Advances in Bioscience and Biotechnology
Vol.05 No.13(2014), Article ID:51324,5 pages
10.4236/abb.2014.513114
Modeling of Imperfect Data in Medical Sciences by Markov Chain with Numerical Computation
Mahmoud Afshari1*, Anoshirvan Ghaffaripour2
1Department of Statistics, College of Science, Persian Gulf University, Bushehr, Iran
2Department of Statistics, College of Science, Yasouj University, Yasuj, Iran
Email: *afshar@pgu.ac.ir
Academic Editor: Jisook Kim, University of Tennessee at Chattanooga, USA
Copyright © 2014 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 24 August 2014; revised 7 October 2014; accepted 1 November 2014
ABSTRACT
In this paper we consider sequences of observations that irregularly space at infrequent time intervals. We will discuss about one of the most important issues of stochastic processes, named Markov chains. We would reconstruct the collected imperfect data as a Markov chain and obtain an algorithm for finding maximum likelihood estimate of transition matrix. This approach is known as
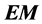 algorithm, which includes main optimum advantages among other approaches, and consists of two phases: phase (maximization of target function). Continue the phase
algorithm, which includes main optimum advantages among other approaches, and consists of two phases: phase (maximization of target function). Continue the phase
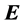 and
and
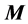 to achieve the sequence convergence of matrix. Its limit is the optimal estimator. This algorithm, in contrast with other optimum algorithms which could be used for this purpose, is practicable in maximum likelihood estimate, and unlike to the methods which involve mathematical, is executable by computer. At the end we will survey the theoretical outcomes with numerical computation by using
to achieve the sequence convergence of matrix. Its limit is the optimal estimator. This algorithm, in contrast with other optimum algorithms which could be used for this purpose, is practicable in maximum likelihood estimate, and unlike to the methods which involve mathematical, is executable by computer. At the end we will survey the theoretical outcomes with numerical computation by using
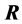 software.
software.
Keywords:
Markov Chain, Matrix Transition, Maximum Likelihood,
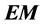 Algorithm, Missing Data
Algorithm, Missing Data

1. Introduction
Today, we humans are faced with many of the random variables and processes. One of the most important issues is the random process of Markov chain. Markov chain is often used to describe how the system changes over time. If we are able to model the system sufficiently to form a Markov chain model, we can then evaluate its various theoretical results through system analysis. In this article, the Matrix transition of Markov chain needed for imperfect observation within a given time is obtained through
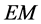 algorithm.
algorithm.
The
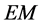 algorithm has two stages:
algorithm has two stages:
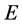 stage and
stage and
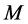 stage. This algorithm basically works in this way: We first take into consideration the initial value for the parameter which in this case is the transition matrix.
stage. This algorithm basically works in this way: We first take into consideration the initial value for the parameter which in this case is the transition matrix.
The full set of data (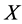 ) is then reconstructed from missing data by estimation of these parameters in
) is then reconstructed from missing data by estimation of these parameters in
 stage. In the
stage. In the
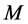 stage, the maximum likelihood of reconstructed data is maximized to get a new estimation of the parameter. Then, based on this new estimation, the
stage, the maximum likelihood of reconstructed data is maximized to get a new estimation of the parameter. Then, based on this new estimation, the
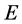 stage is repeated and we get the second estimation in the
stage is repeated and we get the second estimation in the
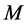 stage. Finally, we continue this process as far as to get convergence estimates.
stage. Finally, we continue this process as far as to get convergence estimates.
Dempstr [1] , Raj [2] , Johnson et al. [3] have obtained the value of maximum likelihood of the transition matrix for a sequence of observations.
Among the researchers who examined the issues of statistical inference of Markov chains and published articles in this area are Melichson [4] , Capee [5] , Chip [6] and Robert [7] .
2. Modeling of Missing Data Based on Markov Chain
Following observations in Table 1 are series of real data obtained about a kind of disease related to 3 patients at different times during 6 months in a hospital. We have missed some of the data because the patients have not attended the hospital in some cases. Number 1 indicates that the patient’s condition is satisfactory and number 2 shows the patients are in a very bad condition. The asterisk indicates that in a particular time point, the data has not been observed.
First, the patient’s condition is reported as: 1) Next month, no data are is available. Two months later the condition of that patient is reported as; 2) One month later his condition is reported as (1) again, and so on. We call such a set of data incomplete and it is shown as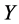 .
.
The incomplete data are collected against complete data (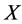 ) which are gathered in all intervals between the first and the last observation.
) which are gathered in all intervals between the first and the last observation.
Such a system can be modeled as a Markov chain with
 condition space and transition matrix P.
condition space and transition matrix P.
Generally, we will have
 if we consider
if we consider
 as the number of condition change from
as the number of condition change from
 to
to
 at the time interval
at the time interval .
.
 as the transition probability from
as the transition probability from
 to
to
 condition at t time,
condition at t time,
 as the number of condition change from
as the number of condition change from
 to
to
 in a time unit for the whole
in a time unit for the whole
 data , and
data , and
 as the element of matrix
as the element of matrix , i.e. condition change probability
, i.e. condition change probability
 a stage from
a stage from
 to
to
 condition. Having this fact in mind that with the incomplete data
condition. Having this fact in mind that with the incomplete data
 and the nonzero suitable initial transition matrix, there will be different complete data
and the nonzero suitable initial transition matrix, there will be different complete data
 with their own probabilities, we estimate the transition matrix by the
with their own probabilities, we estimate the transition matrix by the
 algorithm as follows:
algorithm as follows:
1—First, we change the specified incomplete data ( ) to complete data (
) to complete data ( ) by considering a suitable amount for those intervals we have no observation and data. In other words, we reconstruct the complete data (
) by considering a suitable amount for those intervals we have no observation and data. In other words, we reconstruct the complete data ( ) from the incomplete data.
) from the incomplete data.
2—We consider an initial value for an arbitrary non-zero element of the transfer matrix as .
.
3—We compute maximum likelihood of
 observations with the initial transmission matrix
observations with the initial transmission matrix
 as follows:
as follows:

