remaining images for test and we take three cases with different input and find the mean of these three cases. From the experimental results listed in Table 3, we can see that the recognition rate of WSD- 2DDA is superior to other methods. Example of images is shown in (Figure 2).
5.3. Experiment on the Headpose Database
The head pose database [22,23] is a benchmark of 2790 monocular face images of 15 persons with variations of pan and tilt angles from –90 to +90 degrees. For every person, 2 series of 93 images (93 different poses) are available. The purpose of having 2 series per person is to be able to train and test algorithms on known and unknown faces. People in the database wear glasses or not and have various skin color. Background is willingly neutral and uncluttered in order to focus on face operations. All images have been taken using the FAME Platform of the PRIMA Team in INRIA Rhone-Alpes. To obtain different poses, we have put markers in the whole room. Each marker corresponds to a 2D pose (pan, tilt). Post-it is used as markers. The whole set of post-it covers a half-sphere in front of the person see Table 4. Each image is manually cropped and resized 92 × 112 pixel in this experiment. We use a number of training images between 10 to 100 and the different 88 images for test. From the experimental results listed in Table 5, we can see that the recognition rate of WSD2DDA is superior to other methods. Face positions on each image are labeled in an individual text file. In Figure 3 a small sample of this database.
6. Conclusions
A novel feature extraction method, weighted scatter difference (WSD2DDA) is proposed in this paper. This method gives an alternative better solution of the singularity problem and reduces the cost in the complexity of the LDA algorithm.
Specifically, the propose method has the following advantages: the recognition rate of WSD2DDA is better than other existing methods; the execution time of WSD- 2DDA, 2DLDA and 2DPCA is less than PCA + LDA. Finally we have shown that though the cup time depends on the size of the face images and the number of classes, the method is very effective in face recognition. The faces used during experimentation are ORL, Yale B and Head Pose face databases respectively on which we demonstrate that the proposed method gives a good performance of face recognition rate.

Figure 2. Examples of Yale B database.








Figure 3. A small sample of head pose database.

Table 2. Recognition time on ORL database per second.

Table 3. Comparison result of recognition accuracy on Yale B database.

Table 4. Chow pan and tilt angles of head pose database.