Table 1. Missing data for patient.

 (1)
(1)
4—We calculate the relative maximum (1) and show it as .
.
5—We repeat the steps 3 and 4 so much that the obtained matrix sequence
 gets to convergence
gets to convergence
 matrix, in other words, our optimal estimate is
matrix, in other words, our optimal estimate is .
.
The
 calculation and unique maximum
calculation and unique maximum
 are stated through the following theorem.
are stated through the following theorem.
Theorem 1: Suppose that the matrix transition of the imperfect data in Table 1 is , then
, then

Proof: We assume the system at the time
 is in the
is in the
 condition and at the next time interval it is in the
condition and at the next time interval it is in the
 condition. The probability that a change occurs between conditions
condition. The probability that a change occurs between conditions
 and
and
 is done in the
is done in the
 time interval is computed according to the Figure 1 provided that the system gets to n condition at
time interval is computed according to the Figure 1 provided that the system gets to n condition at
 from the starting point condition
from the starting point condition
 at
at .
.
First the system starting from m condition changes to
 condition with the probability of
condition with the probability of
 at the time unit of
at the time unit of . Then the system is likely to change to n condition at
. Then the system is likely to change to n condition at
 with the probability of
with the probability of .
.
Suppose that we define
 and
and
 as follows:
as follows:
 : Cases in which changes from i to j condition occurs at
: Cases in which changes from i to j condition occurs at .
.
 : Cases in which system starting from m condition at
: Cases in which system starting from m condition at
 gets to n condition at
gets to n condition at .
.
Then we have:

It is clear that the probability of the number of condition changes between the
 and
and
 conditions along with a change from
conditions along with a change from
 to
to
 condition at the t time interval is equal to:
condition at the t time interval is equal to: .
.
So, the expected number of such condition changes in all time intervals is:
 because
because
 and
and
 conditions repeatedly occurs at t intervals. Therefore, the expected number of transitions from
conditions repeatedly occurs at t intervals. Therefore, the expected number of transitions from
 to
to
 condition on the condition of observed data
condition on the condition of observed data
 and Matrix transition
and Matrix transition
 accumulating on all observed data is obtained as follows:
accumulating on all observed data is obtained as follows: .
.
Theorem 2: Suppose that the matrix transition of the imperfect data in Table 1 is , then there is a unique relative maximum with its entry is as follows:
, then there is a unique relative maximum with its entry is as follows:


Figure 1. System gets to n condition.
Proof:
 (2)
(2)
Equation (2) has been obtained because the sum of entries in each line is one.