Table 5. Comparison result of recognition accuracy on head pose database.
7. Future Work
In the future work we plan to apply Kernel Relevance Weighted (2DLDA) and Kernel Weighted Scatter-Difference Based Two Dimensional Discriminant Analysis for Face Recognition.
REFERENCES
- R. O. Dudo, P. E. Hart and D. Stork, “Pattern Classification,” Wiley, New York, 2000.
- K. Fukunage, “Introduction to Statistical Pattren Classification,” Academic Press, San Diego, 1990.
- P. N. Belhumeour, J. P. Hespanha and D. J. Kriegman. “Eiegnfaces vs Fisherfaces: Recognition Using Class Specific Linear Projection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 19, No. 7, 1997, pp. 711-720. doi:10.1109/34.598228
- D. L. Swets and J. Y. Weng, “Using Discriminant Eigenfeatures for Image Retrieval,” IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. 18, No. 8, 1996, pp. 831-836.
- S. Dudoit, J. Fridlyand and T. P. Speed, “Comparison of Discrimination Methods for the Classification of Tumors Using Gene Expression Data,” Journal of the American Statistical Association, Vol. 97, No. 457, 2002, pp. 77-87. doi:10.1198/016214502753479248
- W. J. Krzanowski, P. Jonathan, W. V. McCarthy and M. R. Thomas, “Discriminant Analysis with Singular Covariance Matrices: Methods and Applications to Spectroscopic Data,” Applied Statistics, Vol. 44, No. 1, 1995, pp. 101-115. doi:10.2307/2986198
- X. Li, “Weighted Maximum Scatter Difference Based Feature Extraction and Its Application to Face Recognition,” Machine Vision and Applications, Vol. 22, No. 3, 2011, pp. 591-595.
- J. Yang and D. Zhang, “Two-Dimensional PCA: A New Approach to Appearance-Based Face Representation and Recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 26, No. 1, 2004, pp. 131-137. doi:10.1109/TPAMI.2004.1261097
- J. Yang and J. Y. Yang, “Form Image Vector to Matrix: A Straightforward Image Projection Technique-IMPCA vs PCA,” Pattern Recognition, Vol. 35, No. 9, 2002, pp. 1997-1999. doi:10.1016/S0031-3203(02)00040-7
- J. Ye, R. Janardan and Q. Li, “Two Dimensional Linear Discriminant Analysis,” Proceedings Neural Information Processing Systems (NIPS), 2004, pp. 1569-1576.
- J. Ye, “Generalized Low Rank Approximations of Matrices,” The Twenty-First International Conference on Machine Learning, Banff, Vol. 69, 2004, p. 112.
- M. Li and B. Yuang, “2D-LDA: A Novel Statistical Linear Discriminant Analysis for Image Matrix,” Pattern Recognition Letters, Vol. 26, No. 5, 2005, pp. 527-532. doi:10.1016/j.patrec.2004.09.007
- E. K. Tang, P. N. Suganthan, X. Yao and A. K. Qin, “Linear Dimensionality Reduction Using Relevance Weighted LDA,” Pattern Recognition, Vol. 38, No. 4, 2005, pp. 485-493. doi:10.1016/j.patcog.2004.09.005
- K. Chougdali, M. Jedra and N. Zahid, “Kernel Weighted Scatter Difference Discriminant Analysis,” Journal of Image Analysis and Recognition, Vol. 5112, 2008, pp. 977-983. doi:10.1007/978-3-540-69812-8_97
- W. Zhao, A. Krishnaswamy, R. Chellappa, D. L. Swets and J. Weng, “Discriminant Analysis of Principal Components for Face Recognition-FGR,” International Conference on Automatic Face and Gesture Recognition, 14- 16 April 1998, pp. 336-341.
- W. Zhao, R. Chellappa and N. Nandhakumar, “Emprical Performance Analysis of Linear Discriminant, Classifiers,” IEEE Computer Society Conference on Computer Vision and Pattern Recognition, College Park, 23-25 June 1998, pp. 164-169.
- W. Zhao, “Subspace Methods in Object/Face Recognition,” International Conference on Neural Networks IEEE, College Park, 1999. pp. 3260-3264.
- F. X. Song, D. Zhang, Q. L. Chen and J. Z. Wang, “Face Recognition Based on a Novel Linear Discriminant Criterion,” Pattern Analysis and Applications, Vol. 10, No. 3, 2007, pp. 165-174. doi:10.1007/s10044-006-0057-3
- S. L. Guan and X. D. Li, “Improved Maximum Scatter Difference Discriminant Analysis for Face Recognition,” Proceedings of the 2009 International Workshop on Information Security and Application (IWISA 2009), Qingdao, 21-22, November 2009.
- M. Addlesee, C. Turner and A. Hopper, “Displaying the Future,” 4th International Scientific Conference on Work with Display Units, Milan, October 1994, Technical Report 94.13 http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
- A. S. Georghiades, P. N. Belhumeur and D. J. Kriegman, “From Few to Many: Illumination Cone Models for Face Recognition under Variable Lighting and Pose,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 23, No. 6, 2001, pp. 643-660. http://cvc.yale.edu/projects/yalefacesB/yalefacesB.html
- N. Gourier, D. Hall and J. L. Crowley, “Estimating Face Orientation from Robust Detection of Salient Facial Features.” http://www-prima.inrialpes.fr/perso/Gourier/Pointing04-Gourier.pdf
- “Head Pose Image Database,” International Workshop on Visual Observation of Deictic Gestures, Cambridge, 2004. http://www-prima.inrialpes.fr/perso/Gourier/Faces/HPDatabase.html