 (3)
(3)
Adding Equation (3) on , we have:
, we have:
 (4)
(4)
By replacing Equation (4) in Equation (3), the proof is completed.
Remark: the fourth stage in algorithm is computed and algorithm is completed as the following:
1) We compute .
.
2) We compute matrix transition of first stage through this formula:

The obtained
 s for all
s for all
 and
and
 forms another matrix in the form of
forms another matrix in the form of
 for the next iteration.
for the next iteration.
3. Numerical Computation
In this section, all the theories mentioned are surveyed on the Table 1 through a program written in
 software.
software.
For actual observations we have Table 2 which is number of change from
 to
to
 at the time interval
at the time interval .
.
Conducting computer program written on the bases of the
 algorithm to estimate the matrix transition of the system and the original transition
algorithm to estimate the matrix transition of the system and the original transition , we will have the following outputs:
, we will have the following outputs:
 ,
, ,
,
 ,
, ,
,
 ,
, ,
,
 ,
, ,
,
 ,
,
 (5)
(5)
 Algorithm with another initial matrix will be:
Algorithm with another initial matrix will be:
 ,
, ,
,
 ,
, ,
,
 ,
, ,
,
 ,
, ,
,
 ,
,
 (6)
(6)
As it is seen, the results (5) and (6) are the same in either way.
4. Conclusions
In using the
 algorithm, we are practically faced with some issues which should be focused to accelerate our work and save time.
algorithm, we are practically faced with some issues which should be focused to accelerate our work and save time.
1) If the initial transition matrix , which is arbitrarily chosen, is of a zero entry or the number of transitions from one condition to another one is zero in a unit of time, the corresponding entries of all produced matrices are zero, too. The initial matrix entries must be non-zero to avoid such condition.
, which is arbitrarily chosen, is of a zero entry or the number of transitions from one condition to another one is zero in a unit of time, the corresponding entries of all produced matrices are zero, too. The initial matrix entries must be non-zero to avoid such condition.
2) Increase in the number of time units between successive observations increases the power of transition matrix. If the number of the observed condition changes is relatively low, the time interval between observations is high. Accordingly, with respect to time needed for computation, it is not economical to integrate all these to-
Table 2. Condition change from
 to
to
 at the time interval
at the time interval
 for missing data.
for missing data.
gether in the analysis. Actually it is better to keep the maximum time interval at the level in which the probability of condition change is ignored. If the maximum time interval is too large, the increase in the time unit can be effective.
3) If the maximum time intervals are relatively low, the computation time of each stage is short, although different performances may be necessary before achieving convergence.
4) In practical computation, we have accepted that when the maximum difference between successive entries of transition matrix is smaller than a predetermined value, e.g. . In other words, convergence is achieved when for all values of i, j, and the given value for r, we have:
. In other words, convergence is achieved when for all values of i, j, and the given value for r, we have: .
.
Acknowledgements
The support of Research Committee of Persian Gulf University is greatly acknowledged.
References
- Dempstr, A.P., Larid, N.M. and Rubin, D.B. (1997) Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, 39, 1-38.
- Raj, B. (2002) Asymmetry of Business Cycles: The Markov-Switching Approach, Soft-Tissue Material Properties Under Large Deformation: Strain Rate Effect. Hand Book of Applied Econometrics and Statistical Inference, 3, 687-710.
- Johnson, C. and Gallivan, S. (1995) Estimating a Markov Transition Matrix from Observational Data. Journal of the Operational Researches Society, 46, 405-410. http://dx.doi.org/10.1057/jors.1995.55
- Melichson, I. (1999) A Fast Improvement to the EM Algorithm on the Own Terms. Journal of the Royal Statistical Society—Series B, 51, 127-138.
- Cappee, O., Moulines, E. and Ryden, T. (2005) Inference in Hidden Markov Models. Springer, New York.
- Chib, S. (1996) Calculating Posterior Distributions and Modal Estimates in Markov Mixture Models. Journal of Eco- nometrics, 75, 79-97. http://dx.doi.org/10.1016/0304-4076(95)01770-4
- Roberts, W. and Ephraim, Y. (2008) An EM algorithm for Ion Chanel Current Estimation. IEEE Transactions on Signal Processing, 56, 26-35. http://dx.doi.org/10.1109/TSP.2007.906743
NOTES

*Corresponding author.